Gestion des incidents de sécurité Microsoft : détection et analyse
Pour détecter les activités malveillantes, chacun des services en ligne consigne de manière centralisée les événements de sécurité et d’autres données et effectue différentes techniques analytiques pour rechercher des activités anormales ou suspectes. Les fichiers journaux sont collectés à partir de serveurs et d’appareils d’infrastructure Microsoft services en ligne et stockés dans des bases de données centralisées et consolidées.
Microsoft adopte une approche basée sur les risques pour détecter les activités malveillantes. Nous utilisons les données d’incident et le renseignement sur les menaces pour définir et hiérarchiser nos détections.
L’utilisation d’une équipe de personnes hautement expérimentées, compétentes et qualifiées est l’un des piliers les plus importants de la réussite de la phase de détection et d’analyse. Microsoft emploie plusieurs équipes de service qui incluent des employés ayant des compétences sur tous les composants de la pile, y compris le réseau, les routeurs, les pare-feu, les équilibreurs de charge, les systèmes d’exploitation et les applications.
Les mécanismes de détection de sécurité dans Microsoft services en ligne incluent également des notifications et des alertes lancées par différentes sources. Microsoft services en ligne équipes de réponse à la sécurité sont les principaux orchestrateurs du processus d’escalade des incidents de sécurité. Ces équipes reçoivent toutes les escalades et sont chargées d’analyser et de confirmer la validité de l’incident de sécurité.
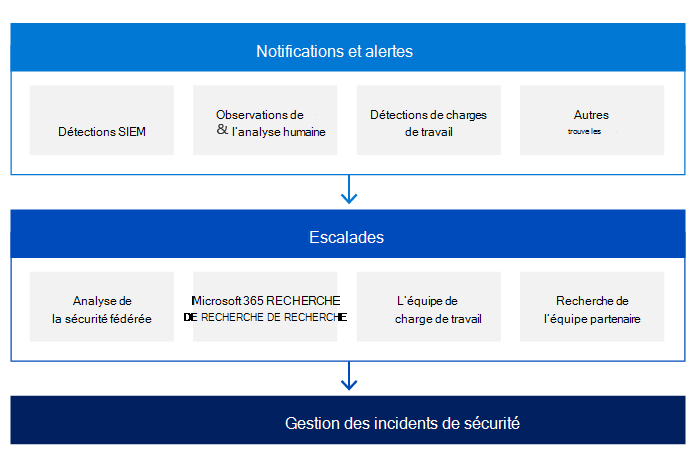
L’un des principaux piliers de la détection est la notification :
- Chaque équipe de service est chargée de consigner toute action ou événement à l’intérieur du service en fonction des exigences de l’équipe de sécurité du service en ligne. Tous les journaux créés par les différentes équipes de service sont traités par une solution SIEM (Security Information and Event Management) avec des règles de sécurité et de détection prédéfinies. Ces règles évoluent en fonction des recommandations de l’équipe de sécurité, sur les informations apprises à partir d’incidents de sécurité précédents, pour déterminer s’il existe une activité suspecte ou malveillante.
- Si un client détermine qu’un incident de sécurité est en cours, il peut ouvrir un cas de support auprès de Microsoft, qui est affecté à l’équipe de communication Microsoft et transformé en escalade vers toutes les équipes appropriées.
Les équipes de service Azure, Dynamics 365 et Microsoft 365 utilisent également les informations acquises dans l’analyse des tendances par le biais de la surveillance et de la journalisation de la sécurité pour détecter les anomalies dans les systèmes d’information Microsoft services en ligne qui peuvent indiquer une attaque ou un incident de sécurité. Microsoft services en ligne systèmes agrègent la sortie de ces journaux dans l’environnement de production en serveurs de journalisation centralisés. À partir de ces serveurs de journalisation centralisés, les journaux d’activité sont examinés pour repérer les tendances dans l’environnement de production. Les données agrégées dans les serveurs centralisés sont transmises en toute sécurité dans un service de journalisation pour l’interrogation avancée, la création de tableau de bord et la détection d’activités anormales et malveillantes. Le service utilise également le Machine Learning pour détecter les anomalies avec la sortie du journal.
Pendant la phase d’escalade et en fonction de la nature de l’incident de sécurité, les équipes de réponse à la sécurité peuvent impliquer un ou plusieurs experts de diverses équipes de Microsoft :
- Équipe sécurité et conformité des services en ligne
- Centre Microsoft Threat Intelligence (MSTIC)
- Microsoft Security Response Center (MSRC)
- Affaires d’entreprise, externes et juridiques (CELA)
- Sécurité Azure
- Ingénierie Microsoft 365, entre autres.
Avant qu’une escalade vers une équipe de réponse de sécurité ne se produise, l’équipe de service est chargée de déterminer et de définir le niveau de gravité de l’incident de sécurité en fonction de critères définis tels que :
- Confidentialité
- Impact
- Portée
- Nombre de locataires affectés
- Région
- Service
- Détails de l’incident
- Réglementations spécifiques du secteur client ou du marché.
La hiérarchisation des incidents est déterminée à l’aide de facteurs distincts, notamment l’impact fonctionnel de l’incident, l’impact informationnel de l’incident et la récupérabilité de l’incident.
Après avoir reçu une escalade concernant un incident de sécurité, l’équipe de sécurité organise une équipe virtuelle (équipe v) composée de membres de l’équipe de réponse à la sécurité du service en ligne Microsoft, des équipes de service et de l’équipe de communication des incidents. L’équipe v doit ensuite confirmer la légitimité de l’incident de sécurité et éliminer les faux positifs. L’exactitude des informations fournies par les indicateurs déterminés pendant la phase de préparation est essentielle. En analysant ces informations par catégorie d’attaque vectorielle, l’équipe v peut déterminer si l’incident de sécurité est une préoccupation légitime.
Au début de l’enquête, l’équipe de réponse aux incidents de sécurité enregistre toutes les informations sur l’incident en fonction de nos stratégies de gestion des cas. À mesure que le cas progresse, nous suivons les actions en cours et suivons les normes de gestion des preuves pour la collecte, la conservation et la sécurisation de ces données tout au long du cycle de vie des incidents.
Voici quelques exemples de ces actions :
- Résumé, qui est une brève description de l’incident et de son impact potentiel
- Gravité et priorité de l’incident, qui sont dérivées de l’évaluation de l’impact potentiel
- Liste de tous les indicateurs identifiés qui ont conduit à la détection de l’incident
- Liste des incidents associés
- Liste de toutes les actions effectuées par l’équipe v
- Toutes les preuves recueillies, qui seront également conservées pour l’analyse post mortem et les futures investigations judiciaires
- Étapes et actions suivantes recommandées
Après la confirmation de l’incident de sécurité, les principaux objectifs de l’équipe de réponse de sécurité et de l’équipe de service appropriée sont de contenir l’attaque, de protéger le ou les services attaqués et d’éviter un impact global plus important. En même temps, les équipes d’ingénierie appropriées s’emploient à déterminer la cause racine et à préparer le premier plan de récupération.
Dans la phase suivante, l’équipe de réponse de sécurité identifie les clients affectés par l’incident de sécurité, le cas échéant. L’étendue de l’effet peut prendre un certain temps pour déterminer, en fonction de la région, du centre de données, du service, de la batterie de serveurs, du serveur, etc. La liste des clients concernés est compilée par l’équipe de service et l’équipe de communication Microsoft correspondante, qui gère ensuite le processus de notification des clients dans le cadre d’obligations contractuelles et de conformité.
Articles connexes
- Gestion des incidents de sécurité Microsoft
- Gestion des incidents de sécurité Microsoft : Préparation
- Gestion des incidents de sécurité Microsoft : confinement, éradication et récupération
- Gestion des incidents de sécurité Microsoft : activité post-incident
- Comment consigner un ticket de support d’événement de sécurité
- Notification de violation Azure et Dynamics 365 dans le cadre du RGPD