Base de données de lac
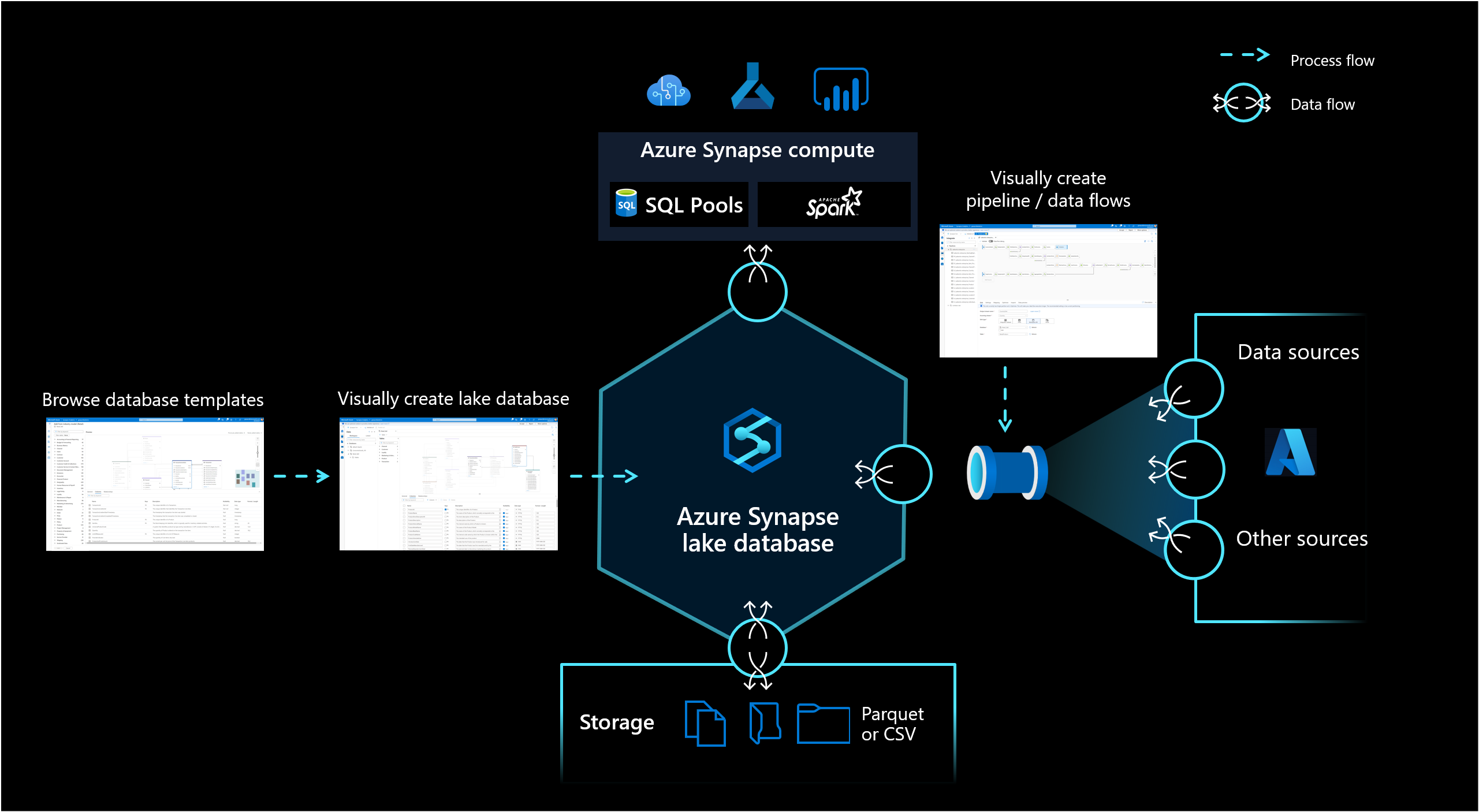
La base de données de lac dans Azure Synapse Analytics permet aux clients de réunir la conception de la base de données et les méta-informations sur les données qui y sont stockées, et offre la possibilité de décrire comment et où les données doivent être stockées. Une base de données de lac relève le défi des lacs de données d’aujourd’hui où il est difficile de comprendre la manière dont les données sont structurées.
Concepteur de bases de données
Le nouveau concepteur de base de données dans Synapse Studio vous donne la possibilité de créer un modèle de données pour votre base de données de lac et d’y ajouter des informations. Chaque entité et attribut peut être décrit pour fournir des informations supplémentaires sur le modèle qui ne contient pas seulement des entités mais aussi des relations. En particulier, l’absence de modélisation de relations est un défi pour l’interaction sur le lac de données. Ce défi est désormais relevé avec un concepteur intégré offrant des possibilités qui étaient disponibles dans les bases de données, mais pas sur le lac. En outre, la possibilité d’ajouter des descriptions et des valeurs de démonstration possibles au modèle permet aux utilisateurs qui interagissent avec celui-ci d’obtenir des informations là où ils en ont besoin pour mieux comprendre les données.
Stockage des données
Les bases de données de lac utilisent un lac de données sur le compte Stockage Azure pour stocker les données de la base de données. Les données peuvent être stockées au format Parquet, Delta ou CSV, et différents paramètres peuvent être utilisés pour optimiser le stockage. Chaque base de données de lac utilise un service lié pour définir l’emplacement du dossier de données racine. Pour chaque entité, des dossiers distincts sont créés par défaut à l’intérieur de ce dossier de base de données sur le lac de données. Par défaut, toutes les tables à l’intérieur d’une base de données de lac utilisent le même format, mais les formats et l’emplacement des données peuvent être modifiés par entité si cela est demandé.
Notes
La publication d’une base de données de lac ne crée aucune des structures ou schémas sous-jacents nécessaires pour interroger les données dans Spark ou SQL. Après la publication, chargez des données dans votre base de données de lac à l’aide de pipelines pour commencer à l’interroger.
Actuellement, la prise en charge du format Delta pour les bases de données de lac n’est pas prise en charge dans Synapse Studio.
La synchronisation des objets de base de données de lac entre le stockage et Synapse est unidirectionnelle. Veillez à créer ou modifier le schéma d’objets de base de données de lac à l’aide du concepteur de bases de données dans Synapse Studio. Si vous apportez de telles modifications à partir de Spark ou directement dans le stockage, les définitions de vos bases de données de lac seront désynchronisées. Si cela se produit, vous pourriez voir d’anciennes définitions de base de données de lac dans le concepteur de bases de données. Vous devez répliquer et publier ces modifications dans le concepteur de bases de données afin de rétablir la synchronisation de vos bases de données de lac.
Calcul de base de données
La base de données de lac est exposée dans un pool SQL serverless Synapse SQL et Apache Spark, offrant aux utilisateurs la possibilité de dissocier le stockage du calcul. Les métadonnées associées à la base de données de lac facilitent pour différent moteurs de calcul, non seulement la fourniture d’une expérience intégrée, mais aussi l’utilisation d’informations supplémentaires (par exemple, des relations) qui n’étaient pas prises en charge à l’origine sur le lac de données.
Étapes suivantes
Continuez à explorer les fonctionnalités du concepteur de base de données en suivant les liens ci-dessous.