La dérive de données (préversion) sera supprimée et remplacée par Model Monitor
La dérive de données (préversion) sera supprimée au 01/09/2025, et vous pouvez commencer à utiliser moniteur de modèle pour vos tâches de dérive de données. Vérifiez le contenu ci-dessous pour comprendre les étapes de remplacement, de fonctionnalité et de modification manuelle.
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Apprenez à répondre au besoin de gouvernance et à l’équilibrer avec le besoin d’agilité.
Remarque
La surveillance des modèles Azure Machine Learning (v2) offre des fonctionnalités améliorées pour la dérive des données, ainsi que des fonctionnalités supplémentaires pour la surveillance des signaux et des métriques. Pour en savoir plus sur les fonctionnalités de surveillance des modèles dans Azure Machine Learning (v2), consultez surveillance des modèles avec Azure Machine Learning.
Avec les analyses de jeux de données Azure Machine Learning (version préliminaire), vous pouvez :
- Analyser la dérive de vos données pour comprendre comment elles évoluent au fil du temps.
- Surveiller les données de modèle pour identifier les différences entre les jeux de données de formation et de service. Commencez par la collecte des données de modèle à partir des modèles déployés.
- Surveiller les nouvelles données pour identifier les différences entre le jeu de données de référence et le jeu de données cible.
- Profiler les caractéristiques dans les données pour suivre la façon dont les propriétés statistiques évoluent au fil du temps.
- Configurer des alertes sur la dérive des données pour les premiers avertissements relatifs aux problèmes potentiels.
- Créez une version de jeu de données lorsque vous déterminez que les données ont été trop dérivées.
Un jeu de données Azure Machine Learning est utilisé pour créer l’analyse. Le jeu de données doit inclure une colonne timestamp.
Vous pouvez afficher les métriques de dérive des données avec le kit de développement logiciel (SDK) Python ou dans Azure Machine Learning Studio. Les autres métriques et insights sont disponibles par le biais de la ressource Azure Application Insights associée à l’espace de travail Azure Machine Learning.
Important
La détection de dérive des données pour les jeux de données est actuellement en version préliminaire publique. La préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail en production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Prérequis
Pour créer et utiliser des analyses de jeux de données, vous avez besoin des éléments suivants :
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. Essayez la version gratuite ou payante d’Azure Machine Learning dès aujourd’hui.
- Un espace de travail Azure Machine Learning.
- Le SDK Azure Machine Learning pour Python installé, qui inclut le paquet azureml-datasets.
- Données structurées (tabulaires) avec un horodatage spécifié dans le chemin d’accès du fichier, le nom de fichier ou la colonne dans les données.
Prérequis (migrer vers le moniteur de modèle)
Lorsque vous migrez vers Model Monitor, vérifiez les conditions préalables mentionnées dans cet article Conditions préalables à la surveillance du modèle Azure Machine Learning.
Qu’est-ce qu’une dérive de données ?
La précision du modèle se dégrade au fil du temps, principalement en raison de la dérive de données. Dans le contexte de l’apprentissage automatique, la dérive de données est la modification des données d’entrée du modèle qui entraîne une dégradation des performances du modèle. La surveillance de la dérive des données permet de détecter les problèmes de performances du modèle.
Les causes de la dérive des données sont les suivantes :
- Modifications de processus en amont, comme le remplacement d’un capteur, lequel ne prend plus les mesures en pouces mais en centimètres.
- Problèmes de qualité des données, par exemple un capteur cassé indique toujours une valeur nulle.
- Dérive naturelle des données, comme la variation de la température moyenne au fil des saisons.
- Modification de la relation entre caractéristiques ou écart de covariable.
Azure Machine Learning simplifie la détection de la dérive en calculant une mesure unique en faisant abstraction de la complexité des jeux de données comparés. Ces jeux de données peuvent comporter des centaines de fonctionnalités et des dizaines de milliers de lignes. Une fois la dérive détectée, vous pouvez examiner les fonctionnalités qui sont à l’origine de la dérive. Vous Inspectez ensuite les métriques au niveau des fonctionnalités pour déboguer et isoler la cause racine de la dérive.
Cette approche descendante permet de surveiller facilement les données qu’avec les techniques traditionnelles basées sur les règles. Les techniques basées sur des règles telles que la plage de données autorisée ou les valeurs uniques autorisées peuvent être longues et sujettes aux erreurs.
Dans Azure Machine Learning, vous utilisez des analyses de jeu de données pour détecter et alerter la dérive des données.
Analyses de jeu de données
Avec un moniteur de jeu de données, vous pouvez :
- Détecter et signaler la dérive des données sur les nouvelles données d’un jeu de données.
- Analyser les données de l’historique de la dérive.
- Profiler les nouvelles données au fil du temps.
L’algorithme de dérive des données fournit une mesure globale des modifications apportées aux données et indique les caractéristiques qui sont responsables de l’investigation. Les analyses de jeu de données produisent un certain nombre d’autres métriques en profilant les nouvelles données dans le jeu de données timeseries.
Des alertes personnalisées peuvent être configurées sur toutes les métriques générées par le superviseur via Azure Application Insights. Les superviseurs de jeu de données permettent de détecter rapidement les problèmes des données et de réduire le temps nécessaire au débogage du problème en identifiant ses causes probables.
Conceptuellement, il existe trois scénarios principaux pour la configuration des analyses de jeux de données dans Azure Machine Learning.
| Scénario | Description |
|---|---|
| Surveiller des données de service d’un modèle afin de détecter toute dérive des données de formation du modèle | Les résultats de ce scénario sont le fruit de la surveillance d’un proxy en vue de vérifier l’exactitude du modèle, étant donné que celle-ci se dégrade si les données de service dérivent des données de formation. |
| Analyser un jeu de données de série chronologique pour la dérive d’une période précédente. | Ce scénario est plus général et peut être utilisé pour analyser les jeux de données impliqués en amont ou en aval de la génération de modèles. Le jeu de données cible doit avoir une colonne timestamp. Le jeu de données de base peut être n’importe quel jeu de données tabulaires ayant des caractéristiques en commun avec le jeu de données cible. |
| Exécution de l’analyse des données passées. | Ce scénario peut permettre de comprendre les données historiques et éclairer les décisions de définition des paramètres des moniteurs de jeu de données. |
Les analyses de jeu de données dépendent des services Azure suivants.
| Service Azure | Description |
|---|---|
| Dataset | La dérive utilise les jeux de données Machine Learning pour récupérer les données d’apprentissage et comparer les données pour la formation du modèle. Le profil de génération des données est utilisé pour générer certaines des mesures rapportées telles que min, max, valeurs distinctes, comptage des valeurs distinctes. |
| Pipeline et calcul Azure Machine Learning | Le travail de calcul de dérive est hébergé dans un pipeline Azure Machine Learning. La tâche est déclenchée à la demande ou par planification pour s’exécuter sur un calcul configuré au moment de la création de l’analyse de dérive. |
| Application Insights | La dérive émet des mesures pour Application Insights appartenant à l’espace de travail Machine Learning. |
| Stockage Blob Azure | La dérive émet des métriques au format json vers le stockage d’objets blob Azure. |
Jeux de données de référence et cibles
Vous surveillez les jeux de données Azure Machine Learning pour la dérive de données. Lorsque vous créez une analyse de jeu de données, vous référencez votre :
- Jeu de données de base (généralement le jeu de données d’apprentissage d’un modèle).
- Jeu de données cible (généralement constitué de données d’entrée de modèle) est comparé à votre jeu de données de référence au fil du temps. Cette comparaison signifie que votre jeu de données cible doit comporter une colonne d’horodatage (timestamp).
L’analyse compare les jeux de données de référence et cible.
Migrer vers Model Monitor
Dans Model Monitor, vous trouverez les concepts correspondants comme suit, et vous trouverez plus de détails dans cet article Configurer la supervision des modèles en mettant vos données de production dans Azure Machine Learning :
- Jeu de données de référence : similaire à votre jeu de données de référence pour la détection de dérive de données, il est défini comme le dernier jeu de données d’inférence de production passé.
- Données d’inférence de production : similaires à votre jeu de données cible dans la détection de dérive de données, les données d’inférence de production peuvent être collectées automatiquement à partir de modèles déployés en production. Il peut également s’agir de données d’inférence que vous stockez.
Créer un jeu de données cible
Le jeu de données cible doit avoir la caractéristique timeseries définie sur cette valeur en spécifiant la colonne timestamp à partir d’une colonne de données ou d’une colonne virtuelle dérivée du modèle de chemin d’accès des fichiers. Créez un jeu de données avec timestamp en utilisant le SDK Python ou Azure Machine Learning Studio. Une colonne représentant un « timestamp » doit être spécifiée pour ajouter une caractéristique timeseries au jeu de données. Si vos données sont partitionnées dans une structure de dossiers avec des informations temporelles, telles que « {yyyyyy/MM/dd} », créez une colonne virtuelle via le paramètre de modèle de chemin d’accès et définissez-la comme « timestamp de partition » afin d’activer la fonctionnalité API sur les séries temporelles.
S’APPLIQUE À : SDK Python azureml v1
Dans la classe Dataset, la méthode with_timestamp_columns() définit la colonne date et heure du jeu de données.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Conseil
Pour obtenir un exemple complet d’utilisation de la caractéristique timeseries de jeux de données, consultez l’exemple de notebook ou la documentation du SDK des jeux de données.

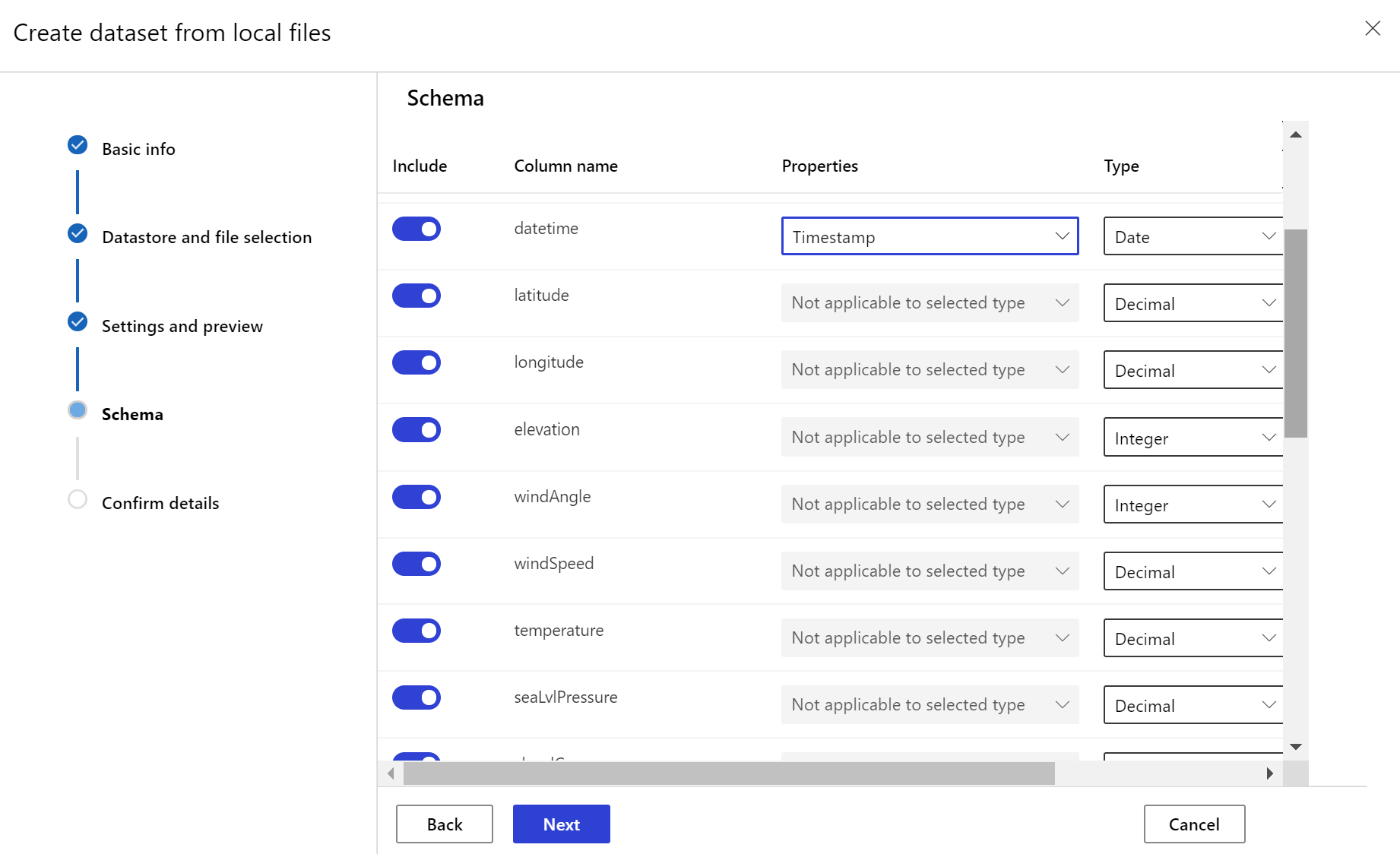
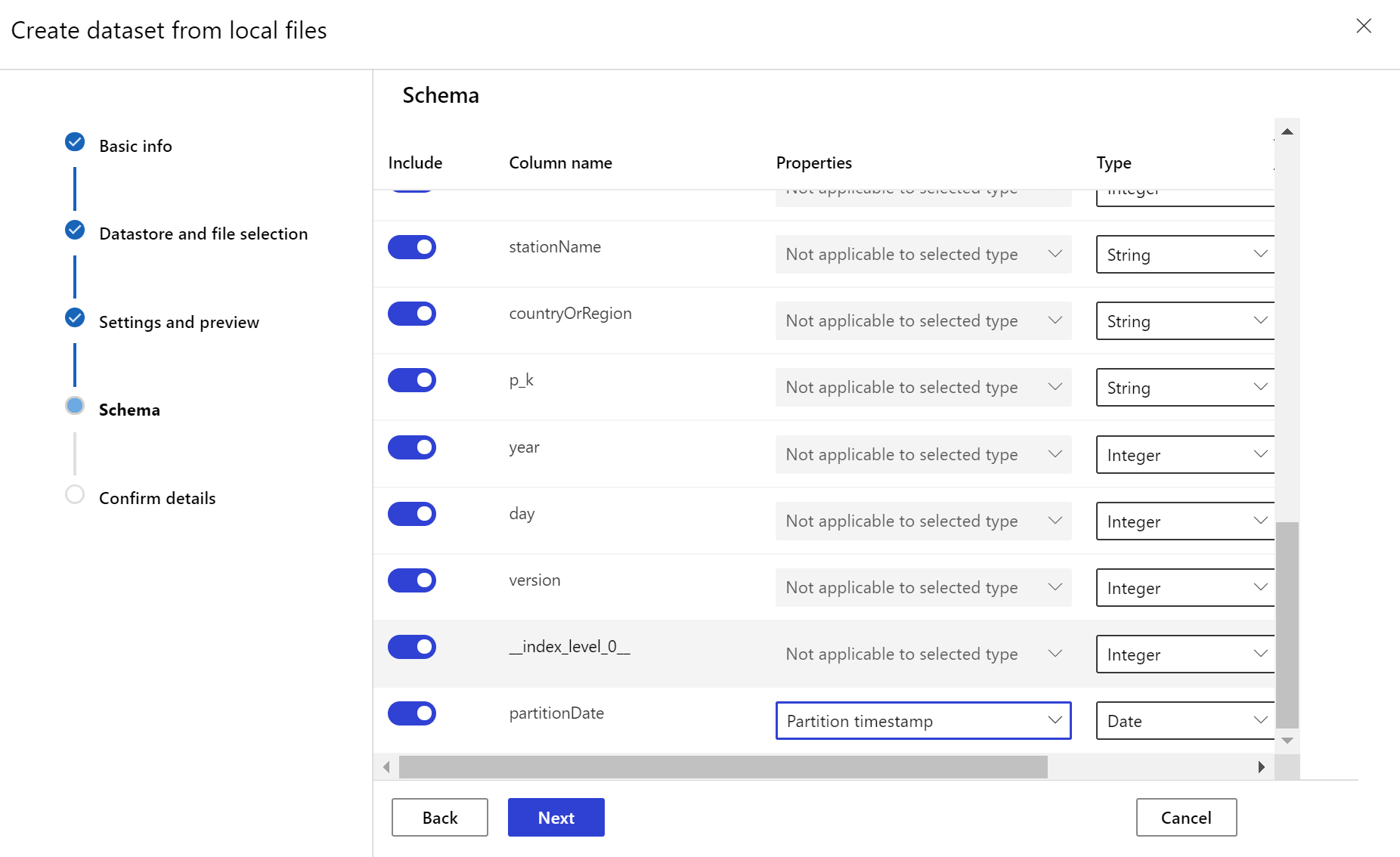
Créer des analyses de jeu de données
Créer des analyses de jeu de données pour détecter et alerter la dérive des données sur un nouveau jeu de données. Pour ce faire, vous pouvez utiliser le SDK Python ou Azure Machine Learning Studio.
Comme décrit plus loin, une analyse de jeu de données s’exécute à des intervalles de fréquence définie (quotidienne, hebdomadaire, mensuelle). L’analyse porte sur les nouvelles données disponibles dans le jeu de données cible depuis sa dernière exécution. Dans certains cas, une telle analyse des données les plus récentes peut être insuffisante :
- Les nouvelles données de la source en amont ont été retardées en raison d’un pipeline de données rompu, et ces nouvelles données n’étaient pas disponibles lors de l’exécution de l’analyse du jeu de données.
- Un jeu de données de série chronologique ne comportait que des données historiques, et vous souhaitez analyser les modèles de dérive dans le jeu de données au fil du temps. Par exemple : comparez le trafic qui circule vers un site web, en hiver et en été, pour identifier les modèles saisonniers.
- Vous débutez avec les analyses de jeux de données. Vous souhaitez évaluer le fonctionnement de la fonctionnalité avec vos données existantes avant de la configurer pour analyser les jours à venir. Dans ces scénarios, vous pouvez envoyer une exécution à la demande, avec une plage de dates de jeu de données cible spécifique, à comparer avec le jeu de données de référence.
La fonction de renvoi exécute un travail de renvoi, pour une plage de dates de début et de fin spécifiée. Un travail de renvoi remplit les points de données manquants attendus dans un jeu de données, afin de garantir l’exactitude et l’exhaustivité des données.
Remarque
La surveillance des modèles Azure Machine Learning ne prend pas en charge la fonction de remplissage manuel, si vous souhaitez rétablir le moniteur de modèle pour un intervalle de temps spécifique, vous pouvez créer un autre moniteur de modèle pour cette plage de temps spécifique.
S’APPLIQUE À : SDK Python azureml v1
La documentation de référence du SDK python sur la dérive des données fournir des informations complètes sur le sujet.
Voici un exemple de création d’un moniteur analyse de jeu de données à l’aide du SDK Python :
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Conseil
Pour obtenir un exemple complet de configuration d’un jeu de données et d’un détecteur de dérive de données timeseries, consultez notre exemple de notebook.
Créer un moniteur de modèle (migrer vers le moniteur de modèle)
Lorsque vous migrez vers Model Monitor, si vous avez déployé votre modèle en production dans un point de terminaison en ligne Azure Machine Learning et activé collecte de données au moment du déploiement, Azure Machine Learning collecte les données d’inférence de production et les stocke automatiquement dans le Stockage Blob Microsoft Azure. Vous pouvez ensuite utiliser la surveillance du modèle Azure Machine Learning pour surveiller en continu ces données d’inférence de production, et vous pouvez choisir directement le modèle pour créer un jeu de données cible (données d’inférence de production dans Model Monitor).
Lorsque vous migrez vers Model Monitor, si vous n’avez pas déployé votre modèle en production dans un point de terminaison en ligne Azure Machine Learning ou que vous ne souhaitez pas utiliser collecte de données, vous pouvez également configurer la surveillance des modèles avec des signaux et des métriques personnalisés.
Les sections suivantes contiennent plus d’informations sur la migration vers le moniteur de modèle.
Créer un moniteur de modèle via des données de production collectées automatiquement (migrer vers le moniteur de modèle)
Si vous avez déployé votre modèle en production dans un point de terminaison en ligne Azure Machine Learning et activé la collecte de données au moment du déploiement.
Vous pouvez utiliser le code suivant pour configurer la surveillance des modèles prête à l’emploi :
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Créer un moniteur de modèle par le biais d’un composant de prétraitement de données personnalisé (Migrer vers Model Monitor)
Lorsque vous migrez vers Model Monitor, si vous n’avez pas déployé votre modèle en production dans un point de terminaison en ligne Azure Machine Learning ou que vous ne souhaitez pas utiliser collecte de données, vous pouvez également configurer la surveillance des modèles avec des signaux et des métriques personnalisés.
Si vous n’avez pas de déploiement, mais que vous avez des données de production, vous pouvez utiliser les données pour effectuer une surveillance des modèles en continu. Pour surveiller ces modèles, vous devez pouvoir :
- Collecter les données d’inférence de production des modèles déployés en production.
- Inscrire les données d’inférence de production en tant que ressource de données Azure Machine Learning et garantir des mises à jour continues des données.
- Fournir un composant de prétraitement des données personnalisé et l’inscrire en tant que composant Azure Machine Learning.
Vous devez fournir un composant de prétraitement des données personnalisé si vos données ne sont pas collectées avec le collecteur de données. Sans ce composant de prétraitement des données personnalisé, le système de surveillance des modèles Azure Machine Learning ne sait pas comment traiter vos données sous forme tabulaire avec prise en charge du fenêtrage temporel.
Votre composant de prétraitement personnalisé doit avoir les signatures d’entrée et de sortie suivantes :
| Entrée/sortie | Nom de la signature | Type | Description | Exemple de valeur |
|---|---|---|---|---|
| input | data_window_start |
littéral, chaîne | heure de début de la fenêtre de données au format ISO8601. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
littéral, chaîne | heure de fin de la fenêtre de données au format ISO8601. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Données d’inférence de production collectées, qui sont inscrites en tant que ressource de données Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Jeu de données tabulaire qui correspond à une partie du schéma de données de référence. |
Pour obtenir un exemple de composant de prétraitement de données personnalisé, consultez custom_preprocessing dans le dépôt GitHub azuremml-examples.
Comprendre les résultats de la dérive des données
Cette section vous montre les résultats de la surveillance d’un jeu de données, qui se trouvent dans la page Jeux de données / Analyseurs de jeu de données dans Azure Studio. Vous pouvez mettre à jour les paramètres et analyser les données existantes pour une période spécifique sur cette page.
Commencez par des insights de haut niveau sur l'ampleur de la dérive des données et un aperçu des caractéristiques à étudier plus en détail.
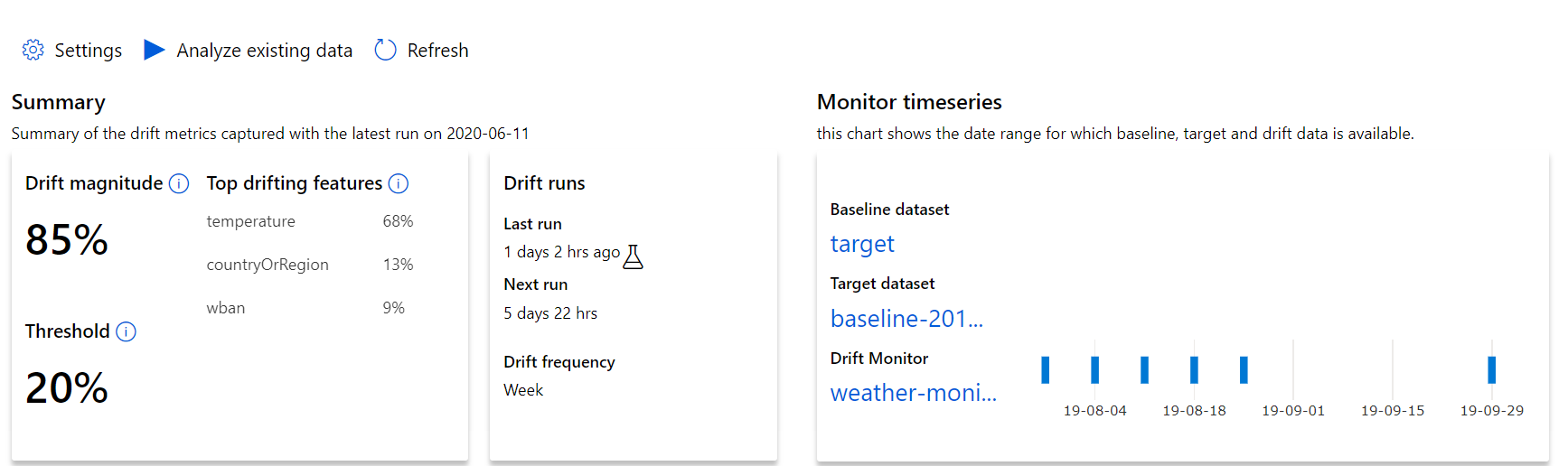
| Métrique | Description |
|---|---|
| Ampleur de la dérive de données | Pourcentage entre la ligne de base et le jeu de données cible au fil du temps. Le pourcentage est compris entre 0 et 100, 0, où 0 indique des jeux de données identiques et 100 indique que le modèle de dérive de données Azure Machine Learning peut distinguer complètement les deux jeux de données. Le bruit est pris en compte dans le calcul du pourcentage de précision en raison des techniques Machine Learning utilisées pour cette amplitude. |
| Caractéristiques ayant le plus dérivé | Liste les caractéristiques du jeu de données présentant la plus forte dérive et contribuant le plus à la métrique d'amplitude de la dérive. En raison de la dérive de la covariable, la distribution sous-jacente d’une fonctionnalité n’a pas nécessairement besoin d’être modifiée pour avoir une importance relativement élevée. |
| Seuil | L’amplitude de la dérive de données au-delà du seuil défini déclenche des alertes. Configurez la valeur de seuil dans les paramètres de l’analyse. |
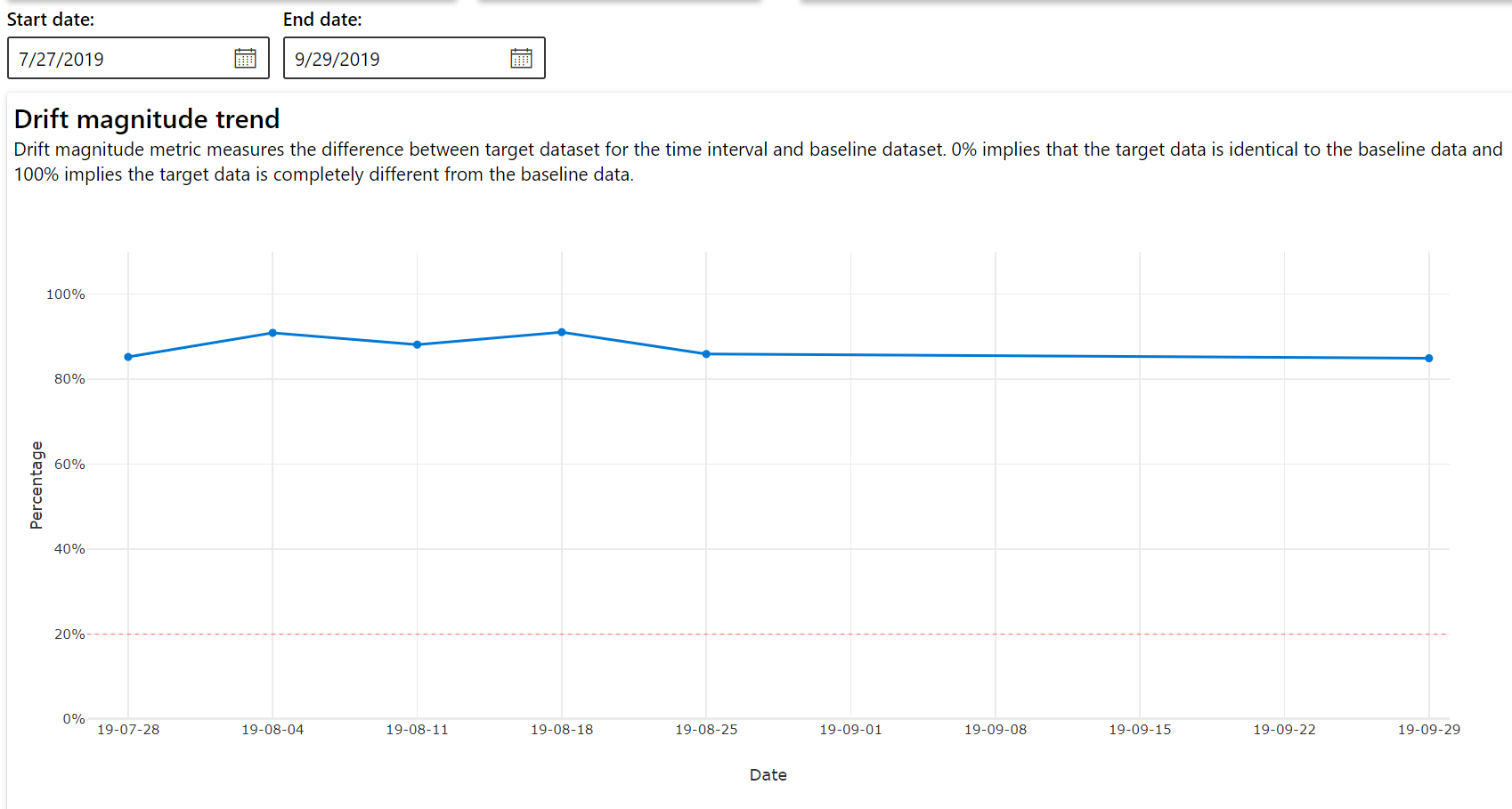
Tendance de l'amplitude de la dérive
Découvrez comment le jeu de données diffère du jeu de données cible au cours de la période spécifiée. Plus on se rapproche des 100 %, plus les deux jeux de données sont différents.
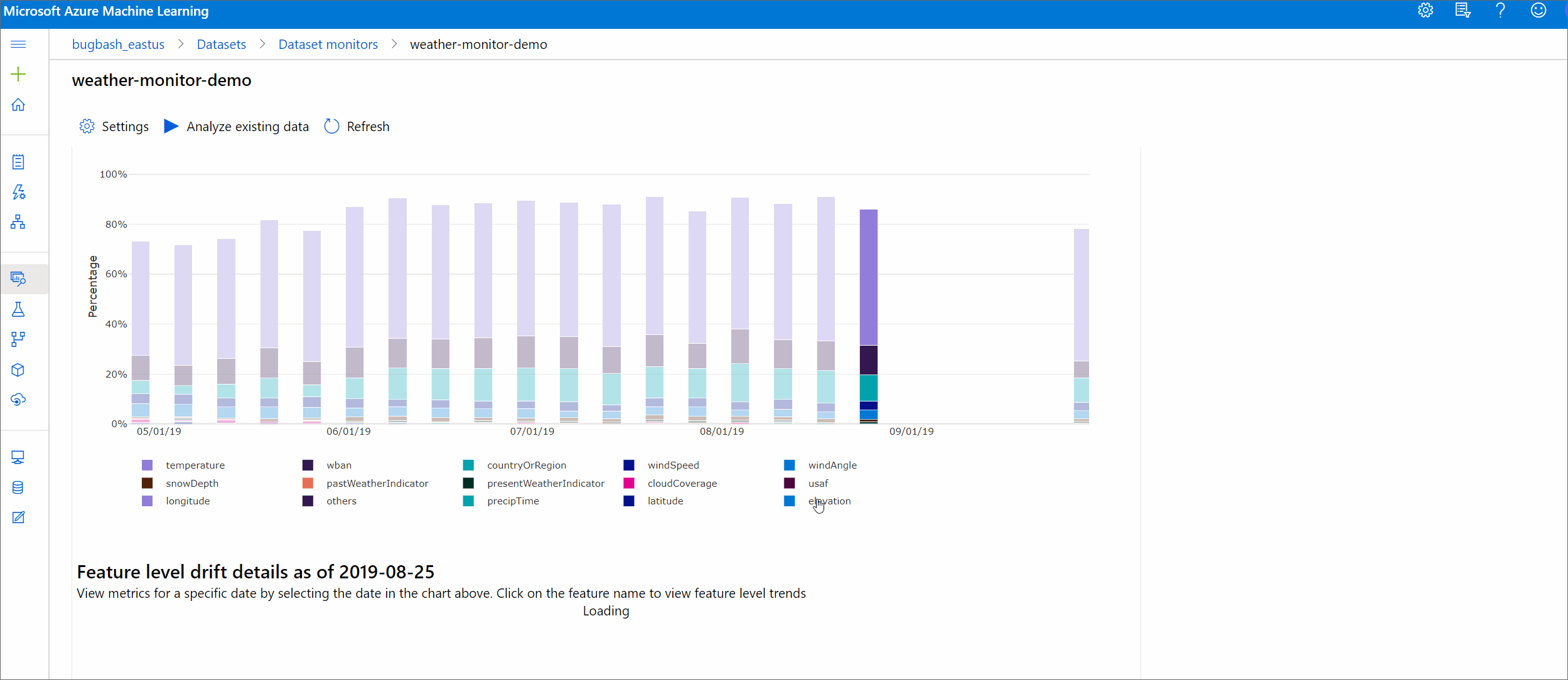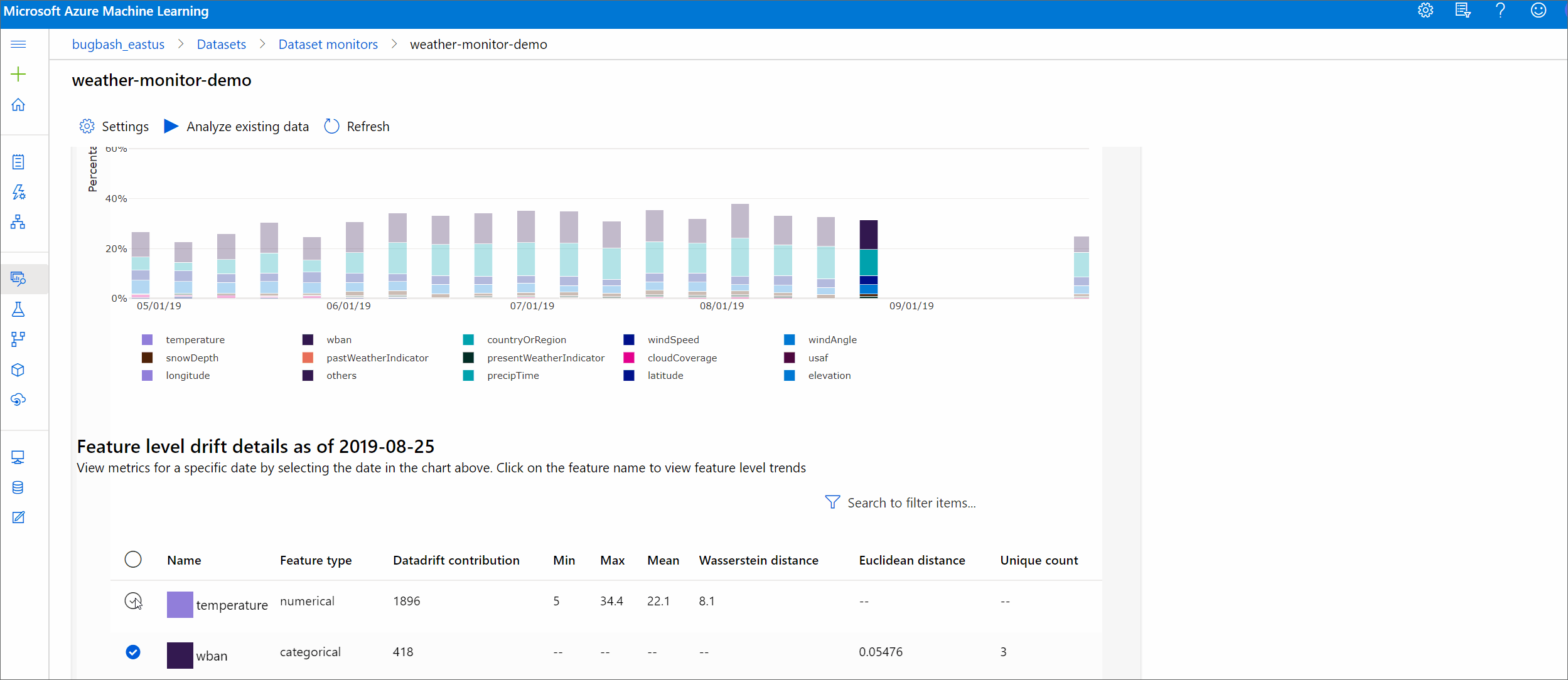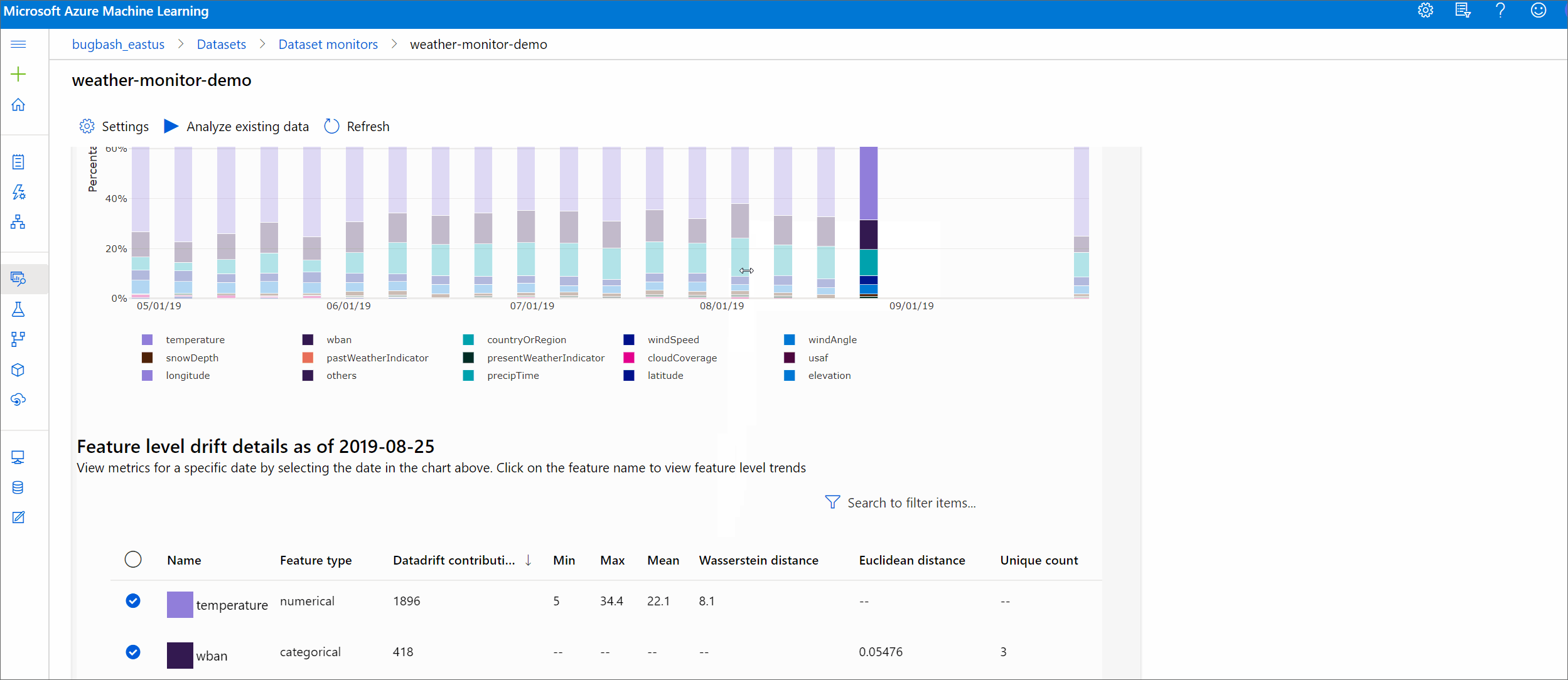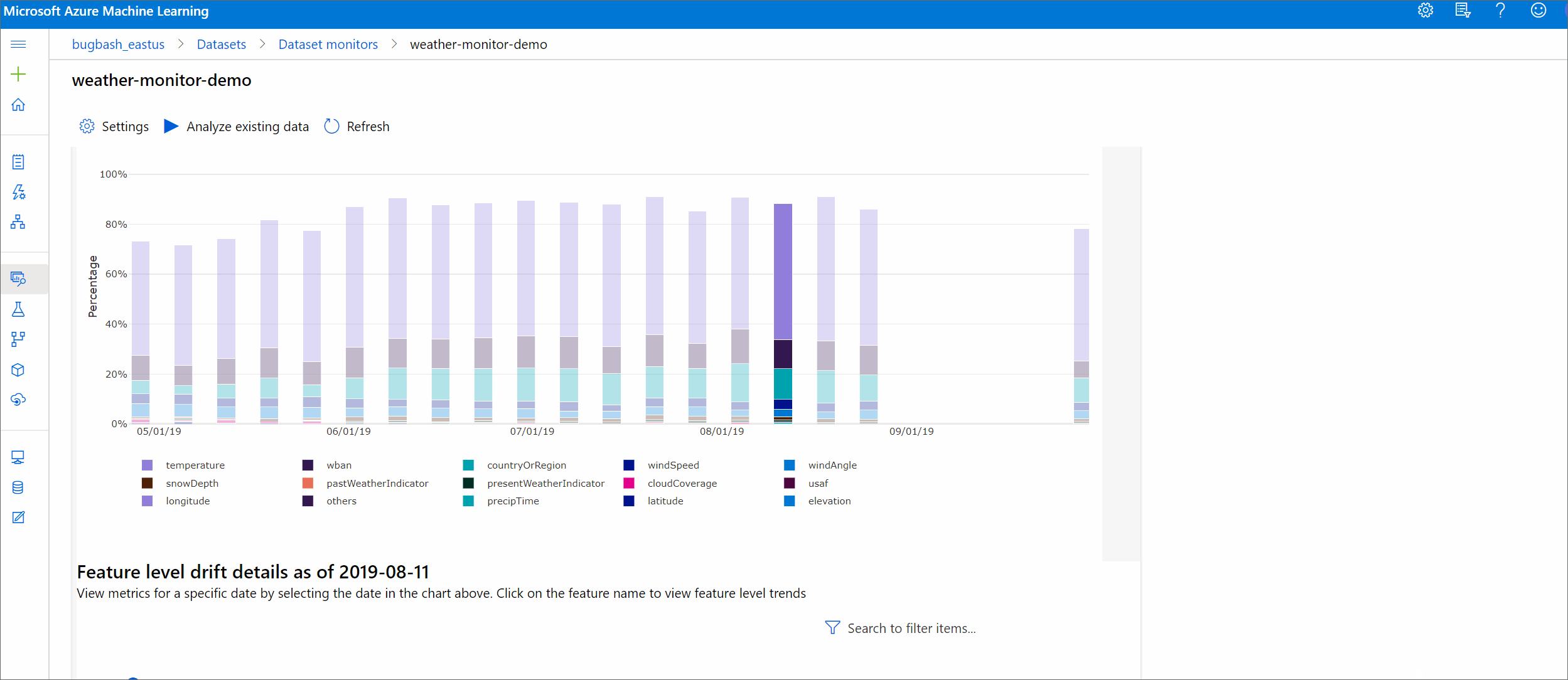
Amplitude de la dérive par caractéristiques
Cette section contient des insights au niveau de la fonctionnalité sur la modification de la distribution de la fonctionnalité sélectionnée, ainsi que d'autres statistiques, au fil du temps.
Le jeu de données cible est également profilé au fil du temps. La distance statistique entre la distribution de ligne de base de chaque fonctionnalité est comparée au fil du jeu de données cible. Conceptuellement, cela ressemble à l’amplitude de la dérive de données. Toutefois, cette distance statistique concerne une fonctionnalité individuelle plutôt que toutes les fonctionnalités. Les valeurs minimum, maximum et moyenne sont également disponibles.
Dans Azure Machine Learning Studio, sélectionnez une barre dans le graphique pour afficher les détails au niveau de la fonctionnalité pour cette date. Par défaut, il affiche la distribution du jeu de données de référence et la distribution de la tâche récente de la même fonctionnalité.
Ces métriques peuvent également être récupérées dans le SDK Python par le biais de la méthode get_metrics() sur un objet DataDriftDetector.
Détails de la caractéristique
Enfin, faites défiler l’écran pour afficher les détails de chaque fonctionnalité. Utilisez les listes déroulantes au-dessus du graphique pour sélectionner la fonctionnalité, puis sélectionnez la métrique que vous souhaitez afficher.
Les mesures dans le graphique dépendent du type de fonctionnalité.
Caractéristiques numériques
Métrique Description Distance Wasserstein Quantité minimale de travail nécessaire à la transformation de la distribution de référence en distribution cible. Valeur moyenne Valeur moyenne de la caractéristique. Valeur minimale Valeur minimale de la caractéristique. Valeur maximale Valeur maximale de la caractéristique. Caractéristiques par catégorie
Métrique Description Distance euclidienne Calculée pour les colonnes catégorielles. La distance euclidienne est calculée sur deux vecteurs, générés à partir de la distribution empirique de la même colonne catégorielle à partir de deux jeux de données. 0 indique qu’il n’y a aucune différence dans les distributions empiriques. Plus la valeur s’éloigne de 0, plus la colonne a dérivé. Les tendances peuvent être observées à partir d’un tracé de série chronologique de cette mesure et peuvent être utiles pour dévoiler une fonction de dérive. Valeurs uniques Nombre de valeurs uniques (cardinalité) de la caractéristique.
Sur ce graphique, sélectionnez une seule date pour comparer la répartition des caractéristiques entre la cible et cette date pour la caractéristique affichée. Pour les caractéristiques numériques, cela montre deux distributions de probabilité. Si la fonctionnalité est numérique, un graphique à barres est affiché.
Métriques, alertes et événements
Les métriques peuvent être interrogées dans la ressource Azure Application Insights associée à votre espace de travail Machine Learning, Vous avez accès à toutes les fonctionnalités d’Application Insights, notamment la configuration de règles d’alerte personnalisées et de groupes d’actions pour déclencher une action, comme une notification E-mail/SMS/Push/Voix ou une fonction Azure. Pour plus d’informations, reportez-vous à la documentation complète d’Application Insights.
Pour commencer, accédez au Portail Azure et sélectionnez la page Vue d’ensemble de votre espace de travail. La ressource Application Insights associée se trouve à l’extrême droite :

Sélectionnez Journaux (analytique) sous Supervision dans le volet gauche :
Les métriques du superviseur de jeu de données sont stockées en tant que customMetrics. Vous pouvez écrire et exécuter une requête après avoir configuré un moniteur de jeu de données pour les visualiser :

Après avoir identifié les métriques pour configurer des règles d’alerte, créez une règle d’alerte :
Vous pouvez utiliser un groupe d’actions existant ou en créer un pour définir l’action à entreprendre quand les conditions définies sont remplies :
Dépannage
Limitations et problèmes connus des superviseurs de dérive de données :
L’intervalle de temps lors de l’analyse des données d’historique est limité à 31 intervalles du paramètre de fréquence du moniteur.
Limitation à 200 caractéristiques sauf si aucune liste de caractéristiques n’est spécifiée (toutes les caractéristiques sont utilisées).
La taille de calcul doit être suffisamment grande pour gérer les données.
Vérifiez que votre jeu de données contient des données comprises entre la date de début et la date de fin pour une tâche d’analyse donnée.
Les analyses de jeu de données ne fonctionnent que sur les jeux de données qui contiennent 50 lignes ou plus.
Dans le jeu de données, les colonnes, ou caractéristiques, sont classées comme catégories ou comme nombres, en fonction des conditions du tableau suivant. Si la caractéristique ne respecte pas ces conditions (par exemple, une colonne de type chaîne avec plus de >100 valeurs uniques), elle est supprimée de notre algorithme de dérive de données, mais elle est toujours profilée.
Type de caractéristique Type de données Condition Limites Par catégorie string Le nombre de valeurs uniques dans la caractéristique est inférieur à 100 et inférieur à 5 % du nombre de lignes. La valeur null est traitée comme sa propre catégorie. Numérique int, float Les valeurs de la caractéristique sont de type de données numérique et ne répondent pas aux conditions d’une caractéristique catégorielle. Caractéristique supprimée si >15 % des valeurs ont la valeur Null. Si vous avez créé une analyse de dérive de données, mais que vous ne voyez pas les données sur la page Analyses de jeux de données dans Azure Machine Learning Studio, essayez les procédures suivantes.
- Vérifiez que vous avez sélectionné la bonne plage de dates en haut de la page.
- Sous l’onglet Analyses des jeux de données, sélectionnez le lien d’expérience pour vérifier l’état de la tâche. Le lien se trouve tout à droite du tableau.
- Si la tâche s’est correctement déroulée, consultez les journaux des pilotes pour connaître le nombre de mesures générées ou voir s’il y a des messages d’avertissement. Vous trouverez les journaux des pilotes sous l’onglet Sortie + journaux après avoir sélectionné une expérience.
Si la fonction
backfill()du SDK ne génère pas le résultat attendu, cela peut être dû à un problème d’authentification. Lorsque vous créez le calcul à transmettre à cette fonction, n’utilisez pasRun.get_context().experiment.workspace.compute_targets. Au lieu de cela, utilisez ServicePrincipalAuthentication comme suit pour créer le calcul que vous transmettez à cette fonctionbackfill():
Remarque
Ne codez pas en dur le mot de passe du principal de service dans votre code. Au lieu de cela, récupérez-le à partir de l’environnement Python, du magasin de clés ou d’une autre méthode sécurisée d’accès aux secrets.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
À partir du collecteur de données du modèle, les données peuvent prendre jusqu’à 10 minutes pour arriver dans votre compte de stockage Blob. Toutefois, cela prend généralement moins de temps. Dans un script ou un notebook, attendez 10 minutes pour vérifier que les cellules ci-dessous s’exécutent.
import time time.sleep(600)
Étapes suivantes
- Pour configurer une analyse de jeu de données, accédez à Azure Machine Learning studio ou au notebook Python.
- Découvrez comment configurer la dérive de données sur les modèles déployés sur Azure Kubernetes Service.
- Configurez des superviseurs de dérive de jeu de données avec Azure Event Grid.