Matérialiser les données dans Azure Cosmos DB à l’aide de l’éditeur sans code de Stream Analytics
Cet article explique comment utiliser l’éditeur sans code pour créer facilement un travail Stream Analytics. Le travail lit en continu le contenu de votre instance d’Event Hubs et effectue des agrégations telles que la somme et la moyenne. Vous sélectionnez des champs à regrouper sur une fenêtre de temps, puis le travail écrit les résultats en continu dans Azure Cosmos DB.
Prérequis
- Vos ressources Azure Event Hubs et Azure Cosmos DB doivent être accessibles publiquement, et elles ne peuvent pas résider derrière un pare-feu ou être sécurisées dans un réseau virtuel Azure.
- Les données de votre instance d’Event Hubs doivent être sérialisées au format JSON, CSV ou Avro.
Développer un travail Stream Analytics
Suivez les étapes ci-dessous pour développer un travail Stream Analytics permettant de matérialiser des données dans Azure Cosmos DB.
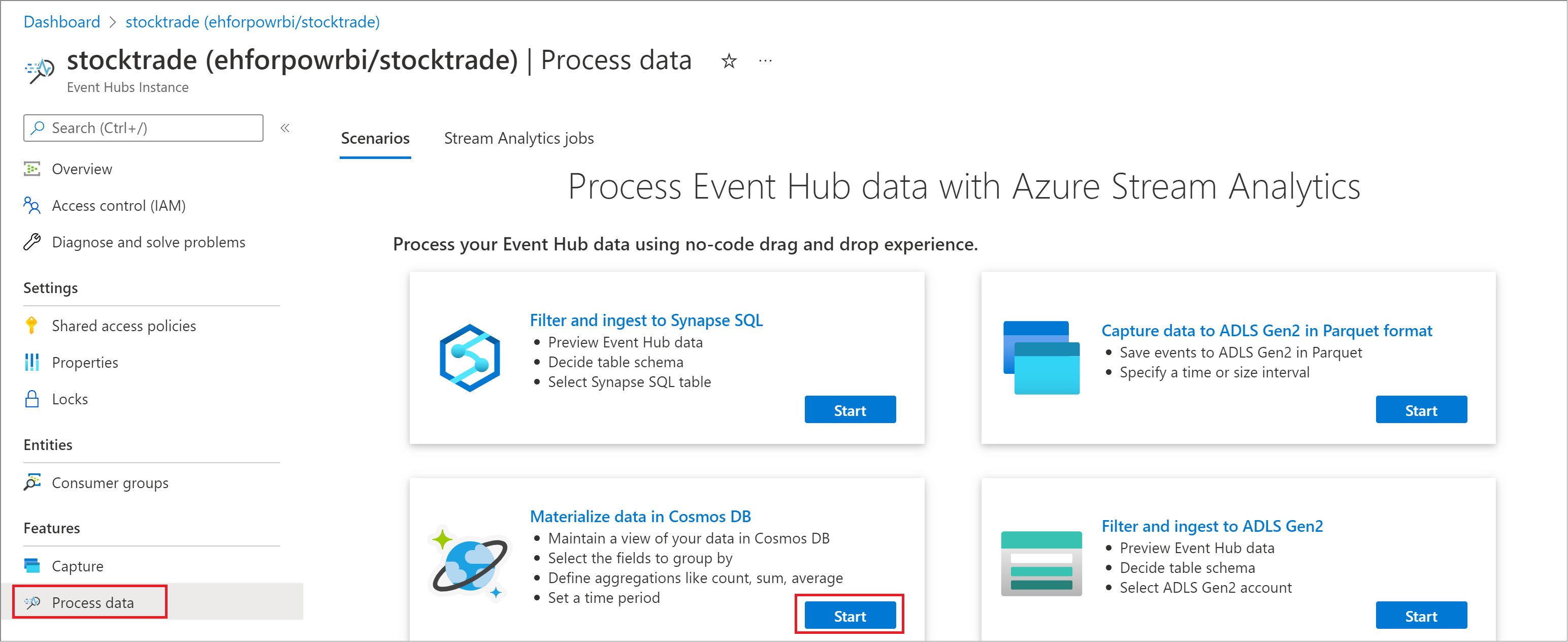
- Sur le portail Azure, recherchez et sélectionnez votre instance d’Azure Event Hubs.
- Sous Fonctionnalités, sélectionnez Traiter les données. Puis sélectionnez Démarrer dans la carte intitulée Matérialiser des données dans Azure Cosmos DB.
- Attribuez un nom à votre travail et sélectionnez Créer.
- Spécifiez le type de Sérialisation de vos données dans l’instance d’Event Hubs et la méthode d’authentification à utiliser par le travail pour se connecter à Event Hubs. Sélectionnez Connecter.
- Si la connexion est établie avec succès et que des flux de données circulent dans votre instance d’Event Hubs, vous verrez immédiatement deux éléments :
- Champs présents dans votre charge utile d’entrée. Sélectionnez les trois points en regard d’un champ pour supprimer, renommer ou modifier le type de données de ce champ.
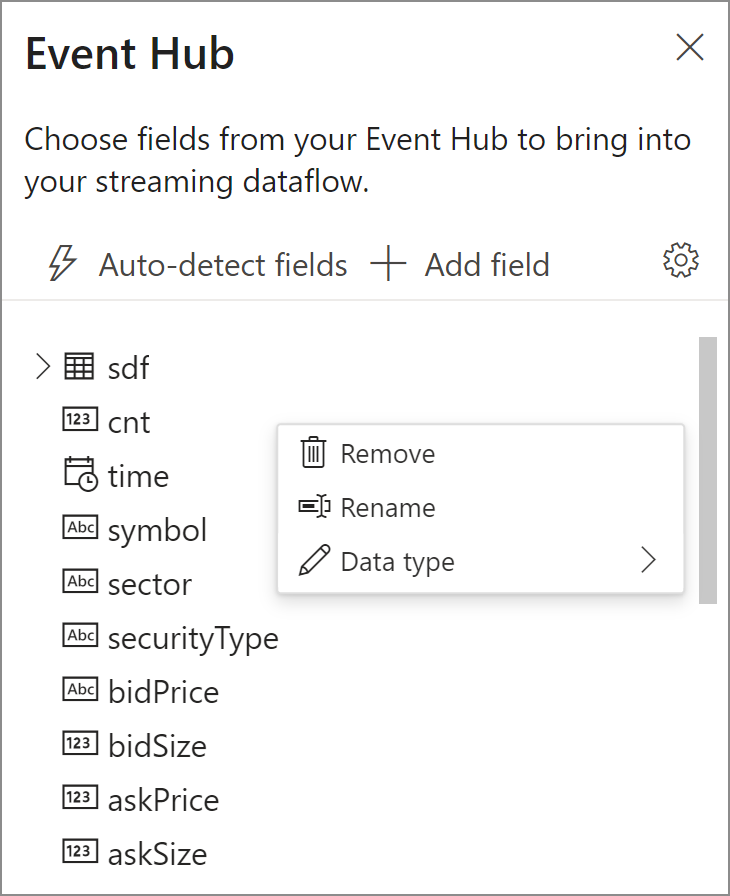
- Échantillon de vos données d’entrée dans le volet inférieur, sous Aperçu des données, qui s’actualise automatiquement et périodiquement. Vous pouvez sélectionner Suspendre l’aperçu de la diffusion en continu si vous préférez avoir une vue statique de votre échantillon de données d’entrée.

- Champs présents dans votre charge utile d’entrée. Sélectionnez les trois points en regard d’un champ pour supprimer, renommer ou modifier le type de données de ce champ.
- À l’étape suivante, vous spécifiez le champ et l’agrégat que vous souhaitez calculer, comme la moyenne et le nombre. Vous pouvez également spécifier le champ auquel vous souhaitez appliquer Regrouper par, ainsi que la fenêtre de temps. Vous pouvez ensuite valider les résultats de l’étape dans la section Aperçu des données.
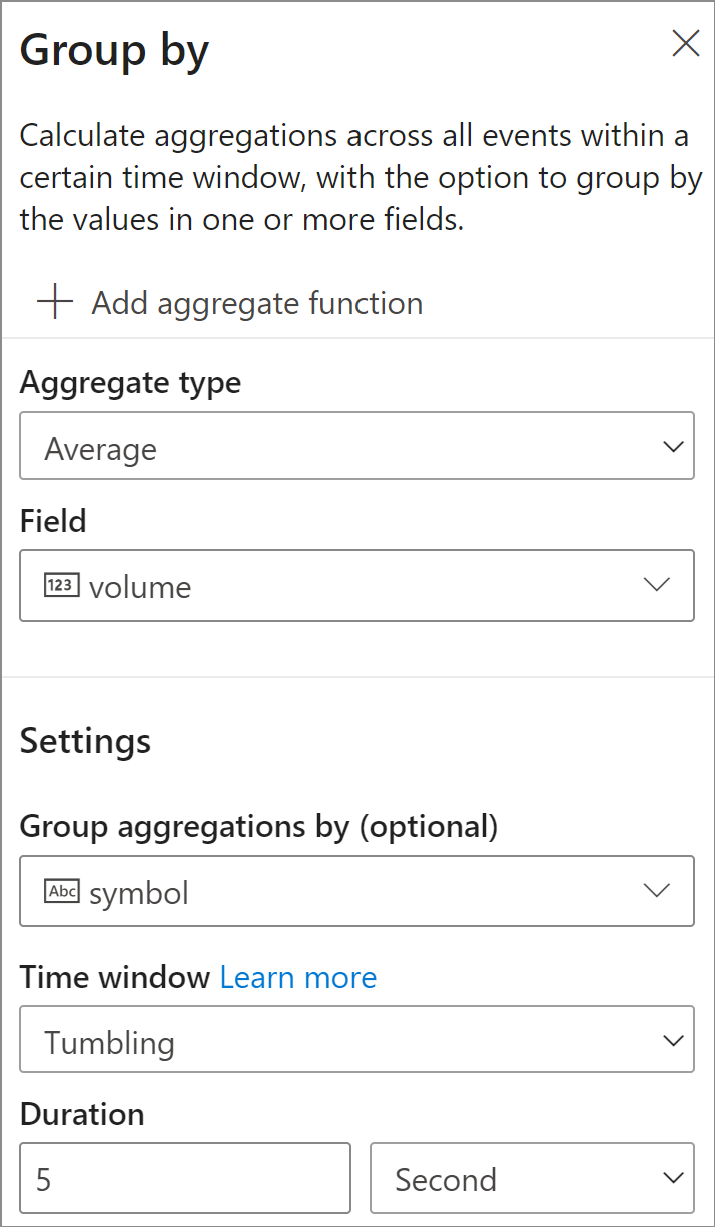
- Choisissez le conteneur et la base de données Cosmos DB où vous souhaitez que les résultats soient écrits.
- Lancez le travail Stream Analytics en sélectionnant Démarrer.
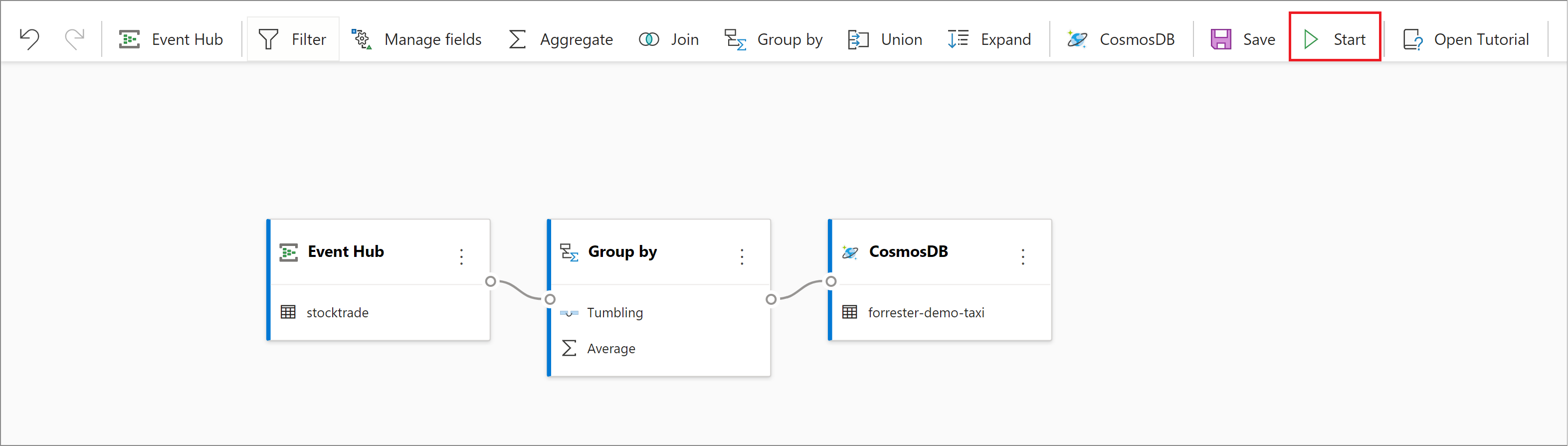
Pour démarrer le travail, vous devez spécifier :- Le nombre d’unités de streaming (SU) avec lesquelles le travail est exécuté. Les SU représentent les capacités de calcul et de mémoire allouées au travail. Nous vous recommandons de commencer par trois et d’ajuster cette valeur en fonction de vos besoins.
- L’option de gestion des erreurs de données de sortie vous permet de spécifier le comportement souhaité lorsque la sortie d’un travail vers votre destination échoue en raison d’erreurs de données. Par défaut, votre travail réessaie jusqu’à ce que l’opération d’écriture aboutisse. Vous pouvez également choisir de supprimer des événements de sortie.
- Une fois que vous avez sélectionné Démarrer, le travail commence à s’exécuter dans les deux minutes. Visualisez le travail dans la section Traiter les données de l’onglet Travaux Stream Analytics. Vous pouvez explorer les métriques du travail, et si nécessaire, arrêter et redémarrer celui-ci.





Considérations relatives à l’utilisation de la fonctionnalité de géo Event Hubs
Azure Event Hubs a récemment lancé la fonctionnalité géo en préversion publique. Cette fonctionnalité est différente de la fonctionnalité récupération d’urgence géo d’Azure Event Hubs.
Lorsque le type de basculement est Forcé et que la cohérence de la réplication est Asynchrone, le travail Stream Analytics ne garantit pas exactement une sortie vers une sortie Azure Event Hubs.
Azure Stream Analytics, comme producteur avec un hub d’événements en tant que sortie, peut observer un retard de filigrane sur le travail pendant la durée de basculement et pendant la limitation par Event Hubs au cas où le décalage de réplication entre le serveur principal et le serveur secondaire atteint la limite maximale configurée de décalage.
Azure Stream Analytics, comme consommateur avec Event Hubs en tant qu’entrée, peut observer un délai de filigrane sur le travail pendant la durée de basculement et peut ignorer les données ou rechercher des données dupliquées une fois le basculement terminé.
En raison de ces avertissements, nous vous recommandons de redémarrer le travail Stream Analytics avec l’heure de début appropriée juste après la fin du basculement d’Event Hubs. En outre, étant donné que la fonctionnalité géo d’Event Hubs est en préversion publique, nous vous déconseillons d’utiliser ce modèle pour les travaux Stream Analytics de production à ce stade. Le comportement actuel de Stream Analytics s’améliore avant que la fonctionnalité de géo d’Event Hubs soit généralement disponible et puisse être utilisée dans des travaux de production Stream Analytics.
Étapes suivantes
Vous savez maintenant utiliser l’éditeur sans code de Stream Analytics pour développer un travail qui lit à partir d’instances d’Event Hubs et calcule des agrégats tels que des nombres ou des moyennes et les écrit dans votre ressource Azure Cosmos DB.