Validation des entrées dans les requêtes Azure Stream Analytics
La validation des entrées est une technique à utiliser pour protéger la logique de requête principale contre des événements malformés ou inattendus. La requête est mise à niveau pour traiter et vérifier explicitement les enregistrements afin qu’ils ne puissent pas arrêter la logique principale.
Pour implémenter la validation d’entrée, nous ajoutons deux étapes initiales à une requête. Nous vérifions d’abord que le schéma envoyé à la logique métier principale correspond à ses attentes. Nous trions ensuite les exceptions et routons éventuellement les enregistrements non valides vers une sortie secondaire.
Une requête avec validation d’entrée est structurée de la façon suivante :
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Pour voir un exemple de requête complet configuré avec la validation d’entrée, consultez la section : Exemple de requête avec la validation d’entrée.
Cet article montre comment implémenter cette technique.
Contexte
Les travaux Azure Stream Analytics (ASA) traitent les données provenant de flux. Les flux sont des séquences de données brutes qui sont transmises sérialisées (CSV, JSON, AVRO...). Pour lire à partir d’un flux, une application doit connaître le format de sérialisation spécifique utilisé. Dans ASA, le format de sérialisation des événements doit être défini lors de la configuration d’une entrée de streaming.
Une fois les données désérialisées, il faut appliquer un schéma pour leur donner une signification. Par schéma, nous entendons la liste des champs dans le flux, et leurs types de données respectifs. Avec ASA, le schéma des données entrantes n’a pas besoin d’être défini au niveau de l’entrée. En revanche, ASA prend en charge les schémas d’entrée dynamique de manière native. Il s’attend à ce que la liste des champs (colonnes), et leurs types, changent entre les événements (lignes). L’ASA infère également les types de données quand aucun n’est fourni explicitement, et essaie de convertir implicitement les types si nécessaire.
La gestion dynamique des schémas est une fonctionnalité puissante, essentielle pour le traitement de flux. Les flux de données contiennent souvent des données provenant de plusieurs sources, incluant plusieurs types d’événements ayant chacun un schéma unique. Pour router, filtrer et traiter les événements sur ces flux, ASA doit les ingérer tous, quel que soit leur schéma.
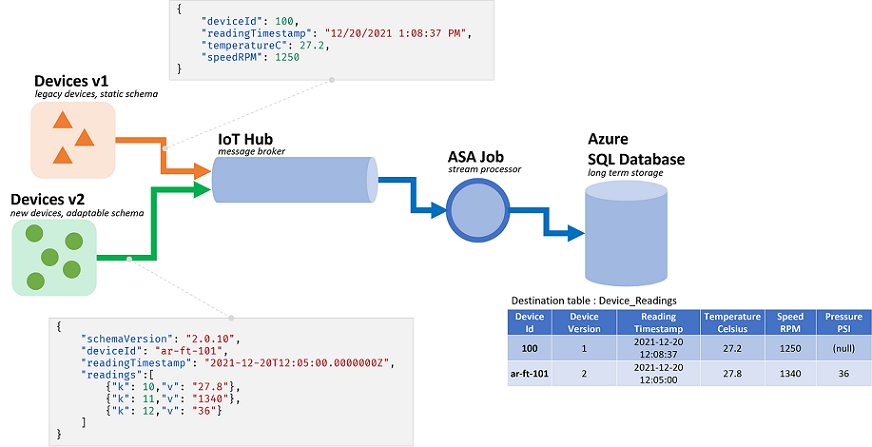
Toutefois, les possibilités qu’offre la gestion dynamique des schémas vont de pair avec un inconvénient potentiel. Des événements inattendus peuvent traverser la logique de requête principale et la dégrader. À titre d’exemple, nous pouvons utiliser ROUND sur un champ de type NVARCHAR(MAX). ASA le convertit implicitement en valeur flottante pour correspondre à la signature de ROUND. Nous attendons ou espérons ici que ce champ contienne toujours des valeurs numériques. Cependant, lorsque nous recevons un événement dont le champ est défini sur "NaN", ou dont le champ est totalement absent, le travail peut échouer.
Avec une validation des entrées, nous ajoutons des étapes préliminaires à notre requête pour traiter de tels événements malformés. Nous utiliserons principalement WITH et TRY_CAST pour l’implémenter.
Scénario : validation d’entrée pour les producteurs d’événements non fiables
Nous allons créer un nouveau travail ASA qui ingérera les données provenant d’un Event Hub unique. Comme c’est le plus souvent le cas, nous ne sommes pas responsables des producteurs de données. Ici, les producteurs sont des appareils IoT vendus par plusieurs fournisseurs de matériel.
En rencontrant les parties prenantes, nous nous convenons d’un format de sérialisation et d’un schéma. Tous les appareils enverront (push) de tels messages à un Event Hub commun, entrée du travail d’ASA.
Le contrat de schéma se définit comme suit :
| Nom du champ | Type de champ | Description du champ |
|---|---|---|
deviceId |
Integer | Identificateur d’appareil unique |
readingTimestamp |
Datetime | Heure du message, générée par une passerelle centrale |
readingStr |
String | |
readingNum |
Numérique | |
readingArray |
Tableau de chaînes |
Ce qui nous donne l’exemple de message suivant sous une sérialisation JSON :
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Nous pouvons déjà constater une discordance entre le contrat de schéma et son implémentation. Dans le format JSON, il n’y a pas de type de données pour DateHeure. La valeur sera transmise sous la forme d’une chaîne de caractères (voir readingTimestamp ci-dessus). ASA peut facilement résoudre le problème, mais révèle la nécessité de valider et convertir explicitement les types. D’autant plus pour les données sérialisées en CSV, car toutes les valeurs sont alors transmises sous forme de chaîne.
Il existe une autre discordance. L’ASA utilise son propre système de type qui ne correspond pas au système entrant. Si ASA dispose de types intégrés pour les entiers (bigint), les dates, les chaînes de caractères (nvarchar(max)) et les tableaux, il ne prend en charge que les valeurs numériques flottantes. Cette discordance n’est pas un problème pour la plupart des applications. Mais dans certains cas limites, cela pourrait entraîner de légères dérives de précision. Dans ce cas, nous convertissons la valeur numérique en chaîne de caractères dans un nouveau champ. Ensuite, en aval, nous utilisons un système prenant en charge la décimale fixe pour détecter et corriger des dérives potentielles.
Pour en revenir à notre question, nous avons l’intention d’effectuer les opérations suivantes :
- Passer
readingStrà une fonction définie par l’utilisateur (UDF) JavaScript - Compter le nombre d’enregistrements dans le tableau
- Arrondir
readingNumà la deuxième décimale - Insérer les données dans une table SQL
Le schéma de la table SQL de destination est le suivant :
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
Une bonne pratique consiste à mapper ce qui arrive à chaque champ à mesure de la progression dans le travail :
| Champ | Entrée (JSON) | Type hérité (ASA) | Sortie (Azure SQL) | Commentaire |
|---|---|---|---|---|
deviceId |
nombre | bigint | entier | |
readingTimestamp |
string | nvarchar(MAX) | datetime2 | |
readingStr |
string | nvarchar(MAX) | nvarchar(200) | utilisé par l’UDF |
readingNum |
nombre | float | décimal (18,2) | à arrondir |
readingArray |
tableau(chaîne) | tableau de nvarchar(MAX) | entier | à compter |
Prérequis
Nous allons développer la requête dans Visual Studio Code en utilisant l’extension Outils ASA. Les premières étapes de ce didacticiel vous guideront dans l’installation des composants requis.
Dans VS Code, nous allons utiliser des exécutions locales avec des entrées/sorties locales pour ne pas exposer de coût, et accélérer la boucle de débogage. Nous n’aurons pas besoin de configurer un Event Hub ou une Azure SQL Database.
Requête de base
Commençons par une implémentation de base, sans validation des entrées. Vous en aurez besoin dans la section suivante.
Dans VS Code, nous allons créer un projet ASA
Dans le dossier input, nous allons créer un fichier JSON nommé data_readings.json et y ajouter les enregistrements suivants :
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Ensuite, nous allons définir une entrée locale nommée readings, faisant référence au fichier JSON que nous avons créé ci-dessus.
Une fois configuré, celui-ci devrait ressembler à ceci :
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Avec Aperçu des données, nous pouvons observer que nos enregistrements sont chargés correctement.
Nous allons créer une UDF JavaScript nommée udfLen en faisant un clic droit sur le dossier Functions et en sélectionnant ASA: Add Function. Le code que nous allons utiliser est le suivant :
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
Dans les exécutions locales, nous n’avons pas besoin de définir de sorties. Nous n’avons même pas besoin d’utiliser INTO, s’il y a plus d’une sortie. Dans le fichier .asaql, nous pouvons remplacer la requête existante par :
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Examinons rapidement la requête que nous avons soumise :
- Pour compter le nombre d’enregistrements dans chaque tableau, nous devons d’abord les décompresser. Nous allons utiliser CROSS APPLY et GetArrayElements() (autres exemples ici)
- Ce faisant, nous obtenons deux ensembles de données dans la requête : l’entrée d’origine et les valeurs de tableau. Pour être sûr de ne pas mélanger les champs, nous définissons des alias (
AS r) et les utilisons partout. - Ensuite, pour compter (
COUNT) réellement les valeurs du tableau, nous devons opérer une agrégation avec GROUP BY. - Pour cela, nous devons définir une fenêtre de temps. Ici, puisque nous n’en avons pas besoin pour notre logique, la fenêtre d’instantané est le bon choix.
- Ce faisant, nous obtenons deux ensembles de données dans la requête : l’entrée d’origine et les valeurs de tableau. Pour être sûr de ne pas mélanger les champs, nous définissons des alias (
- Nous devons également regrouper (
GROUP BY) tous les champs, et les projeter dansSELECT. La projection explicite des champs est une bonne pratique, carSELECT *permet que les erreurs circulent de l’entrée à la sortie.- Si nous définissons une fenêtre de temps, nous pouvons définir un horodatage avec TIMESTAMP BY. Ici, ce n’est pas nécessaire pour que notre logique fonctionne. Pour les exécutions locales, sans
TIMESTAMP BY, tous les enregistrements sont chargés sur un seul horodatage, l’heure de début de l’exécution.
- Si nous définissons une fenêtre de temps, nous pouvons définir un horodatage avec TIMESTAMP BY. Ici, ce n’est pas nécessaire pour que notre logique fonctionne. Pour les exécutions locales, sans
- Nous utilisons l’UDF pour filtrer les lectures où
readingStrcompte moins de deux caractères. Nous aurions dû utiliser LEN ici. Nous utilisons une UDF uniquement à des fins de démonstration.
Nous pouvons démarrer une exécution et observer les données en cours de traitement :
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Chaîne | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Autre chaîne | 2,38 | 1 |
| 3 | 2021-12-10T10:01:20 | Troisième chaîne | -4,85 | 3 |
| 1 | 2021-12-10T10:02:10 | Quatrième chaîne | 1.21 | 2 |
Maintenant que nous savons que notre requête fonctionne, nous allons la tester avec plus de données. Remplaçons le contenu de data_readings.json par les enregistrements suivants :
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Nous pouvons voir ici les problèmes suivants :
- L’appareil #1 a fait tout ce qu’il fallait.
- L’appareil #2 a oublié d’inclure un
readingStr - L’appareil #3 a envoyé
NaNen tant que nombre - L’appareil #4 a envoyé un enregistrement vide au lieu d’un tableau.
L’exécution du travail maintenant ne devrait pas bien se terminer. Nous allons obtenir l’un des messages d’erreur suivants :
L’appareil 2 nous donnera :
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
L’appareil 3 nous donnera :
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
L’appareil 4 nous donnera :
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
À chaque fois, des enregistrements malformés ont pu circuler de l’entrée à la logique de requête principale sans être validés. Nous réalisons maintenant la valeur de la validation des entrées.
Implémentation de la validation des entrées
Étendons notre requête pour valider l’entrée.
La première étape de la validation des entrées consiste à définir les attentes du schéma de la logique métier de base. Si l’on se réfère au besoin d’origine, notre logique principale consiste à effectuer les opérations suivantes :
- Transmettre
readingStrà une UDF JavaScript pour mesurer sa longueur - Compter le nombre d’enregistrements dans le tableau
- Arrondir
readingNumà la deuxième décimale - Insérer les données dans une table SQL
Pour chaque point, nous pouvons énumérer les attentes :
- L’UDF requiert un argument de type chaîne de caractères (nvarchar(max) ici) qui ne peut pas avoir la valeur null.
GetArrayElements()requiert un argument de type tableau ou une valeur nullRoundrequiert un argument de type bigint ou float, ou une valeur null- Au lieu de nous appuyer sur la conversion implicite d’ASA, nous devrions la faire nous-mêmes et gérer les conflits de type dans la requête.
Une façon de procéder consiste à adapter la logique principale pour traiter ces exceptions. Mais dans ce cas, nous pensons que notre logique principale est parfaite. Alors validons plutôt les données entrantes.
Commençons par utiliser WITH pour ajouter une couche de validation des entrées comme première étape de la requête. Nous allons utiliser TRY_CAST pour convertir les champs dans le type attendu, et les définir sur NULL en cas d’échec de la conversion :
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Avec le dernier fichier d’entrée que nous avons utilisé (celui contenant des erreurs), cette requête retournera ce qui suit :
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Chaîne | 1.7145 | ["A", "B"] | 1 | 2021-12-10T10:00:00Z | Chaîne | 1.7145 | ["A", "B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Troisième chaîne | NaN | ["D","E","F"] | 3 | 2021-12-10T10:01:20Z | Troisième chaîne | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | Quatrième chaîne | 1.2126 | {} | 4 | 2021-12-10T10:02:10Z | Quatrième chaîne | 1.2126 | NULL |
Nous pouvons déjà constater que deux de nos erreurs ont été corrigées. Nous avons transformé NaN et {} en NULL. Nous sommes maintenant sûrs que ces enregistrements seront insérés correctement dans la table SQL de destination.
Nous devons maintenant décider comment traiter les enregistrements avec des valeurs manquantes ou non valides. Après discussion, nous avons décidé de rejeter les enregistrements contenant une valeur readingArray vide ou non valide, ou dans lesquels la valeur readingStr est manquante.
Nous ajoutons donc une deuxième couche qui va trier les enregistrements entre logique de validation et logique principale :
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Une bonne pratique consiste à écrire une seule clause WHERE pour les deux sorties, et à utiliser NOT (...) dans la seconde. De cette façon, aucun enregistrement ne peut être exclu des deux sorties et perdu.
Nous obtenons maintenant deux sorties. Debug1 contient les enregistrements qui seront envoyés à la logique principale :
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | Chaîne | 1.7145 | ["A", "B"] |
| 3 | 2021-12-10T10:01:20Z | Troisième chaîne | NULL | ["D","E","F"] |
Debug2 contient les enregistrements qui seront rejetés :
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | Quatrième chaîne | 1.2126 | {} | 4 | 2021-12-10T10:02:10Z | Quatrième chaîne | 1.2126 | NULL |
L’étape finale consiste à rajouter notre logique principale. Nous allons également ajouter la sortie qui rassemble les rejets. Dans ce cas, l’idéal consiste à utiliser un adaptateur de sortie qui n’impose pas de typage fort, comme un compte de stockage.
La requête complète figure dans la dernière section.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
Ce qui nous donnera l’ensemble suivant pour la sortie SQLOutput, sans erreur possible :
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | Chaîne | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20Z | Troisième chaîne | NULL | 3 |
Les deux autres enregistrements sont envoyés à une sortie BlobOutput pour un examen humain et un post-traitement. Notre requête est maintenant sûre.
Exemple de requête avec validation des entrées
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Extension de la validation des entrées
Le commande GetType peut être utilisée pour vérifier explicitement un type. Elle fonctionne bien avec CASE dans la projection ou WHERE au niveau de l’ensemble. La commande GetType peut également être utilisée pour vérifier de façon dynamique le schéma entrant par rapport à un référentiel de métadonnées. Le référentiel peut être chargé via un ensemble de données de référence.
L’opération unit-testing est une bonne pratique pour assurer la résilience de notre requête. Nous allons créer une série de tests consistant en des fichiers d’entrée et leur sortie attendue. Notre requête devra correspondre à la sortie qu’elle génère pour aboutir. Dans ASA, l’opération unit-testing est effectuée via le module npm asa-streamanalytics-cicd. Des cas de test avec divers événements malformés devraient être créés et testés dans le pipeline de déploiement.
Enfin, nous pouvons effectuer quelques tests d’intégration légers dans VS Code. Nous pouvons insérer des enregistrements dans la table SQL via une exécution locale vers une sortie dynamique.
Obtenir de l’aide
Pour obtenir de l’aide supplémentaire, essayez notre page de questions Microsoft Q&A pour Azure Stream Analytics.
Étapes suivantes
- Configurer des pipelines CI/CD à l’aide du package npm
- vue d’ensemble des exécutions de Stream Analytics locales dans Visual Studio Code avec les Outils ASA
- Tester des requêtes Stream Analytics localement avec des exemples de données à l’aide de Visual Studio Code
- Tester des requêtes Stream Analytics localement par rapport à une entrée de stream en direct à l'aide de Visual Studio Code
- Explorer des travaux Azure Stream Analytics avec Visual Studio Code (préversion)