Résoudre les problèmes de calcul Kubernetes
Dans cet article, vous allez apprendre à résoudre les erreurs courantes liées aux charges de travail sur le calcul Kubernetes. Les erreurs courantes comprennent les erreurs de travaux d’entraînement et de point de terminaison.
Guide d’inférence
Les erreurs courantes de point de terminaison Kubernetes sur le calcul Kubernetes sont classées en deux étendues : étendue de calcul et étendue de cluster. Les erreurs d’étendue de calcul sont liées à la cible de calcul, par exemple la cible de calcul est introuvable ou elle n’est pas accessible. Les erreurs d’étendue du cluster sont liées au cluster Kubernetes sous-jacent, par exemple le cluster lui-même n’est pas accessible ou il est introuvable.
Erreurs de calcul Kubernetes
Voici une liste des types d’erreurs courantes dans l’étendue de calcul que vous pouvez rencontrer lorsque vous utilisez le calcul Kubernetes pour créer des points de terminaison en ligne et des déploiements en ligne pour l’inférence de modèle en temps réel. Vous pouvez les résoudre en suivant les liens des sections pour obtenir des conseils :
- ERREUR : GenericComputeError
- ERREUR : ComputeNotFound
- ERREUR : ComputeNotAccessible
- ERREUR : InvalidComputeInformation
- ERREUR : InvalidComputeNoKubernetesConfiguration
ERREUR : GenericComputeError
Le message d’erreur est :
Failed to get compute information.
Cette erreur se produit lorsque le système n’a pas pu obtenir les informations de calcul du cluster Kubernetes. Vous pouvez vérifier les éléments suivants pour résoudre le problème :
- Vérifiez l’état du cluster Kubernetes. Si le cluster n’est pas en cours d’exécution, vous devez d’abord le démarrer.
- Vérifiez l’intégrité du cluster Kubernetes.
- Vous pouvez afficher le rapport de vérification de l’intégrité du cluster pour rechercher d’éventuels problèmes, par exemple si le cluster n’est pas accessible.
- Vous pouvez accéder au portail de votre espace de travail pour vérifier l’état du calcul.
- Vérifiez si les informations relatives aux types d’instances sont correctes. Vous pouvez vérifier les types d’instances pris en charge dans la documentation du calcul Kubernetes.
- Essayez de détacher et de rattacher le calcul à l’espace de travail, le cas échéant.
Notes
Pour résoudre les erreurs en effectuant un rattachement, veillez à effectuer cette opération avec exactement la même configuration que le calcul détaché précédemment, par exemple le même nom de calcul et le même espace de noms. Sinon, vous risquez de rencontrer d’autres erreurs.
ERREUR : ComputeNotFound
Le message d'erreur est le suivant :
Cannot find Kubernetes compute.
Cette erreur se produit quand :
- Le système ne trouve pas le calcul lors de la création/mise à jour d’un point de terminaison/déploiement en ligne.
- Le calcul des points de terminaison/déploiements en ligne existants a été supprimé.
Vous pouvez vérifier les éléments suivants pour résoudre le problème :
- Essayez de créer le point de terminaison et le déploiement.
- Essayez de détacher et de rattacher le calcul à l’espace de travail. Prenez note des autres remarques sur le rattachement.
ERREUR : ComputeNotAccessible
Le message d'erreur est le suivant :
The Kubernetes compute is not accessible.
Cette erreur se produit lorsque la MSI (identité managée) de l’espace de travail n’a pas accès au cluster AKS. Vous pouvez vérifier si la MSI de l’espace de travail a accès à AKS, et si ce n’est pas le cas, vous pouvez suivre ce document pour gérer l’accès et l’identité.
ERREUR : InvalidComputeInformation
Le message d'erreur est le suivant :
The compute information is invalid.
Il existe un processus de validation de la cible de calcul lors du déploiement de modèles sur votre cluster Kubernetes. Cette erreur doit se produire lorsque les informations de calcul ne sont pas valides. Par exemple, la cible de calcul est introuvable ou la configuration de l’extension Azure Machine Learning a été mise à jour dans votre cluster Kubernetes.
Vous pouvez vérifier les éléments suivants pour résoudre le problème :
- Vérifiez si la cible de calcul que vous avez utilisée est correcte et si elle existe dans votre espace de travail.
- Essayez de détacher et de rattacher le calcul à l’espace de travail. Prenez note des autres remarques sur le rattachement.
ERREUR : InvalidComputeNoKubernetesConfiguration
Le message d'erreur est le suivant :
The compute kubeconfig is invalid.
Cette erreur devrait se produire lorsque le système n’a pas trouvé de configuration pour se connecter au cluster, par exemple :
- Pour un cluster Arc-Kubernetes, aucune configuration Azure Relay n’est trouvée.
- Pour un cluster Arc, aucune configuration AKS n’est trouvée.
Pour recréer la configuration de la connexion de calcul dans votre cluster, vous pouvez essayer de détacher et de rattacher le calcul à l’espace de travail. Prenez note des autres remarques sur le rattachement.
Erreur de cluster Kubernetes
Vous trouverez ci-dessous une liste des types d’erreurs dans l’étendue de cluster que vous pouvez rencontrer lorsque vous utilisez le calcul Kubernetes pour créer des points de terminaison en ligne et des déploiements en ligne pour l’inférence de modèle en temps réel. Vous pouvez les résoudre en suivant le conseil fourni :
- ERREUR : GenericClusterError
- ERREUR : ClusterNotReachable
- ERREUR : ClusterNotFound
- ERREUR : ClusterServiceNotFound
- ERREUR : ClusterUnauthorized
ERREUR : GenericClusterError
Le message d'erreur est le suivant :
Failed to connect to Kubernetes cluster: <message>
Cette erreur se produit lorsque le système n’a pas pu se connecter au cluster Kubernetes pour une raison inconnue. Vous pouvez vérifier les éléments suivants pour résoudre le problème :
Pour les clusters AKS :
- Vérifiez si le cluster AKS est arrêté.
- Si le cluster n’est pas en cours d’exécution, vous devez d’abord le démarrer.
- Vérifiez si le cluster AKS a activé le réseau sélectionné en utilisant des plages d’adresses IP autorisées.
- Si le cluster AKS a activé des plages d’adresses IP autorisées, vérifiez que toutes les plages d’adresses IP du plan de contrôle Azure Machine Learning ont été activées pour le cluster AKS. Pour plus d’informations, vous pouvez consulter ce document.
Pour un cluster AKS ou un cluster Kubernetes avec Azure Arc :
- Vérifiez si le serveur d’API Kubernetes est accessible en exécutant la commande
kubectldans le cluster.
ERREUR : ClusterNotReachable
Le message d'erreur est le suivant :
The Kubernetes cluster is not reachable.
Cette erreur se produit lorsque le système ne peut pas se connecter à un cluster. Vous pouvez vérifier les éléments suivants pour résoudre le problème :
Pour les clusters AKS :
- Vérifiez si le cluster AKS est arrêté.
- Si le cluster n’est pas en cours d’exécution, vous devez d’abord le démarrer.
Pour un cluster AKS ou un cluster Kubernetes avec Azure Arc :
- Vérifiez si le serveur d’API Kubernetes est accessible en exécutant la commande
kubectldans le cluster.
ERREUR : ClusterNotFound
Le message d'erreur est le suivant :
Cannot found Kubernetes cluster.
Cette erreur devrait se produire lorsque le système ne trouve pas le cluster AKS/Arc-Kubernetes.
Vous pouvez vérifier les éléments suivants pour résoudre le problème :
- Tout d’abord, vérifiez l’ID de ressource du cluster dans le portail Azure pour vérifier si la ressource de cluster Kubernetes existe toujours et s’exécute normalement.
- Si le cluster existe et s’exécute, vous pouvez essayer de détacher et de rattacher le calcul à l’espace de travail. Prenez note des autres remarques sur le rattachement.
ERREUR : ClusterServiceNotFound
Le message d'erreur est le suivant :
AzureML extension service not found in cluster.
Cette erreur doit se produire lorsque le service d’entrée appartenant à l’extension n’a pas suffisamment de pods en back-end.
Vous pouvez :
- Accédez au cluster et vérifiez l’état du service
azureml-ingress-nginx-controlleret de son pod principal sous l’espace de nomsazureml. - Si le cluster n’a pas de pods principaux en cours d’exécution, vérifiez la raison en décrivant le pod. Par exemple, si le pod n’a pas suffisamment de ressources à exécuter, vous pouvez supprimer certains pods pour libérer suffisamment de ressources pour le pod d’entrée.
ERREUR : ClusterUnauthorized
Le message d'erreur est le suivant :
Request to Kubernetes cluster unauthorized.
Cette erreur ne doit se produire que dans le cluster avec TA, ce qui signifie que le jeton d’accès a expiré pendant le déploiement.
Vous pouvez réessayer après plusieurs minutes.
Conseil
Vous trouverez un guide plus complet de résolution des erreurs courantes lors de la création/mise à jour des déploiements et des points de terminaison en ligne Kubernetes dans Guide pratique pour résoudre les problèmes liés aux points de terminaison en ligne.
Erreur d’identité
ERREUR : RefreshExtensionIdentityNotSet
Cette erreur se produit lorsque l’extension est installée, mais que l’identité de l’extension n’est pas correctement attribuée. Vous pouvez essayer de réinstaller l’extension pour la corriger.
Notez que cette erreur concerne uniquement les clusters managés
Comment vérifier que sslCertPemFile et sslKeyPemFile sont corrects ?
Pour autoriser l’affichage des erreurs connues, vous pouvez utiliser les commandes afin d’exécuter une vérification de base de référence pour votre certificat et votre clé. Attendez-vous à ce que la deuxième commande retourne « Clé RSA OK » sans vous demander de mot de passe.
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
Exécutez les commandes pour vérifier si sslCertPemFile et sslKeyPemFile sont mis en correspondance :
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
Pour sslCertPemFile, il s’agit du certificat public. Il doit inclure la chaîne de certificats qui inclut les certificats suivants, et doit se trouver dans la séquence du certificat de serveur, du certificat d’autorité de certification intermédiaire et du certificat d’autorité de certification racine :
- Certificat de serveur : le serveur le présente au client pendant l’établissement d'une liaison TLS. Il contient la clé publique, le nom de domaine et d’autres informations relatives au serveur. Le certificat de serveur est signé par une autorité de certification intermédiaire qui garantit l’identité du serveur.
- Certificat d’autorité de certification intermédiaire : l’autorité de certification intermédiaire le présente au client afin de prouver son autorité concernant la signature du certificat de serveur. Il contient la clé publique, le nom et d’autres informations relatives à l’autorité de certification intermédiaire. Le certificat d’autorité de certification intermédiaire est signé par une autorité de certification racine qui garantit l’identité de l’autorité de certification intermédiaire.
- Certificat d’autorité de certification racine : l’autorité de certification racine le présente au client afin de prouver son autorité concernant la signature du certificat d’autorité de certification intermédiaire. Il contient la clé publique, le nom et d’autres informations relatives à l’autorité de certification racine. Le certificat d’autorité de certification racine est auto-signé et approuvé par le client.
Guide d’entraînement
Lorsque le travail de formation est en cours d’exécution, vous pouvez vérifier l’état du travail dans le portail de l’espace de travail. Lorsque vous rencontrez un état de travail anormal (par exemple, le travail a fait l’objet de plusieurs tentatives, il est bloqué à l’état d’initialisation ou il a fini par échouer), vous pouvez suivre le guide afin de résoudre le problème.
Débogage de nouvelle tentative de travail
Si le pod du travail d’entraînement s’exécutant dans le cluster a été arrêté en raison d’une erreur OOM (mémoire insuffisante) sur le nœud, le travail est automatiquement réessayé sur un autre nœud disponible.
Pour déboguer davantage la cause racine de la tentative de travail, vous pouvez accéder au portail de l’espace de travail pour vérifier le journal de la nouvelle tentative de travail.
- Chaque journal de nouvelle tentative est enregistré dans un nouveau dossier de journal au format « retry-<numéro_nouvelle_tentative> » (par exemple : retry-001).
Vous pouvez ensuite obtenir les informations de mappage du nœud au travail de la nouvelle tentative, afin de déterminer le nœud sur lequel le travail de nouvelle tentative s’exécute.
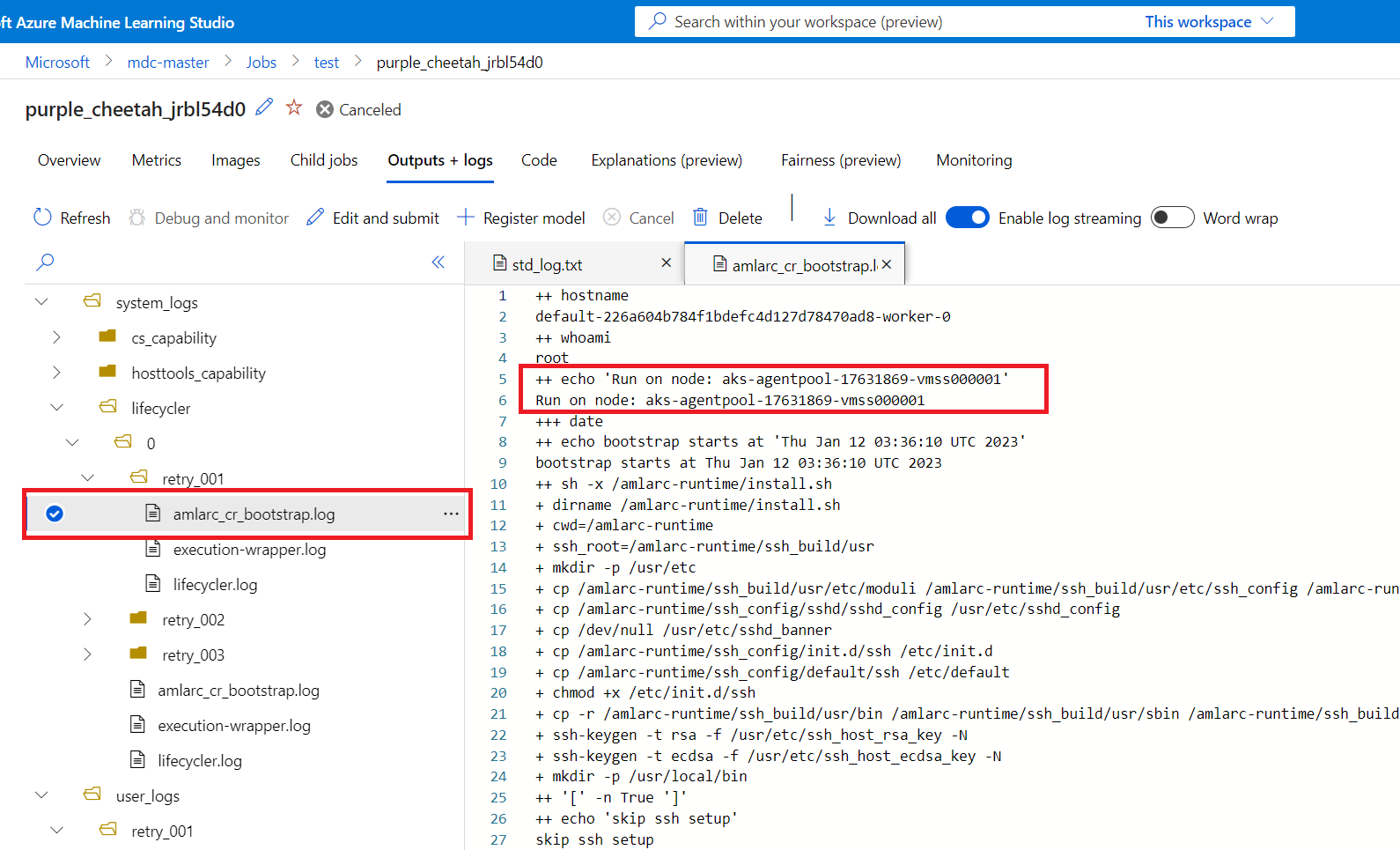
Vous pouvez obtenir des informations sur le mappage du nœud de travail à partir de amlarc_cr_bootstrap.log sous le dossier system_logs.
Le nom d’hôte du nœud sur lequel le pod de travail s’exécute est indiqué dans ce journal, par exemple :
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
« ask-agentpool-17631869-vmss0000 » représente le nom d’hôte du nœud qui exécute ce travail dans votre cluster AKS. Vous pouvez ensuite accéder au cluster pour vérifier l’état du nœud à des fins d’analyse plus approfondie.
Le pod de travail est bloqué dans l’état d’initialisation
Si le travail s’exécute plus longtemps que prévu et que vous constatez que vos pods de travail sont bloqués dans un état d’initialisation avec l’avertissement Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matched, le problème peut être dû au fait que l’extension Azure Machine Learning ne prend pas en charge le mode de téléchargement pour les données d’entrée.
Pour résoudre ce problème, passez au mode montage pour vos données d’entrée.
Erreurs courantes d’échec de travail
Ci-dessous, vous trouverez une liste des types d’erreurs courantes que vous pouvez rencontrer en utilisant la calcul Kubernetes pour créer et exécuter un travail de formation et que vous pouvez résoudre en suivant ces indications :
- le travail a échoué. 137
- le travail a échoué. E45004
- le travail a échoué. 400
- Donner une clé de compte ou un jeton SAS
- Échec de l’autorisation AzureBlob
le travail a échoué. 137
Le message d’erreur est :
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
Vérifiez votre paramètre de proxy et si 127.0.0.1 a été ajouté à proxy-skip-range lors de l’utilisation de az connectedk8s connect en suivant cette configuration réseau.
le travail a échoué. E45004
Le message d’erreur est :
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Vérifiez si vous avez défini enableTraining=True lors de l’installation de l’extension Azure Machine Learning. Vous trouverez plus d’informations dans Déployer l’extension Azure Machine Learning sur un cluster AKS ou Arc Kubernetes.
le travail a échoué. 400
Le message d’erreur est :
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
Vous pouvez suivre la section de résolution des problèmes Private Link pour vérifier vos paramètres réseau.
Donner une clé de compte ou un jeton SAS
Si vous devez accéder à Azure Container Registry (ACR) pour l’image Docker et à un compte de stockage pour les données de formation, ce problème se produit lorsque le calcul n’est pas spécifié avec une identité managée.
Pour accéder à Azure Container Registry (ACR) à partir d’un cluster de calcul Kubernetes pour les images Docker, ou accéder à un compte de stockage pour les données de formation, vous devez attacher le calcul Kubernetes avec une identité managée affectée par le système ou affectée par l’utilisateur activée.
Dans le scénario de formation ci-dessus, cette identité de calcul est nécessaire pour que le calcul Kubernetes soit utilisé comme informations d’identification pour communiquer entre la ressource ARM liée à l’espace de travail et le cluster de calcul Kubernetes. Par conséquent, sans cette identité, le travail d’entraînement échoue et signale l’absence de clé de compte ou de jeton SAS. Par exemple, pour accéder au compte de stockage, si vous ne spécifiez pas d’identité managée pour votre calcul Kubernetes, le travail échoue avec le message d’erreur suivant :
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
Cela est dû au fait que le compte de stockage par défaut de l’espace de travail Machine Learning sans informations d’identification n’est pas pris en charge pour les travaux d’entraînement dans le calcul Kubernetes.
Pour atténuer ce problème, vous pouvez affecter une identité managée à l’étape d’attachement de calcul, ou vous pouvez affecter une identité managée au calcul une fois qu’il a été attaché. Vous trouverez plus d’informations dans la section Affecter une identité managée à la cible de calcul.
Échec de l’autorisation AzureBlob
Si vous devez accéder à AzureBlob pour le chargement ou le téléchargement de données dans vos travaux de formation sur le calcul Kubernetes, le travail échoue avec le message d’erreur suivant :
Unable to upload project files to working directory in AzureBlob because the authorization failed.
Cela est dû au fait que l’autorisation a échoué lorsque le travail a tenté de charger les fichiers projet dans AzureBlob. Vous pouvez vérifier les éléments suivants pour résoudre le problème :
- Vérifiez que le compte de stockage a activé les exceptions « Autoriser les services Azure dans la liste des services approuvés à accéder à ce compte de stockage » et que l’espace de travail figure dans la liste des instances de ressources.
- Vérifiez que l’espace de travail dispose d’une identité managée affectée par le système.
Problème de liaison privée
Nous pouvons utiliser la méthode pour vérifier la configuration de la liaison privée en nous connectant à un pod dans le cluster Kubernetes, puis vérifier les paramètres réseau associés.
Recherchez l’ID d’espace de travail dans le portail Azure ou obtenez cet ID en exécutant
az ml workspace showdans la ligne de commande.Afficher tous les pods azureml-fe exécutés par
kubectl get po -n azureml -l azuremlappname=azureml-fe.Connectez-vous à l’un d’eux, puis exécutez
kubectl exec -it -n azureml {scorin_fe_pod_name} bash.Si le cluster n’utilise pas de proxy, exécutez
nslookup {workspace_id}.workspace.{region}.api.azureml.ms. Si vous configurez correctement la liaison privée entre le réseau virtuel et l’espace de travail, l’adresse IP interne dans le réseau virtuel doit obtenir une réponse via l’outil DNSLookup.Si le cluster utilise un proxy, vous pouvez essayer de lancer une requête
curlsur l’espace de travail
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
Lorsque le proxy et l’espace de travail sont correctement configurés avec une liaison privée, vous devez observer la présence d’une tentative de connexion à une adresse IP interne. Une réponse avec un code d’état HTTP 401 est attendue dans ce scénario si un jeton n’est pas fourni.
Autres problèmes connus
La mise à jour du calcul Kubernetes ne prend pas effet
Pour le moment, l’interface CLI v2 et le SDK v2 n’autorisent pas la mise à jour d’une configuration d’un calcul Kubernetes existant. Par exemple, le changement de l’espace de noms ne prend pas effet.
Le nom de l’espace de travail ou du groupe de ressources se termine par ’-’
Une cause courante de la défaillance « InternalServerError » lors de la création de charges de travail telles que des déploiements, des points de terminaison ou des travaux dans un calcul Kubernetes réside dans le fait d’avoir les caractères spéciaux tels que ’-’ à la fin du nom de votre espace de travail ou groupe de ressources.