Identifier les limites du modèle de domaine pour chaque microservice
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

L’objectif de l’identification des limites et de la taille du modèle pour chaque microservice n’est pas d’obtenir la séparation la plus granulaire possible, même si vous devez tendre vers de petits microservices autant que possible. Votre objectif doit plutôt être de parvenir à la séparation la plus significative en fonction de votre connaissance du domaine. Vous ne devez pas mettre l’accent sur la taille, mais plutôt sur les fonctionnalités métier. De plus, si une cohésion claire est nécessaire pour une certaine zone de l’application en raison d’un grand nombre de dépendances, cela indique également la nécessité d’avoir un seul microservice. La cohésion est une façon d’identifier comment dissocier ou regrouper ensemble des microservices. Enfin, au fil de l’approfondissement de vos connaissances sur le domaine, vous devez adapter la taille de votre microservice par itérations successives. Trouver la bonne taille ne se fait pas en une seule fois.
Sam Newman, promoteur reconnu des microservices et auteur du livre Building Microservices, insiste sur le fait que vous devez concevoir vos microservices en fonction du modèle de contexte délimité (qui fait partie de la conception pilotée par le domaine), introduit précédemment. Parfois, un contexte délimité peut être composé de plusieurs services physiques, mais l’inverse n’est pas vrai.
Un modèle de domaine avec des entités de domaine spécifique s’applique dans un contexte délimité ou un microservice concret. Un contexte délimité détermine l’applicabilité d’un modèle de domaine, et donne aux membres de l’équipe de développement une compréhension claire et partagée de ce qui doit être cohésif et de ce qui peut être développé indépendamment. Ces objectifs sont identiques pour les microservices.
La loi de Conway est un autre outil qui influence vos choix de conception. Elle établit qu’une application reflète les limites sociales de l’organisation qui l’a produite. Toutefois, l’inverse est parfois vrai : l’organisation de l’entreprise est déterminée par le logiciel. Il peut s’avérer nécessaire d’inverser la loi de Conway et de créer les limites selon la façon dont vous souhaitez que l’entreprise soit organisée, en retenant les conseils relatifs au processus métier.
Pour identifier les contextes liés, vous pouvez utiliser un modèle DDD appelé modèle de mappage de contexte. Avec le mappage de contexte, vous identifiez les différents contextes dans l’application et leurs limites. Par exemple, il est courant d’avoir d’un contexte et des limites différents pour chaque petit sous-système. Le mappage de contexte est un moyen de définir et de rendre explicite ces limites entre domaines. Un contexte délimité est autonome et inclut les détails d’un seul domaine (des détails comme les entités de domaine). Il définit les contrats d’intégration avec les autres contextes délimités. Ceci est similaire à la définition d’un microservice : il est autonome, il implémente certaines fonctionnalités de domaine et doit fournir des interfaces. C’est pourquoi le mappage de contexte et le modèle de contexte délimité sont une bonne approche pour identifier les limites du modèle de domaine de vos microservices.
Durant la conception d’une application importante, vous voyez comment son modèle de domaine peut être fragmenté : par exemple, un expert du domaine des catalogues ne nomme pas les entités dans le catalogue et dans l’inventaire de la même façon qu’un expert du domaine des transports. L’entité du domaine utilisateur peut aussi être différente en taille et en nombre d’attributs quand vous traitez avec un expert de la relation clientèle, qui veut stocker tous les détails du client, par rapport à un expert du domaine de la gestion des commandes, qui a besoin seulement de données partielles sur le client. Il est très difficile de lever l’ambiguïté de tous les termes d’un domaine dans tous les domaines liés à une grosse application. Toutefois, le plus important est de ne pas essayer d’unifier les termes. À la place, acceptez les différences et la richesse de chaque domaine. Si vous essayez d’avoir une base de données unifiée pour toute l’application, les tentatives d’obtention d’un vocabulaire unifié sont difficiles et ne semblent correctes pour aucun des experts des différents domaines. Ainsi, les contextes délimités (implémentés en tant que microservices) vous aident à préciser où vous pouvez utiliser certains termes du domaine, et où vous devez scinder le système pour créer des contextes délimités supplémentaires avec des domaines distincts.
Vous savez que vous avez déterminé les bonnes limites et les bonnes tailles de chaque contexte délimité et de chaque modèle de domaine si vous n’avez que quelques relations fortes entre les modèles de domaine. De plus, vous n’avez généralement pas besoin de fusionner les informations provenant de plusieurs modèles de domaine au moment de l’exécution d’opérations d’application classiques.
La meilleure réponse à la question de la taille que doit avoir un modèle de domaine pour chaque microservice est peut-être la suivante : il doit avoir un contexte délimité autonome, aussi isolé que possible, qui vous permet de travailler sans devoir passer constamment à d’autres contextes (autres modèles de microservice). Dans la figure 4-10, vous pouvez voir comment plusieurs microservices (plusieurs contextes délimités) ont chacun leur propre modèle et comment leurs entités peuvent être définies, en fonction des exigences spécifiques de chacun des domaines identifiés dans votre application.
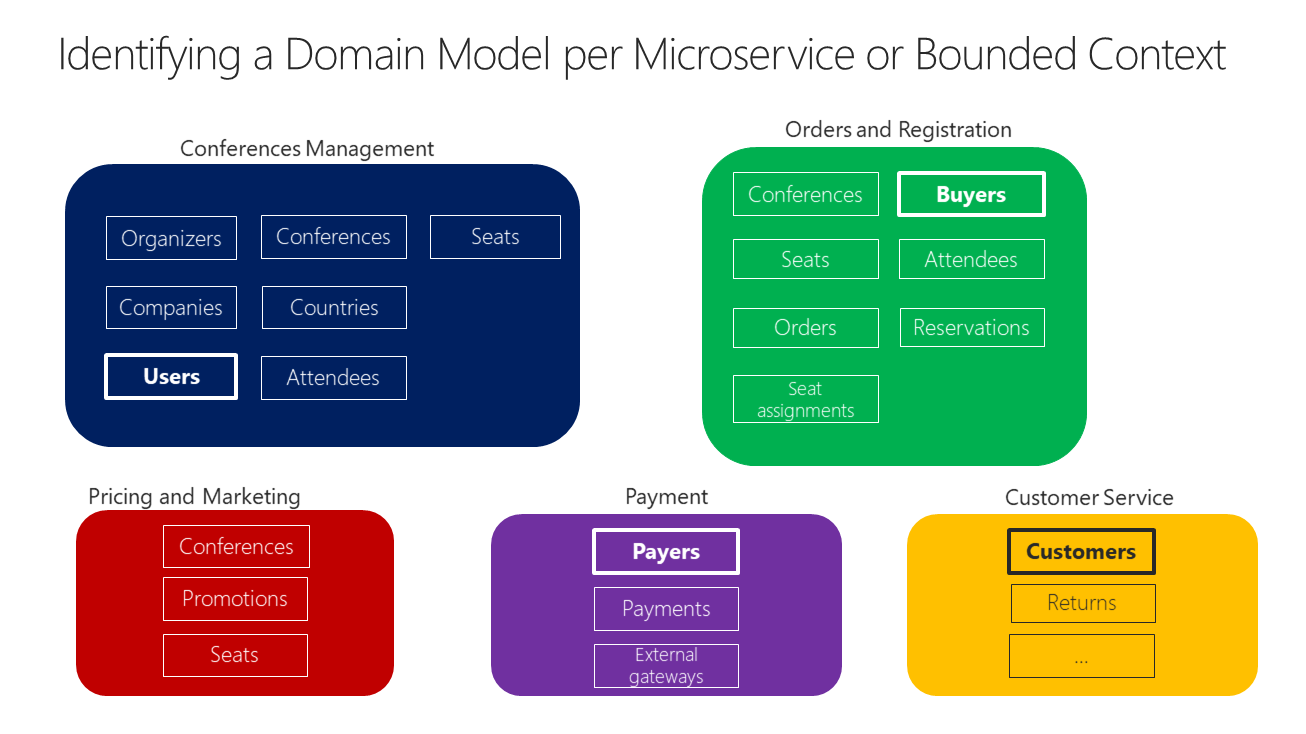
Figure 4-10. Identification des entités et des limites du modèle de microservice
La figure 4-10 illustre un exemple de scénario relatif à un système de gestion de conférences en ligne. La même entité apparaît sous les termes « Users » (Utilisateurs), « Buyers » (Acheteurs), « Payers » (Payeurs) et « Customers » (Clients) en fonction du contexte délimité. Vous avez identifié plusieurs contextes délimités qui peuvent être implémentés en tant que microservices, en fonction des domaines définis pour vous par les experts des domaines. Comme vous pouvez le voir, il existe des entités qui sont présentes dans un seul modèle de microservice, comme Payments (Paiements) dans le microservice Payment (Paiement). Ceux-ci seront faciles à implémenter.
Cependant, vous pouvez également avoir des entités qui ont une forme différente, mais qui partagent la même identité entre les différents modèles de domaine des différents microservices. Par exemple, l’entité User (Utilisateur) est identifiée dans le microservice Conferences Management (Gestion des conférences). Ce même utilisateur, avec la même identité, est celui qui est nommé Buyers (Acheteurs) dans le microservice Ordering (Commandes), ou celui qui est nommé Payer (Payeur) dans le microservice Payment (Paiement), et même celui qui est nommé Customer (Client) dans le microservice Customer Service (Service client). C’est pourquoi, en fonction de l’ubiquité du langage utilisé par chaque expert du domaine, un utilisateur peut avoir une perspective différente, avec même des attributs différents. L’entité représentant un utilisateur dans le modèle de microservice nommé Conferences Management peut avoir la plupart de ses attributs de données personnelles. Cependant, ce même utilisateur dans la forme Payer du microservice Payment ou dans la forme Customer dans le microservice Customer Service peut ne pas nécessiter la même liste d’attributs.
Une approche similaire est illustrée dans la figure 4-11.
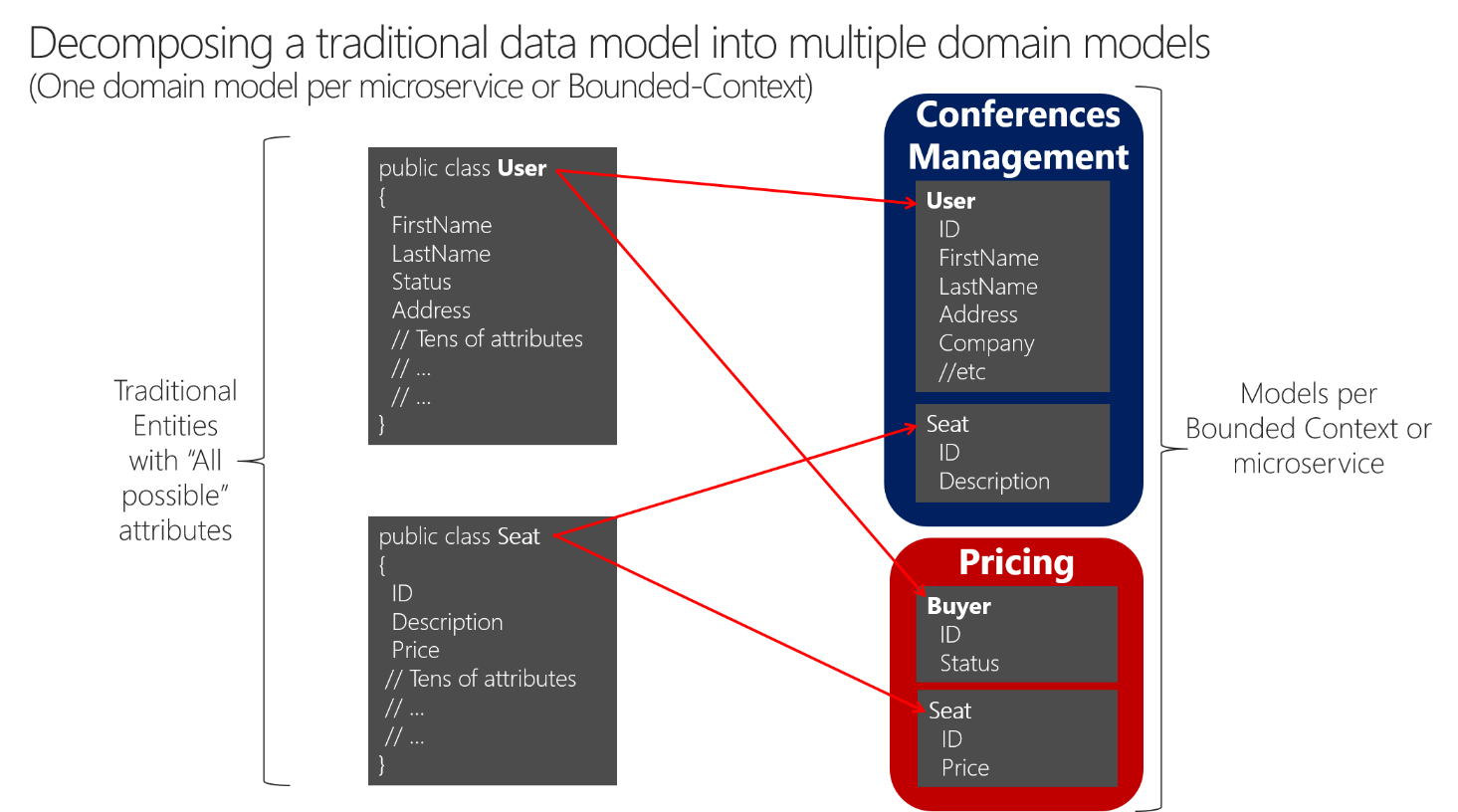
Figure 4-11. Décomposition des modèles de données traditionnels en plusieurs modèles de domaine
Quand vous décomposez un modèle de données classique en plusieurs contextes liés, différentes entités peuvent partager la même identité (un acheteur est également un utilisateur) avec des attributs distincts dans chaque contexte lié. Vous pouvez voir que l’utilisateur est présent dans le modèle de microservice Conferences Management en tant qu’entité User, et qu’il est également présent sous la forme de l’entité Buyer dans le microservice Pricing (Tarification), avec d’autres attributs ou détails sur l’utilisateur quand il est en fait un acheteur. Chaque microservice ou contexte délimité peut ne pas avoir besoin de toutes les données relatives à une entité User, mais seulement d’une partie d’entre elles, selon le problème à résoudre ou le contexte. Par exemple, dans le modèle de microservice Pricing, vous n’avez pas besoin de l’adresse ou du nom de l’utilisateur, mais simplement d’ID (en tant qu’identité) et de Status (État), qui a un impact sur les remises pour la tarification des sièges par acheteur.
L’entité Seat (Siège) a le même nom, mais des attributs différents dans chaque modèle de domaine. Cependant, Seat partage l’identité basée sur le même ID, comme cela se passe avec User et Buyer.
Il existe ici un concept partagé, celui d’un utilisateur présent dans plusieurs services (domaines), qui partagent tous l’identité de cet utilisateur. Il peut cependant exister dans chaque modèle de domaine des détails supplémentaires ou différents sur l’entité utilisateur. Par conséquent, il doit exister un moyen de mapper une entité utilisateur d’un domaine (microservice) à un autre.
Il existe plusieurs avantages à ne pas partager la même entité utilisateur avec le même nombre d’attributs entre les domaines. Un des avantages est de réduire la duplication, de façon que les modèles de microservice n’aient pas les données dont ils n’ont pas besoin. Un autre avantage est d’avoir un microservice principal qui détient un certain type de données par entité, afin que les mises à jour et les requêtes pour ce type de données soient pilotées seulement par ce microservice.