Comment mettre en forme les résultats dans la Recherche Azure AI
Cet article décrit comment utiliser une réponse de requête dans la Recherche Azure AI. La structure d’une réponse est déterminée par les paramètres de la requête elle-même, comme décrit dans Rechercher dans des documents (REST) ou Classe SearchResults (Azure pour .NET).
Les paramètres de la requête déterminent :
- Sélection de champ
- Nombre de correspondances trouvées dans l’index pour la requête
- Pagination
- Le nombre de résultats dans la réponse (jusqu’à 50, par défaut)
- Ordre de tri
- Mise en surbrillance des termes dans un résultat, en mettant en correspondance la totalité ou une partie du terme dans le corps
Composition des résultats
Les résultats sont tabulaires, composés de champs qui sont « récupérables » ou limités aux champs spécifiés dans les paramètres $select. Les lignes sont les documents correspondants.
Vous pouvez choisir les champs qui se trouvent dans les résultats de la recherche. Bien qu’un document de recherche puisse avoir un grand nombre de champs, en général, seuls quelques-uns sont nécessaires pour représenter chaque document dans les résultats. Dans une demande de requête, ajoutez $select=<field list> pour spécifier les champs « récupérables » qui doivent s’afficher dans la réponse.
Choisissez les champs qui distinguent et différencient les documents, en fournissant suffisamment d’informations pour inviter l’utilisateur à cliquer sur le document. Sur un site d’e-commerce, il peut s’agir d’un nom de produit, d’une description, d’une couleur, d’une taille, d’un prix et d’une évaluation. Pour l’exemple intégré hotels-sample-index, il peut s’agir des champs « select » dans l’exemple suivant :
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City"
"count": true
}
Conseils en cas de résultats inattendus
Parfois, le contenu des résultats de recherche est inattendu. Par exemple, vous constaterez peut-être que certains résultats semblent être des doublons, ou qu’un résultat qui devrait apparaître près du haut est positionné plus bas dans les résultats. Quand les résultats de requête sont inattendus, vous pouvez essayer ces modifications de requête pour voir si les résultats s’améliorent :
Remplacez
searchMode=any(valeur par défaut) parsearchMode=allpour exiger des correspondances sur tous les critères plutôt que sur un seul d’entre eux. Cela s’applique particulièrement quand des opérateurs booléens sont inclus dans la requête.Expérimentez différents analyseurs lexicaux ou analyseurs personnalisés pour déterminer s’ils modifient le résultat de la requête. L’analyseur par défaut fractionne les mots avec tirets et réduit les mots aux formes racines, ce qui améliore généralement la robustesse d’une réponse de requête. Toutefois, si vous devez conserver les tirets ou si des chaînes incluent des caractères spéciaux, vous devrez peut-être configurer des analyseurs personnalisés pour vous assurer que l’index contient des jetons au format approprié. Pour plus d’informations, consultez Recherche de termes partiels et modèles avec des caractères spéciaux (traits d’union, caractères génériques, expressions régulières, modèles).
Comptage des correspondances
Le paramètre de comptage retourne le nombre de documents dans l’index qui correspondent à la requête. Pour retourner le nombre, ajoutez $count=true à la demande de requête. Aucune valeur maximale n’est imposée par le service de recherche. En fonction de la requête et du contenu de vos documents, le nombre peut être aussi élevé que le nombre de documents dans l’index.
Le nombre est précis quand l’index est stable. Si le système ajoute, met à jour ou supprime activement des documents, le comptage est approximatif et exclut les documents qui ne sont pas entièrement indexés.
Le nombre ne sera pas affecté par la maintenance de routine ou d’autres charges de travail sur le service de recherche. Toutefois, si vous disposez de plusieurs partitions et d’un seul réplica, des fluctuations à court terme peuvent se produire concernant le nombre de documents (plusieurs minutes) à mesure que les partitions sont redémarrées.
Conseil
Pour vérifier les opérations d’indexation, vous pouvez confirmer que l’index contient le nombre de documents attendu en ajoutant $count=true à une requête de recherche search=* vide. Le résultat correspond au nombre total de documents dans votre index.
Quand vous testez la syntaxe de requête, $count=true peut rapidement déterminer si vos modifications retournent des résultats supérieurs ou inférieurs, ce qui peut être utile.
Résultats de pagination
Par défaut, le moteur de recherche retourne les 50 premières correspondances. Les 50 premières correspondances sont déterminées par le score de recherche, en supposant que la requête est une recherche en texte intégral ou une recherche sémantique. Dans le cas contraire, les 50 premières correspondances utilisent un ordre arbitraire des requêtes de correspondance exacte (où un « @searchScore=1.0 » uniforme indique un classement arbitraire).
La limite supérieure est de 1 000 documents retournés par page de résultats de recherche. Vous pouvez donc définir la valeur supérieure pour retourner jusqu’à 1 000 documents dans le premier résultat. Dans les API de préversion plus récentes, si vous utilisez une requête hybride, vous pouvez spécifier maxTextRecallSize pour retourner jusqu’à 10 000 documents.
Pour contrôler la pagination de tous les documents renvoyés dans un jeu de résultats, ajoutez les paramètres $top et $skip à la demande de requête GET, ou top et skip à la demande de requête POST. La liste suivante explique la logique.
Retournez le premier jeu de 15 documents correspondants plus un nombre total de correspondances :
GET /indexes/<INDEX-NAME>/docs?search=<QUERY STRING>&$top=15&$skip=0&$count=trueRetournez le deuxième jeu, en ignorant les 15 premiers pour obtenir les 15 suivants :
$top=15&$skip=15. Répétez cette opération pour le troisième ensemble de 15 correspondances :$top=15&$skip=30
Il n’est pas garanti que les résultats des requêtes paginées soient stables si l’index sous-jacent est modifié. La pagination modifie la valeur de $skip pour chaque page, mais chaque requête est indépendante et opère sur l’affichage actuel des données telles qu’elles existent dans l’index au moment de la requête. En d’autres termes, il n’y a aucune mise en cache ni capture instantanée des résultats, comme c’est le cas dans une base de données à usage général.
Voici un exemple de la façon dont vous pouvez obtenir des doublons. Imaginons un index avec quatre documents :
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Supposons à présent que vous souhaitiez que les résultats soient retournés par deux, classés par évaluation. Vous exécuterez cette requête pour obtenir la première page des résultats, $top=2&$skip=0&$orderby=rating desc, et vous obtenez les résultats suivants :
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
Sur le service, supposez qu’un cinquième document est ajouté à l’index entre les appels de requête : { "id": "5", "rating": 4 }. Peu de temps après, vous exécutez une requête pour extraire la deuxième page, $top=2&$skip=2&$orderby=rating desc, et vous obtenez ces résultats :
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Notez que le document 2 est extrait 2 fois. Cela est dû au fait que le nouveau document 5 a une plus grande valeur d’évaluation. Il est donc trié avant le document 2 et atterrit sur la première page. Bien que ce comportement puisse être inattendu, c’est généralement ainsi qu’un moteur de recherche se comporte.
Parcourir un grand nombre de résultats
L’utilisation de $top et $skip permet à une requête de recherche de parcourir 100 000 résultats, mais que se passe-t-il si les résultats sont supérieurs à 100 000 ? Pour parcourir une réponse aussi grande, utilisez un ordre de tri et un filtre de plage comme solution de contournement pour $skip.
Dans cette solution de contournement, un tri et un filtre sont appliqués à un champ d’ID de document ou à un autre champ qui est unique pour chaque document. Le champ unique doit avoir une attribution filterable et sortable dans l’index de recherche.
Envoyez une requête pour obtenir une page complète de résultats triés.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Choisissez le dernier résultat renvoyé par la requête de recherche. L’exemple de résultat indiqué ici a seulement la valeur « id ».
{ "id": "50" }Utilisez cette valeur « id » dans une requête de plage pour récupérer la page suivante des résultats. Ce champ « id » doit avoir des valeurs uniques, sinon la pagination peut contenir des résultats en double.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }La pagination se termine quand la requête renvoie zéro résultat.
Remarque
Les attributs « filterable » et « sortable » peuvent être activés seulement quand un champ est ajouté pour la première fois à un index, ils ne peuvent pas être activés sur un champ existant.
Classement des résultats
Dans une requête de recherche en texte intégral, les résultats peuvent être classés selon :
- un score de recherche
- un score de reclassement sémantique
- un ordre de tri sur un champ « sortable »
Vous pouvez également améliorer toutes les correspondances trouvées dans des champs spécifiques en ajoutant un profil de score.
Trier par score de recherche
Pour les requêtes de recherche en texte intégral, les résultats sont automatiquement classés en fonction d’un score de recherche, calculé sur la base de la fréquence et de la proximité des termes dans un document (valeurs dérivées de TF-IDF), les scores les plus élevés étant attribués aux documents présentant des correspondances plus nombreuses ou plus fortes sur un terme de recherche.
La plage « @search.score » peut être illimitée, ou s’étendre de 0 à (mais non inclus) 1,00 sur les services plus anciens.
Pour les deux algorithmes, un « @search.score » égal à 1.00 indique un jeu de résultats non évalué ou non classé, où le score 1.0 est uniforme pour tous les résultats. Des résultats sans score se produisent quand le formulaire de requête est une recherche approximative, des requêtes Regex ou de caractères génériques, ou une recherche vide (search=*). Si vous devez imposer une structure de classement sur des résultats sans score, vous pouvez utiliser une expression $orderby pour atteindre cet objectif.
Trier avec le reclassement sémantique
Si vous utilisez le classeur sémantique, « @search.rerankerScore » détermine l’ordre de tri de vos résultats.
La plage « @search.rerankerScore » est comprise entre 1 et 4,00, où un score plus élevé indique une correspondance sémantique plus forte.
Trier avec $orderby
Si un tri cohérent est une exigence de l’application, vous pouvez définir une expression $orderby sur un champ. Seuls les champs qui sont indexés en tant que « triables » peuvent être utilisés pour trier les résultats.
Les champs couramment utilisés dans $orderby incluent les champs d’évaluation, de date et d’emplacement. Le filtrage par emplacement nécessite que l’expression de filtre appelle la fonction geo.distance(), en plus du nom de champ.
Les champs numériques (Edm.Double, Edm.Int32, Edm.Int64) sont triés dans l’ordre numérique (par exemple, 1, 2, 10, 11, 20).
Les champs de chaîne (sous-champs Edm.String, Edm.ComplexType) sont triés dans l’ordre de tri ASCII ou dans l’ordre de tri Unicode, selon la langue. Vous ne pouvez trier des collections de n’importe quel type.
Le contenu numérique des champs de chaîne est trié par ordre alphabétique (1, 10, 11, 2, 20).
Les chaînes majuscules sont triées avant la minuscule (APPLE, Apple, BANANA, Banana, Apple, apple, banana). Vous pouvez affecter une normalisation de texte pour prétraiter le texte avant le tri pour modifier ce comportement. L’utilisation du générateur de jetons en minuscules sur un champ n’a pas d’effet sur le comportement de tri, car la Recherche Azure AI effectue le tri sur une copie non analysée du champ.
Les chaînes qui commencent par des signes diacritiques apparaissent en dernier (Äpfel, Öffnen, Üben).
Améliorer la pertinence avec un profil de score
Une autre approche qui favorise la cohérence consiste à utiliser un profil de score personnalisé. Les profils de scoring vous permettent de mieux contrôler le classement des éléments dans les résultats de recherche, avec la possibilité d’augmenter le nombre de correspondances trouvées dans des champs spécifiques. La logique de score supplémentaire peut aider à surmonter les différences mineures entre les réplicas, car les scores de recherche pour chaque document sont plus éloignés les uns des autres. Nous vous recommandons d’utiliser l’algorithme de classement pour cette approche.
Mise en surbrillance des correspondances
La mise en surbrillance des correspondances fait référence à la mise en forme de texte (par exemple, caractères gras ou surlignage jaune) appliquée au terme correspondant dans un résultat, ce qui facilite le repérage de l’occurrence. La mise en surbrillance est utile pour des champs de contenu longs, comme un champ de description, où la correspondance n’est pas immédiatement évidente.
Notez que la mise en surbrillance est appliquée à des termes individuels. Il n’existe pas de fonctionnalité de mise en évidence pour le contenu d’un champ entier. Si vous souhaitez mettre en surbrillance toute une expression, vous devez fournir les termes correspondants (ou l’expression correspondante) dans une chaîne de requête entre guillemets. Cette technique est décrite plus loin dans cette section.
Des instructions pour la mise en surbrillance des correspondances sont fournies dans la demande de requête. Les requêtes qui déclenchent une extension de requête dans le moteur, telles que les recherches floues ou par caractères génériques, offrent une prise en charge limitée de la mise en surbrillance des correspondances.
Conditions de mise en surbrillance des correspondances
- Les champs doivent être de type
Edm.StringouCollection(Edm.String) - Les champs doivent être attribués à possibilité de recherche
Spécifier la mise en évidence dans la requête
Pour retourner des termes mis en évidence, incluez le paramètre « highlight » dans la demande de requête. Le paramètre est défini sur une liste de champs délimités par des virgules.
Par défaut, le format de marquage est <em>, mais vous pouvez remplacer la balise à l’aide de paramètres highlightPreTag et highlightPostTag. Votre code client gère la réponse (par exemple, en appliquant une police en gras ou un arrière-plan jaune).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Par défaut, la Recherche Azure AI renvoie jusqu’à cinq éléments en surbrillance par champ. Vous pouvez ajuster ce nombre en ajoutant un tiret suivi d’un entier. Par exemple, "highlight": "description-10" retourne jusqu’à 10 termes mis en évidence de contenu correspondant dans le champ « description ».
Résultats mis en évidence
Lorsque la mise en surbrillance est ajoutée à la requête, la réponse comprend la mention « @search.highlights » pour chaque résultat afin que votre code d’application puisse cibler cette structure. La liste des champs spécifiés pour la « mise en évidence » est incluse dans la réponse.
Dans une recherche par mot clé, chaque terme est analysé séparément. Une requête portant sur « divine secrets » retourne les correspondances sur tout document contenant l’un ou l’autre terme.
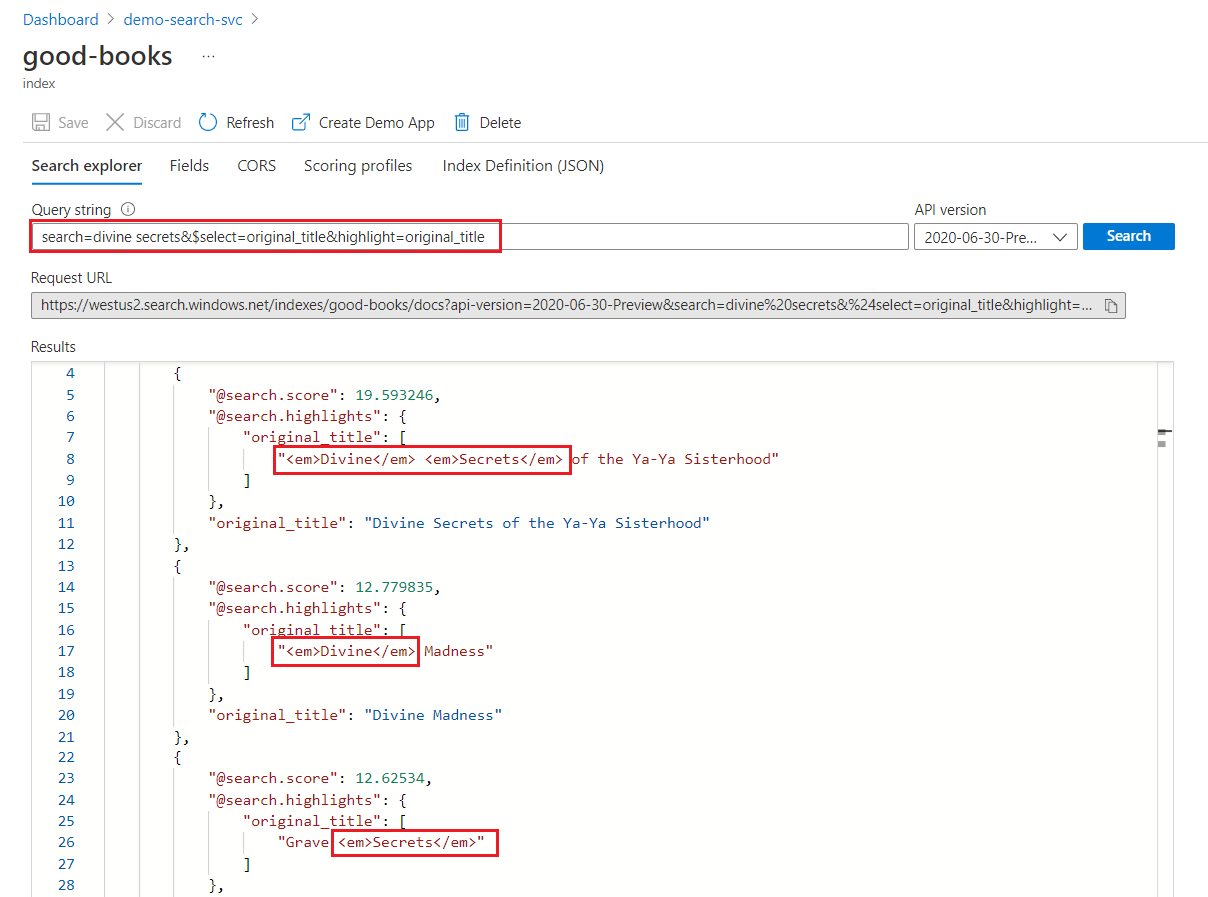
Mise en évidence de recherche de mot clé
Dans un champ mis en évidence, la mise en forme est appliquée aux termes entiers. Par exemple, sur une correspondance par rapport à « The Divine Secrets of the Ya-Ya Sisterhood », la mise en forme est appliquée séparément à tous les termes, même s’ils sont consécutifs.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Mise en évidence de recherche d’expression
La mise en forme des termes entiers s’applique même à une recherche d’expression, où plusieurs termes sont placés entre guillemets. L’exemple suivant est la même requête, sauf que « divine search » est soumis en tant qu’expression entre guillemets (certains clients REST exigent la mise en échappement des guillemets intérieurs avec une barre oblique inverse \") :
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Comme le critère a maintenant les deux termes, une seule correspondance est trouvée dans l’index de recherche. La réponse à la requête ci-dessus ressemble à ceci :
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Mise en évidence d’expression sur des services plus anciens
Les services de recherche qui ont été créés avant le 15 juillet 2020 implémentent une expérience de mise en évidence différente pour les requêtes d’expressions.
Pour les exemples suivants, imaginez une chaîne de requête incluant l’expression « super bowl » entre guillemets. Avant juillet 2020, tous les termes d’expression étaient mis en surbrillance :
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Pour les services de recherche après juillet 2020, seules les expressions qui correspondent à la requête d’expression complète sont renvoyées dans « @search.highlights » :
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Étapes suivantes
Pour générer rapidement une page de recherche pour votre client, envisagez les options suivantes :
Créer une application de démo, dans le portail, crée une page HTML avec une barre de recherche, une navigation par facettes et une zone de résultats qui contient des images.
Le tutoriel Ajouter la recherche sur une application ASP.NET Core (MVC) contient un exemple de code permettant de générer un client fonctionnel.
Ajouter une recherche aux applications web est un tutoriel et un exemple de code qui utilise les bibliothèques React JavaScript pour l’expérience utilisateur. L’application est déployée à l’aide d’Azure Static Web Apps.