Soumettre des travaux Spark dans Azure Machine Learning
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Azure Machine Learning prend en charge la soumission de tâches d’apprentissage automatique autonomes et la création de pipelines de Machine Learning, qui impliquent plusieurs étapes de flux de travail de Machine Learning. Azure Machine Learning gère à la fois la création de tâches Spark autonomes et la création de composants Spark réutilisables que les pipelines Azure Machine Learning peuvent utiliser. Cet article vous apprend à soumettre des tâches Spark avec :
- L’interface utilisateur Azure Machine Learning studio
- Interface CLI Azure Machine Learning
- Kit de développement logiciel (SDK) Azure Machine Learning
Pour plus d’informations sur les concepts d’Apache Spark dans Azure Machine Learning, consultez cette ressource.
Prérequis
- INTERFACE DE LIGNE DE COMMANDE
- Kit de développement logiciel (SDK) Python
- Interface utilisateur du studio
S’APPLIQUE À : Extension Azure CLI ml v2 (actuelle)
- Un abonnement Azure : si vous n’en possédez pas, créez un compte gratuit avant de commencer.
- Un espace de travail Azure Machine Learning. Consultez Créer des ressources d’espace de travail pour plus d’informations.
- Créez une instance de calcul Azure Machine Learning.
- Installez le CLI Azure Machine Learning.
- (Facultatif) : Un pool Synapse Spark attaché dans l’espace de travail Azure Machine Learning.
Remarque
- Pour en savoir plus sur l’accès aux ressources lors de l’utilisation du calcul Spark serverless Azure Machine Learning et du pool Synapse Spark attaché, consultez Garantir l’accès aux ressources pour les travaux Spark.
- Azure Machine Learning fournit un pool de quotas partagés à partir duquel tous les utilisateurs peuvent accéder au quota de calcul pour effectuer des tests pendant une période limitée. Lorsque vous utilisez le calcul Spark serverless, Azure Machine Learning vous permet d’accéder à ce quota partagé pendant une courte période.
Attacher une identité managée affectée par l’utilisateur à l’aide de l’interface CLI v2
- Créez un fichier YAML définissant l’identité managée affectée par l’utilisateur, qui doit être attachée à l’espace de travail :
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Avec le paramètre
--file, utilisez le fichier YAML dans la commandeaz ml workspace updatepour joindre l’identité managée affectée par l’utilisateur :az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Attacher une identité managée affectée par l’utilisateur à l’aide de ARMClient
- Installez
ARMClient, un simple outil de ligne de commande qui permet d’appeler l’API Azure Resource Manager. - Créez un fichier JSON définissant l’identité managée affectée par l’utilisateur, qui doit être attachée à l’espace de travail :
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Exécutez la commande suivante dans l’invite PowerShell ou l’invite de commandes pour attacher l’identité managée affectée par l’utilisateur à l’espace de travail.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Remarque
- Pour garantir l’exécution réussie de la tâche Spark, attribuez les rôles Contributeur et Contributeur aux données Blob du stockage, sur le compte de stockage Azure utilisé pour l’entrée et la sortie des données, à l’identité utilisée par la tâche Spark.
- L’accès au réseau public doit être activé dans l’espace de travail Azure Synapse pour garantir la réussite de l’exécution du travail Spark à l’aide d’un pool Synapse Spark attaché.
- Dans un espace de travail Azure Synapse associé à un réseau virtuel managé, si un pool Synapse Spark attaché pointe vers un pool Synapse Spark, vous devez configurer un point de terminaison privé managé sur un compte de stockage, pour garantir l’accès aux données.
- Le calcul Spark serverless prend en charge un réseau virtuel managé Azure Machine Learning. Si un réseau managé est provisionné pour le calcul Spark serverless, les points de terminaison privés correspondants pour le compte de stockage doivent également être provisionnés pour garantir l’accès aux données.
Soumettez un travail Spark autonome
Après avoir apporté les modifications nécessaires pour le paramétrage de script Python, vous pouvez utiliser un script Python développé avec le data wrangling interactif pour envoyer un traitement par lots afin de traiter un plus grand volume de données. Vous pouvez envoyer un traitement par lots de wrangling de données en tant que travail Spark autonome.
Un travail Spark nécessite un script Python qui prend des arguments. Vous pouvez modifier le code Python développé à l’origine à partir du data wrangling interactif pour développer ce script. Un exemple de script Python est présenté ici.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Remarque
Cet exemple de code Python utilise pyspark.pandas. Seul le runtime Spark version 3.2 ou ultérieure le prend en charge.
Ce script ci-dessus prend deux arguments qui transmettent le chemin des données d’entrée et du dossier de sortie, respectivement :
--titanic_data--wrangled_data
S’APPLIQUE À : Extension ml Azure CLI v2 (actuelle)
Pour créer un travail, vous pouvez définir un travail Spark autonome en tant que fichier de spécification YAML, que vous pouvez utiliser dans la commande az ml job create, avec le paramètre --file. Définissez ces propriétés dans le fichier YAML :
Propriétés YAML dans la spécification du travail Spark
type: à définir surspark.code: définit l’emplacement du dossier qui contient les scripts et le code source pour ce travail.entry: définit le point d’entrée du travail ; doit couvrir l’une des propriétés suivantes :file: définit le nom du script Python qui sert de point d’entrée pour le travail.class_name: définit le nom de la classe qui sert de point d’entrée pour le travail.
py_files: définit une liste de fichiers.zip,.eggou.pyà placer dansPYTHONPATHpour réussir l’exécution du travail. Cette propriété est facultative.jars: définit une liste de fichiers.jarà inclure dans le pilote Spark et l’exécuteurCLASSPATHpour réussir l’exécution du travail. Cette propriété est facultative.files: définit une liste de fichiers à copier dans le répertoire de travail de chaque exécuteur pour réussir l’exécution du travail. Cette propriété est facultative.archives: définit une liste d’archives à extraire dans le répertoire de travail de chaque exécuteur pour réussir l’exécution du travail. Cette propriété est facultative.conf: définit les propriétés de pilote et d’exécuteur Spark suivantes :spark.driver.cores: nombre de cœurs pour le pilote Spark.spark.driver.memory: mémoire allouée au pilote Spark, en Go (gigaoctets).spark.executor.cores: nombre de cœurs pour l’exécuteur Spark.spark.executor.memory: allocation de mémoire pour l’exécuteur Spark, en Go (gigaoctets).spark.dynamicAllocation.enabled: valeurTrueouFalseindiquant si les exécuteurs doivent être alloués dynamiquement ou non.- Si l’allocation dynamique des exécuteurs est activée, définissez ces propriétés :
spark.dynamicAllocation.minExecutors: nombre minimal d’instances d’exécuteurs Spark pour l’allocation dynamique.spark.dynamicAllocation.maxExecutors: nombre maximal d’instances d’exécuteurs Spark pour l’allocation dynamique.
- Si l’allocation dynamique d’exécuteurs est désactivée, définissez cette propriété :
spark.executor.instances: nombre d’instances d’exécuteur Spark.
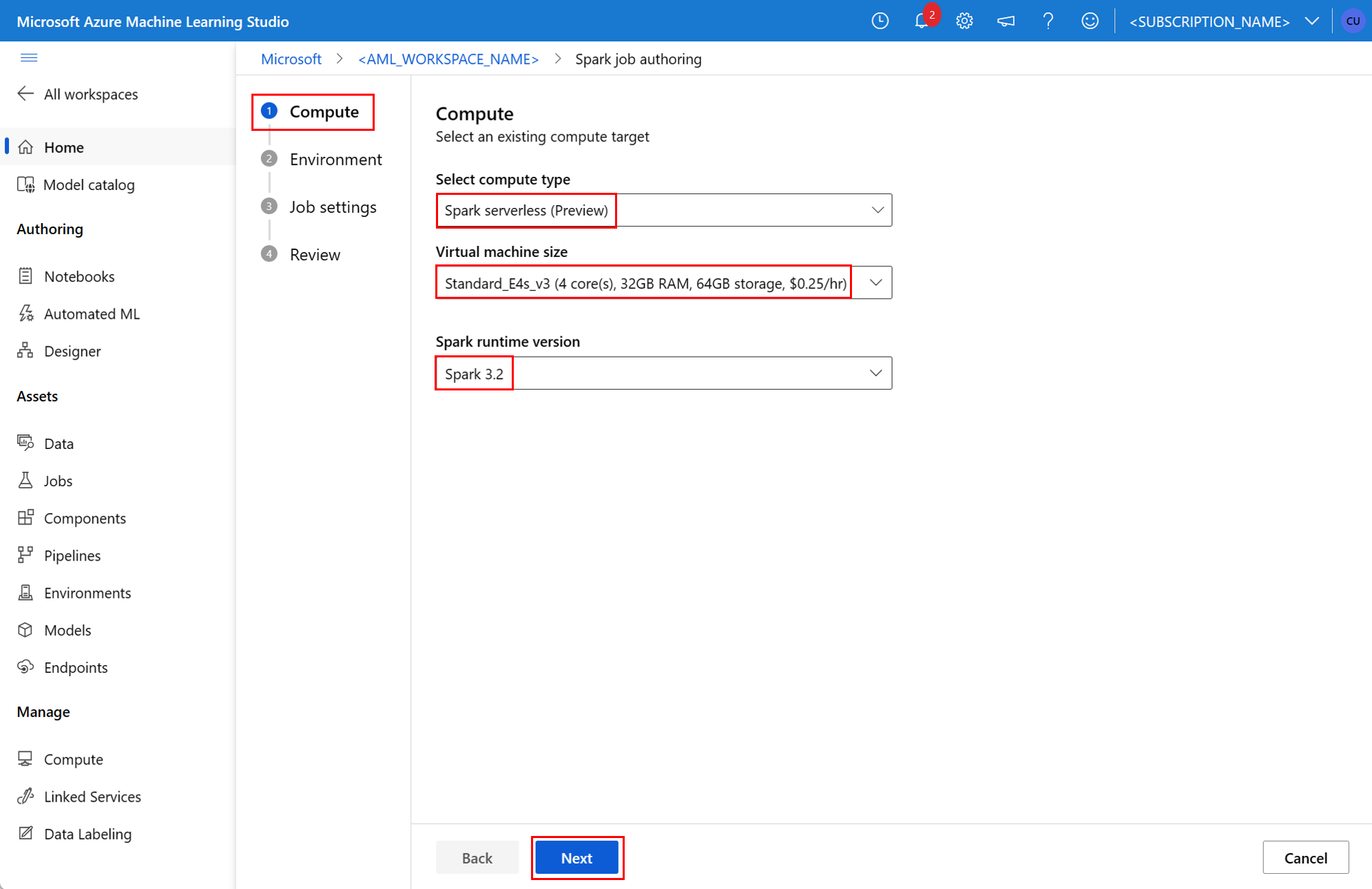
environment: environnement Azure Machine Learning pour l’exécution du travail.args: arguments de ligne de commande à passer au script Python du point d’entrée du travail. Pour obtenir un exemple, consultez le fichier de spécification YAML fourni ici.resources: cette propriété définit les ressources que doit utiliser un calcul Spark serverless Azure Machine Learning. Elle utilise les propriétés suivantes :instance_type: type d’instance de calcul à utiliser pour le pool Spark. Actuellement, les types d’instance suivants sont pris en charge :standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version: définit la version du runtime Spark. Actuellement, les versions de runtime Spark suivantes sont prises en charge :3.33.4Important
Azure Synapse Runtime pour Apache Spark : annonces
- Runtime Azure Synapse pour Apache Spark 3.3 :
- Date d'annonce EOLA : 12 juillet 2024
- Date de fin de support : 31 mars 2025. Après cette date, le runtime sera désactivé.
- Pour une assistance continue et des performances optimales, nous vous conseillons de migrer vers Apache Spark 3.4.
- Runtime Azure Synapse pour Apache Spark 3.3 :
Voici un exemple de fichier YAML :
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute: cette propriété définit le nom d’un pool Spark Synapse attaché comme illustré dans cet exemple :compute: mysparkpoolinputs: cette propriété définit les entrées pour le travail Spark. Les entrées pour un travail Spark peuvent être une valeur littérale ou des données stockées dans un fichier ou un dossier.- Une valeur littérale peut être un nombre, une valeur booléenne ou une chaîne. En voici quelques exemples :
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Les données stockées dans un fichier ou un dossier doivent être définies avec les propriétés suivantes :
type: propriété à définir sururi_fileouuri_folderpour les données d’entrée contenues dans un fichier ou dans un dossier, respectivement.path: URI des données d’entrée, par exempleazureml://,abfss://ouwasbs://.mode: propriété à définir surdirect. Cet exemple montre la définition d’une entrée de travail, qui peut être désignée$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Une valeur littérale peut être un nombre, une valeur booléenne ou une chaîne. En voici quelques exemples :
outputs: cette propriété définit les sorties du travail Spark. Les sorties d’un travail Spark peuvent être écrites dans un fichier ou un emplacement de dossier, défini à l’aide des trois propriétés suivantes :type: vous pouvez définir cette propriété sururi_fileouuri_folderpour écrire des données de sortie dans un fichier ou un dossier respectivement.path: cette propriété définit l’URI de l’emplacement de sortie, par exempleazureml://,abfss://ouwasbs://.mode: propriété à définir surdirect. Cet exemple montre la définition d’une sortie de travail, que vous pouvez désigner${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity: cette propriété facultative définit l’identité utilisée pour la soumission de ce travail. Elle peut avoir les valeursuser_identityetmanaged. Si la spécification YAML ne définit pas d’identité, le travail Spark utilise l’identité par défaut.
Travail Spark autonome
Cet exemple de spécification YAML montre un travail Spark autonome. Il utilise du calcul Spark serverless pour Azure Machine Learning :
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Remarque
Pour utiliser un pool Synapse Spark attaché, définissez la propriété compute dans l’exemple de fichier de spécification YAML illustré précédemment, au lieu de la propriété resources.
Vous pouvez utiliser les fichiers YAML précédents dans la commande az ml job create avec le paramètre --file pour créer un travail Spark autonome comme indiqué ici :
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Vous pouvez exécuter la commande ci-dessus à partir de :
- terminal d’une instance de calcul Azure Machine Learning.
- terminal de Visual Studio Code connecté à une instance de calcul Azure Machine Learning.
- votre ordinateur local sur lequel Azure Machine Learning CLI est installé.
Composant Spark dans un travail de pipeline
Un composant Spark offre la possibilité d’utiliser le même composant dans plusieurs pipelines Azure Machine Learning en tant qu’étape de pipeline.
S’APPLIQUE À : Extension Azure CLI ml v2 (actuelle)
La syntaxe YAML d’un composant Spark ressemble essentiellement à la syntaxe YAML pour la spécification d’un travail Spark. Les propriétés suivantes sont définies différemment dans la spécification YAML du composant Spark :
name: nom du composant Spark.version: version du composant Spark.display_name: nom du composant Spark à afficher dans l’interface utilisateur et ailleurs.description: description du composant Spark.inputs: propriété similaire à la propriétéinputsdécrite dans la section sur la syntaxe YAML pour une spécification de travail Spark, si ce n’est qu’elle ne définit pas la propriétépath. Cet extrait de code montre un exemple de propriétéinputsde composant Spark :inputs: titanic_data: type: uri_file mode: directoutputs: propriété similaire à la propriétéoutputsdécrite dans la section sur la syntaxe YAML pour une spécification de travail Spark, si ce n’est qu’elle ne définit pas la propriétépath. Cet extrait de code montre un exemple de propriétéoutputsde composant Spark :outputs: wrangled_data: type: uri_folder mode: direct
Remarque
Un composant Spark ne définit pas les propriétés identity, compute et resources. Le fichier de spécification YAML du pipeline définit ces propriétés.
Ce fichier de spécification YAML fournit un exemple de composant Spark :
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Vous pouvez utiliser le composant Spark défini dans le fichier de spécification YAML ci-dessus dans un travail de pipeline Azure Machine Learning. Consultez la ressource Schéma YAML du travail de pipeline pour en savoir plus sur la syntaxe YAML qui définit un travail de pipeline. Cet exemple montre un fichier de spécification YAML pour un travail de pipeline, avec un composant Spark et un calcul Spark serverless Azure Machine Learning :
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Notes
Pour utiliser un pool Synapse Spark attaché, définissez la propriété compute dans l’exemple de fichier de spécification YAML illustré ci-dessus au lieu de la propriété resources.
Vous pouvez utiliser le fichier de spécification YAML ci-dessus dans la commande az ml job create avec le paramètre --file pour la création d’un travail de pipeline comme indiqué ici :
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Vous pouvez exécuter la commande ci-dessus à partir de :
- le terminal d’une instance de calcul Azure Machine Learning.
- le terminal de Visual Studio Code, connecté à une instance de calcul Azure Machine Learning.
- votre ordinateur local sur lequel Azure Machine Learning CLI est installé.
Résolution des problèmes liés aux travaux Spark
Pour résoudre les problèmes d’un travail Spark, vous pouvez accéder aux journaux générés pour ce travail dans Azure Machine Learning studio. Pour afficher les journaux d’un travail Spark :
- Accédez à Travaux dans le volet gauche de l’interface utilisateur Azure Machine Learning studio
- Sélectionnez l’onglet Tous les travaux
- Sélectionnez la valeur Nom d’affichage pour le travail
- Dans la page des détails du travail, sélectionnez l’onglet Sortie + journaux
- Dans l’Explorateur de fichiers, développez le dossier logs, puis le dossier azureml
- Accéder aux journaux des travaux Spark dans les dossiers du gestionnaire de pilotes et de bibliothèques
Notes
Pour résoudre les problèmes liés aux travaux Spark créés lors du wrangling de données interactif dans une session de notebook, sélectionnez Détails du travail en haut à droite de l’interface utilisateur du notebook. Un travail Spark à partir d’une session interactive de notebook est créé sous le nom d’expérience notebook-runs.