Exécuter ou réinitialiser des indexeurs, des compétences ou des documents
Dans la recherche cognitive Azure AI, il existe plusieurs façons d’exécuter un indexeur :
- Exécuter immédiatement lors de la création de l’indexeur, en supposant qu’il n’est pas créé en mode « désactivé ».
- Exécuter selon une planification pour invoquer l’exécution à intervalles réguliers.
- Exécuter à la demande, avec ou sans « réinitialisation ».
Cet article explique comment exécuter des indexeurs à la demande, avec et sans réinitialisation. Elle décrit également l’exécution de l’indexeur, la durée et la concurrence.
Comment les indexeurs se connectent à des ressources Azure
Les indexeurs sont l’un des rares sous-systèmes qui effectuent des appels sortants explicites vers d’autres ressources Azure. En termes de rôles Azure, les indexeurs n’ont pas d’identités distinctes : une connexion du moteur de recherche à une autre ressource Azure est effectuée à l’aide de l’identité managée affectée par le système ou affectée par l’utilisateur d’un service de recherche. Si l’indexeur se connecte à une ressource Azure sur un réseau virtuel, vous devez créer une liaison privée partagée pour cette connexion. Pour plus d’informations sur les connexions sécurisées, consultez Sécurité dans Recherche Azure AI.
Exécution de l’indexeur
Un service de recherche exécute un travail d’indexeur par unité de recherche. Chaque service de recherche commence par une unité de recherche, mais chaque nouvelle partition ou réplica augmente les unités de recherche de votre service. Vous pouvez vérifier le nombre d’unités de recherche dans la section Essentiel de la page Vue d’ensemble du portail Azure. Si vous avez besoin d’un traitement simultané, assurez-vous que vos unités de recherche incluent suffisamment de réplicas. Les indexeurs ne s’exécutent pas en arrière-plan. Vous pouvez donc détecter plus de limitation des requêtes que d’habitude si le service est sous pression.
La capture d’écran suivante montre le nombre d’unités de recherche, qui détermine le nombre d’indexeurs pouvant s’exécuter simultanément.

Une fois l’exécution de l’indexeur démarrée, vous ne pouvez pas la suspendre ou l’arrêter. L’exécution de l’indexeur s’arrête lorsqu’il n’y a plus de documents à charger ou à actualiser, ou lorsque la limite de durée maximale d’exécution est atteinte.
Vous pouvez exécuter plusieurs indexeurs en même temps en supposant une capacité suffisante, mais chaque indexeur est une instance unique. Le démarrage d’une nouvelle instance alors que l’indexeur est déjà en cours d’exécution génère cette erreur : "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed.".
Environnement d’exécution des indexeurs
Un travail d’indexation s’exécute dans un environnement d’exécution managé. Actuellement, il existe deux environnements :
Un environnement d’exécution privé s’exécute sur les clusters de recherche spécifiques à votre service de recherche. Si votre service de recherche est Standard2 ou supérieur, vous pouvez définir le paramètre
executionEnvironmentdans la définition de l’indexeur pour toujours exécuter un indexeur dans l’environnement d’exécution privée.Un environnement multilocataires possède des processeurs de contenu gérés et sécurisés par Microsoft, sans frais supplémentaires. Cet environnement est utilisé pour décharger le traitement gourmand en calculs, en laissant les ressources spécifiques au service disponibles pour les opérations de routine. Dans la mesure du possible, la plupart des ensembles de compétences s’exécutent dans l’environnement multilocataire. Il s’agit de la valeur par défaut.
Traitement avec calcul intensif fait référence à des ensembles de compétences s’exécutant sur des processeurs de contenu, et à des travaux d’indexeur qui traitent un volume élevé de documents ou des documents de grande taille. Le traitement d’ensembles de compétences sur les processeurs de contenu multilocataire est déterminé par des heuristiques et des informations système et n’est pas sous contrôle client. Les services S2 et les versions ultérieures prennent en charge l’épinglage d’un indexeur et d’un ensemble de compétences exclusivement à vos clusters de recherche via le paramètre
executionEnvironment.Remarque
Les pare-feux IP bloquent l’environnement multilocataire. Par conséquent, si vous disposez d’un pare-feu, créez une règle qui autorise le traitement multilocataire.
Les limites de l’indexeur varient pour chaque environnement :
| Charge de travail | Durée maximale | Nombre maximal de travaux | Environnement d’exécution |
|---|---|---|---|
| Exécution privée | 24 heures | Un travail d'indexeur par unité de recherche 1. | L’indexation ne s’exécute pas en arrière-plan. Au lieu de cela, le service de recherche équilibre tous les travaux d’indexation par rapport aux requêtes en cours et aux actions de gestion des objets (telles que la création ou la mise à jour des index). Lorsque vous exécutez des indexeurs, vous devez vous attendre à une certaine latence des requêtes si les volumes d’indexation sont importants. |
| Multi-locataire | 2 heures 2 | Indéterminé 3 | Étant donné que le cluster de traitement du contenu est multilocataires, les processeurs de contenu sont ajoutés pour répondre à la demande. Si vous rencontrez un retard dans une exécution planifiée ou à la demande, c’est probablement parce que le système ajoute des processeurs ou attend qu’un nœud soit disponible. |
1 Les unités de recherche peuvent être des combinaisons flexibles de partitions et de réplicas, mais les travaux d’indexation ne sont pas liés les uns aux autres. En d’autres termes, si vous avez 12 unités, vous pouvez avoir simultanément 12 travaux d’indexation basés en exécution privée, quelle que soit la façon dont les unités de recherche sont déployées.
2 Si plus de deux heures sont nécessaires pour traiter toutes les données, activez la détection des modifications et planifiez l’exécution de l’indexeur à 5 minutes pour reprendre l’indexation rapidement si elle s’arrête en raison d’un délai d’attente. Pour plus d’informations sur les stratégies, consultez Indexation d’un jeu de données volumineux.
3 « Indéterminé » signifie que la limite n’est pas quantifiée par le nombre de travaux. Certaines charges de travail, telles que le traitement de l’ensemble de compétences, peuvent s’exécuter en parallèle, ce qui peut entraîner de nombreux travaux, même si un seul indexeur est impliqué. Bien que l’environnement n’impose pas de contraintes, les limites de l’indexeur pour votre service de recherche s’appliquent toujours.
Exécuter sans réinitialisation
Une opération Exécuter l’indexeur détectera et traitera uniquement ce qui est nécessaire pour synchroniser l’index de recherche avec les modifications de la source de données sous-jacente. L’indexation incrémentale commence par la localisation d’une limite supérieure interne afin de trouver le dernier document de recherche mis à jour, qui devient le point de départ de l’exécution de l’indexeur sur les documents nouveaux et mis à jour dans la source de données.
La détection des modifications est essentielle pour déterminer ce qui est nouveau ou mis à jour dans la source de données. Les indexeurs utilisent les fonctionnalités de détection des modifications de la source de données sous-jacente pour déterminer ce qui est nouveau ou mis à jour dans la source de données.
Le stockage Azure intègre la détection des modifications par le biais de sa propriété LastModified.
D’autres sources de données, telles qu’Azure SQL ou Azure Cosmos DB, doivent être configurées pour la détection des modifications avant que l’indexeur puisse lire uniquement les nouvelles lignes et celles mises à jour.
Si le contenu sous-jacent est inchangé, une opération d’exécution n’a aucun effet. Dans ce cas, l’historique d’exécution de l’indexeur indique les 0\0 documents traités.
Vous devez réinitialiser l’indexeur, comme expliqué dans la section suivante, pour effectuer un retraitement complet.
Réinitialisation des indexeurs
Après l’exécution initiale, un indexeur garde la trace des documents de recherche qui ont été indexés à l’aide d’une limite supérieure interne. Le marqueur n’est jamais exposé, mais en interne, l’indexeur sait à quel endroit il s’est arrêté.
Si vous devez régénérer tout ou partie d’un index, vous pouvez effacer la limite supérieure de l’indexeur grâce à une réinitialisation. Les API de réinitialisation sont disponibles à des niveaux décroissants dans la hiérarchie d’objets :
- Réinitialiser les indexeurs efface la limite supérieure et effectue une réindexation complète de tous les documents.
- Réinitialiser les documents (préversion) réindexe un document spécifique ou une liste de documents.
- Réinitialiser les compétences (préversion) appelle le traitement des compétences pour une compétence spécifique.
Après la réinitialisation, continuez avec une commande Run pour retraiter les documents nouveaux et existants. Les documents de recherche orphelins qui n’ont pas d’équivalent dans la source de données ne peuvent pas être supprimés par réinitialisation/exécution. Si vous devez supprimer des documents, consultez plutôt Documents – Index.
Comment réinitialiser et exécuter les indexeurs
La réinitialisation efface la limite supérieure. Tous les documents de l’index de recherche sont marqués d’un indicateur de remplacement complet, sans mise à jour en ligne ni fusion avec le contenu existant. Pour les indexeurs avec un ensemble de compétences et une mise en cache d’enrichissement, la réinitialisation de l’index réinitialise également l’ensemble de compétences de manière implicite.
Le travail réel se produit lorsque vous faites suivre une réinitialisation d’une commande Run :
- Tous les nouveaux documents trouvés dans la source sous-jacente sont ajoutés à l’index de recherche.
- Tous les documents qui existent à la fois dans la source de données et dans l’index de recherche seront remplacés dans l’index de recherche.
- Tout contenu enrichi créé à partir d’ensembles de compétences sera régénéré. Le cache d’enrichissement, s’il est activé, est actualisé.
Comme indiqué précédemment, la réinitialisation est une opération passive : vous devez la faire suivre d’une requête Run pour régénérer l’index.
Les opérations de réinitialisation/d’exécution s’appliquent à un index de recherche ou à une base de connaissances, à des documents ou à des projections spécifiques, ainsi qu’aux enrichissements mis en cache si une réinitialisation inclut explicitement ou implicitement des compétences.
La réinitialisation s’applique également aux opérations de création et de mise à jour. Elle ne déclenche pas la suppression ni le nettoyage des documents orphelins dans l’index de recherche. Pour plus d’informations sur la suppression de documents, consultez Documents – Index.
Une fois que vous avez réinitialisé un indexeur, vous ne pouvez pas annuler l’action.
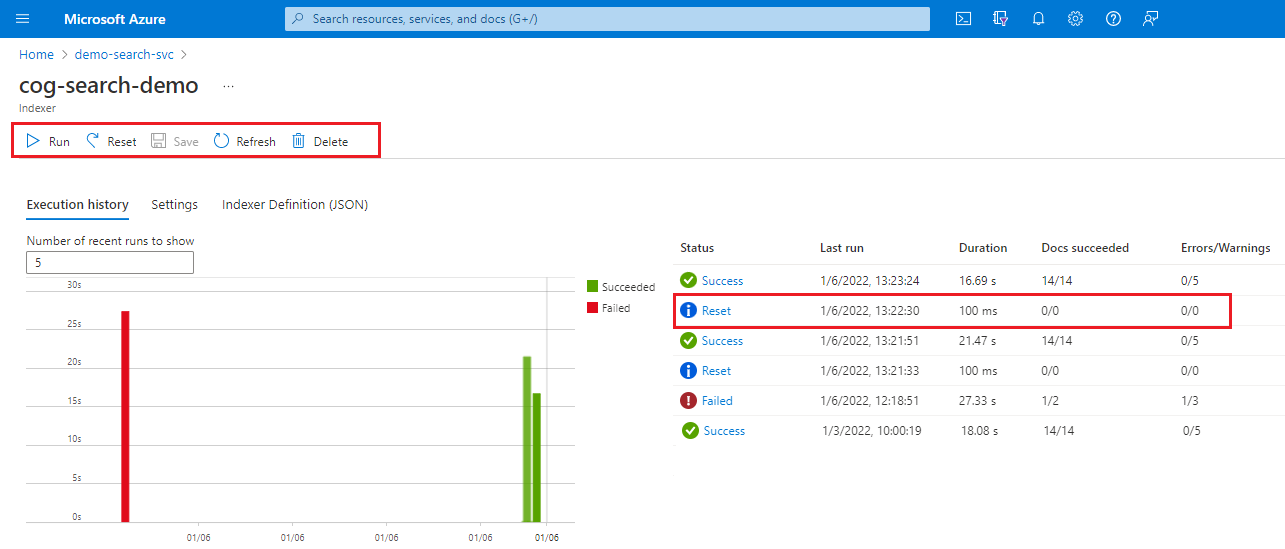
Connectez-vous au portail Azure et ouvrez la page du service de recherche.
Dans la page Vue d’ensemble, sélectionnez l’onglet Indexeurs.
Sélectionnez un indexeur.
Sélectionnez la commande Reset, puis cliquez sur Oui pour confirmer l’action.
Actualisez la page pour afficher l’état. Vous pouvez sélectionner l’élément pour en afficher les détails.
Sélectionnez Exécuter pour démarrer le traitement de l’indexeur, ou attendez la prochaine exécution planifiée.
Comment réinitialiser les compétences (préversion)
Pour les indexeurs qui ont des ensembles de compétences, vous pouvez réinitialiser les compétences individuelles pour forcer le traitement de cette compétence et de toute compétence en aval qui dépend de sa sortie. Le cache d’enrichissement, si vous l’avez activé, est également actualisé.
Réinitialiser les compétences est actuellement disponible uniquement en mode REST, via 2020-06-30-preview ou une version ultérieure. Nous vous recommandons l’API dans la préversion la plus récente.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Vous pouvez spécifier des compétences individuelles, comme indiqué dans l’exemple ci-dessus, mais si l’une de ces compétences requiert la sortie de compétences non répertoriées (« #2 » à « #4 »), les compétences non répertoriées sont exécutées, sauf si le cache peut fournir les informations nécessaires. Pour que cela soit vrai, les enrichissements mis en cache pour les compétences « #2 » à « #4 » ne doivent pas avoir de dépendances vis-à-vis de la compétence « #1 » (répertoriée pour la réinitialisation).
Si aucune compétence n’est spécifiée, la totalité de l’ensemble de compétences est exécutée et, si la mise en cache est activée, le cache est également actualisé.
N’oubliez pas de faire suivre par Exécuter l’indexeur pour appeler le traitement réel.
Comment réinitialiser les documents (préversion)
Les Indexeurs – Réinitialiser les documents acceptent une liste de clés de document afin que vous puissiez actualiser des documents spécifiques. S’ils sont spécifiés, les paramètres de réinitialisation deviennent le seul déterminant de ce qui est traité, quelles que soient les autres modifications apportées aux données sous-jacentes. Par exemple, si 20 blobs ont été ajoutés ou mis à jour depuis la dernière exécution de l’indexeur, mais que vous ne réinitialisez qu’un seul document, seul ce document est traité.
Pour chaque document, tous les champs de ce document de recherche sont actualisés avec les valeurs de la source de données. Vous ne pouvez pas choisir les champs à actualiser.
Si le document est enrichi par le biais d’un ensemble de compétences et contient des données en cache, l’ensemble de compétences est appelé uniquement pour les documents spécifiés, et le cache est mis à jour pour les documents retraités.
Lorsque vous testez cette API pour la première fois, les API suivantes peuvent vous aider à valider et à tester les comportements. Vous pouvez utiliser les préversions de l’API 2020-06-30-preview et ultérieures. Nous vous recommandons l’API dans la préversion la plus récente.
Appelez Indexeurs – Obtenir l’état avec une version d’API en préversion pour vérifier l’état de réinitialisation et l’état d’exécution. Vous pouvez trouver des informations sur la demande de réinitialisation à la fin de la réponse d’état.
Appelez Indexeurs – Réinitialiser les documents avec une version d’API en préversion pour spécifier les documents à traiter.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }Les clés de document fournies dans la demande sont des valeurs de l’index de recherche, qui peuvent être différentes des champs correspondants dans la source de données. Si vous n’êtes pas sûr de la valeur de la clé, envoyez une requête pour retourner la valeur. Vous pouvez utiliser
selectpour retourner seulement le champ de la clé du document.Pour les blobs analysés dans plusieurs documents de recherche (où parsingMode est défini sur jsonLines ou jsonArrays ou delimitedText), la clé de document est générée par l’indexeur et peut vous être inconnue. Dans ce scénario, une requête pour la clé de document retourne la valeur correcte.
Appelez Exécuter l’indexeur (toute version d’API) pour traiter les documents que vous avez spécifiés. Seuls ces documents spécifiques sont indexés.
Appelez Exécuter l’indexeur une deuxième fois pour traiter les documents à partir de la dernière limite supérieure.
Appelez Rechercher des documents pour rechercher les valeurs mises à jour, ainsi que pour renvoyer les clés de document si vous n’êtes pas sûr de la valeur. Utilisez
"select": "<field names>"si vous souhaitez limiter les champs qui apparaissent dans la réponse.
Remplacer la liste des clés de document
En appelant l’API Réinitialiser les documents plusieurs fois avec des clés différentes, les nouvelles clés sont ajoutées à la liste des clés de document réinitialisées. L’appel de l’API avec le paramètre overwrite défini sur true remplacera la liste actuelle par la nouvelle :
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Vérifier l’état de réinitialisation « currentState »
Pour vérifier l’état de réinitialisation et voir quelles clés de document sont mises en file d’attente pour traitement, procédez comme suit.
Appelez Obtenir l’état de l’indexeur avec une API en préversion.
L’API de préversion renverra la section
currentState, qui se trouve à la fin de la réponse."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Vérifiez le « mode » :
Pour Réinitialiser les compétences, le « mode » sera
indexingAllDocs(car tous les documents sont potentiellement concernés, en termes de champs renseignés par l’enrichissement par IA).Pour Réinitialiser les documents, le « mode » doit être défini sur
indexingResetDocs. L’indexeur conserve cet état jusqu’à ce que toutes les clés de document fournies dans l’appel de réinitialisation des documents soient traitées, période pendant laquelle aucun autre travail d’indexation ne sera exécuté. Pour trouver tous les documents de la liste des clés de documents, il faut craquer chaque document pour le localiser et le faire correspondre à la clé, ce qui peut prendre un certain temps si le jeu de données est volumineux. Si un conteneur de blobs contient des centaines de blobs et que les documents que vous souhaitez réinitialiser se trouvent à la fin, l’indexeur ne trouvera pas les blobs correspondants tant que tous les autres n’auront pas été vérifiés au préalable.Une fois que les documents ont été retraités, exécutez à nouveau Obtenir l’état de l’indexeur. L’indexeur revient au mode
indexingAllDocset traitera tous les autres documents nouveaux ou mis à jour lors de la prochaine exécution.
Étapes suivantes
Les API de réinitialisation sont utilisées pour indiquer la portée de la prochaine exécution de l’indexeur. Pour le traitement proprement dit, vous devrez invoquer une exécution d’indexeur à la demande ou autoriser un travail planifié pour terminer le travail. Une fois l’exécution terminée, l’indexeur revient au traitement normal, qu’il s’agisse d’un traitement planifié ou d’un traitement à la demande.
Après avoir réinitialisé et réexécuté les travaux d’indexation, vous pouvez surveiller l’état à partir du service de recherche ou obtenir des informations détaillées grâce à la journalisation des ressources.