Guide pratique pour utiliser Azure.Search.Documents dans une application .NET
Cet article explique comment créer et gérer des objets de recherche à l'aide de C# et de la bibliothèque client Azure.Search.Documents (version 11) dans le SDK Azure pour .NET.
À propos de la version 11
Azure SDK for .NET comprend une bibliothèque client Azure.Search.Documents de l'équipe Azure SDK qui est fonctionnellement équivalente à la bibliothèque client précédente, Microsoft.Azure.Search. La version 11 est plus cohérente en termes de programmabilité Azure. Certains exemples incluent l’authentification de clé AzureKeyCredential et la sérialisation System.Text.Json.Serialization pour JSON.
Comme avec les versions précédentes, vous pouvez utiliser cette bibliothèque pour :
- Créer et gérer des index de recherche, des sources de données, des indexeurs, des ensembles de compétences et des mappages de synonymes
- Charger et gérer des documents de recherche dans un index
- Exécuter des requêtes, tout cela sans avoir à gérer les détails de HTTP et JSON
- Appeler et gérer l’enrichissement par IA (ensembles de compétences) et les sorties
La bibliothèque est distribuée sous la forme d’un seul package NuGet, qui comprend toutes les API utilisées pour l’accès programmatique à un service de recherche.
La bibliothèque cliente définit des classes comme SearchIndex, SearchField et SearchDocument, ainsi que des opérations telles que SearchIndexClient.CreateIndex et SearchClient.Search sur les classes SearchIndexClient et SearchClient. Ces classes sont organisées dans les espaces de noms suivants :
Azure.Search.DocumentsAzure.Search.Documents.IndexesAzure.Search.Documents.Indexes.ModelsAzure.Search.Documents.Models
La version 11 cible la spécification du service de recherche 2020-06-30.
La bibliothèque de client ne fournit pas d’opérations de management des services telles que la création et la mise à l’échelle des services de recherche ainsi que la gestion des clés API. Si vous avez besoin de gérer vos ressources de recherche à partir d’une application .NET, utilisez la bibliothèque Microsoft.Azure.Management.Search du Kit SDK Azure pour .NET.
Mettre à niveau vers la version 11
Si vous utilisez une version antérieure du SDK .NET et que vous souhaitez effectuer une mise à niveau vers la version en disponibilité générale, consultez Mettre à niveau vers la version 11 du SDK .NET Recherche Azure AI.
Configuration requise du kit de développement logiciel (SDK)
Visual Studio 2019 ou version ultérieure.
Votre propre service Recherche Azure AI. Pour utiliser le SDK, vous avez besoin du nom de votre service et d'une ou plusieurs clés API. Créez un service dans le portail Azure si vous n’en avez pas.
Téléchargez le package NuGet via Outils>Gestionnaire des packages NuGet>Gérer les packages NuGet pour la solution dans Visual Studio. Recherchez le package nommé
Azure.Search.Documents.
Le SDK Azure pour .NET est conforme à .NET Standard 2.0.
Exemple d’application
Cet article enseigne par l’exemple en s’appuyant sur l’exemple de code DotNetHowTo sur GitHub pour illustrer les concepts fondamentaux de Recherche Azure AI, ainsi que la création, le chargement et l’interrogation d’un index de recherche.
Pour le reste de l’article, supposons un nouvel index nommé hotels, comportant quelques documents, avec plusieurs requêtes qui correspondent à des résultats.
L’exemple suivant montre le programme principal, avec le flux global :
// This sample shows how to delete, create, upload documents and query an index
static void Main(string[] args)
{
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
SearchIndexClient indexClient = CreateSearchIndexClient(configuration);
string indexName = configuration["SearchIndexName"];
Console.WriteLine("{0}", "Deleting index...\n");
DeleteIndexIfExists(indexName, indexClient);
Console.WriteLine("{0}", "Creating index...\n");
CreateIndex(indexName, indexClient);
SearchClient searchClient = indexClient.GetSearchClient(indexName);
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(searchClient);
SearchClient indexClientForQueries = CreateSearchClientForQueries(indexName, configuration);
Console.WriteLine("{0}", "Run queries...\n");
RunQueries(indexClientForQueries);
Console.WriteLine("{0}", "Complete. Press any key to end application...\n");
Console.ReadKey();
}
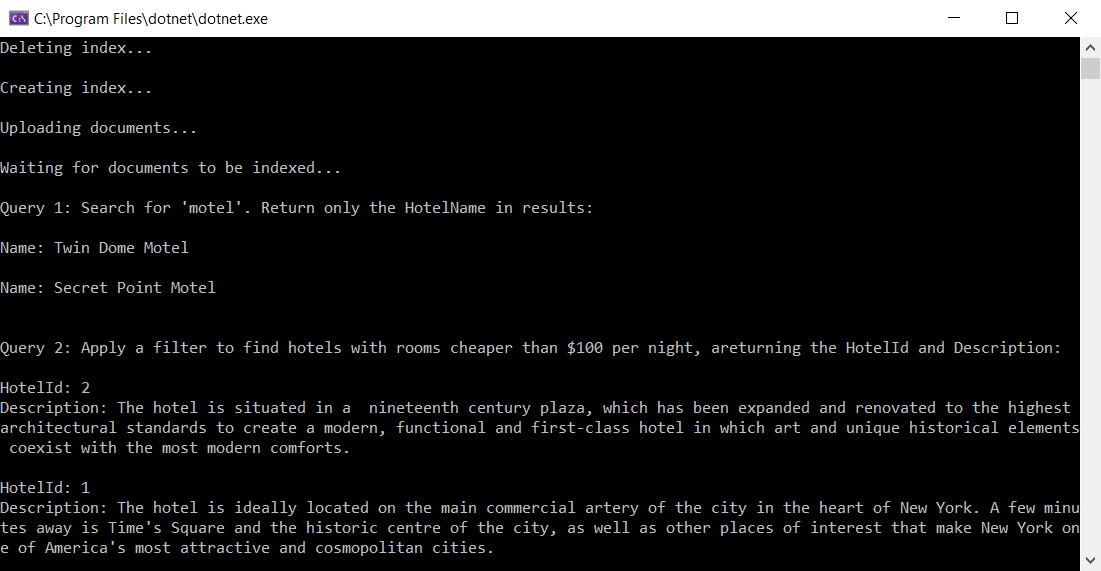
Voici une capture d’écran partielle de la sortie, en supposant que vous exécutez cette application avec un nom de service et des clés API valides :
Types de clients
La bibliothèque de client utilise trois types de client pour diverses opérations : SearchIndexClient pour créer, mettre à jour ou supprimer des index, SearchClient pour charger ou interroger un index, et SearchIndexerClient pour utiliser des indexeurs et des ensembles de compétences. Cet article est consacré aux deux premières.
Au minimum, tous les clients exigent le nom ou le point de terminaison du service ainsi qu’une clé API. Il est courant de fournir ces informations dans un fichier de configuration, qui sont similaires à ce que vous trouvez dans le fichier appsettings.json de l’exemple d’application DotNetHowTo. Pour lire à partir du fichier de configuration, ajoutez using Microsoft.Extensions.Configuration; à votre programme.
L’instruction suivante crée le client d’index utilisé pour créer, mettre à jour ou supprimer des index. Elle utilise un point de terminaison de service et une clé API d’administrateur.
private static SearchIndexClient CreateSearchIndexClient(IConfigurationRoot configuration)
{
string searchServiceEndPoint = configuration["YourSearchServiceEndPoint"];
string adminApiKey = configuration["YourSearchServiceAdminApiKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceEndPoint), new AzureKeyCredential(adminApiKey));
return indexClient;
}
L’instruction suivant crée le client de recherche utilisé pour charger des documents ou exécuter des requêtes. SearchClient nécessite un index. Vous avez besoin d’une clé API d’administration pour charger les documents, mais vous pouvez utiliser une clé API de requête pour exécuter des requêtes.
string indexName = configuration["SearchIndexName"];
private static SearchClient CreateSearchClientForQueries(string indexName, IConfigurationRoot configuration)
{
string searchServiceEndPoint = configuration["YourSearchServiceEndPoint"];
string queryApiKey = configuration["YourSearchServiceQueryApiKey"];
SearchClient searchClient = new SearchClient(new Uri(searchServiceEndPoint), indexName, new AzureKeyCredential(queryApiKey));
return searchClient;
}
Remarque
Si vous fournissez une clé non valide pour l’opération d’importation (par exemple, une clé de requête là où une clé d’administration était demandée), SearchClient lève une CloudException avec le message d’erreur Forbidden la première fois que vous appelez une méthode d’opération dessus. Si cette situation se produit, vérifiez la clé API.
Supprimer l’index.
Dans les premières étapes du développement, vous souhaiterez peut-être inclure une instruction DeleteIndex pour supprimer un index de transition afin de pouvoir le recréer avec une définition mise à jour. L’exemple de code pour Recherche Azure AI comporte souvent une étape de suppression qui vous permet de réexécuter l’exemple.
La ligne suivante appelle DeleteIndexIfExists :
Console.WriteLine("{0}", "Deleting index...\n");
DeleteIndexIfExists(indexName, indexClient);
Cette méthode utilise l’élément SearchIndexClient donné pour vérifier si l’index existe et, dans l’affirmative, elle le supprime :
private static void DeleteIndexIfExists(string indexName, SearchIndexClient indexClient)
{
try
{
if (indexClient.GetIndex(indexName) != null)
{
indexClient.DeleteIndex(indexName);
}
}
catch (RequestFailedException e) when (e.Status == 404)
{
// Throw an exception if the index name isn't found
Console.WriteLine("The index doesn't exist. No deletion occurred.");
Remarque
L’exemple de code de cet article utilise des méthodes synchrones pour des raisons de simplicité, mais nous vous recommandons d’utiliser des méthodes asynchrones dans vos applications pour qu’elles restent évolutives et réactives. Par exemple, dans la méthode précédente, vous pouvez utiliser DeleteIndexAsync au lieu de DeleteIndex.
Création d'un index
Vous pouvez utiliser SearchIndexClient pour créer un index.
La méthode suivante crée un objet SearchIndex avec une liste d’objets SearchField qui définit le schéma du nouvel index. Chaque champ a un nom, un type de données et plusieurs attributs qui définissent son comportement de recherche.
Les champs peuvent être définis à partir d’une classe de modèle à l’aide de FieldBuilder. La classe FieldBuilder utilise la réflexion pour créer une liste d’objets SearchField pour l’index en examinant les attributs et propriétés publics de la classe de modèle Hotel donnée. Nous examinerons la classe Hotel plus en détail un peu plus tard.
private static void CreateIndex(string indexName, SearchIndexClient indexClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
indexClient.CreateOrUpdateIndex(definition);
}
En plus des champs, vous pouvez ajouter des profils de notation, des générateurs de suggestions ou des options CORS à l’index (ces paramètres sont omis de l’exemple par souci de concision). Vous trouverez plus d’informations sur l’objet SearchIndex et ses composants dans la liste des propriétés SearchIndex et dans les Informations de référence sur l’API REST.
Remarque
Vous pouvez toujours créer directement la liste des objets Field au lieu d’utiliser la fonctionnalité FieldBuilder, si nécessaire. Par exemple, vous ne voudrez peut-être pas utiliser une classe de modèle, ou vous aurez peut-être besoin de recourir à une classe de modèle existante que vous ne souhaitez pas modifier en ajoutant des attributs.
Appeler CreateIndex dans Main()
Main crée un index hotels en appelant la méthode précédente :
Console.WriteLine("{0}", "Creating index...\n");
CreateIndex(indexName, indexClient);
Utiliser une classe de modèle pour la représentation des données
L’exemple DotNetHowTo utilise des classes de modèle pour les structures de données Hotel, Address et Room. Hotel fait référence à Address, un type complexe à un niveau (un champ à plusieurs parties) et Room (une collection de champs à plusieurs parties).
Vous pouvez utiliser ces types pour créer et charger l’index ainsi que pour structurer la réponse à partir d’une requête :
// Use-case: <Hotel> in a field definition
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
// Use-case: <Hotel> in a response
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
Une autre approche consiste à ajouter directement des champs à un index. L'exemple suivant ne montre que quelques champs.
SearchIndex index = new SearchIndex(indexName)
{
Fields =
{
new SimpleField("hotelId", SearchFieldDataType.String) { IsKey = true, IsFilterable = true, IsSortable = true },
new SearchableField("hotelName") { IsFilterable = true, IsSortable = true },
new SearchableField("hotelCategory") { IsFilterable = true, IsSortable = true },
new SimpleField("baseRate", SearchFieldDataType.Int32) { IsFilterable = true, IsSortable = true },
new SimpleField("lastRenovationDate", SearchFieldDataType.DateTimeOffset) { IsFilterable = true, IsSortable = true }
}
};
Définitions des champs
Votre modèle de données dans .NET et le schéma d’index qui lui correspond doivent prendre en charge l’expérience de recherche que vous souhaitez offrir à vos utilisateurs finaux. Chaque objet de niveau supérieur dans .NET, comme la recherche de document dans un index de recherche, correspond à un résultat de recherche qui sera présenté dans votre interface utilisateur. Par exemple, dans une application de recherche d’hôtel, vos utilisateurs voudront peut-être rechercher par nom d’hôtel, équipements d’hôtel ou caractéristiques d’une chambre en particulier.
Dans chaque classe, un champ est défini avec un type de données et des attributs qui déterminent la façon dont il est utilisé. Le nom de chaque propriété publique de chaque classe correspond à un champ portant le même nom dans la définition d’index.
Observez l’extrait de code suivant, qui extrait plusieurs définitions de champs à partir de la classe Hotel. Notez que Address et Rooms sont des types C# qui ont leurs propres définitions de classe (consultez l’exemple de code si vous voulez les voir). Il s’agit de types complexes. Pour plus d’informations, consultez How to model complex types (Modélisation des types complexes).
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[JsonIgnore]
public bool? SmokingAllowed => (Rooms != null) ? Array.Exists(Rooms, element => element.SmokingAllowed == true) : (bool?)null;
[SearchableField]
public Address Address { get; set; }
public Room[] Rooms { get; set; }
Choisir une classe de champ
Lors de la définition des champs, vous pouvez utiliser la classe SearchField de base ou bien des modèles d’assistance dérivés qui servent de modèles, avec des propriétés préconfigurées.
Un seul champ de votre index doit servir de clé de document (IsKey = true). Il doit s’agir d’une chaîne qui identifie chaque document de manière unique. Il est également nécessaire d’avoir IsHidden = true, ce qui signifie qu’il ne peut pas être visible dans les résultats de recherche.
| Type de champ | Description et utilisation |
|---|---|
SearchField |
Classe de base, avec la plupart des propriétés définies sur null, à l’exception de Name, qui est obligatoire, et de AnalyzerName dont la valeur par défaut est Lucene standard. |
SimpleField |
Modèle d’assistance. Peut être n’importe quel type de données, ne peut jamais faire l’objet d’une recherche (il est ignoré pour les requêtes de recherche de texte intégral) et peut être récupéré (il n’est pas masqué). Les autres attributs sont désactivés par défaut, mais peuvent être activés. Vous pouvez utiliser un SimpleField pour les ID de document ou les champs utilisés seulement dans des filtres, des facettes ou des profils de scoring. Dans ce cas, veillez à appliquer tous les attributs nécessaires pour le scénario, comme IsKey = true pour un ID de document. Pour plus d’informations, consultez SimpleFieldAttribute.cs dans le code source. |
SearchableField |
Modèle d’assistance. Doit être une chaîne, et peut toujours faire l’objet d’une recherche et d’une récupération. Les autres attributs sont désactivés par défaut, mais peuvent être activés. Comme ce type de champ peut faire l’objet d’une recherche, il prend en charge les synonymes et l’ensemble complet des propriétés de l’analyseur. Pour plus d’informations, consultez SearchableFieldAttribute.cs dans le code source. |
Que vous utilisiez l’API SearchField de base ou un des modèles d’assistance, vous devez activer explicitement les attributs de filtre, de facette et de tri. Par exemple, IsFilterable, IsSortable et IsFacetable doivent être explicitement attribués, comme illustré dans l’exemple précédent.
Ajouter des attributs de champ
Notez que chaque champ comporte des attributs tels que IsFilterable, IsSortable, IsKey et AnalyzerName. Ces attributs sont mappés directement aux attributs de champs correspondants dans un index Recherche Azure AI. La classe FieldBuilder utilise ces propriétés pour construire des définitions de champ pour l’index.
Mappage de types de champ
Les types .NET des propriétés correspondent à leurs types de champ équivalents dans la définition d’index. Par exemple, la propriété de chaîne Category correspond au champ category, qui est de type Edm.String. Il existe des mappages de type similaire entre bool?, Edm.Boolean, DateTimeOffset? et Edm.DateTimeOffset, etc.
Avez-vous remarqué la propriété SmokingAllowed ?
[JsonIgnore]
public bool? SmokingAllowed => (Rooms != null) ? Array.Exists(Rooms, element => element.SmokingAllowed == true) : (bool?)null;
L’attribut JsonIgnore de cette propriété indique au FieldBuilder de ne pas la sérialiser sur l’index en tant que champ. C’est un excellent moyen de créer des propriétés calculées côté client que vous pouvez utiliser comme helpers dans votre application. Dans ce cas, la propriété SmokingAllowed indique s’il est permis de fumer dans l’une des Room de la collection Rooms. Si la valeur est false partout, cela signifie qu’il est interdit de fumer dans tout l’hôtel.
Charger un index
La prochaine étape dans Main remplit l’index hotels qui vient d’être créé. Ce remplissage d’index s’effectue dans la méthode suivante : (Une partir du code a été remplacée par ... à des fins d’illustration. Pour le code complet de remplissage des données, voir l’exemple complet de la solution.)
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Stay-Kay City Hotel",
...
Address = new Address()
{
StreetAddress = "677 5th Ave",
...
},
Rooms = new Room[]
{
new Room()
{
Description = "Budget Room, 1 Queen Bed (Cityside)",
...
},
new Room()
{
Description = "Budget Room, 1 King Bed (Mountain View)",
...
},
new Room()
{
Description = "Deluxe Room, 2 Double Beds (City View)",
...
}
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Old Century Hotel",
...
{
StreetAddress = "140 University Town Center Dr",
...
},
Rooms = new Room[]
{
new Room()
{
Description = "Suite, 2 Double Beds (Mountain View)",
...
},
new Room()
{
Description = "Standard Room, 1 Queen Bed (City View)",
...
},
new Room()
{
Description = "Budget Room, 1 King Bed (Waterfront View)",
...
}
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Gastronomic Landscape Hotel",
...
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
...
},
Rooms = new Room[]
{
new Room()
{
Description = "Standard Room, 2 Queen Beds (Amenities)",
...
},
new Room ()
{
Description = "Standard Room, 2 Double Beds (Waterfront View)",
...
},
new Room()
{
Description = "Deluxe Room, 2 Double Beds (Cityside)",
...
}
}
}
};
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// Sometimes when your Search service is under load, indexing will fail for some of the documents in
// the batch. Depending on your application, you can take compensating actions like delaying and
// retrying. For this simple demo, we just log the failed document keys and continue.
Console.WriteLine("Failed to index some of the documents: {0}");
}
Console.WriteLine("Waiting for documents to be indexed...\n");
Thread.Sleep(2000);
Cette méthode présente quatre parties. La première crée un tableau de trois Hotelobjets contenant chacun troisRoom objets qui servent de données d’entrée à charger dans l’index. Ces données sont codées en dur pour plus de simplicité. Dans une vraie application, les données sont probablement issues d’une source de données externe, comme une base de données SQL.
La deuxième partie crée un IndexDocumentsBatch contenant les documents. Vous spécifiez l’opération que vous souhaitez appliquer au lot au moment de sa création, dans ce cas en appelant IndexDocumentsAction.Upload. Le lot est ensuite chargé dans l’index Recherche Azure AI par la méthode IndexDocuments.
Remarque
Dans cet exemple, vous chargez juste les documents. Si vous souhaitez fusionner les modifications dans les documents existants ou supprimer des documents, vous pouvez créer des lots en appelant IndexDocumentsAction.Merge, IndexDocumentsAction.MergeOrUpload ou IndexDocumentsAction.Delete à la place. Vous pouvez aussi combiner plusieurs opérations dans un lot unique en appelant IndexBatch.New, qui accepte une collection d’objets IndexDocumentsAction, dont chacun indique à Recherche Azure AI d’effectuer une opération spécifique sur un document. Vous pouvez créer chaque IndexDocumentsAction avec sa propre opération en appelant la méthode correspondante comme IndexDocumentsAction.Merge, IndexAction.Upload, et ainsi de suite.
La troisième partie de cette méthode est un bloc catch qui gère un cas d'erreur important pour l'indexation. Si votre service de recherche échoue à indexer certains documents du lot, une exception RequestFailedException est générée. Une exception peut se produire si vous indexez des documents alors que votre service est soumis à une forte charge. Nous vous recommandons vivement de prendre en charge explicitement ce cas de figure dans votre code. Vous pouvez retarder puis relancer l'indexation des documents qui ont échoué, ouvrir une session et continuer comme dans l’exemple, ou faire autre chose selon la cohérence des données requise par votre application. Une alternative consiste à utiliser SearchIndexingBufferedSender pour le traitement par lot intelligent, le vidage automatique et les nouvelles tentatives pour les actions d’indexation ayant échoué. Pour plus de contexte, consultez l’exemple SearchIndexingBufferedSender.
Enfin, la méthode UploadDocuments retarde son exécution de deux secondes. L’indexation s’exécutant en mode asynchrone dans votre service de recherche, l’exemple d’application doit attendre quelque temps afin de s’assurer que les documents sont disponibles pour la recherche. Ce genre de retard n’est nécessaire que dans les démonstrations, les tests et les exemples d'applications.
Appeler UploadDocuments dans Main()
L’extrait de code suivant configure une instance de SearchClient à l’aide de la méthode GetSearchClient de indexClient. indexClient utilise une clé API d’administrateur sur ses requêtes, ce qui est nécessaire pour charger ou actualiser des documents.
Une autre approche consiste à appeler SearchClient directement, en transmettant une clé API d’administrateur sur AzureKeyCredential.
SearchClient searchClient = indexClient.GetSearchClient(indexName);
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(searchClient);
Exécuter des requêtes
Premièrement, configurez un SearchClient qui lit le point de terminaison de service et la clé API de requête à partir de appsettings.json :
private static SearchClient CreateSearchClientForQueries(string indexName, IConfigurationRoot configuration)
{
string searchServiceEndPoint = configuration["YourSearchServiceEndPoint"];
string queryApiKey = configuration["YourSearchServiceQueryApiKey"];
SearchClient searchClient = new SearchClient(new Uri(searchServiceEndPoint), indexName, new AzureKeyCredential(queryApiKey));
return searchClient;
}
Deuxièmement, définissez une méthode qui envoie une demande de requête.
Chaque fois qu’elle exécute une requête, la méthode crée un objet SearchOptions. Cet objet permet de spécifier des options supplémentaires pour la requête, comme le tri, le filtrage, la pagination et la génération de facettes. Dans cette méthode, nous définissons les propriétés Filter, Select et OrderBy pour différentes requêtes. Pour plus d’informations sur la syntaxe des requêtes de recherche, consultez Syntaxe de requête simple.
L'étape suivante est l'exécution de la requête. La recherche est exécutée à l’aide de la méthode SearchClient.Search. Pour chaque requête, transmettez le texte de recherche à utiliser en tant que chaîne (ou à défaut l’élément "*") ainsi que les options de recherche créées précédemment. Nous spécifions également Hotel comme paramètre de type pour SearchClient.Search, qui demande au SDK de désérialiser les documents figurant dans les résultats de recherche, en objets de type Hotel.
private static void RunQueries(SearchClient searchClient)
{
SearchOptions options;
SearchResults<Hotel> results;
Console.WriteLine("Query 1: Search for 'motel'. Return only the HotelName in results:\n");
options = new SearchOptions();
options.Select.Add("HotelName");
results = searchClient.Search<Hotel>("motel", options);
WriteDocuments(results);
Console.Write("Query 2: Apply a filter to find hotels with rooms cheaper than $100 per night, ");
Console.WriteLine("returning the HotelId and Description:\n");
options = new SearchOptions()
{
Filter = "Rooms/any(r: r/BaseRate lt 100)"
};
options.Select.Add("HotelId");
options.Select.Add("Description");
results = searchClient.Search<Hotel>("*", options);
WriteDocuments(results);
Console.Write("Query 3: Search the entire index, order by a specific field (lastRenovationDate) ");
Console.Write("in descending order, take the top two results, and show only hotelName and ");
Console.WriteLine("lastRenovationDate:\n");
options =
new SearchOptions()
{
Size = 2
};
options.OrderBy.Add("LastRenovationDate desc");
options.Select.Add("HotelName");
options.Select.Add("LastRenovationDate");
results = searchClient.Search<Hotel>("*", options);
WriteDocuments(results);
Console.WriteLine("Query 4: Search the HotelName field for the term 'hotel':\n");
options = new SearchOptions();
options.SearchFields.Add("HotelName");
//Adding details to select, because "Location" isn't supported yet when deserializing search result to "Hotel"
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Description");
options.Select.Add("Category");
options.Select.Add("Tags");
options.Select.Add("ParkingIncluded");
options.Select.Add("LastRenovationDate");
options.Select.Add("Rating");
options.Select.Add("Address");
options.Select.Add("Rooms");
results = searchClient.Search<Hotel>("hotel", options);
WriteDocuments(results);
}
Troisièmement, définissez une méthode qui écrit la réponse, en imprimant chaque document sur la console :
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
Appeler RunQueries dans Main()
SearchClient indexClientForQueries = CreateSearchClientForQueries(indexName, configuration);
Console.WriteLine("{0}", "Running queries...\n");
RunQueries(indexClientForQueries);
Explorer les constructions de requête
Examinons de plus près chacune des requêtes exécutées. Voici le code permettant d’exécuter la première requête :
options = new SearchOptions();
options.Select.Add("HotelName");
results = searchClient.Search<Hotel>("motel", options);
WriteDocuments(results);
Dans le cas présent, nous recherchons dans l’intégralité de l’index le mot motel, dans tous les champs pouvant faire l’objet d’une recherche, et ne voulons récupérer que les noms d’hôtel, comme spécifié par l’option Select. Voici les résultats :
Name: Stay-Kay City Hotel
Name: Old Century Hotel
Dans la deuxième requête, utilisez un filtre pour sélectionner des chambres dont le tarif est inférieur à 100 USD. Renvoyez uniquement l’ID de l’hôtel et la description dans les résultats :
options = new SearchOptions()
{
Filter = "Rooms/any(r: r/BaseRate lt 100)"
};
options.Select.Add("HotelId");
options.Select.Add("Description");
results = searchClient.Search<Hotel>("*", options);
Cette requête utilise une expression $filter OData (Rooms/any(r: r/BaseRate lt 100)) pour filtrer les documents dans l’index. Il utilise l’opérateur any pour appliquer « BaseRate lt 100 » à chaque élément de la collection Rooms (Chambres). Pour plus d’informations, voir Syntaxe de filtre OData.
Dans la troisième requête, recherchez les deux hôtels ayant été le plus récemment rénovés, et affichez le nom et la date de la dernière rénovation de ces derniers. Voici le code :
options =
new SearchOptions()
{
Size = 2
};
options.OrderBy.Add("LastRenovationDate desc");
options.Select.Add("HotelName");
options.Select.Add("LastRenovationDate");
results = searchClient.Search<Hotel>("*", options);
WriteDocuments(results);
Dans la dernière requête, recherchez tous les noms d’hôtel contenant le mot hotel :
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Description");
options.Select.Add("Category");
options.Select.Add("Tags");
options.Select.Add("ParkingIncluded");
options.Select.Add("LastRenovationDate");
options.Select.Add("Rating");
options.Select.Add("Address");
options.Select.Add("Rooms");
results = searchClient.Search<Hotel>("hotel", options);
WriteDocuments(results);
Cette section conclut la présentation du SDK .NET, mais ne vous arrêtez pas en si bon chemin. La section suivante propose d’autres ressources pour en savoir plus sur la programmation avec Recherche Azure AI.
Contenu connexe
Parcourez la documentation de référence de l’API pour Azure.Search.Documents et API REST
Parcourez d’autres exemples de code basés sur Azure.Search.Documents dans azure-search-dotnet-samples et search-dotnet-getting-started
Consultez les conventions d’affectation de noms pour apprendre les règles de dénomination des différents objets.
Consultez les types de données pris en charge