Optimiser les performances et gérer les bases de données dans Azure Database pour MySQL - Serveur flexible avec sys_schema
Le performance_schema MySQL, qui a été introduit dans MySQL 5.5, fournit l’instrumentation pour bon nombre de ressources serveur vitales, telles que l’allocation de mémoire, les programmes stockés, le verrouillage des métadonnées, etc. Or, le performance_schema contient plus de 80 tables et, pour obtenir les informations nécessaires, il faut souvent joindre les tables du performance_schema et les tables d’information_schema. En s’appuyant sur performance_schema et information_schema, sys_schema fournit une collection considérable de vues conviviales dans une base de données en lecture seule disponible dans Serveur flexible Azure Database pour MySQL version 5.7.
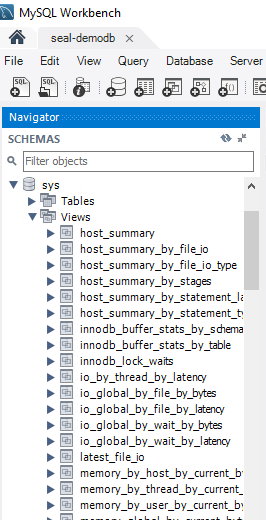
Il existe 52 vues dans le sys_schema, et chaque vue présente l’un des préfixes suivants :
- Host_summary ou IO : latences liées aux E/S.
- InnoDB : état de la mémoire tampon et verrous InnoDB.
- Mémoire : utilisation de la mémoire par l’hôte et les utilisateurs.
- Schéma : informations relatives au schéma, telles que l’incrémentation automatique, les index, etc.
- Statement : informations sur les instructions SQL ; il peut s’agir d’une instruction qui a entraîné une analyse de table complète ou une durée de requête longue.
- Utilisateur : ressources consommées et regroupées par utilisateur. Il peut s’agir par exemple d’E/S de fichiers, de connexions ou de mémoire.
- Wait : événements d’attente regroupés par hôte ou utilisateur.
À présent, intéressons-nous à quelques modèles d’utilisation courants de sys_schema. Pour commencer, nous allons regrouper les modèles d’utilisation dans deux catégories : réglage des performances et maintenance de base de données.
Réglage des performances
sys.user_summary_by_file_io
Les E/S représentent l’opération la plus coûteuse de la base de données. Nous pouvons déterminer la latence moyenne des E/S en interrogeant la vue sys.user_summary_by_file_io. Avec par défaut 125 Go de stockage provisionné, la latence des E/S est d’environ 15 secondes.
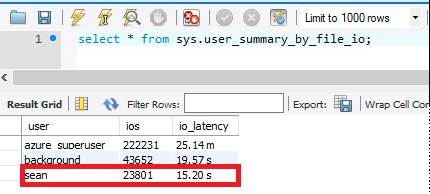
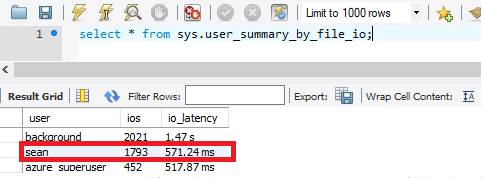
Dans la mesure où Serveur flexible Azure Database pour MySQL met à l’échelle les E/S en fonction du stockage, après l’augmentation de mon stockage provisionné à 1 To, la latence des E/S est réduite à 571 ms.
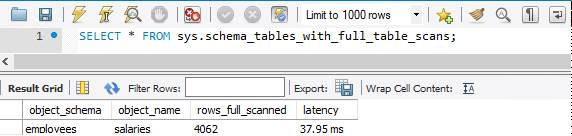
sys.schema_tables_with_full_table_scans
En dépit d’une planification minutieuse, de nombreuses requêtes peuvent donner lieu à des analyses de table complète. Pour plus d’informations sur les types d’index et sur la manière de les optimiser, vous pouvez vous référer à cet article : Performance des requêtes de profil dans Azure Database pour MySQL – Serveur flexible à l’aide de EXPLAIN. Les analyses de table complète sont gourmandes en ressources et dégradent les performances de votre base de données. Le moyen le plus rapide de rechercher des tables avec une analyse de table complète est d’interroger la vue sys.schema_tables_with_full_table_scans.
sys.user_summary_by_statement_type
Pour résoudre les problèmes de performance de la base de données, il peut être utile d’identifier les événements qui se produisent dans votre base de données, notamment en utilisant la vue sys.user_summary_by_statement_type.
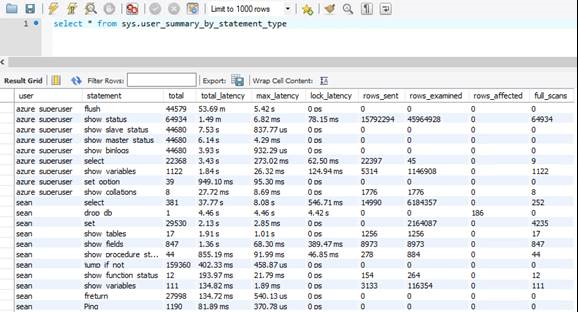
Dans cet exemple, Serveur flexible Azure Database pour MySQL a passé 53 minutes à vider 44 579 fois le journal des requêtes lentes. Cela représente beaucoup de temps et un grand nombre d’E/S. Vous pouvez réduire cette activité en désactivant votre journal des requêtes lentes ou en diminuant la fréquence de la journalisation des requêtes lentes dans le portail Azure.
Maintenance de base de données
sys.innodb_buffer_stats_by_table
[!IMPORTANT]
L’interrogation de cette vue peut avoir un impact sur les performances. Il est recommandé d’effectuer cette résolution des problèmes pendant les heures creuses.
Le pool de mémoires tampons InnoDB réside en mémoire et constitue le principal mécanisme de cache entre le SGBD et le stockage. La taille du pool de mémoires tampons InnoDB est liée au niveau de performances et ne peut pas être modifiée, sauf si une autre référence SKU de produit est choisie. Comme pour la mémoire de votre système d’exploitation, les pages anciennes sont écartées pour faire place à des données plus récentes. Pour identifier les tables qui consomment la majeure partie de la mémoire du pool de mémoires tampons InnoDB, vous pouvez interroger la vue sys.innodb_buffer_stats_by_table.
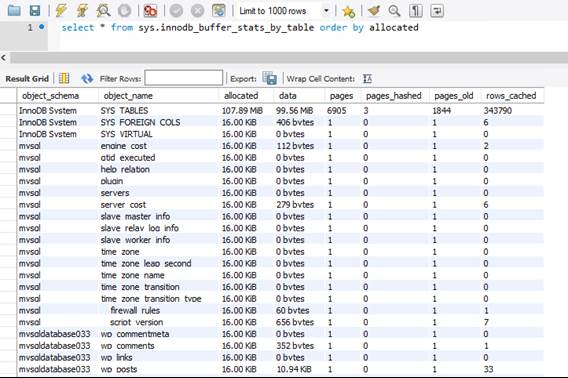
Dans le schéma ci-dessus, il apparaît qu’en dehors des tables et vues système, chaque table de la base de données mysqldatabase033, qui héberge l’un de mes sites WordPress, occupe 16 Ko, soit 1 page, de données en mémoire.
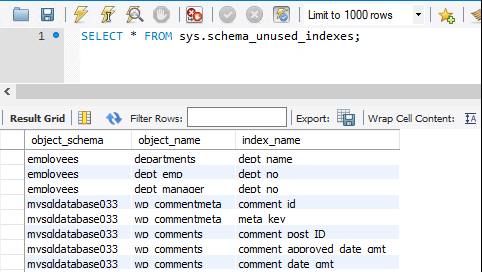
Sys.schema_unused_indexes et sys.schema_redundant_indexes
Les index sont des outils efficaces pour améliorer les performances de lecture, mais ils induisent des coûts supplémentaires en termes d’insertions et de stockage. Sys.schema_unused_indexes et sys.schema_redundant_indexes donnent des indications sur les index non utilisés ou en double.

Conclusion
En résumé, sys_schema est un outil efficace à la fois pour le réglage des performances et la maintenance de base de données. Veillez à tirer parti de cette fonctionnalité dans votre instance Serveur flexible Azure Database pour MySQL.