Utiliser le tableau de bord d’IA responsable dans Azure Machine Learning studio
Les tableaux de bord Intelligence artificielle responsable sont liés à vos modèles inscrits. Pour afficher votre tableau de bord Intelligence artificielle responsable, accédez à votre registre de modèles et sélectionnez le modèle inscrit pour lequel vous avez généré un tableau de bord Intelligence artificielle responsable. Ensuite, sélectionnez l’onglet IA responsable pour voir la liste des tableaux de bord générés.

Vous pouvez configurer plusieurs tableaux de bord et les attacher à votre modèle inscrit. Diverses combinaisons de composants (interprétabilité, analyse des erreurs, analyse causale, etc.) peuvent être attachées à chaque tableau de bord IA responsable. L’image suivante présente la personnalisation d’un tableau de bord et les composants qui ont été générés dans celui-ci. Dans chaque tableau de bord, vous pouvez afficher ou masquer différents composants dans l’interface utilisateur du tableau de bord.

Sélectionnez le nom du tableau de bord pour l’ouvrir en plein écran dans votre navigateur. Pour revenir à votre liste de tableaux de bord, vous pouvez sélectionner Retour aux détails du modèle à tout moment.

Fonctionnalités complètes avec une ressource de calcul intégrée
Certaines fonctionnalités du tableau de bord IA responsable nécessitent un calcul dynamique, à la volée et en temps réel (par exemple, analyse de simulation). Si vous ne connectez pas une ressource de calcul au tableau de bord, il se peut que vous constatiez que certaines fonctionnalités sont manquantes. La connexion à une ressource de calcul vous permet de disposer de l’ensemble des fonctionnalités de votre tableau de bord IA responsable pour les composants suivants :
- Analyse des erreurs
- La définition de votre cohorte globale de données sur n’importe quelle cohorte d’intérêt met à jour l’arborescence d’erreurs au lieu de la désactiver.
- La sélection d’autres métriques d’erreur ou de performances est prise en charge.
- La sélection d’un sous-ensemble de caractéristiques pour la formation du mappage d’arborescence des erreurs est prise en charge.
- Il est possible de modifier le nombre minimal d'échantillons requis par nœud terminal et la profondeur de l'arborescence des erreurs.
- La mise à jour dynamique de la carte thermique pour un maximum de deux caractéristiques est prise en charge.
- Importance de la fonctionnalité
- Un tracé des attentes conditionnelles individuelles (ICE) sous l’onglet Importance des caractéristiques individuelles est pris en charge.
- Scénarios de simulation
- La génération d’un nouveau point de données de scénario de simulation pour comprendre le changement minimal requis pour le résultat souhaité est prise en charge.
- Analyse causale
- Sélection d’un point de données individuel, perturbation de ses caractéristiques de traitement et affichage du résultat causatif attendu du scénario de simulation pris en charge (uniquement pour les scénarios d’apprentissage automatique par régression).
Vous trouverez également ces informations sur la page du tableau de bord IA responsable en sélectionnant l’icône Informations, comme illustré dans l’image suivante :

Activer la fonctionnalité complète du tableau de bord IA responsable
Sélectionnez une instance de calcul en cours d’exécution dans la liste déroulante Calcul en haut du tableau de bord. Si vous n’avez pas de calcul en cours d’exécution, créez une instance de calcul en sélectionnant le signe plus (+) en regard de la liste déroulante. Vous pouvez également sélectionner le bouton Démarrer le calcul pour démarrer une instance de calcul arrêtée. La création ou le démarrage d’une instance de calcul peuvent prendre quelques minutes.

Une fois le calcul à l’état En cours d’exécution, votre tableau de bord IA responsable commence à se connecter à l’instance de calcul. Pour ce faire, un processus de terminal est créé sur l’instance de calcul sélectionnée, et le point de terminaison IA responsable est démarré sur le terminal. Sélectionnez Afficher les sorties du terminal pour afficher le processus de terminal actuel.

Lorsque votre tableau de bord Intelligence artificielle responsable est connecté à l’instance de calcul, vous voyez une barre de messages verte et le tableau de bord est désormais entièrement fonctionnel.

Si le processus prend du temps et que votre tableau de bord IA responsable n’est toujours pas connecté à l’instance de calcul, ou si une barre de messages d’erreur rouge s’affiche, cela indique l’existence de problèmes liés au démarrage de votre point de terminaison IA responsable. Sélectionnez Afficher les sorties terminales et faites défiler vers le bas pour afficher le message d’erreur.

Si vous avez du mal à déterminer comment résoudre le problème d’échec de connexion à l’instance de calcul, sélectionnez l’icône Sourire en haut à droite. Faites-nous par de vos commentaires sur tout problème ou erreur que vous rencontrez. Vous pouvez inclure une capture d’écran et votre adresse e-mail dans le formulaire de commentaire.




Vue d’ensemble de l’interface utilisateur du tableau de bord Intelligence artificielle responsable
Le tableau de bord IA responsable comprend un ensemble robuste et riche de visualisations et de fonctionnalités pour vous aider à analyser votre modèle Machine Learning ou à prendre des décisions pilotées par des données :
- Contrôles globaux
- Analyse des erreurs
- Vue d’ensemble du modèle et métriques d’impartialité
- Analyse de données
- Importance de caractéristique (explications de modèles)
- Scénarios de simulation
- Analyse causale
Contrôles globaux
En haut du tableau de bord, vous pouvez créer des cohortes (sous-groupes de points de données partageant des caractéristiques spécifiées) sur lesquelles concentrer votre analyse dans chaque composant. Le nom de la cohorte actuellement appliquée au tableau de bord est toujours affiché en haut à gauche de votre tableau de bord. L’affichage par défaut dans votre tableau de bord est votre jeu de données entier, intitulé Toutes les données (par défaut).

- Paramètres de cohorte : vous permet d’afficher et de modifier les détails de chaque cohorte dans un panneau latéral.
- Configuration du tableau de bord : vous permet d’afficher et de modifier la disposition du tableau de bord global dans un panneau latéral.
- Changer de cohorte : vous permet de sélectionner une autre cohorte et d’afficher ses statistiques dans une fenêtre contextuelle.
- Nouvelle cohorte : vous permet de créer et d’ajouter une nouvelle cohorte à votre tableau de bord.
Sélectionnez Paramètres de cohorte pour ouvrir un panneau avec la liste de vos cohortes, où vous pouvez créer, modifier, dupliquer ou supprimer des cohortes.

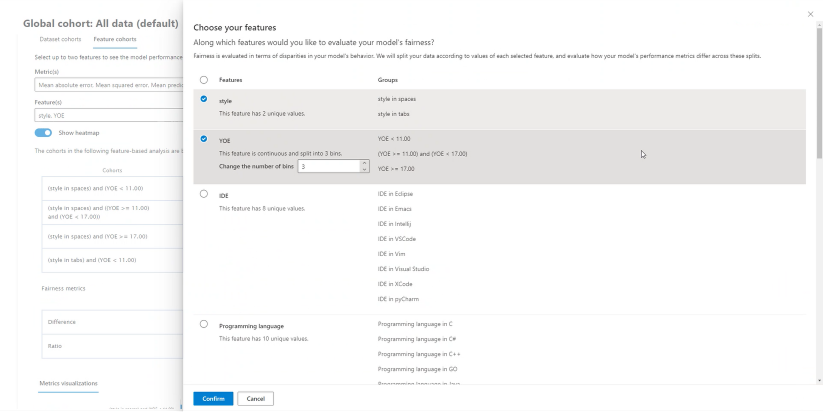
Sélectionnez Nouvelle cohorte en haut du tableau de bord ou dans Paramètres de cohorte afin d’ouvrir un nouveau panneau avec des options pour filtrer sur les critères suivants :
- Index : filtre sur la position du point de données dans le jeu de données complet.
- Jeu de données : filtre sur la valeur d’une caractéristique particulière dans le jeu de données.
- Valeur Y prédite : filtre sur la prédiction effectuée par le modèle.
- Y réel : filtre sur la valeur réelle de la caractéristique cible.
- Erreur (régression) : filtre sur une erreur (ou Résultat de classification (classification) : filtre sur le type et la précision de la classification).
- Valeurs catégorielles : filtre sur une liste de valeurs qui doivent être incluses.
- Valeurs numériques : filtre sur une opération booléenne sur les valeurs (par exemple, sélectionner les points de données où l’âge est < 64).

Vous pouvez nommer votre nouvelle cohorte de jeux de données, sélectionner Ajouter un filtre pour ajouter chaque filtre à utiliser, puis effectuer l’une des opérations suivantes :
- Sélectionner Enregistrer pour enregistrer la nouvelle cohorte dans votre liste de cohortes.
- Sélectionner Enregistrer et basculer pour enregistrer la nouvelle cohorte et basculer immédiatement la cohorte globale du tableau de bord vers la nouvelle cohorte.

Sélectionnez Configuration du tableau de bord pour ouvrir un panneau contenant la liste des composants que vous avez configurés sur votre tableau de bord. Vous pouvez masquer des composants sur votre tableau de bord en sélectionnant l’icône Corbeille, comme illustré dans l’image suivante :

Vous pouvez rajouter des composants à votre tableau de bord via l’icône circulaire signe plus (+) de couleur bleue dans le séparateur entre chaque composant, comme illustré dans l’image suivante :

Analyse des erreurs
Les sections suivantes expliquent comment interpréter et utiliser des arborescences et des cartes thermiques d’erreurs.
Mappage d’arborescence des erreurs
Le premier volet du composant d’analyse des erreurs est une arborescence qui illustre la répartition de l’échec du modèle entre diverses cohortes avec une visualisation d’arborescence. Sélectionnez n’importe quel nœud pour afficher le chemin de prédiction sur vos caractéristiques où une erreur a été trouvée.

- Vue Carte thermique : bascule vers une visualisation sous la forme d’une carte thermique de la distribution des erreurs.
- Liste des caractéristiques : vous permet de modifier les caractéristiques utilisées dans la carte thermique à l’aide d’un panneau latéral.
- Couverture des erreurs : affiche le pourcentage de toutes les erreurs dans le jeu de données concentré dans le nœud sélectionné.
- Erreur (régression) ou Taux d’erreur (classification) : affiche l’erreur ou le pourcentage d’échecs de tous les points de données du nœud sélectionné.
- Nœud : représente une cohorte du jeu de données, potentiellement avec des filtres appliqués, et le nombre d’erreurs sur le nombre total de points de données dans la cohorte.
- Ligne de remplissage : visualise la distribution de points de données dans des cohortes enfants en fonction des filtres, avec le nombre de points de données représentés par l’épaisseur de ligne.
- Informations de sélection : contient des informations sur le nœud sélectionné dans un panneau latéral.
- Enregistrer en tant que nouvelle cohorte : crée une cohorte avec les filtres spécifiés.
- Instances dans la cohorte de base : affiche le nombre total de points dans l’ensemble du jeu de données et le nombre de points correctement et incorrectement prédits.
- Instances dans la cohorte sélectionnée : affiche le nombre total de points dans le nœud sélectionné et le nombre de points correctement et incorrectement prédits.
- Chemin de prédiction (filtres) : répertorie les filtres placés sur le jeu de données complet pour créer cette cohorte plus petite.
Sélectionnez le bouton Liste des caractéristiques pour ouvrir un panneau latéral à partir duquel vous pouvez ré-effectuer l’apprentissage de l’arborescence d’erreurs sur des caractéristiques spécifiques.

- Caractéristiques de recherche : vous permet de trouver des caractéristiques spécifiques dans le jeu de données.
- Caractéristiques : répertorie le nom de la caractéristique dans le jeu de données.
- Importances : guide pratique pour savoir comment la caractéristique peut être liée à l’erreur. Calculé par le biais d’un score de l’information mutuelle entre la caractéristique et l’erreur sur les étiquettes. Vous pouvez utiliser ce score pour vous aider à choisir les caractéristiques à choisir dans l’analyse des erreurs.
- Coche : vous permet d’ajouter ou de supprimer la caractéristique dans l’arborescence.
- Profondeur maximale : profondeur maximale de l’arborescence de substitution entraînée sur les erreurs.
- Nombre de terminaux : nombre de terminaux de l’arbre de substitution entraîné sur les erreurs.
- Nombre minimal d’échantillons dans un terminal : nombre minimal de données requises pour créer un nœud terminal.
Carte thermique des erreurs
Sélectionnez l’onglet Carte thermique pour basculer vers une vue différente de l’erreur dans le jeu de données. Vous pouvez sélectionner une ou plusieurs cellules de carte thermique et créer des cohortes. Vous pouvez choisir jusqu’à deux caractéristiques pour créer une carte thermique.

- Cellules : affiche le nombre de cellules sélectionnées.
- Couverture des erreurs : affiche le pourcentage de toutes les erreurs concentrées dans les cellules sélectionnées.
- Taux d’erreur : affiche le pourcentage d’échecs de tous les points de données dans les cellules sélectionnées.
- Caractéristiques de l’axe : sélectionne l’intersection des caractéristiques à afficher dans la carte thermique.
- Cellules : représente une cohorte du jeu de données, avec des filtres appliqués, et le pourcentage d’erreurs sur le nombre total de points de données dans la cohorte. Un contour bleu indique les cellules sélectionnées et l’obscurité du rouge représente la concentration d’échecs.
- Chemin de prédiction (filtres) : répertorie les filtres placés sur le jeu de données complet pour chaque cohorte sélectionnée.
Vue d’ensemble du modèle et métriques d’impartialité
Le composant Vue d’ensemble du modèle fournit un ensemble complet de métriques de performances et d’équité pour évaluer votre modèle, ainsi que des métriques clés de disparité des performances avec les caractéristiques et les cohortes de jeux de données spécifiées.
Cohortes d'ensembles de données
Le volet Cohortes de jeux de données vous permet d’examiner votre modèle en comparant les performances de celui-ci avec diverses cohortes de jeux de données spécifiées par l’utilisateur (accessible via l’icône Paramètres de cohorte en haut à droite du tableau de bord).

- Aidez-moi à choisir des métriques : sélectionnez cette icône pour ouvrir un panneau contenant plus d’informations sur les métriques de performances du modèle disponibles pour affichage dans le tableau. Ajustez facilement les métriques à afficher en utilisant la liste déroulante multisélection pour sélectionner et désélectionner des métriques de performances.
- Afficher la carte thermique : activez ou désactivez cette option pour afficher ou masquer la visualisation de carte thermique dans le tableau. Le dégradé de la carte thermique correspond à la plage normalisée entre la valeur la plus basse et la valeur la plus élevée dans chaque colonne.
- Tableau des métriques pour chaque cohorte de jeux de données : affichez les colonnes de cohortes de jeux de données, la taille d’échantillon de chaque cohorte et les métriques de performances du modèle sélectionnées pour chaque cohorte.
- Graphique à barres visualisant des métriques individuelles : affichez l’erreur absolue moyenne dans les cohortes pour faciliter la comparaison.
- Choisir la métrique (axe x) : sélectionnez ce bouton pour choisir les métriques à afficher dans le graphique à barres.
- Choisir les cohortes (axe y) : sélectionnez ce bouton pour choisir les cohortes à afficher dans le graphique à barres. La sélection de Cohorte de caractéristiques peut être désactivée, sauf si vous spécifiez d’abord les caractéristiques souhaitées sous l’onglet Cohorte de caractéristiques du composant.
Sélectionnez Aidez-moi à choisir des métriques pour ouvrir un panneau contenant la liste des métriques de performances de modèle et leurs définitions, qui peut vous aider à sélectionner les métriques appropriées à afficher.
| Scénario d’apprentissage automatique | Mesures |
|---|---|
| régression ; | Erreur absolue moyenne, erreur carrée moyenne, coefficient de détermination, prédiction moyenne. |
| classification ; | Exactitude, précision, rappel, score F1, taux de faux positifs, taux de faux négatifs, taux de sélection. |
Cohortes de caractéristiques
Le volet Cohortes de caractéristiques vous permet d’examiner votre modèle en comparant les performances de celui-ci entre les caractéristiques sensibles et non sensibles spécifiées par l’utilisateur (par exemple, les performances entre diverses cohortes de genre, de race et de niveau de revenu).

Aidez-moi à choisir des métriques : sélectionnez cette icône pour ouvrir un panneau contenant plus d’informations sur les métriques disponibles pour affichage dans le tableau. Ajustez facilement les métriques à afficher en utilisant la liste déroulante multisélection pour sélectionner et désélectionner des métriques de performances.
Aidez-moi à choisir des caractéristiques : sélectionnez cette icône pour ouvrir un panneau contenant plus d’informations sur les caractéristiques disponibles dans le tableau, avec des descripteurs de chaque caractéristique et de sa capacité de compartimentage (voir ci-dessous). Ajustez facilement les caractéristiques que vous pouvez afficher à l’aide de la liste déroulante multisélection permettant de les sélectionner et désélectionner.
Afficher la carte thermique : activez/désactivez cette option pour afficher une visualisation de carte thermique. Le dégradé de la carte thermique correspond à la plage normalisée entre la valeur la plus basse et la valeur la plus élevée dans chaque colonne.
Tableau des métriques pour chaque cohorte de caractéristiques : tableau avec des colonnes pour les cohortes de caractéristiques (sous-cohorte de votre caractéristique sélectionnée), taille d’échantillon de chaque cohorte et métriques de performances du modèle sélectionné pour chaque cohorte de caractéristiques.
Métriques d’impartialité/métriques de disparité : tableau qui correspond au tableau des métriques et affiche la différence maximale ou le ratio maximal dans les scores de performances entre deux cohortes de caractéristiques.
Graphique à barres visualisant des métriques individuelles : affichez l’erreur absolue moyenne dans les cohortes pour faciliter la comparaison.
Choisir les cohortes (axe y) : sélectionnez ce bouton pour choisir les cohortes à afficher dans le graphique à barres.
La sélection de Choisir des cohortes a pour effet d’ouvrir un panneau avec une option permettant d’afficher une comparaison des cohortes de jeux de données sélectionnées ou des cohortes de caractéristiques en fonction de ce que vous sélectionnez dans la liste déroulante multisélection en dessous. Sélectionnez Confirmer pour enregistrer les modifications apportées à l’affichage du graphique à barres.
Choisir la métrique (axe x) : sélectionnez ce bouton pour choisir les métriques à afficher dans le graphique à barres.


Analyse des données
Avec le composant d’analyse de données, le volet Affichage des tables affiche une vue tabulaire de votre jeu de données pour toutes les caractéristiques et lignes.
Le panneau Mode graphique affiche des tracés agrégés et individuels de points de données. Vous pouvez analyser les statistiques de données le long des axes x et y à l’aide de filtres tels que des résultats prédits, des caractéristiques de jeu de données et des groupes d’erreurs. Cette vue vous aide à comprendre une surreprésentation et une sous-représentation dans votre jeu de données.

Sélectionner une cohorte de jeux de données à explorer : spécifiez la cohorte de jeux de données dans votre liste de cohortes pour lesquelles vous souhaitez afficher les statistiques de données.
Axe X : affiche le type de la valeur tracée horizontalement. Modifiez les valeurs en sélectionnant le bouton pour ouvrir un panneau latéral.
Axe Y : affiche le type de la valeur tracée verticalement. Modifiez les valeurs en sélectionnant le bouton pour ouvrir un panneau latéral.
Type de graphique : spécifie le type de graphique. Choisissez entre des tracés agrégés (graphiques à barres) ou des points de données individuels (nuage de points).
La sélection de l’option Points de données individuels sous Type de graphique vous fait passer à une vue désagrégée des données avec la disponibilité d’un axe de couleurs.

Importance des caractéristiques (explications des modèles)
Le composant d’explication de modèle vous permet de voir quelles caractéristiques étaient les plus importantes dans les prédictions de votre modèle. Vous pouvez afficher les caractéristiques qui ont globalement affecté la prédiction de votre modèle dans le volet Importance des caractéristiques agrégées, ou afficher les importances des caractéristiques pour des points de données individuels dans le volet Importance des caractéristiques individuelles.
Importances des caractéristiques agrégées (explications globales)

Top K des caractéristiques : répertorie les caractéristiques globales les plus importantes pour une prédiction et vous permet de la modifier via une barre de curseur.
Importance des caractéristiques agrégées : visualise le poids de chaque caractéristique dans l’influence des décisions de modèle sur toutes les prédictions.
Trier par : vous permet de sélectionner les importances de la cohorte en fonction desquelles trier le graphique d’importance des caractéristiques agrégées.
Type de graphique : vous permet de choisir entre un affichage sous forme de graphique à barres des importances moyennes pour chaque caractéristique et un diagramme à surfaces des importance pour toutes les données.
Lorsque vous sélectionnez l’une des caractéristiques dans le graphique à barres, le tracé de dépendance est rempli, comme illustré dans l’image suivante. Le tracé de dépendance montre la relation entre les valeurs d’une caractéristique et ses valeurs d’importance de caractéristique correspondantes affectant la prédiction du modèle.

Importance des caractéristiques de [caractéristique] (régression) ou Importance des caractéristiques de [caractéristique] sur [classe prédite] (classification) : trace l’importance d’une caractéristique particulière dans les prédictions. Pour les scénarios de régression, les valeurs d’importance sont en termes de résultat, donc l’importance positive des caractéristiques signifie qu’elle a contribué positivement au résultat. L’inverse s’applique à l’importance négative des caractéristiques. Pour les scénarios de classification, des importances positives des caractéristiques signifient que la valeur de la caractéristique contribue à la classe prédite indiquée dans le titre de l’axe Y. L’importance négative des caractéristiques signifie qu’elle agit à l’encontre de la classe prédite.
Afficher le tracé de dépendance pour : sélectionne la caractéristique dont vous souhaitez tracer les importances.
Sélectionner une cohorte de jeux de données : sélectionne la cohorte dont vous souhaitez tracer les importances.

Importances individuelles des caractéristiques (explications locales)
L’image suivante montre comment les caractéristiques influencent les prédictions effectuées sur des points de données spécifiques. Vous pouvez choisir jusqu’à cinq points de données pour lesquels comparer les importances des caractéristiques.

Tableau de sélection de points : affichez vos points de données et sélectionnez jusqu’à cinq points à afficher dans le tracé d’importance des caractéristiques ou le tracé ICE sous le tableau.

Tracé d’importance des caractéristiques : graphique à barres de l’importance de chaque caractéristique pour la prédiction du modèle sur les points de données sélectionnés.
- Top k des caractéristiques : vous permet de spécifier le nombre de caractéristiques pour lesquelles montrer les importances à l’aide d’un curseur.
- Trier par : vous permet de sélectionner le point (de ceux cochés ci-dessus) dont les importances des caractéristiques sont affichées dans l’ordre décroissant sur le tracé d’importance des caractéristiques.
- Afficher les valeurs absolues : activez/désactivez cette option pour trier le graphique à barres sur les valeurs absolues. Cela vous permet de voir les caractéristiques les plus impactantes, que leur direction soit positive ou négative.
- Graphique à barres : affiche l’importance de chaque caractéristique dans le jeu de données pour la prédiction de modèle des points de données sélectionnés.
Tracé d’attente conditionnelle individuelle (ICE) : bascule vers le tracé ICE montrant les prédictions de modèle sur une plage de valeurs d’une caractéristique particulière.

- Min (caractéristiques numériques) : spécifie la limite inférieure de la plage de prédictions dans le tracé ICE.
- Max (caractéristiques numériques) : spécifie la limite supérieure de la plage de prédictions dans le tracé ICE.
- Étapes (caractéristiques numériques) : spécifie le nombre de points pour lesquels afficher les prédictions dans l’intervalle.
- Valeurs des caractéristiques (caractéristiques catégorielles) : spécifie les valeurs de caractéristiques catégorielles pour lesquelles afficher les prédictions.
- Caractéristique : spécifie la caractéristique pour laquelle effectuer des prédictions.
Scénarios de simulation
L’analyse de scénario fournit un ensemble diversifié d’exemples de simulation générés par la modification minimale des valeurs de caractéristiques pour produire la classe (classification) ou la plage (régression) de prédiction souhaitée.

Sélection de point : sélectionne le point pour lequel créer un contrefactuel, et sous lequel afficher dans le tracé des caractéristiques les mieux classées.

Tracé des caractéristiques les mieux classées : affiche, dans l’ordre décroissant de fréquence moyenne, les caractéristiques à perturber pour créer un ensemble diversifié de scénarios de la classe souhaitée. Vous devez générer au moins 10 scénarios différents par point de données pour activer ce graphique, en raison du manque de précision avec un nombre inférieur de contrefactuels.
Point de données sélectionné : effectue la même action que la sélection de point dans le tableau, sauf dans un menu déroulant.
Classe souhaitée pour les scénarios : spécifie la classe ou la plage pour laquelle générer des scénarios.
Créer un scénario de simulation : ouvre un panneau pour la création de points de données de scénario de simulation.
Sélectionnez le bouton Créer un scénario de simulation pour ouvrir un panneau de fenêtre complète.

Caractéristiques de recherche : recherche les caractéristiques permettant d’observer et de modifier les valeurs.
Trier les scénarios par caractéristiques classées : trie les exemples de scénario dans l’ordre d’effet de perturbation. (Voir également Tracé des caractéristiques les mieux classées, abordé précédemment.)
Exemples de scénarios : répertorie les valeurs de caractéristiques d’exemples de scénarios avec la classe ou la plage souhaitée. La première ligne est le point de données de référence d’origine. Sélectionnez Définir la valeur pour définir toutes les valeurs de votre propre point de données de scénario dans la ligne inférieure avec les valeurs de l’exemple de scénario pré-généré.
Valeur ou classe prédite : répertorie la prédiction de modèle de la classe d’un scénario en fonction de ces caractéristiques modifiées.
Créer votre propre contrefactuel : vous permet de perturber vos propres caractéristiques pour modifier le contrefactuel. Les caractéristiques qui ont été modifiées par rapport à la valeur d’origine sont indiquées par la mise en gras du titre (par exemple, Employeur et Langage de programmation). Sélectionnez Afficher le delta de prédiction pour afficher la différence dans la nouvelle valeur de prédiction par rapport au point de données d’origine.
Nom du scénario de simulation : vous permet de nommer le scénario de manière unique.
Enregistrer en tant que nouveau point de données : enregistre le scénario que vous avez créé.


Analyse causale
Les sections suivantes expliquent comment lire l’analyse causale de votre jeu de données sur certains traitements spécifiés par l’utilisateur.
Effets causaux agrégés
Sélectionnez l’onglet Effets causaux agrégés du composant Analyse causale pour afficher les effets de causalité moyens pour les caractéristiques de traitement prédéfinies (les caractéristiques que vous souhaitez traiter pour optimiser votre résultat).
Notes
La fonctionnalité de cohorte globale n’est pas prise en charge pour le composant d’analyse causale.

Tableau des effets causaux agrégés directs : affiche l’effet causal de chaque caractéristique agrégée sur l’ensemble du jeu de données et des statistiques de confiance associées.
- Traitements continus : en moyenne dans cet exemple, l’augmentation de cette caractéristique d’une unité entraîne l’augmentation de la probabilité de classe de x unités, où X est l’effet causal.
- Traitements binaires : en moyenne dans cet exemple, l’activation de cette caractéristique entraîne l’augmentation de la probabilité de classe de x unités, où X est l’effet causal.
Tracé direct en boîte à moustaches de l’effet causal agrégé : visualise les effets causaux et les intervalles de confiance des points dans le tableau.
Effets causaux individuels et simulation causale
Pour obtenir une vue granulaire des effets causaux sur un point de données individuel, basculez vers l’onglet Simulation causale individuelle.

- Axe X : sélectionne la caractéristique à tracer sur l’axe x.
- Axe Y : sélectionne la caractéristique à tracer sur l’axe y.
- Nuage de points causal individuel : visualise les points du tableau sous forme de nuage de points pour permettre de sélectionner un point de données pour l’analyse de la simulation causale et l’affichage des effets causaux individuels en-dessous.
- Définir une nouvelle valeur de traitement :
- (numérique) : affiche un curseur pour modifier la valeur de la caractéristique numérique en tant qu’intervention réelle.
- (catégorique) : affiche une liste déroulante pour sélectionner la valeur de la caractéristique catégorielle.
Stratégie de traitement
Sélectionnez l’onglet Stratégie de traitement pour basculer vers un affichage permettant de déterminer les interventions réelles, et de voir les traitements à appliquer pour obtenir un résultat particulier.

Définir la caractéristique de traitement : sélectionne une caractéristique à modifier en tant qu’intervention réelle.
Stratégie de traitement globale recommandée : affiche les interventions recommandées pour les cohortes de données afin d’améliorer la valeur des caractéristiques cibles. Le tableau peut être lu de gauche à droite, où la segmentation du jeu de données se fait d’abord dans les lignes, puis dans les colonnes. Par exemple, pour 658 personnes dont l’employeur n’est pas Snapchat et dont le langage de programmation n’est pas JavaScript, la stratégie de traitement recommandée consiste à augmenter le nombre de référentiels GitHub auxquels contribuer.
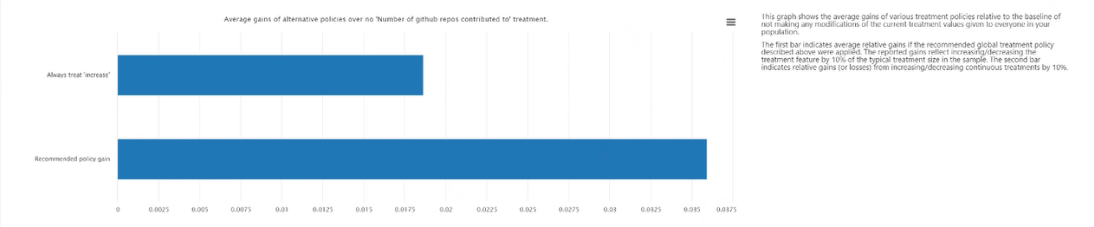
Gains moyens des stratégies alternatives par rapport au traitement consistant à toujours appliquer : trace la valeur de caractéristique cible dans un graphique à barres du gain moyen dans votre résultat pour la stratégie de traitement recommandée ci-dessus par rapport au traitement consistant à toujours appliquer.
Stratégie de traitement individuel recommandée :
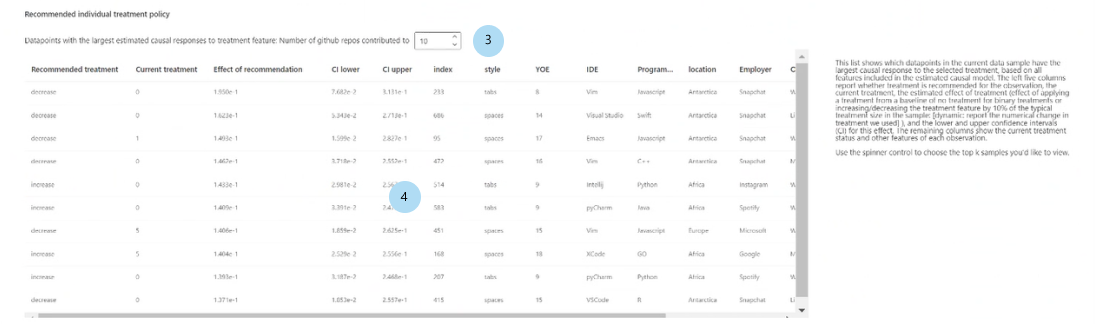
Afficher le top k des exemples de points de données classés par effets causaux pour la caractéristique de traitement recommandée : sélectionne le nombre de points de données à afficher dans le tableau.
Tableau de stratégie de traitement individuel recommandée : répertorie, dans l’ordre décroissant de l’effet causal, les points de données dont les caractéristiques cibles seraient les plus améliorées par une intervention.


Étapes suivantes
- Récapitulez et partagez vos insights d’Intelligence artificielle responsable avec la Carte de performance Intelligence artificielle responsable sous forme d’export PDF.
- En savoir plus sur les concepts et les techniques à la base du tableau de bord Intelligence artificielle responsable.
- Affichez des exemples de notebooks YAML et Python pour générer un tableau de bord Intelligence artificielle responsable avec YAML ou Python.
- Explorez les fonctionnalités du tableau de bord IA responsable via cette démonstration web interactive du Laboratoire d’IA.
- Apprenez-en davantage sur la façon d’utiliser le tableau de bord et la carte de performance d’IA responsable pour déboguer des données et des modèles, et éclairer la prise de décisions dans ce billet de blog de la communauté technique.
- Découvrez comment le tableau de bord et la carte de performance d’IA responsable ont été utilisés par le UK National Health Service (NHS) dans un témoignage client réel.