Utiliser un metastore Hive externe pour le pool Synapse Spark
Remarque
Les metastores Hive externes ne seront plus pris en charge dans Azure Synapse Runtime pour Apache Spark 3.4 et les versions ultérieures dans Synapse.
Azure Synapse Analytics permet aux pools Apache Spark du même espace de travail de partager un metastore HMS (metastore Hive) managé comme catalogue. Quand les clients veulent persister les métadonnées du catalogue Hive en dehors de l’espace de travail et partager des objets de catalogue avec d’autres moteurs de calcul en dehors de l’espace de travail, comme HDInsight et Azure Databricks, ils peuvent se connecter à un metastore Hive externe. Dans cet article, vous découvrez comment connecter Synapse Spark à un metastore Apache Hive externe.
Versions de metastore Hive prises en charge
La fonctionnalité fonctionne avec Spark 3.1. Le tableau suivant indique les versions de metastore Hive prises en charge pour chaque version de Spark.
| Version de Spark | HMS 2.3.x | HMS 3.1.X |
|---|---|---|
| 3.3 | Oui | Oui |
Configurer un service lié sur le metastore Hive
Notes
Seuls Azure SQL Database et Azure Database pour MySQL sont pris en charge comme metastore Hive externe. Actuellement, nous prenons uniquement en charge l’authentification avec un utilisateur et un mot de passe. Si la base de données fournie est vide, provisionnez-la avec l’outil de schéma Hive pour créer un schéma de base de données.
Suivez les étapes ci-dessous pour configurer un service lié sur le metastore Hive externe dans l’espace de travail Synapse.
Ouvrez Synapse Studio, accédez à Gérer > Services liés à gauche, puis sélectionnez Nouveau pour créer un service lié.
Choisissez Azure SQL Database ou Azure Database pour MySQL en fonction de votre type de base de données, puis sélectionnez Continuer.
Entrez le nom du service lié. Enregistrez le nom du service lié. Ces informations seront utilisées pour configurer Spark dans un instant.
Vous pouvez sélectionner Azure SQL Database/Azure Database pour MySQL pour le metastore Hive externe dans la liste des abonnements Azure ou entrer les informations manuellement.
Entrez un nom d’utilisateur et un mot de passe pour configurer la connexion.
Testez la connexion pour vérifier le nom d’utilisateur et le mot de passe.
Sélectionnez Créer pour créer le service lié.
Tester la connexion et récupérer la version du metastore dans le notebook
Certains paramètres de règle de sécurité réseau peuvent bloquer l’accès du pool Spark à la base de données du metastore Hive externe. Avant de configurer le pool Spark, exécutez le code ci-dessous dans un notebook du pool Spark pour tester la connexion à la base de données du metastore Hive externe.
Vous pouvez également obtenir votre version de metastore Hive dans les résultats de sortie. La version du metastore Hive est utilisée dans la configuration Spark.
Avertissement
Ne publiez pas les scripts de test dans votre bloc-notes avec votre mot de passe codé en dur, car cela peut entraîner un risque de sécurité pour votre metastore Hive.
Code de test de connexion pour Azure SQL
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure SQL database > Connection strings > JDBC **/
val url = s"jdbc:sqlserver://{your_servername_here}.database.windows.net:1433;database={your_database_here};user={your_username_here};password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
try {
val connection = DriverManager.getConnection(url)
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
Code de test de connexion pour Azure Database pour MySQL
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure Database for MySQL > Connection strings > JDBC **/
val url = s"jdbc:mysql://{your_servername_here}.mysql.database.azure.com:3306/{your_database_here}?useSSL=true"
try {
val connection = DriverManager.getConnection(url, "{your_username_here}", "{your_password_here}");
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
Configurer Spark pour utiliser le metastore Hive externe
Après avoir créé le service lié au metastore Hive externe, vous devez définir des configurations Spark pour utiliser le metastore Hive externe. Vous pouvez définir la configuration au niveau du pool Spark ou au niveau de la session Spark.
Voici les configurations et les descriptions :
Notes
Synapse est conçu pour utiliser de manière fluide les calculs HDI. Toutefois, HMS 3.1 dans HDI 4.0 n’est pas entièrement compatible avec l’OSS HMS 3.1. Pour l’OSS HMS 3.1, vérifiez ici.
| Configuration Spark | Description |
|---|---|
spark.sql.hive.metastore.version |
Versions prises en charge :
|
spark.sql.hive.metastore.jars |
|
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name |
Nom de votre service lié |
spark.sql.hive.metastore.sharedPrefixes |
com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas |
Configurer au niveau du pool Spark
Lors de la création du pool Spark, sous l’onglet Paramètres supplémentaires, placez les configurations ci-dessous dans un fichier texte et chargez-les dans la section Configuration Apache Spark. Vous pouvez également utiliser le menu contextuel d’un pool Spark existant et choisir la configuration Apache Spark pour ajouter ces configurations.
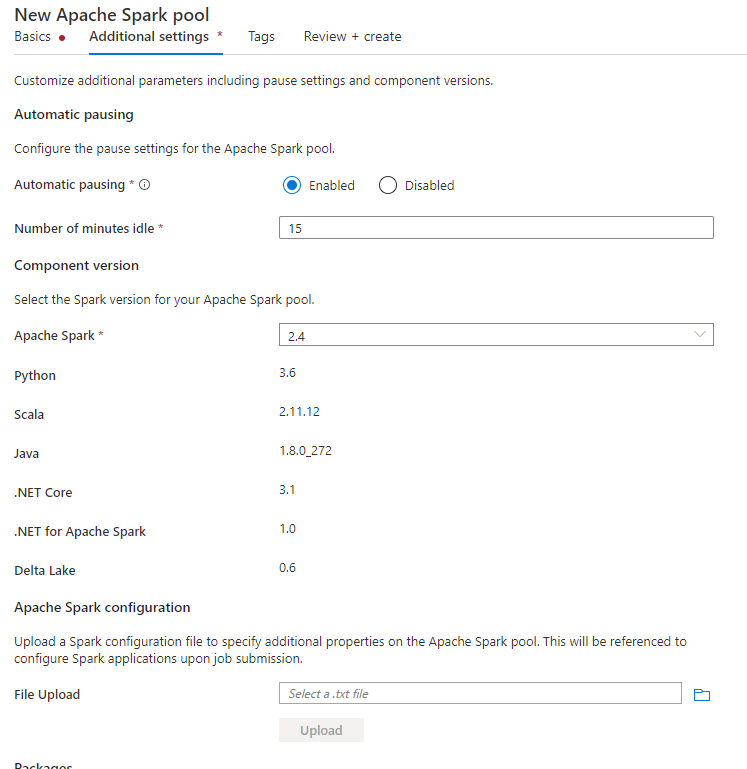
Mettez à jour la version du metastore et le nom du service lié, puis enregistrez les configurations ci-dessous dans un fichier texte pour la configuration du pool Spark :
spark.sql.hive.metastore.version <your hms version, Make sure you use the first 2 parts without the 3rd part>
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name <your linked service name>
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas
Voici un exemple de la version 2.3 du metastore avec un service lié nommé HiveCatalog21 :
spark.sql.hive.metastore.version 2.3
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name HiveCatalog21
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas
Configurer au niveau de la session Spark
Pour une session de notebook, vous pouvez également configurer la session Spark dans le notebook avec la commande magique %%configure. Voici le code.
%%configure -f
{
"conf":{
"spark.sql.hive.metastore.version":"<your hms version, 2 parts>",
"spark.hadoop.hive.synapse.externalmetastore.linkedservice.name":"<your linked service name>",
"spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*",
"spark.sql.hive.metastore.sharedPrefixes":"com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas"
}
}
Pour un programme de traitement par lots, la même configuration peut aussi être appliquée avec SparkConf.
Exécuter les requêtes pour vérifier la connexion
Après tous ces paramètres, essayez de répertorier les objets de catalogue en exécutant la requête ci-dessous dans le notebook Spark pour vérifier la connectivité au metastore Hive externe.
spark.sql("show databases").show()
Configurer une connexion de stockage
Le service lié à la base de données du metastore Hive fournit seulement l’accès aux métadonnées du catalogue Hive. Pour interroger les tables existantes, vous devez configurer la connexion au compte de stockage qui stocke également les données sous-jacentes de vos tables Hive.
Configurer la connexion à Azure Data Lake Storage Gen2
Compte de stockage principal de l’espace de travail
Si les données sous-jacentes de vos tables Hive sont stockées dans le compte de stockage principal de l’espace de travail, vous n’avez pas besoin de paramètres supplémentaires. Elle fonctionnera tant que vous avez suivi les instructions de configuration du stockage lors de la création de l’espace de travail.
Autre compte ADLS Gen 2
Si les données sous-jacentes de vos catalogues Hive sont stockées dans un autre compte ADLS Gen 2, vous devez vous assurer que les utilisateurs qui exécutent des requêtes Spark disposent du rôle Contributeur de données blob de Stockage sur le compte de stockage ADLS Gen2.
Configurer la connexion au Stockage Blob
Si les données sous-jacentes de vos tables Hive sont stockées dans le compte de stockage Blob Azure, configurez la connexion en suivant les étapes ci-dessous :
Ouvrez Synapse Studio, accédez à Données > onglet Lié > bouton Ajouter>Se connecter à des données externes.
Sélectionnez Stockage Blob Azure, puis Continuer.
Entrez le nom du service lié. Enregistrez le nom du service lié. Ces informations sont utilisées par la suite dans la configuration Spark.
Sélectionnez le compte de Stockage Blob Azure. Vérifiez que la méthode d’authentification est Clé de compte. Actuellement, le pool Spark peut uniquement accéder à un compte de stockage Blob via une clé de compte.
Testez la connexion et sélectionnez Créer.
Après avoir créé le service lié au compte de stockage Blob, lorsque vous exécutez des requêtes Spark, veillez à exécuter le code Spark ci-dessous dans le notebook pour accéder au compte de stockage Blob pour la session Spark. En savoir plus sur la raison pour laquelle vous devez le faire ici.
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
Après avoir configuré des connexions de stockage, vous pouvez interroger les tables existantes dans le metastore Hive.
Limitations connues
- L’Explorateur d’objets de Synapse Studio continue à afficher des objets dans le metastore Synapse managé au lieu du service HMS externe.
- SQL <-> Synchronisation Spark ne fonctionne pas en cas d’utilisation d’HMS externe.
- Seuls Azure SQL Database et Azure Database pour MySQL sont pris en charge comme base de données de metastore Hive externe. Seule l’autorisation SQL est prise en charge.
- Actuellement, Spark fonctionne uniquement avec des tables Hive externes et des tables Hive managées non transactionnelles/non-ACID. Il ne prend pas en charge les tables transactionnelles/ACID Hive.
- L’intégration d’Apache Ranger n’est pas prise en charge.
Dépannage
Consultez l’erreur ci-dessous lors de l’interrogation d’une table Hive avec des données stockées dans le Stockage Blob
No credentials found for account xxxxx.blob.core.windows.net in the configuration, and its container xxxxx is not accessible using anonymous credentials. Please check if the container exists first. If it is not publicly available, you have to provide account credentials.
Lorsque vous utilisez l’authentification par clé pour votre compte de stockage via le service lié, vous devez effectuer une étape supplémentaire pour obtenir le jeton pour la session Spark. Exécutez le code ci-dessous pour configurer votre session Spark avant d’exécuter la requête. En savoir plus sur la raison pour laquelle vous devez le faire ici.
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
Voir l’erreur ci-dessous lors de la requête d’une table stockée dans un compte ADLS Gen2
Operation failed: "This request is not authorized to perform this operation using this permission.", 403, HEAD
Cela peut se produire si l’utilisateur qui exécute la requête Spark n’a pas un accès suffisant au compte de stockage sous-jacent. Vérifiez que l’utilisateur qui exécute des requêtes Spark a le rôle Contributeur aux données blob de stockage sur le compte de stockage ADLS Gen2. Cette étape peut être effectuée après la création du service lié.
Paramètres liés au schéma HMS
Pour éviter de modifier le schéma/la version back-end HMS, les configurations Hive suivantes sont définies par le système par défaut :
spark.hadoop.hive.metastore.schema.verification true
spark.hadoop.hive.metastore.schema.verification.record.version false
spark.hadoop.datanucleus.fixedDatastore true
spark.hadoop.datanucleus.schema.autoCreateAll false
Si votre version HMS est 1.2.1 ou 1.2.2, il y a un problème dans Hive qui demande uniquement 1.2.0 si vous activez spark.hadoop.hive.metastore.schema.verification sur true . Notre suggestion est de définir votre version HMS sur 1.2.0 ou de choisir une des deux configurations suivantes comme solution de contournement :
spark.hadoop.hive.metastore.schema.verification false
spark.hadoop.hive.synapse.externalmetastore.schema.usedefault false
Si vous devez migrer votre version du service HMS, nous vous recommandons d’utiliser l’outil de schéma hive. Et si le service HMS a été utilisé par les clusters HDInsight, nous vous suggérons d’utiliser la version fournie par HDI.
Changement du schéma HMS pour l’OSS HMS 3.1
Synapse est conçu pour utiliser de manière fluide les calculs HDI. Toutefois, HMS 3.1 dans HDI 4.0 n’est pas entièrement compatible avec l’OSS HMS 3.1. Appliquez manuellement ce qui suit à votre HMS 3.1, s’il n’est pas approvisionné par HDI.
-- HIVE-19416
ALTER TABLE TBLS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
ALTER TABLE PARTITIONS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
Lors du partage du metastore avec un cluster HDInsight 4.0 Spark, je ne peux pas voir les tables
Si vous souhaitez partager le catalogue Hive avec un cluster Spark dans HDInsight 4.0, vérifiez que votre propriété spark.hadoop.metastore.catalog.default dans Synapse Spark est alignée sur la valeur de HDInsight Spark. La valeur par défaut pour HDI Spark est spark et la valeur par défaut pour Synapse Spark est hive.
Quand je partage le metastore Hive avec des clusters HDInsight 4.0 Hive, je peux lister les tables, mais j’obtiens seulement un résultat vide quand j’interroge la table
Comme mentionné dans les limitations, le pool Synapse Spark ne prend en charge que les tables Hive externes et les tables managées non transactionnelles/ACID. Il ne prend pas actuellement en charge les tables transactionnelles/ACID Hive. Dans les clusters HDInsight 4.0 Hive, toutes les tables managées sont créées comme des tables ACID/transactionnelles par défaut. C’est pourquoi vous recevez des résultats vides quand vous interrogez ces tables.
Erreur lorsqu’un metastore externe est utilisé alors que le cache intelligent est activé
java.lang.ClassNotFoundException: Class com.microsoft.vegas.vfs.SecureVegasFileSystem not found
Vous pouvez facilement résoudre ce problème en ajoutant /usr/hdp/current/hadoop-client/* à spark.sql.hive.metastore.jars.
Eg:
spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/*