Utiliser des travaux parallèles dans les pipelines
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Cet article explique comment utiliser l’interface CLI v2 et le kit SDK Python v2 pour exécuter des travaux parallèles dans les pipelines Azure Machine Learning. Les travaux parallèles accélèrent l’exécution des travaux en distribuant les tâches répétées sur de puissants clusters de calcul multinœuds.
Les ingénieurs Machine Learning ont toujours des besoins de mise à l’échelle pour leurs tâches de formation ou d’inférence. Par exemple, quand un scientifique des données fournit un seul script pour former un modèle de prédiction des ventes, les ingénieurs Machine Learning doivent appliquer cette tâche de formation à chaque magasin de données individuel. Les défis de ce processus de scale-out incluent de longs temps d’exécution, qui entraînent des retards ainsi que des problèmes inattendus qui nécessitent une intervention manuelle pour maintenir l’exécution de la tâche.
Le travail principal de la parallélisation Azure Machine Learning consiste à fractionner une seule tâche série en mini-lots, et à envoyer ces mini-lots à plusieurs calculs pour qu’ils soient exécutés en parallèle. Les travaux parallèles réduisent considérablement le temps d’exécution de bout en bout, et gèrent également les erreurs automatiquement. Pensez à utiliser un travail parallèle Azure Machine Learning pour former de nombreux modèles à partir de vos données partitionnées, ou pour accélérer vos tâches d’inférence par lots à grande échelle.
Par exemple, dans un scénario où vous exécutez un modèle de détection d’objet sur un grand ensemble d’images, les travaux parallèles Azure Machine Learning vous permettent de distribuer facilement vos images pour exécuter du code personnalisé en parallèle sur un cluster de calcul spécifique. La parallélisation peut réduire considérablement le temps nécessaire à l’exécution des tâches. Les travaux parallèles Azure Machine Learning peuvent également simplifier et automatiser votre processus pour le rendre plus efficace.
Prérequis
- Disposer d’un compte et d’un espace de travail Azure Machine Learning.
- Découvrez les pipelines Azure Machine Learning.
- Installez Azure CLI et l’extension
ml. Pour plus d’informations, consultez Installer, configurer et utiliser l’interface CLI (v2). L’extensionmls’installe automatiquement la première fois que vous exécutez une commandeaz ml. - Comprendre comment créer et exécuter des pipelines et des composants Azure Machine Learning avec CLI v2.
Créer et exécuter un pipeline avec une étape de travail parallèle
Un travail parallèle Azure Machine Learning peut être utilisé uniquement en tant qu’étape dans un travail de pipeline.
Les exemples suivants proviennent de la ressource Exécuter un travail de pipeline en utilisant un travail parallèle dans un pipeline, située dans le référentiel d’exemples Azure Machine Learning.
Préparer la parallélisation
Cette étape de travail parallèle nécessite une préparation. Vous avez besoin d’un script d’entrée qui implémente les fonctions prédéfinies. Vous devez également spécifier des attributs dans votre définition de tâche relative au travail parallèle pour :
- Définir et lier vos données d’entrée.
- Définir la méthode de division des données.
- Configurer vos ressources de calcul.
- Appeler le script d’entrée.
Les sections suivantes expliquent comment préparer le travail parallèle.
Déclarer les entrées et le paramètre de division des données
Un travail parallèle nécessite le fractionnement et le traitement en parallèle d’une entrée principale. Le format des données d’entrée principales peut correspondre à celui des données tabulaires ou d’une liste de fichiers.
Les différents formats de données ont des types d’entrées, des modes d’entrée et des méthodes de division des données distincts. Le tableau suivant décrit les options :
| Format de données | Type d’entrée | Mode d’entrée | Méthode de division des données |
|---|---|---|---|
| Liste de fichiers | mltable ou uri_folder |
ro_mount ou download |
Par taille (nombre de fichiers) ou par partition |
| Données tabulaires | mltable |
direct |
Par taille (taille physique estimée) ou par partition |
Remarque
Si vous utilisez un mltable tabulaire en tant que données d’entrée principales, vous devez :
- Installer la bibliothèque
mltabledans votre environnement, comme indiqué à la ligne 9 de ce fichier Conda. - Disposer d’un fichier de spécification MLTable dans le chemin d’accès spécifié, avec la section
transformations: - read_delimited:remplie. Pour obtenir des exemples, consultez Créer et gérer des ressources de données.
Vous pouvez déclarer vos données d’entrée principales avec l’attribut input_data dans le code YAML ou Python du travail parallèle, et lier les données à l’input défini de votre travail parallèle en utilisant ${{inputs.<input name>}}. Vous définissez ensuite l’attribut de division des données pour votre entrée principale en fonction de votre méthode de division des données.
| Méthode de division des données | Nom de l’attribut | Type d'attribut | Exemple de travail |
|---|---|---|---|
| Par taille | mini_batch_size |
string | Prédiction par lots Iris |
| Par partition | partition_keys |
Liste de chaînes | Prédiction des ventes de jus d’orange |
Configurer les ressources de calcul pour la parallélisation
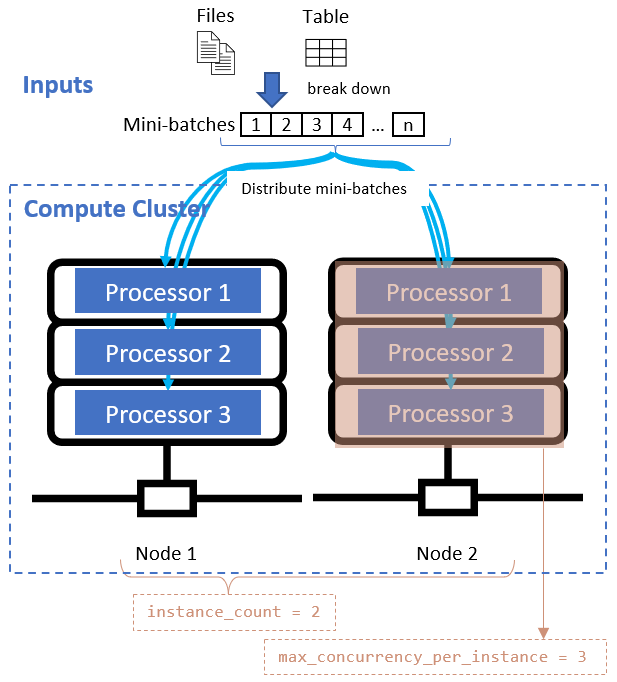
Une fois que vous avez défini l’attribut de division des données, configurez les ressources de calcul pour votre parallélisation en définissant les attributs instance_count et max_concurrency_per_instance.
| Nom de l’attribut | Type | Description | Valeur par défaut |
|---|---|---|---|
instance_count |
entier | Nombre de nœuds à dédier au travail. | 1 |
max_concurrency_per_instance |
entier | Nombre de processeurs sur chaque nœud. | Pour un calcul GPU : 1. Pour un calcul de processeur : nombre de cœurs. |
Ces attributs interagissent avec votre cluster de calcul spécifié, comme le montre le diagramme suivant :
Appeler le script d’entrée
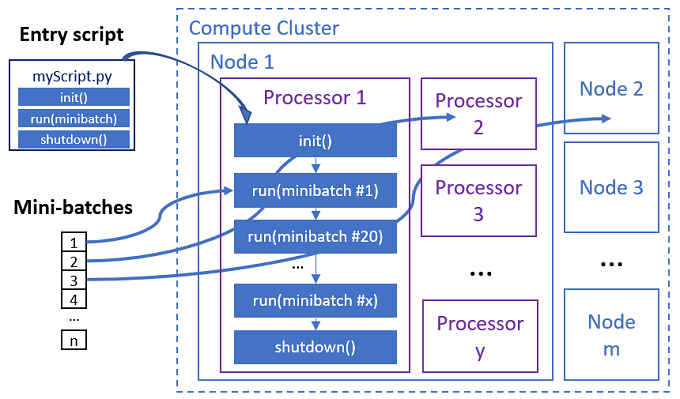
Le script d’entrée est un fichier Python unique qui implémente les trois fonctions prédéfinies suivantes avec du code personnalisé.
| Nom de la fonction | Obligatoire | Description | Entrée | Renvoie |
|---|---|---|---|---|
Init() |
Y | Préparation courante avant de commencer à exécuter des mini-lots. Par exemple, utilisez cette fonction pour charger le modèle dans un objet global. | -- | -- |
Run(mini_batch) |
Y | Implémente la logique d’exécution principale pour les mini-lots. | mini_batch est un DataFrame Pandas si les données d’entrée correspondent à des données tabulaires, ou une liste de chemins d’accès de fichiers si les données d’entrée correspondent à un répertoire. |
DataFrame, liste ou tuple. |
Shutdown() |
N | Fonction facultative permettant d’effectuer des nettoyages personnalisés avant de retourner le calcul au pool. | -- | -- |
Important
Pour éviter les exceptions durant l’analyse des arguments dans les fonctions Init() ou Run(mini_batch), utilisez parse_known_args à la place de parse_args. Consultez l’exemple iris_score pour un script d’entrée avec analyseur d’arguments.
Important
La fonction Run(mini_batch) nécessite le retour d’un élément de DataFrame, de liste ou de tuple. Le travail parallèle compte le nombre d’éléments retournés pour déterminer combien d’entre eux ont été traités correctement dans ce mini-lot. Le nombre d’éléments du mini-lot doit être égal au nombre d’éléments de liste retournés, si tous les éléments ont été traités.
Le travail parallèle exécute les fonctions dans chaque processeur, comme le montre le diagramme suivant.
Consultez les exemples de scripts d’entrée suivants :
- Identification de l’image pour une liste de fichiers d’images
- Classification Iris pour les données Iris tabulaires
Pour appeler le script d’entrée, spécifiez les deux attributs suivants dans votre définition de tâche relative au travail parallèle :
| Nom de l’attribut | Type | Description |
|---|---|---|
code |
string | Chemin d’accès local du répertoire de code source à charger et à utiliser pour le travail. |
entry_script |
string | Fichier Python qui contient l’implémentation des fonctions parallèles prédéfinies. |
Exemple d’étape de travail parallèle
L’étape de travail parallèle suivante déclare le type d’entrée, le mode d’entrée ainsi que la méthode de division des données d’entrée. De plus, elle lie l’entrée, configure le calcul, et appelle le script d’entrée.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Prendre en compte les paramètres d’automatisation
Le travail parallèle Azure Machine Learning expose de nombreux paramètres facultatifs qui peuvent contrôler automatiquement le travail sans intervention manuelle. Le tableau suivant décrit ces paramètres.
| Clé | Type | Description | Valeurs autorisées | Valeur par défaut | Défini dans l’attribut ou l’argument de programme |
|---|---|---|---|---|---|
mini_batch_error_threshold |
entier | Nombre de mini-lots ayant échoué à ignorer dans ce travail parallèle. Si le nombre de mini-lots ayant échoué est supérieur à ce seuil, le travail parallèle est marqué comme ayant échoué. Le mini-lot est marqué comme ayant échoué si : - Le nombre d’éléments retournés en provenance de run() est inférieur au nombre d’entrées du mini-lot.- Les exceptions sont interceptées dans le code run() personnalisé. |
[-1, int.max] |
-1, ce qui signifie ignorer tous les mini-lots ayant échoué |
Attribut mini_batch_error_threshold |
mini_batch_max_retries |
entier | Nombre de nouvelles tentatives en cas d’échec ou d’expiration du mini-lot. Si toutes les nouvelles tentatives échouent, le mini-lot est marqué comme ayant échoué en fonction du calcul de mini_batch_error_threshold. |
[0, int.max] |
2 |
Attribut retry_settings.max_retries |
mini_batch_timeout |
entier | Délai d’expiration en secondes pour l’exécution de la fonction run() personnalisée. Si le délai d’exécution est supérieur à ce seuil, le mini-lot est abandonné, et marqué comme ayant échoué pour déclencher une nouvelle tentative. |
(0, 259200] |
60 |
Attribut retry_settings.timeout |
item_error_threshold |
entier | Le seuil des éléments ayant échoué. Les éléments ayant échoué sont comptabilisés par l’écart de nombre entre les entrées et les retours de chaque mini-lot. Si la somme des éléments ayant échoué est supérieure à ce seuil, le travail parallèle est marqué comme ayant échoué. | [-1, int.max] |
-1, ce qui signifie ignorer toutes les défaillances durant le travail parallèle |
Argument de programme--error_threshold |
allowed_failed_percent |
entier | Similaire à mini_batch_error_threshold, mais utilise le pourcentage de mini-lots ayant échoué à la place du nombre. |
[0, 100] |
100 |
Argument de programme--allowed_failed_percent |
overhead_timeout |
entier | Délai d’expiration en secondes pour l’initialisation de chaque mini-lot. Par exemple, chargement des données de mini-lot, puis passage de ces données à la fonction run(). |
(0, 259200] |
600 |
Argument de programme--task_overhead_timeout |
progress_update_timeout |
entier | Délai d’expiration en secondes pour le monitoring de la progression de l’exécution du mini-lot. Si aucune mise à jour de la progression n’est reçue durant le délai d’expiration défini par paramètre, le travail parallèle est marqué comme ayant échoué. | (0, 259200] |
Calculé dynamiquement par d’autres paramètres | Argument de programme--progress_update_timeout |
first_task_creation_timeout |
entier | Délai d’expiration en secondes pour le monitoring du temps écoulé entre le démarrage du travail et l’exécution du premier mini-lot. | (0, 259200] |
600 |
Argument de programme--first_task_creation_timeout |
logging_level |
string | Niveau de détail des journaux dont l’image mémoire doit être enregistrée dans les fichiers journaux de l’utilisateur. | INFO, WARNING ou DEBUG |
INFO |
Attribut logging_level |
append_row_to |
string | Agrégez tous les retours de chaque exécution du mini-lot, puis enregistrez la sortie correspondante dans ce fichier. Peut faire référence à l’une des sorties du travail parallèle à l’aide de l’expression ${{outputs.<output_name>}} |
Attribut task.append_row_to |
||
copy_logs_to_parent |
string | Option booléenne indiquant si vous souhaitez copier la progression du travail, la vue d’ensemble et les journaux dans le travail de pipeline parent. | True ou False |
False |
Argument de programme--copy_logs_to_parent |
resource_monitor_interval |
entier | Intervalle de temps en secondes pour enregistrer l’image mémoire de l’utilisation des ressources de nœud (par exemple le processeur ou la mémoire) dans le dossier des journaux sous le chemin d’accès logs/sys/perf. Remarque : L’enregistrement fréquent de l’image mémoire des journaux de ressources ralentit légèrement la vitesse d’exécution. Affectez 0 à cette valeur pour arrêter l’enregistrement d’image mémoire de l’utilisation des ressources. |
[0, int.max] |
600 |
Argument de programme--resource_monitor_interval |
L’exemple de code suivant met à jour ces paramètres :
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Créer le pipeline avec l’étape de travail parallèle
L’exemple suivant montre le travail de pipeline complet avec l’étape de travail parallèle incluse :
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Envoyer le travail du pipeline
Soumettez votre travail de pipeline avec l’étape parallèle à l’aide de la commande CLI az ml job create :
az ml job create --file pipeline.yml
Vérifier l’étape parallèle dans l’IU de studio
Une fois que vous avez envoyé une tâche de pipeline, le widget Kit de développement logiciel (SDK) ou CLI vous donne un lien d’URL web vers le graphique de pipeline dans l’interface utilisateur d’Azure Machine Learning Studio.
Pour voir les résultats d’un travail parallèle, double-cliquez sur l’étape parallèle dans le graphe de pipeline, sélectionnez l’onglet Paramètres dans le panneau de détails, développez Paramètres d’exécution, puis développez la section Parallèle.

Pour déboguer une défaillance d’un travail parallèle, sélectionnez l’onglet Sorties + journaux, développez le dossier journaux, puis consultez job_result.txt pour comprendre la raison de l’échec du travail parallèle. Pour plus d’informations sur la structure de journalisation des travaux parallèles, consultez readme.txt dans le même dossier.
