Analyse des données avec Azure Machine Learning
Ce didacticiel utilise le concepteur Azure Machine Learning pour générer un modèle Machine Learning prédictif. Le modèle est basé sur les données stockées dans Azure Synapse. Le scénario de ce didacticiel crée une campagne marketing ciblée pour Adventure Works, le magasin de vélos, en prévoyant si un client est susceptible d’acheter ou non un vélo.
Prérequis
Pour exécuter pas à pas ce didacticiel, vous avez besoin des éléments suivants :
- un pool SQL préchargé avec les exemples de données AdventureWorksDW. Pour l’approvisionner, consultez Créer un pool SQL et chargez les données d’exemple. Si vous disposez déjà d’un entrepôt de données, mais sans disposer d’exemples de données, vous pouvez charger manuellement des exemples de données.
- Un espace de travail Azure Machine Learning. Suivez ce didacticiel pour en créer un nouveau.
Obtenir les données
Les données utilisées sont indiquées dans la vue dbo.vTargetMail dans AdventureWorksDW. Pour utiliser la Banque de données dans ce didacticiel, les données sont d’abord exportées pour le compte Azure Data Lake Storage, car Azure Synapse ne prend pas actuellement en charge les jeux de données. Azure Data Factory peut être utilisé pour exporter des données de l’entrepôt de données vers Azure Data Lake Storage à l’aide de l’activité de copie. Utilisez la requête suivante pour importer :
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Une fois les données disponibles dans Azure Data Lake Storage, les banques de données dans Azure Machine Learning sont utilisées pour se connecter aux services de stockage Azure. Suivez les étapes ci-dessous pour créer un magasin de données et un jeu de données correspondant :
Lancez Azure Machine Learning studio à partir du portail Azure ou connectez-vous à Azure Machine Learning studio.
Cliquez sur Magasins de données dans le volet gauche de la section Gérer, puis cliquez sur Nouveau magasin de données.
Indiquez un nom pour le magasin de données, sélectionnez le type « stockage Blob Azure », indiquez l’emplacement et les informations d’identification. Cliquez sur Créer.
Ensuite, cliquez sur Jeux de données dans le volet gauche de la section Actifs. Sélectionnez Créer un jeu de données avec l’option À partir du magasin de données.
Spécifiez le nom du jeu de données et sélectionnez le type Tabulaire. Ensuite, cliquez sur Suivant pour passer à l’étape suivante.
Dans la section Sélectionner ou créer un magasin de données, sélectionnez l’option Banque de données précédemment créée. Sélectionnez la base de données que vous avez créée auparavant. Cliquez sur Suivant et spécifiez les paramètres de chemin d’accès et de fichier. Veillez à spécifier l’en-tête de colonne si les fichiers en contiennent un.
Cliquez sur Créer pour créer le jeu de données.
Configurer l’expérience du concepteur
Ensuite, suivez les étapes ci-dessous pour configurer le concepteur :
Cliquez sur l’onglet Concepteur dans le volet gauche de la section Auteur.
Sélectionnez Modules prédéfinis faciles à utiliser pour créer un pipeline.
Dans le volet Paramètres à droite, spécifiez le nom du pipeline.
Sélectionnez également un cluster de calcul cible pour l’intégralité de l’expérience dans le bouton paramètres vers un cluster précédemment approvisionné. Fermez la fenêtre Paramètres.
Importer les données
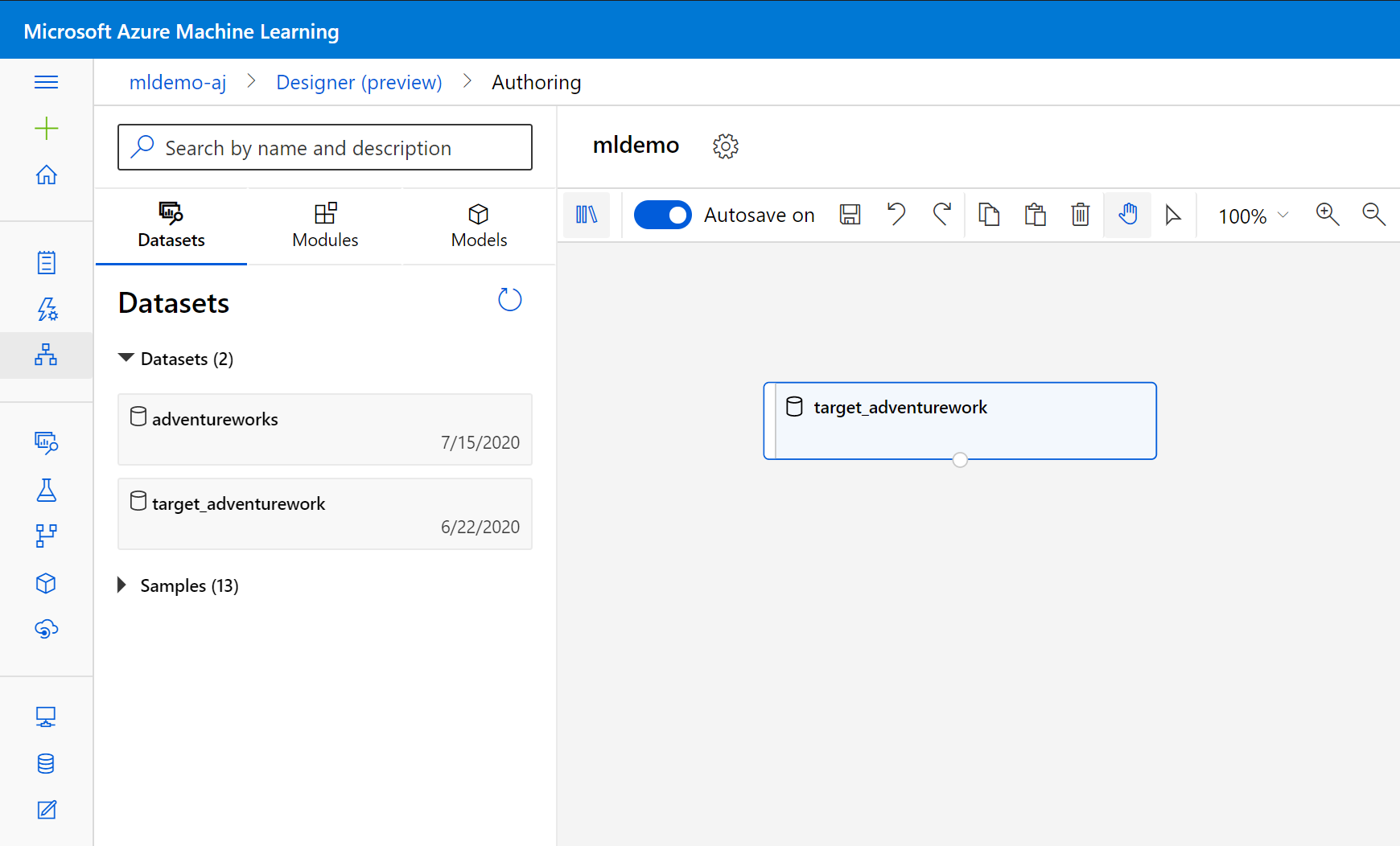
Sélectionnez le sous-onglet Jeux de données dans le volet gauche sous la zone de recherche.
Faites glisser le jeu données que vous avez créé précédemment dans le canevas.
Nettoyer les données
Pour nettoyer les données, supprimez certaines colonnes qui sont inutiles pour le modèle. Pour ce faire, procédez comme suit :
Sélectionnez le sous-onglet Modules dans le volet gauche.
Faites glisser le composant Sélectionner des colonnes dans le jeu de données sous Transformation des données < Manipulation dans le canevas. Connectez ce composant au composant Jeu de données.
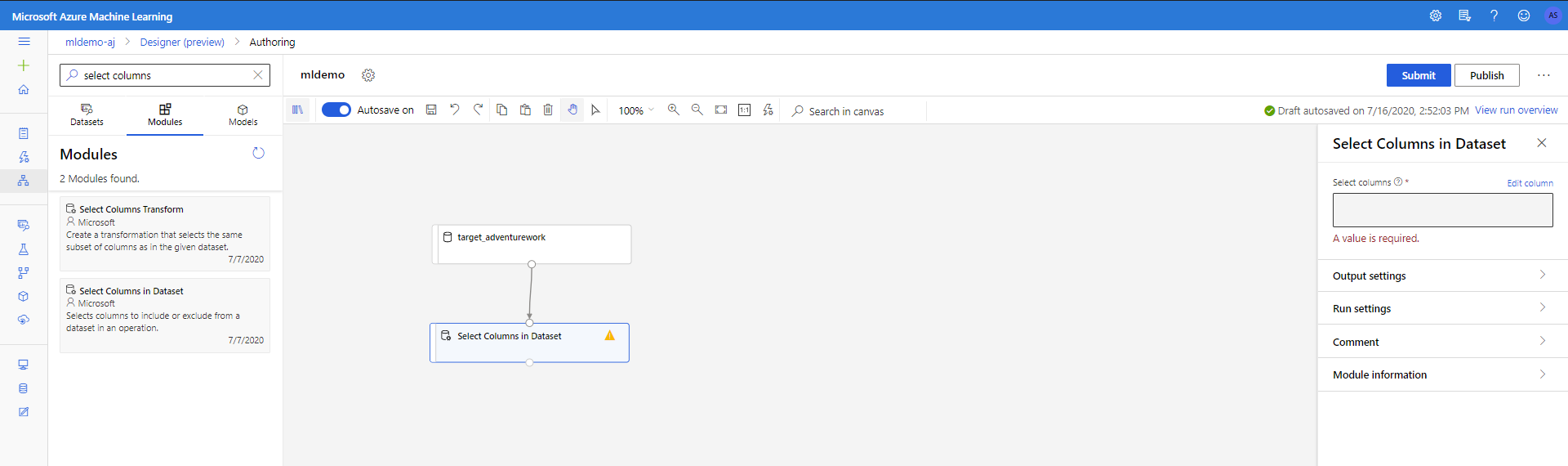
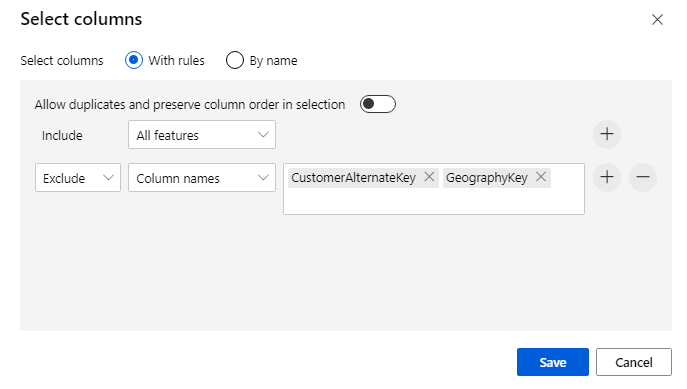
Cliquez sur le composant pour ouvrir le volet Propriétés. Cliquez sur Modifier la colonne pour spécifier les colonnes que vous souhaitez supprimer.
Excluez deux colonnes : CustomerAlternateKey et GeographyKey. Cliquez sur Enregistrer.

Générer le modèle
Les données sont fractionnées en 80-20 : 80 % pour l’apprentissage d’un modèle Machine Learning et 20 % pour tester le modèle. Des algorithmes « À deux classes » pour ce problème de classification binaire sont utilisés.
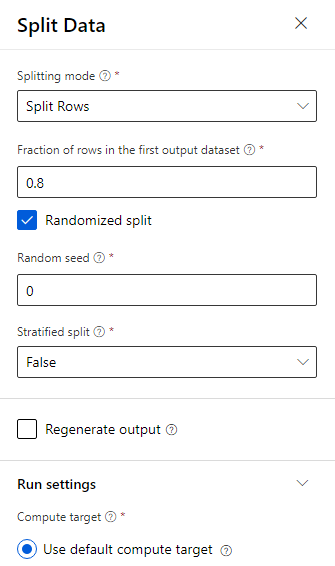
Faites glisser le composant Diviser les données dans le canevas.
Sur le volet Propriétés, entrez 0,8 comme Fraction de lignes dans le premier jeu de données.
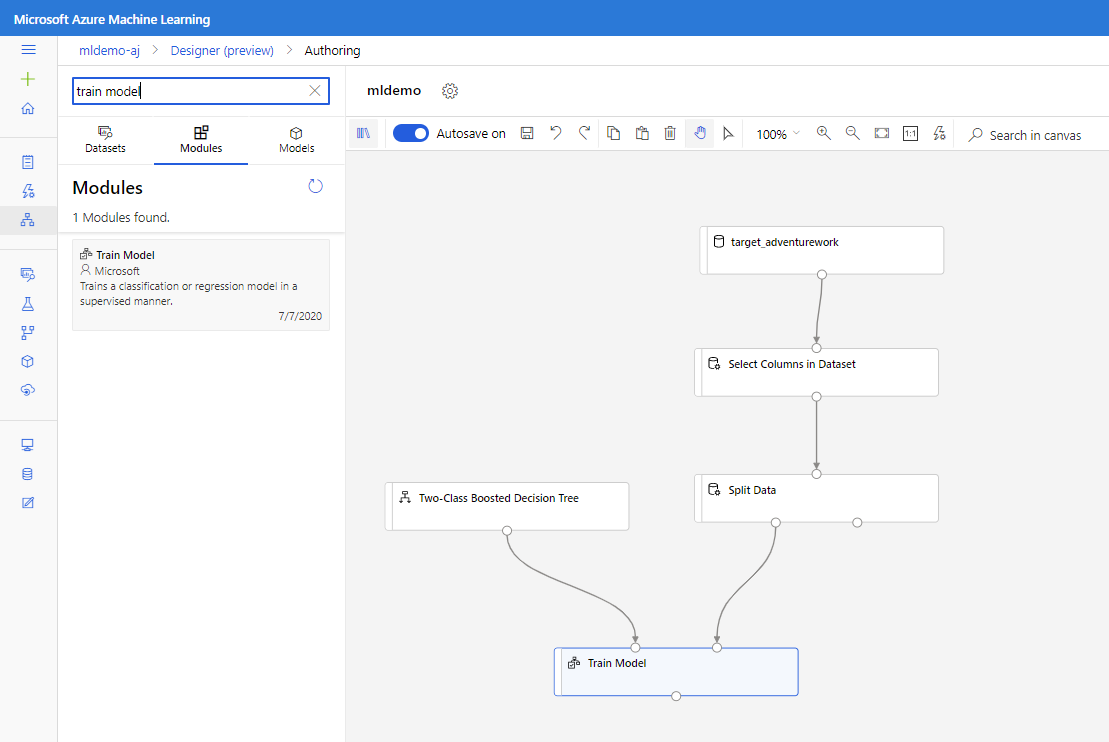
Faites glisser le composant Arbre de décision optimisé à deux classes dans le canevas.
Faites glisser le module Entraîner le modèle dans le canevas. Spécifiez des entrées en le connectant aux composants Arbre de décision optimisé à deux classes (l’algorithme ML) et Division des données (les données sur lesquelles entraîner l’algorithme).
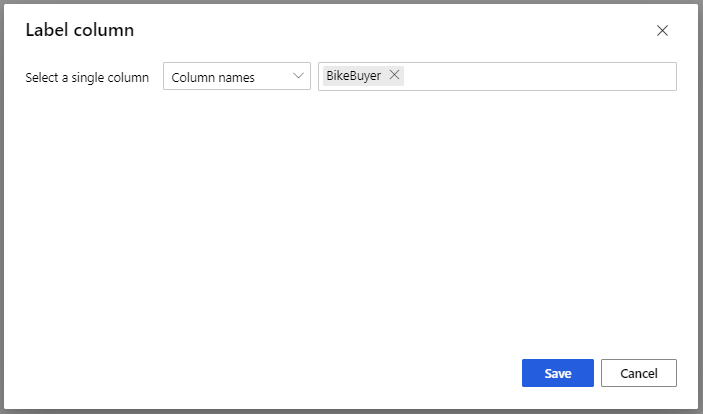
Pour le module Effectuer l'apprentissage du module, dans l’option de Colonne d’étiquette dans le volet Propriétés, sélectionnez Modifier la colonne. Sélectionnez la colonne BikeBuyer comme colonne à prédire et sélectionnez Enregistrer.
Noter le modèle
À présent, testez la manière dont le modèle s’exécute sur les données de test. Deux algorithmes différents seront comparés pour déterminer celui qui est le plus performant. Pour ce faire, procédez comme suit :
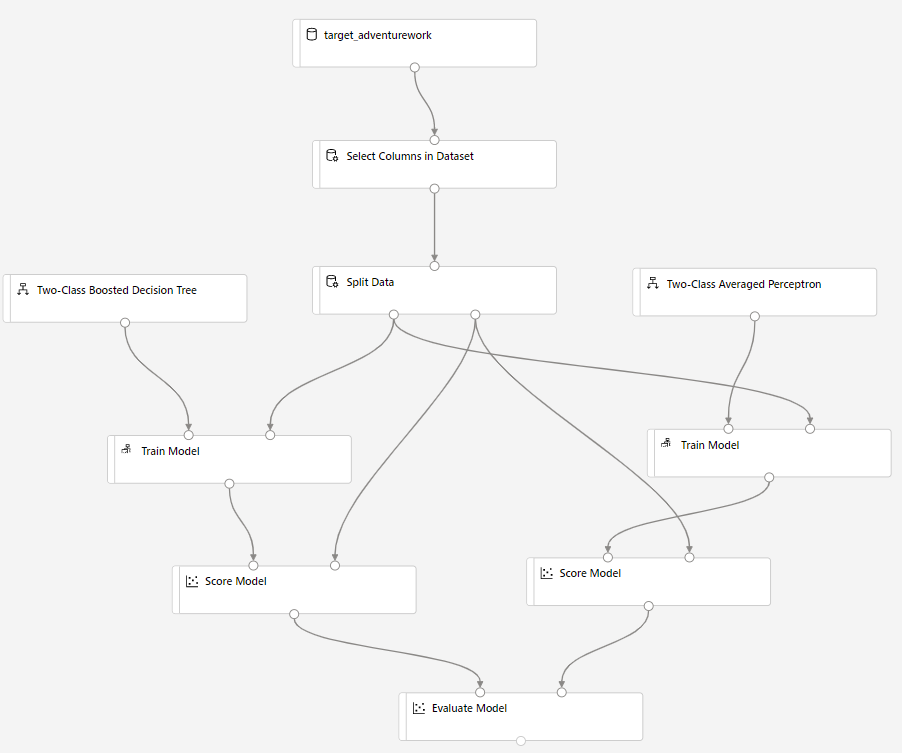
Faites glisser le composant Attribuer des scores au modèle dans le canevas et connectez-le aux composants Entraîner le modèle et Diviser les données.
Faites glisser Machines de points Bayes à deux classes dans la canevas de l’expérience. Vous allez comparer comment cet algorithme fonctionne par rapport à l’arbre de décision optimisé à deux classes.
Copiez et collez les composants Entraîner le modèle et Attribuer des scores au modèle dans le canevas.
Faites glisser le composant Évaluer le modèle dans le canevas pour comparer les deux algorithmes.
Cliquez sur Envoyer pour configurer l’exécution du pipeline.
Une fois l’exécution terminée, cliquez avec le bouton droit sur le composant Évaluer le modèle, puis cliquez sur Visualiser les résultats de l’évaluation.
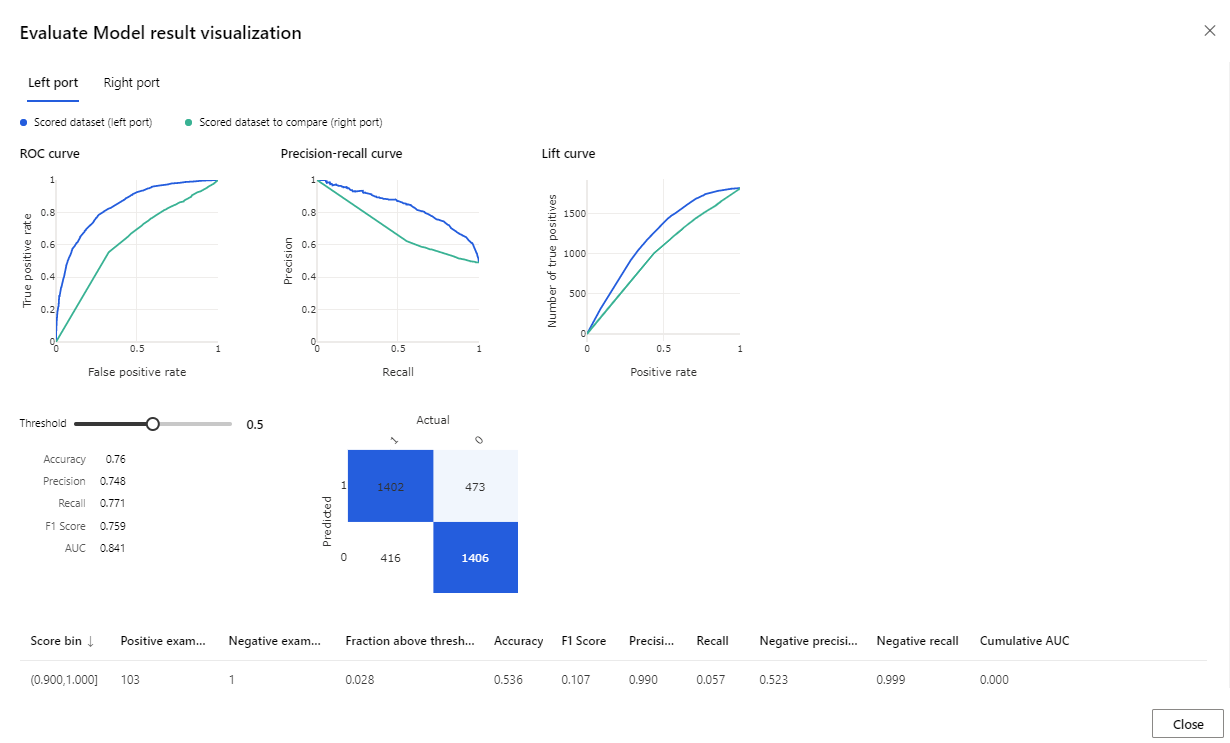

Les mesures fournies sont la courbe ROC, le diagramme de rappel de précision et la courbe d’élévation. En examinant ces mesures, nous pouvons voir que le premier modèle fonctionne mieux que le second. Pour examiner ce que le premier modèle a prédit, cliquez avec le bouton droit sur le composant Attribuer des scores au modèle, puis cliquez sur Visualiser le jeu de données avec scores pour voir les résultats prédits.
Vous verrez deux colonnes supplémentaires ajoutées à votre jeu de données de test.
- Probabilités évaluées : probabilité qu’un client soit un acheteur potentiel de vélo.
- Étiquette de marquage : classification effectuée par le modèle – acheteur de vélo (1) ou non (0). Ce seuil de probabilité pour l’étiquetage est défini à 50 % et peut être ajusté.
En comparant la colonne BikeBuyer (réelle) avec les étiquettes de marquage (prévision), vous pouvez voir comment le modèle a fonctionné. Ensuite, vous pouvez utiliser ce modèle pour faire des prédictions pour les nouveaux clients. Vous pouvez Publier ce modèle en tant que service Web ou écrire les résultats dans Azure synapse.
Étapes suivantes
Pour en savoir plus sur Azure Machine Learning, reportez-vous à Introduction à Machine Learning sur Azure.
En savoir plus sur le scoring intégré dans l’entrepôt de données, ici.