Concevoir une application orientée microservices
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

Cette section porte essentiellement sur le développement d’une application d’entreprise côté serveur hypothétique.
Spécifications de l’application
L’application hypothétique gère les demandes en exécutant une logique métier, en accédant à des bases de données et en retournant des réponses HTML, JSON ou XML. L’application doit prendre en charge une diversité de clients, notamment les navigateurs de bureau exécutant des applications monopages, des applications web classiques, des applications web mobiles et des applications mobiles natives. L’application peut aussi exposer une API pour permettre à des tiers de la consommer. Elle doit par ailleurs pouvoir intégrer ses microservices ou des applications externes de façon asynchrone. Cette approche favorisera ainsi la résilience des microservices en cas de défaillance partielle.
L’application sera constituée des types de composant suivants :
Composants de présentation : ces composants sont chargés de la gestion de l’interface utilisateur et de la consommation des services distants.
Logique de domaine ou métier : ce composant est la logique de domaine de l’application.
Logique d’accès aux bases de données : ce composant est constitué des composants d’accès aux données chargés d’accéder aux bases de données (SQL ou NoSQL).
Logique d’intégration de l’application : ce composant comprend un canal de messagerie basé sur des répartiteurs de messages.
L’application nécessitera une haute scalabilité, tout en permettant une montée en charge autonome de ses sous-systèmes verticaux, car certains d’entre eux auront besoin d’une plus grande scalabilité que d’autres.
L’application doit pouvoir être déployée dans plusieurs environnements d’infrastructure (plusieurs clouds publics et en local) et doit idéalement être multiplateforme, avec la possibilité de passer facilement de Linux à Windows (et inversement).
Contexte de l’équipe de développement
Nous partirons aussi des principes suivants en ce qui concerne le processus de développement de l’application :
Les différents domaines opérationnels de l’application seront gérés par des équipes de développement distinctes.
Les nouveaux membres d’équipe doivent être vite opérationnels, et l’application doit être facile à comprendre et à modifier.
L’application est appelée à évoluer dans le temps, tout comme ses règles métier.
Vous avez besoin d’une grande facilité de maintenance dans le temps, ce qui signifie que vous devez pouvoir implémenter les futures modifications tout en étant en mesure de mettre à jour plusieurs sous-systèmes sans trop perturber les autres sous-systèmes.
Vous voulez pratiquer une intégration continue et un déploiement continu de l’application.
Vous souhaitez tirer parti des nouvelles technologies (frameworks, langages de programmation, etc.) à mesure que l’application évolue. Vous ne souhaitez pas effectuer de migrations complètes de l’application après avoir adopté de nouvelles technologies en raison des coûts élevés induits et de l’impact sur la prévisibilité et la stabilité de l’application.
Choix d’une architecture
Quelle doit être l’architecture de déploiement d’application ? Les spécifications de l’application, parallèlement au contexte de développement, invitent fortement à architecturer l’application en sous-systèmes autonomes sous la forme de microservices et de conteneurs qui collaborent, où chaque microservice est un conteneur.
Dans cette approche, chaque service (conteneur) implémente un ensemble de fonctions cohésives et étroitement liées. Par exemple, une application peut se composer de services tels que le service catalogue, le service commandes, le service panier d’achat, le service profil utilisateur, etc.
Les microservices communiquent via des protocoles tels que HTTP (REST), mais aussi de façon asynchrone (par exemple, via AMQP) chaque fois que cela est possible, surtout pendant la propagation de mises à jour avec des événements d’intégration.
Les microservices sont développés et déployés en tant que conteneurs indépendamment les uns des autres. Avec cette approche, une équipe de développement peut développer et déployer un microservice donné sans que cela n’impacte les autres sous-systèmes.
Chaque microservice dispose de sa propre base de données, ce qui le découple entièrement des autres microservices. Quand elle est nécessaire, la cohérence entre les bases de données des différents microservices est obtenue à travers l’utilisation d’événements d’intégration au niveau de l’application (via un bus d’événements logiques), à l’instar de la séparation des responsabilités en matière de commande et de requête (CQRS). Compte tenu de cela, les contraintes métier doivent accepter la cohérence à terme entre les différents microservices et les bases de données associées.
eShopOnContainers : une application de référence pour .NET et des microservices déployés à l’aide de conteneurs
Pour vous éviter d’avoir à réfléchir sur un domaine d’activité hypothétique que vous ne connaissez peut-être pas et ainsi vous permettre de vous concentrer sur l’architecture et les technologies, nous avons sélectionné un domaine d’activité bien connu, à savoir une application d’e-commerce simplifiée (boutique en ligne) qui présente un catalogue de produits, accepte les commandes des clients, vérifie les stocks et effectue d’autres fonctions opérationnelles. Le code source de cette application basée sur des conteneurs est disponible sur le dépôt GitHub eShopOnContainers.
L’application est constituée de divers sous-systèmes, notamment de plusieurs front-ends d’interface utilisateur de magasin (une application web et une application mobile native), ainsi que des microservices et des conteneurs back-end pour toutes les opérations côté serveur nécessaires avec plusieurs passerelles d’API comme points d’entrée consolidés dans les microservices internes. La figure 6-1 illustre l’architecture de l’application de référence.
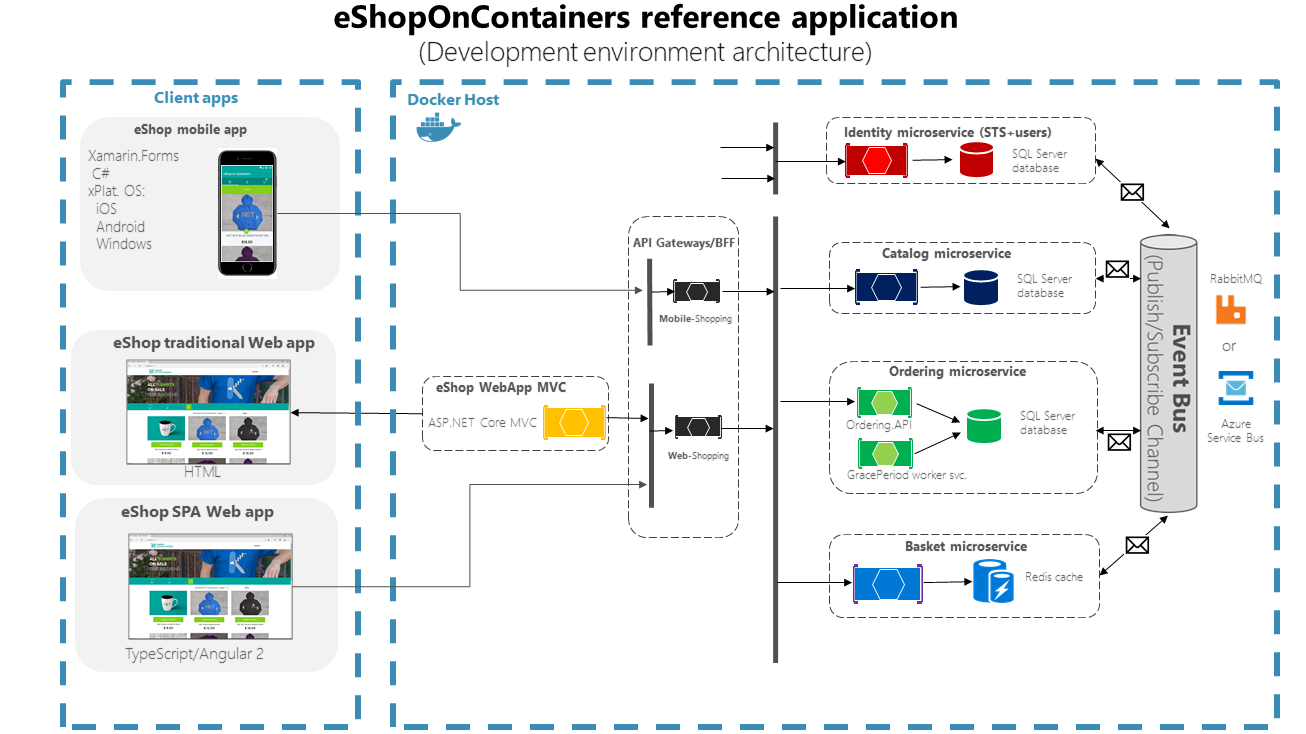
Figure 6-1 : Architecture d’application de référence eShopOnContainers pour l’environnement de développement
Le diagramme ci-dessus montre que les clients mobiles et SPA communiquent avec des points de terminaison de passerelles API uniques, qui communiquent ensuite avec les microservices. Les clients web traditionnels communiquent avec le microservice MVC, qui communique avec les microservices par le biais de la passerelle API.
Environnement d’hébergement : dans la figure 6-1, vous pouvez constater que plusieurs conteneurs sont déployés dans un seul hôte Docker. Cela se produit quand le déploiement est exécuté dans un seul hôte Docker avec la commande docker-compose up. Cependant, si vous utilisez un cluster d’orchestrateurs ou de conteneurs, chaque conteneur peut s’exécuter dans un hôte (nœud) distinct, et un nœud peut exécuter n’importe quel nombre de conteneurs, comme nous l’avons vu dans la section traitant de l’architecture.
Architecture de communication : l’application eShopOnContainers utilise deux types de communication, en fonction du type de l’action fonctionnelle (requêtes ou mises à jour et transactions) :
Communication de client à microservice HTTP via des passerelles d’API. Cette approche est utilisée pour les requêtes et quand il s’agit d’accepter les commandes de mise à jour ou les commandes transactionnelles des applications clientes. L’approche utilisant des passerelles d’API est expliquée en détail dans des sections ultérieures.
Communication asynchrone basé sur les événements : Cette communication emprunte un bus d’événements pour propager des mises à jour aux microservices ou pour s’intégrer avec des applications externes. Le bus d’événements peut être implémenté avec n’importe quelle technologie d’infrastructure de répartiteur de messagerie comme RabbitMQ ou en utilisant des Service Bus (de niveau d’abstraction) plus généralistes comme Azure Service Bus, NServiceBus, MassTransit ou Brighter.
L’application est déployée comme un ensemble de microservices sous forme de conteneurs. Les applications clientes peuvent communiquer avec ces microservices exécutés en tant que conteneurs via les URL publiques publiées par les passerelles d’API.
Souveraineté des données par microservice
Dans l’exemple d’application, chaque microservice possède sa propre base de données ou source de données, bien que toutes les bases de données SQL Server soient déployées comme conteneur unique. Cette décision de conception a été prise uniquement dans le but de faciliter la tâche des développeurs au moment d’obtenir le code sur GitHub, de le cloner et de l’ouvrir dans Visual Studio ou Visual Studio Code. Par ailleurs, elle facilite la compilation des images Docker personnalisées à partir de l’interface CLI .NET et de l’interface CLI Docker et ensuite leur déploiement et leur exécution dans un environnement de développement Docker. Dans les deux cas, l’utilisation de conteneurs pour les sources de données permet aux développeurs de générer et de déployer en quelques minutes sans avoir à provisionner une base de données externe ou toute autre source de données dépendant fortement de l’infrastructure (cloud ou locale).
Dans un environnement de production réel, pour la haute disponibilité et la scalabilité, les bases de données doivent être basées sur des serveurs de base de données dans le cloud ou en local, mais pas dans des conteneurs.
Par conséquent, les unités de déploiement pour les microservices (et même pour les bases de données de cette application) sont des conteneurs Docker, et l’application de référence est une application multiconteneur qui adhère aux principes des microservices.
Ressources supplémentaires
- Code source de l’application de référence eShopOnContainers Code source pour l’application de référence
https://aka.ms/eShopOnContainers/
Avantages d’une solution basée sur des microservices
Une solution basée sur des microservices présente de nombreux avantages :
Chaque microservice est relativement réduit en taille, ce qui facilite sa gestion et son évolution. Plus précisément :
Il est facile à appréhender pour un développeur et sa prise en main s’avère rapide, ce qui autorise une bonne productivité.
Les conteneurs démarrent rapidement, ce qui contribue à améliorer la productivité des développeurs.
Un IDE tel que Visual Studio peut charger rapidement les projets plus petits, ce qui favorise la productivité des développeurs.
Chaque microservice peut être conçu, développé et déployé indépendamment des autres microservices, ce qui offre de l’agilité, car il est plus facile de déployer régulièrement de nouvelles versions des microservices.
Il est possible de faire monter en charge certaines parties de l’application : par exemple, le service catalogue ou le service panier d’achat peuvent nécessiter une montée en charge, mais pas le processus de commande. Une infrastructure de microservices se montre beaucoup plus efficace qu’une architecture monolithique par rapport aux ressources utilisées lors d’une montée en charge.
Vous pouvez répartir le travail de développement entre plusieurs équipes : chaque service peut être sous la responsabilité d’une seule équipe de développement. Chaque équipe peut gérer, développer, déployer et mettre à l’échelle son service indépendamment des autres équipes.
Les problèmes sont plus isolés : en cas de problème dans un service, seul ce service est initialement impacté (sauf si la conception utilisée est inappropriée, avec l’existence de dépendances directes entre les microservices) et les autres services peuvent continuer à traiter les demandes. En revanche, dans une architecture de déploiement monolithique, la défaillance d’un seul composant peut paralyser l’ensemble du système, surtout si des ressources sont impliquées, comme dans le cas d’une fuite de mémoire. De plus, dès que le problème qui touche un microservice est résolu, vous pouvez simplement déployer le microservice concerné sans impacter le reste de l’application.
Vous pouvez utiliser les dernières technologies : sachant que vous pouvez commencer à développer des services de manière indépendante et les exécuter côte à côte (grâce aux conteneurs et à .NET), vous pouvez commencer à utiliser avantageusement les technologies et les frameworks les plus récents au lieu de vous en tenir à une pile ou à un framework plus ancien pour l’ensemble de l’application.
Inconvénients d’une solution basée sur des microservices
Une solution basée sur des microservices présente aussi quelques inconvénients :
Application distribuée : le fait que l’application soit distribuée complique la tâche des développeurs au moment de concevoir et générer les services. Par exemple, les développeurs doivent implémenter une communication interservice en utilisant des protocoles tels que HTTP ou AMQP, ce qui ajoute de la complexité pour les tests et la gestion des exceptions. Cela augmente aussi la latence du système.
Complexité du déploiement : une application qui compte plusieurs dizaines de types de microservice et qui nécessite une haute scalabilité (elle doit pouvoir créer un grand nombre d’instances par service et équilibrer ces services sur les nombreux hôtes) se traduit par une grande complexité de déploiement pour les opérations et la direction informatiques. Si vous n’utilisez pas d’infrastructure orientée microservices (comme un orchestrateur et un planificateur), cette complexité supplémentaire peut demander beaucoup plus d’efforts de déploiement que l’application métier proprement dite.
Transactions atomiques : les transactions atomiques entre plusieurs microservices sont généralement impossibles. La cohérence à terme entre les divers microservices doit être incorporée dans les exigences métier. Pour plus d’informations, consultez les défis liés au traitement des messages idempotents.
Besoins accrus en ressources globales (mémoire totale, lecteurs et ressources réseau pour tous les serveurs ou hôtes) : dans bien des cas, quand vous remplacez une application monolithique par une approche de microservices, la quantité de ressources globales initiales exigée par la nouvelle application basée sur des microservices est supérieure aux besoins d’infrastructure de l’application monolithique d’origine. Cette approche repose sur le fait que le niveau de précision plus élevé et les services distribués demandent davantage de ressources globales. Or, compte tenu du faible coût des ressources en général et de l’avantage de pouvoir effectuer un scale-out de certaines parties de l’application par rapport aux applications monolithiques et à leur coût sur le long terme pour les faire évoluer, l’utilisation accrue de ressources est généralement un bon compromis pour les grandes applications s’inscrivant sur le long terme.
Problèmes liés à la communication directe de client à microservice : quand il s’agit d’une application étoffée constituée de plusieurs dizaines de microservices, des problèmes et des limitations sont à prévoir si l’application impose des communications directes entre les clients et les microservices. L’un des problèmes possibles est une différence entre les besoins du client et des API exposées par chaque microservice. Dans certains cas, l’application cliente peut être amenée à effectuer de nombreuses demandes distinctes pour composer l’interface utilisateur, ce qui peut s’avérer inefficace sur Internet et serait irréalisable sur un réseau mobile. Par conséquent, les demandes de l’application cliente à destination du système backend doivent être réduites au minimum.
Un autre problème concernant les communications directes entre les clients et les microservices est lié au fait que certains microservices peuvent utiliser des protocoles non compatibles avec le web. Il peut arriver qu’un service utilise un protocole binaire et qu’un autre utilise la messagerie AMQP. Ces protocoles n’étant pas compatibles avec un pare-feu, il est préférable de les utiliser en interne. En règle générale, une application doit utiliser des protocoles tels que HTTP et des WebSockets pour communiquer à l’extérieur du pare-feu.
Un autre inconvénient de cette approche directe entre les clients et les services est qu’elle complique la refactorisation des contrats pour ces microservices. Au fil du temps, les développeurs peuvent souhaiter changer la façon dont le système est partitionné en services. Par exemple, il peut vouloir fusionner deux services ou scinder un service en plusieurs services. Or, si les clients communiquent directement avec les services, ce type de refactorisation peut contrarier la compatibilité avec les applications clientes.
Comme indiqué dans la section traitant de l’architecture, si vous avez l’intention de concevoir et de générer une application complexe basée sur des microservices, vous pouvez envisager d’utiliser plusieurs passerelles d’API affinées plutôt que l’approche de communication directe de client à microservice.
Partitionnement des microservices : enfin, quelle que soit l’approche que vous retenez pour votre architecture de microservices, la manière de partitionner une application complète en plusieurs microservices constitue un autre défi. Comme indiqué dans ce guide dans la section traitant de l’architecture, il existe plusieurs techniques et approches. En fait, vous devez identifier les parties de l’application qui sont découplées des autres parties et qui comptent un nombre limité de fortes dépendances. Dans bien des cas, cette approche va de pair avec le partitionnement des services par cas d’usage. Par exemple, dans notre application de boutique en ligne, nous avons un service commandes qui est responsable de toute la logique métier liée au processus de commande. Nous sommes aussi en présence du service catalogue et du service panier d’achat qui implémentent d’autres fonctionnalités. Dans l’idéal, chaque service ne doit avoir qu’un petit nombre de responsabilités. Cette approche s’apparente au principe de responsabilité unique (SRP) qui s’applique aux classes, selon lequel une classe ne doit avoir qu’une seule raison de changer. Mais dans le cas qui nous intéresse, il s’agit de microservices, dont l’étendue est plus importante qu’une classe unique. Surtout, un microservice doit être autonome, de bout en bout, notamment en ce qui concerne la responsabilité de ses propres sources de données.
Architectures externe/interne et modèles de conception
Une architecture externe est une architecture de microservices composée de plusieurs services, conformément aux principes décrits dans la section de ce guide traitant de l’architecture. Cependant, selon la nature de chaque microservice, et quelle que soit l’architecture de microservices générale que vous choisissez, il est courant et parfois conseillé d’avoir différentes architectures internes, chacune basée sur des modèles différents, pour les différents types de microservice. Les microservices peuvent même utiliser des technologies et des langages de programmation différents. La figure 6-2 illustre cette diversité.
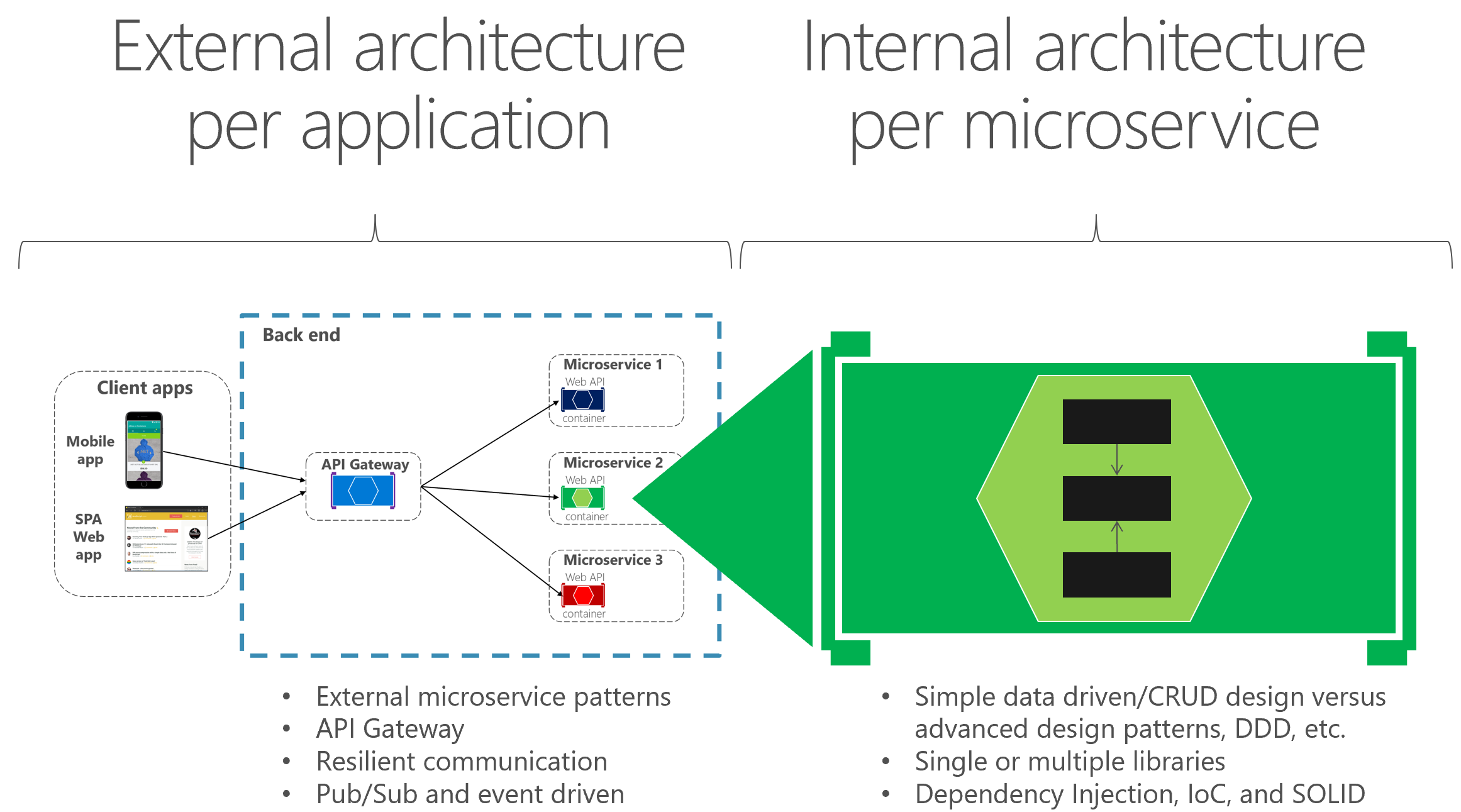
Figure 6-2 : architectures externe/interne et conception
Par exemple, dans notre exemple eShopOnContainers, les microservices catalogue, panier d’achat et profil utilisateur sont simples (il s’agit avant tout de sous-systèmes CRUD). Par conséquent, leur conception et leur architecture interne ne présentent pas de difficultés. Toutefois, d’autres microservices, comme le microservice commande, peuvent s’avèrent plus complexes et refléter des règles métier en constante évolution et une grande complexité de domaine. En pareil cas, vous pouvez souhaiter implémenter des modèles plus élaborés au sein d’un microservice déterminé, comme ceux définis avec les approches de conception pilotée par le domaine (ou DDD, Domain-Driven Design), à l’image du microservice commandes d’eShopOnContainers. (Ces modèles DDD seront examinés plus loin dans la section qui explique l’implémentation du microservice commandes d’eShopOnContainers.)
La décision d’utiliser une technologie différente par microservice peut être justifiée par la nature de chaque microservice. Par exemple, il peut être préférable d’utiliser un langage de programmation fonctionnel comme F#, voire un langage tel que R, si vous ciblez les domaines de l’IA et du machine learning, plutôt qu’un langage de programmation plus orienté objet comme C#.
Le fait est que chaque microservice peut avoir une architecture interne différente basée sur un modèle de conception différent. Il n’est pas souhaitable d’implémenter tous les microservices avec des modèles DDD élaborés, car cet effort d’ingénierie serait inutile. De la même façon, les microservices complexes dont la logique métier évolue en permanence ne sauraient être implémentés en tant que composants CRUD, car le code qui en résulterait serait de mauvaise qualité.
La nouvelle tendance : plusieurs modèles d’architecture et des microservices polyglottes
Les architectes logiciels et les développeurs font appel à divers modèles d’architecture. En voici quelques-uns (mêlant différents styles d’architecture et différents modèles d’architecture) :
CRUD simple, un seul niveau, une seule couche
Conception pilotée par le domaine (DDD) en couches (N-Layered)
Architecture propre (telle que celle utilisé avec eShopOnWeb)
Séparation des responsabilités dans les commandes et les requêtes (CQRS)
Vous pouvez aussi générer des microservices avec diverses technologies et divers langages, notamment les API web ASP.NET Core, NancyFx, ASP.NET Core SignalR (disponible avec .NET Core, versions 2 et ultérieures), F#, Node.js, Python, Java, C++, GoLang, etc.
Le point important est qu’aucun modèle ou style d’architecture en particulier, ni aucune technologie en particulier, ne convient à toutes les situations. La figure 6-3 présente certaines approches et technologies (dans un ordre aléatoire) qui pourraient être utilisées dans différentes microservices.
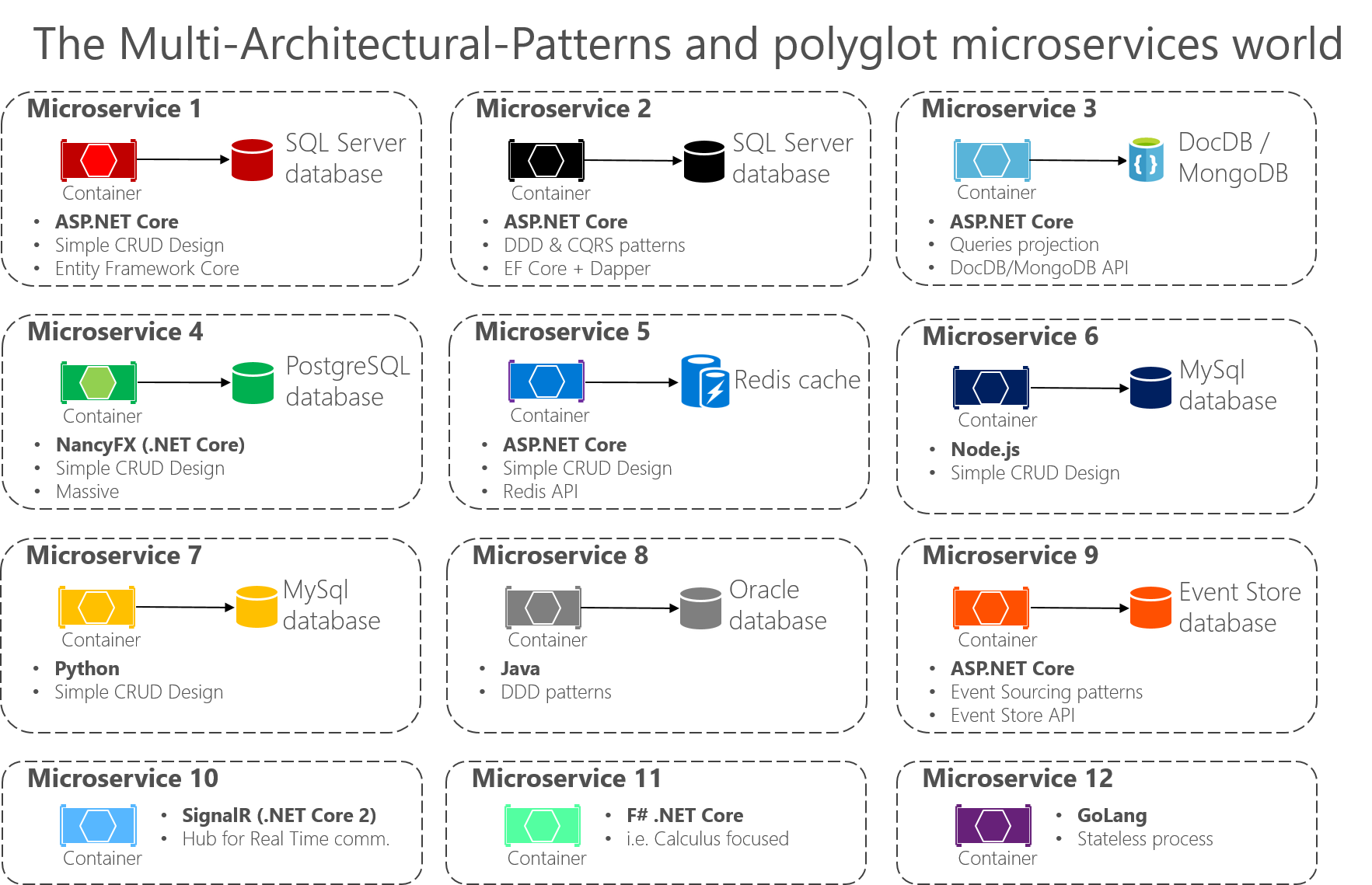
Figure 6-3. l’univers des modèles à plusieurs architectures et des microservices polyglottes
Le modèle à plusieurs architectures avec microservices polyglottes permet de combiner les langages et les technologies pour les adapter aux besoins de chaque microservice tout en leur permettant de communiquer entre eux. Comme le montre la figure 6-3, dans les applications constituées de nombreux microservices (on parle de contextes limités dans la terminologie de la conception pilotée par le domaine, ou simplement de « sous-systèmes » pour les microservices autonomes), vous pouvez implémenter chaque microservice d’une façon différente. Chacun d’eux peut s’appuyer sur un modèle d’architecture différent et utiliser des langages et des bases de données qui varient en fonction de la nature de l’application, des exigences de l’entreprise et des priorités. Dans certains cas, les microservices peuvent être similaires. Mais ce n’est généralement pas le cas, car la limite de contexte et les exigences de chaque sous-système sont en principe différentes.
Par exemple, pour une application de gestion CRUD simple, concevoir et implémenter des modèles DDD ne se justifie pas. Mais pour votre domaine de base ou votre cœur de métier, vous devrez peut-être appliquer des modèles plus élaborés pour faire face à la complexité métier avec des règles métier en constante évolution.
Vous devrez éviter d’appliquer une seule architecture de niveau supérieur basée sur un seul modèle d’architecture, surtout si vous avez affaire à de grandes applications constituées de plusieurs sous-systèmes. Par exemple, il n’est pas judicieux d’appliquer le modèle CQRS en tant qu’architecture de niveau supérieur à l’échelle d’une application entière, mais il peut s’avérer être utile pour un ensemble spécifique de services.
Il n’existe pas de solution miracle, ni de modèle d’architecture universel. Un même modèle d’architecture ne peut pas convenir dans tous les cas. Selon les priorités de chaque microservice, vous devez pour chacun d’eux choisir une approche différente comme expliqué dans les sections suivantes.