Tutoriel : Détecter les panneaux stop dans des images avec Model Builder
Découvrez comment créer un modèle de détection d’objets en utilisant ML.NET Model Builder et Azure Machine Learning pour détecter et localiser les panneaux stop dans les images.
Dans ce tutoriel, vous allez apprendre à :
- Préparer et comprendre les données
- Créer un fichier config Model Builder
- Choisir le scénario
- Choisir l’environnement d’entraînement
- Chargement des données
- Effectuer l’apprentissage du modèle
- Évaluer le modèle
- Utiliser le modèle pour les prévisions
Prérequis
Pour obtenir la liste des prérequis et les instructions d’installation, consultez le Guide d’installation de Model Builder.
Vue d’ensemble de la détection d’objets de Model Builder
La détection d’objets est un problème de vision par ordinateur. Même si elle est étroitement liée à la classification d’images, la détection d’objets effectue une classification d’images à une échelle plus précise. La détection d’objets localise et catégorise les entités dans les images. L’apprentissage des modèles de détection d’objet s’effectue généralement à l’aide du Deep Learning et des réseaux neuronaux. Pour plus d’informations, consultez Deep learning et machine learning.
Utilisez la détection d’objets quand les images contiennent plusieurs objets de différents types.

Voici quelques cas d’utilisation de la détection d’objets :
- Voitures autonomes
- Robotique
- Détection de visage
- Sécurité des espaces de travail
- Dénombrement des objets
- Reconnaissance des activités
Cet exemple crée une application console C# .NET Core qui détecte les panneaux stop dans des images en utilisant un modèle Machine Learning créé avec Model Builder. Le code source de ce tutoriel est disponible dans le dépôt GitHub dotnet/machinelearning-samples.
Préparer et comprendre les données
Le jeu de données Stop Sign se compose de 50 images téléchargées depuis Unsplash, chacune contenant au moins un signe stop.
Créer un projet VoTT
Téléchargez le jeu de données de 50 images de signe stop et décompressez-le.
Téléchargez VoTT (Visual Object Tagging Tool).
Ouvrez VoTT, puis sélectionnez Nouveau projet.
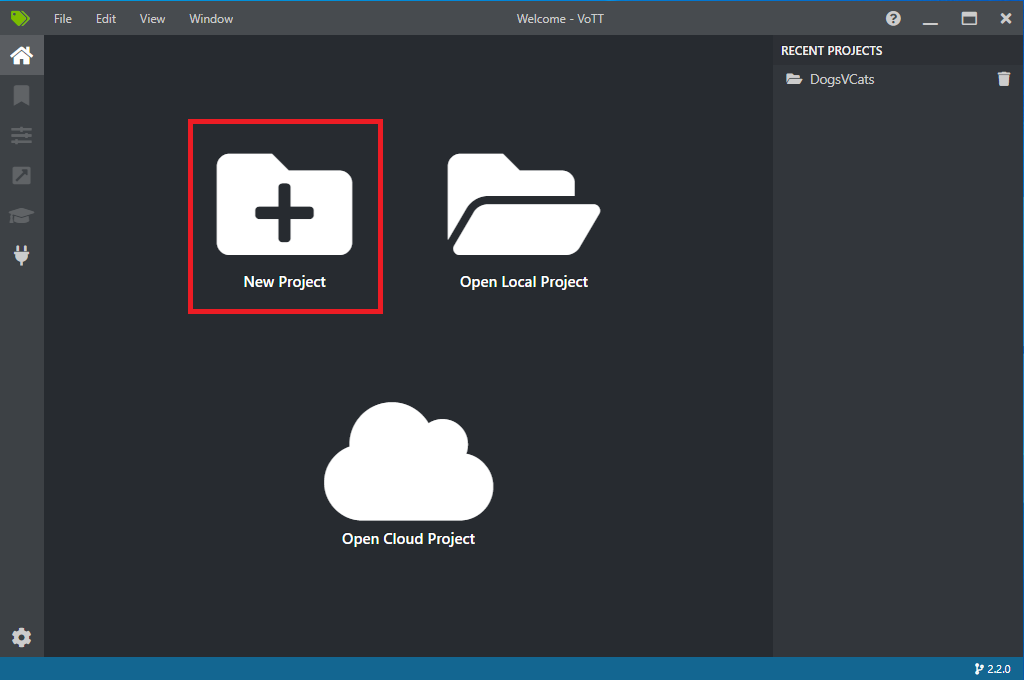
Dans Paramètres du projet, remplacez le Nom d’affichage par « StopSignObjDetection ».
Modifiez le Jeton de sécurité pour Générer un nouveau jeton de sécurité.
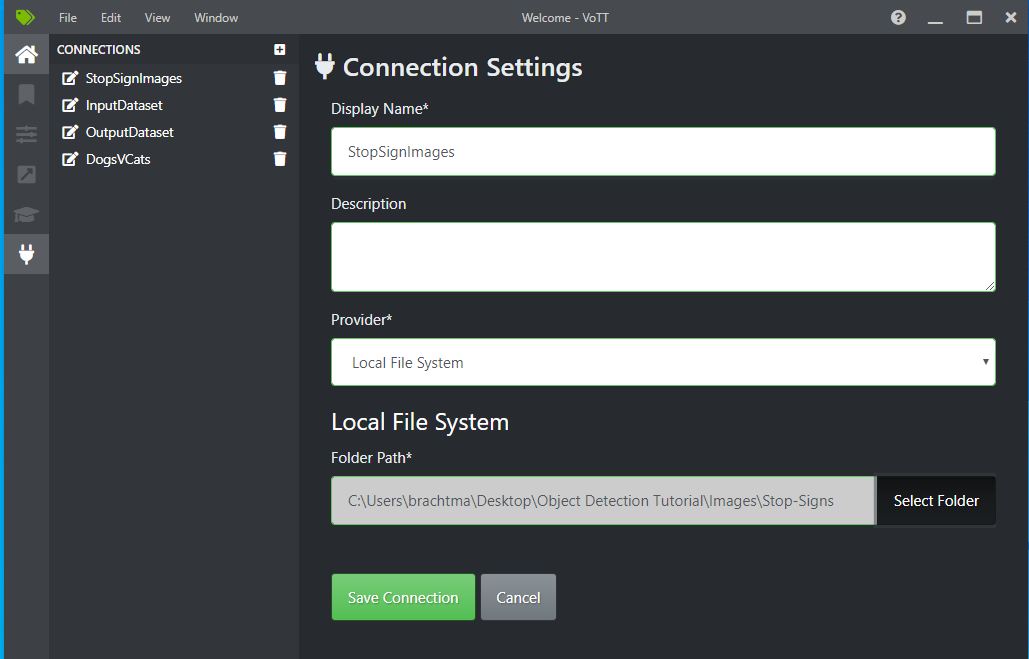
En regard de Connexion source, sélectionnez Ajouter une connexion.
Dans Paramètres de connexion, remplacez le Nom d’affichage pour la connexion source par « StopSignImages », puis sélectionnez Système de fichiers local comme Fournisseur. Pour le Chemin du dossier, sélectionnez le dossier Stop-Signs qui contient les 50 images d’entraînement, puis sélectionnez Enregistrer la connexion.
Dans Paramètres du projet, remplacez la Connexion source par StopSignImages (la connexion que vous venez de créer).
Remplacez également la Connexion cible par StopSignImages. Vos Paramètres de projet doivent maintenant ressembler à cette capture d’écran :
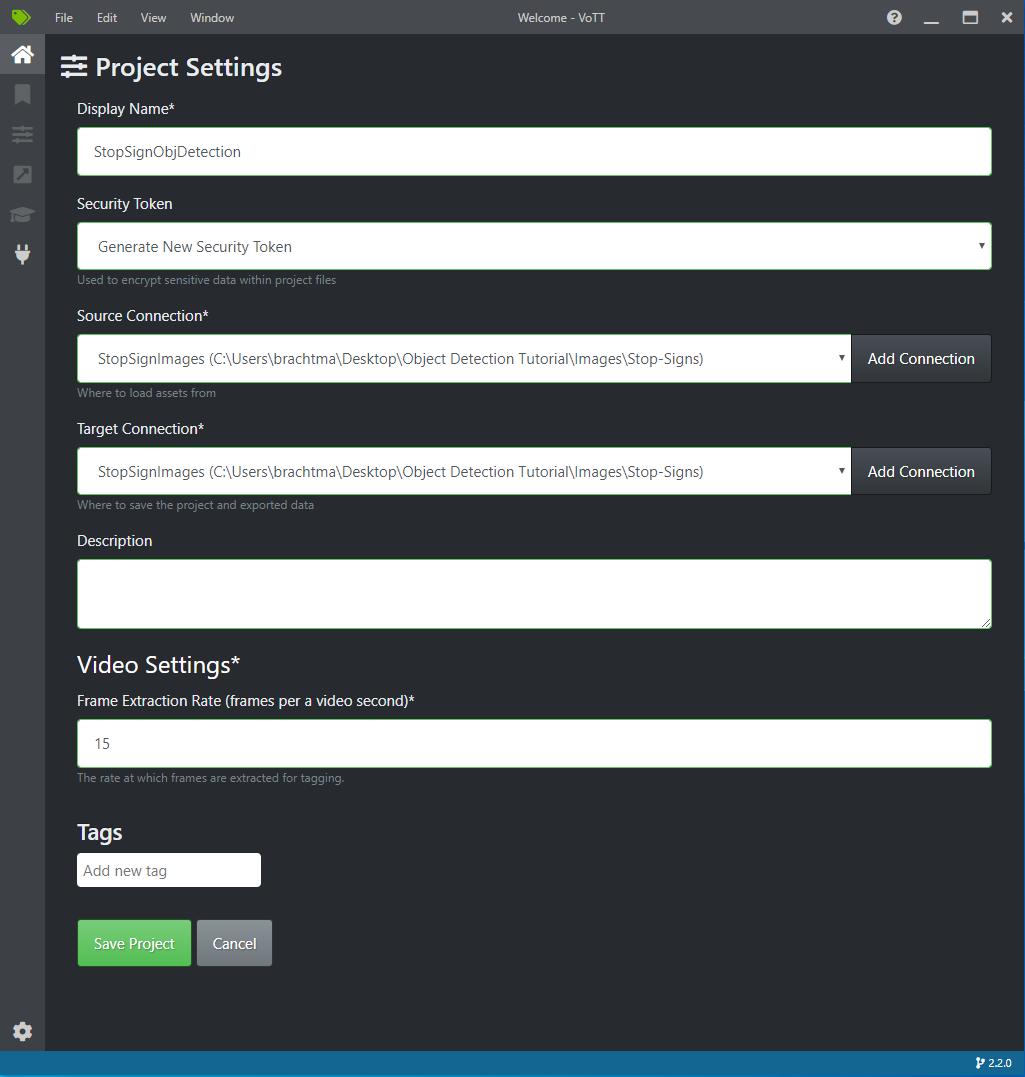
Sélectionnez Enregistrer le projet.
Ajouter une étiquette et étiqueter les images
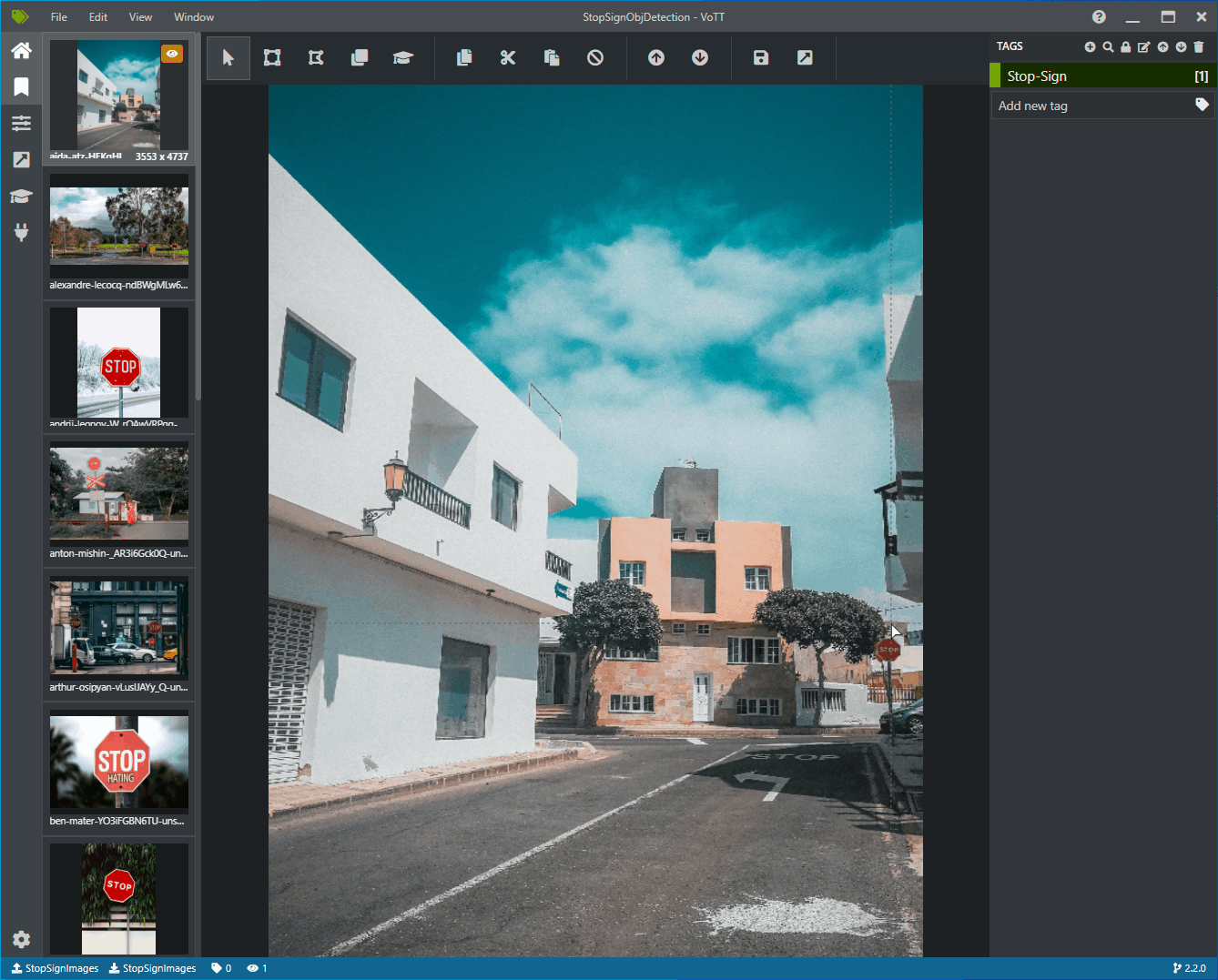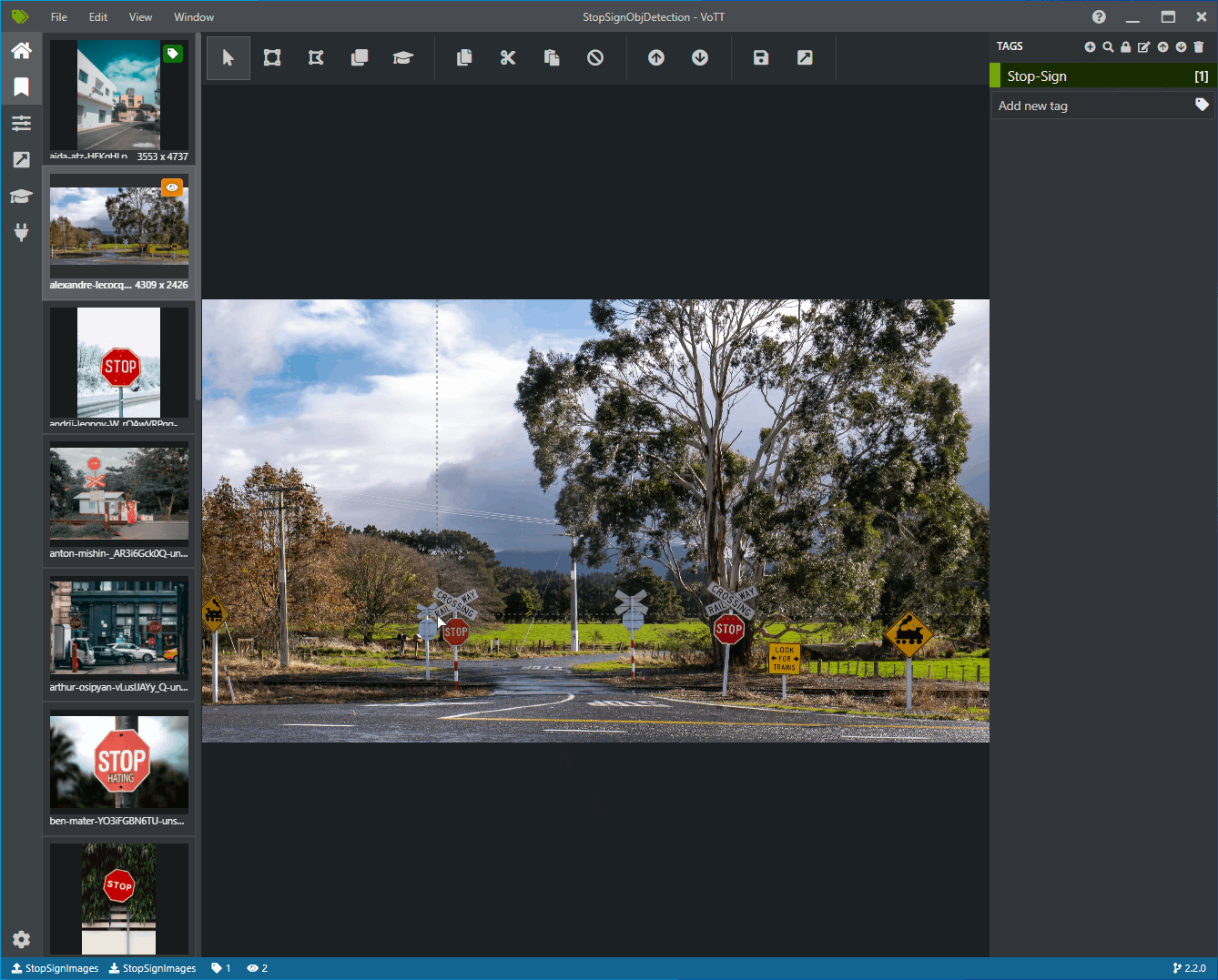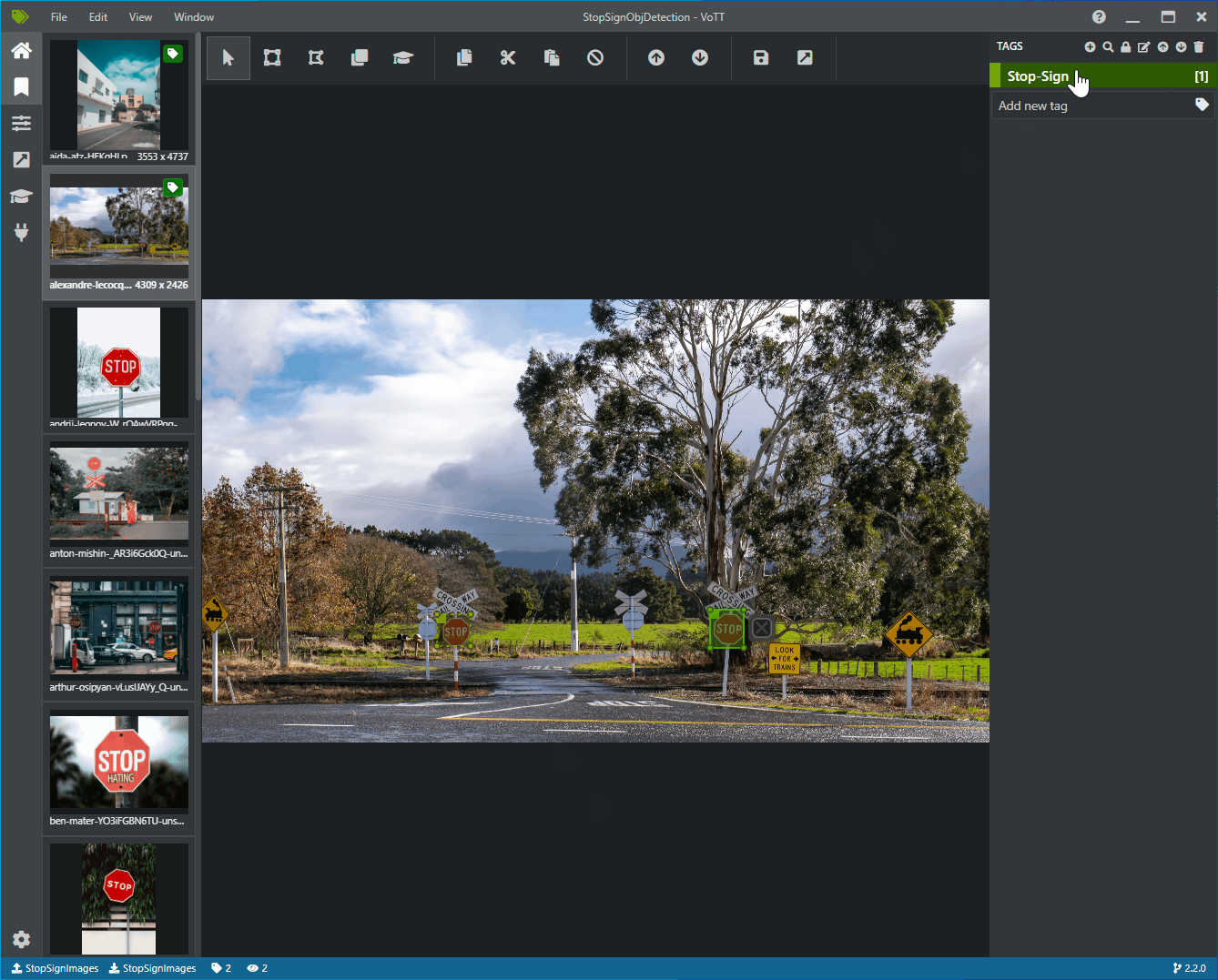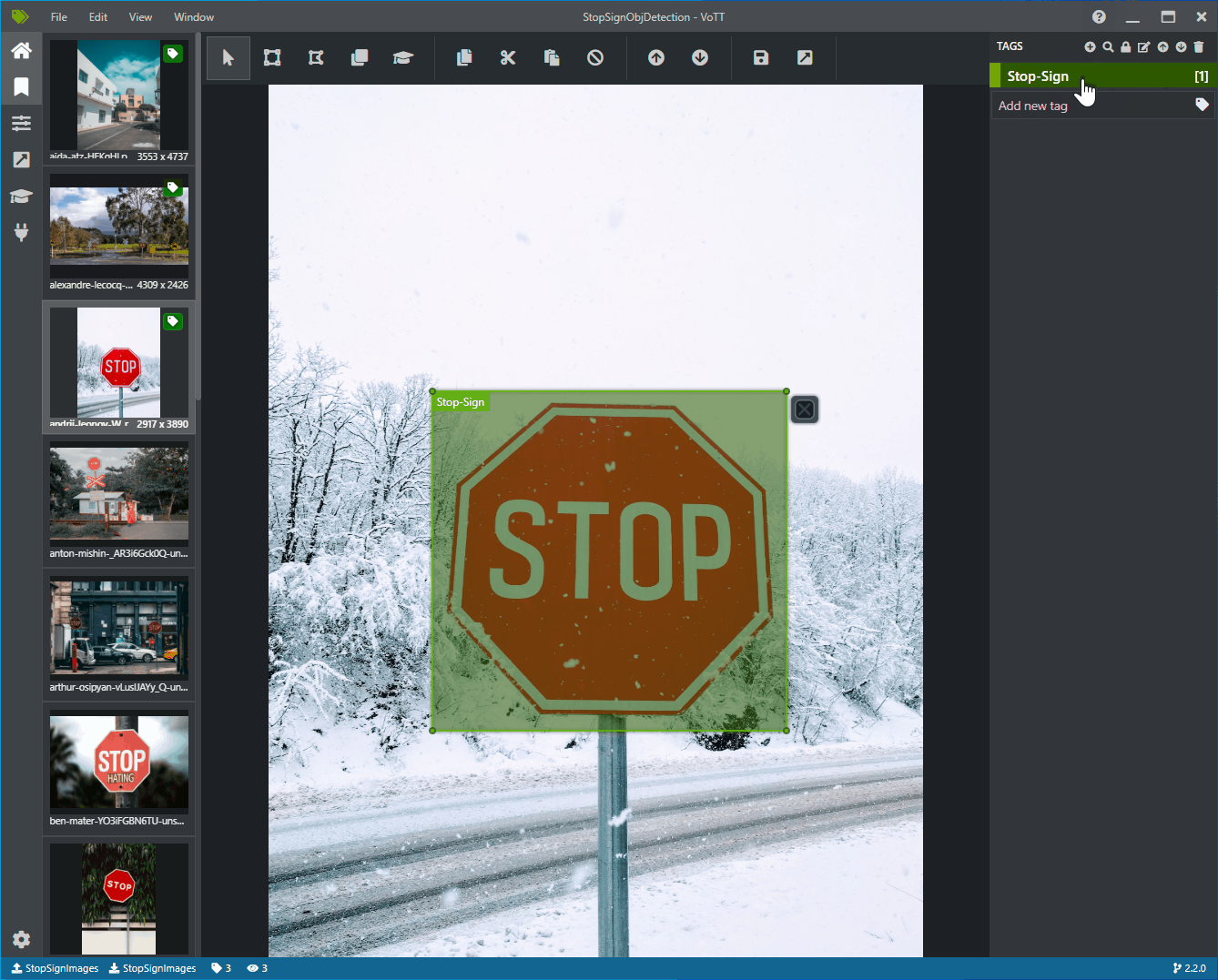
Vous devez maintenant voir une fenêtre avec des aperçus de toutes les images d’entraînement à gauche, un aperçu de l’image sélectionnée au milieu et une colonne Étiquettes à droite. Cet écran est l’éditeur d’étiquettes.
Sélectionnez la première icône (en forme de signe plus) dans la barre d’outils Étiquettes pour ajouter une nouvelle étiquette.

Nommez l’étiquette « Stop-Sign », puis appuyez sur Entrée sur votre clavier.

Cliquez et faites glisser pour dessiner un rectangle autour de chaque signe stop dans l’image. Si le curseur ne vous permet pas de dessiner un rectangle, essayez en sélectionnant l’outil Dessiner un rectangle dans la barre d’outils située en haut ou utilisez le raccourci clavier R.
Après avoir dessiné votre rectangle, sélectionnez l’étiquette Stop-Sign que vous avez créée dans les étapes précédentes pour ajouter l’étiquette au cadre englobant.
Cliquez sur l’aperçu pour l’image suivante dans le jeu de données et répétez ce processus.
Suivez les étapes 3 à 4 pour chaque signe stop dans chaque image.
Exporter votre JSON VoTT
Une fois que vous avez étiqueté toutes vos images d’entraînement, vous pouvez exporter le fichier qui sera utilisé par Model Builder pour l’entraînement.
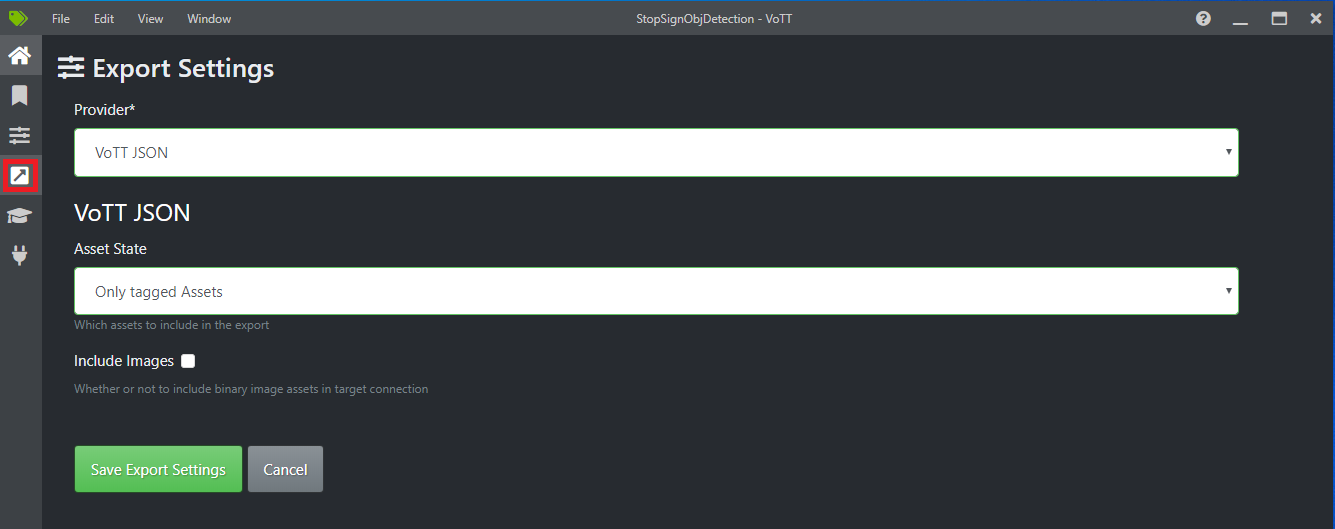
Sélectionnez la quatrième icône dans la barre d’outils de gauche (celle avec la flèche en diagonale dans une case) pour accéder aux Paramètres d’exportation.
Laissez le Fournisseur défini sur JSON VoTT.
Changez État de la ressource en Seulement les ressources étiquetées.
Décochez Inclure les images. Si vous incluez les images, les images d’entraînement seront copiées dans le dossier d’exportation généré, ce qui n’est pas nécessaire.
Sélectionnez Enregistrer les paramètres d’exportation.
Revenez à l’éditeur d’étiquettes (la deuxième icône de la barre d’outils de gauche en forme de ruban). Dans la barre d’outils du haut, sélectionnez l’icône Exporter le projet (la dernière icône en forme de flèche dans une case) ou utilisez le raccourci clavier Ctrl+E.

Cette exportation crée un dossier appelé vott-json-export dans votre dossier Stop-Sign-Images et génère un fichier JSON nommé StopSignObjDetection-export dans ce nouveau dossier. Vous allez utiliser ce fichier JSON dans les étapes suivantes pour entraîner un modèle de détection d’objets dans Model Builder.
Création d’une application console
Dans Visual Studio, créez une application console C# .NET Core appelée StopSignDetection.
Créer un fichier mbconfig
- Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le projet StopSignDetection, puis sélectionnez Ajouter>Modèle Machine Learning... pour ouvrir l’interface utilisateur de Model Builder.
- Dans la boîte de dialogue, nommez le projet Model Builder StopSignDetection, puis cliquez sur Ajouter.
Choisir un scénario
Pour cet exemple, le scénario est la détection d’objets. Dans l’étape Scénario de Model Builder, sélectionnez le scénario Détection d’objets.
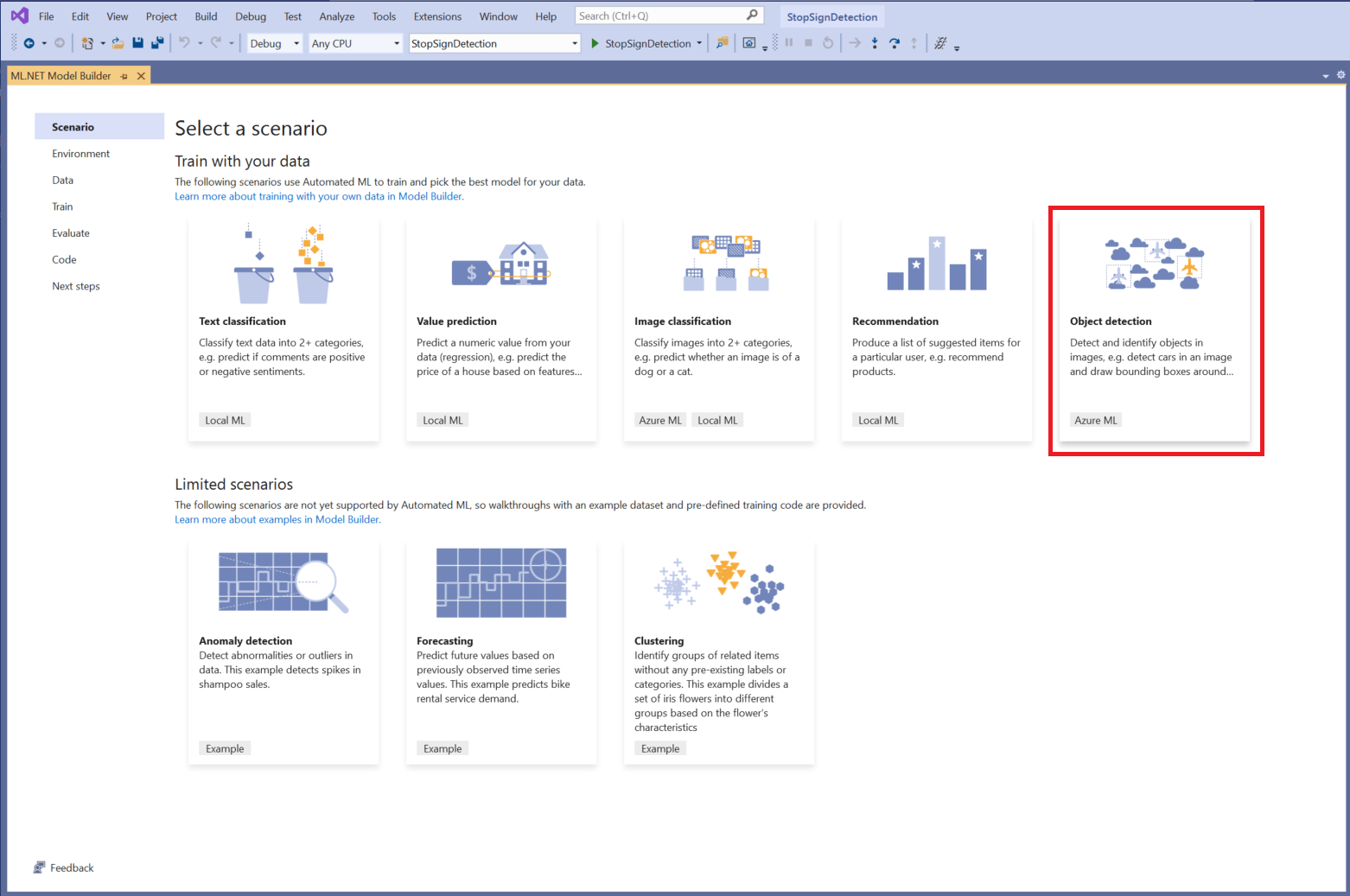
Si vous ne voyez pas Détection d’objets dans la liste des scénarios, il peut être nécessaire de mettre à jour votre version de Model Builder.
Choisir l’environnement d’entraînement
Actuellement, Model Builder prend en charge l’entraînement des modèles de détection d’objets seulement avec Azure Machine Learning : l’environnement d’entraînement Azure est donc sélectionné par défaut.
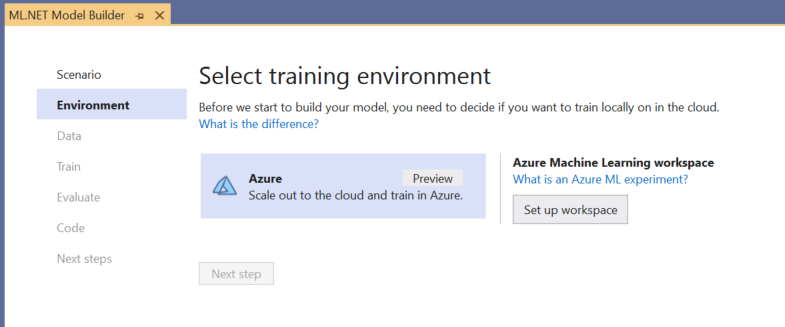
Pour entraîner un modèle en utilisant Azure ML, vous devez créer une expérience Azure ML à partir de Model Builder.
Une expérience Azure ML est une ressource qui encapsule la configuration et les résultats d’une ou plusieurs exécutions d’entraînement de Machine Learning.
Pour créer une expérience Azure ML, vous devez d’abord configurer votre environnement dans Azure. Une expérience a besoin des éléments suivants pour s’exécuter :
- Un abonnement Azure
- Un espace de travail : une ressource Azure ML qui fournit un emplacement central pour l’ensemble des ressources et artefacts Azure ML créés dans le cadre d’une exécution d’entraînement.
- Un calcul : un calcul Azure Machine Learning est une machine virtuelle Linux dans le cloud, utilisée pour l’entraînement. En savoir plus sur les types de calcul pris en charge par Model Builder.
Configurer un espace de travail Azure ML
Pour configurer votre environnement :
Sélectionnez le bouton Configurer un espace de travail.
Dans la boîte de dialogue Créer une expérience, sélectionnez votre abonnement Azure.
Sélectionnez un espace de travail existant ou créez un espace de travail Azure ML.
Quand vous créez un espace de travail, les ressources suivantes sont provisionnées :
- Espace de travail Azure Machine Learning
- Stockage Azure
- Azure Application Insights
- Azure Container Registry
- Azure Key Vault
Ce processus peut donc prendre quelques minutes.
Sélectionnez un calcul existant ou créez un calcul Azure ML. Ce processus peut prendre quelques minutes.
Laissez le nom de l’expérience par défaut et sélectionnez Créer.
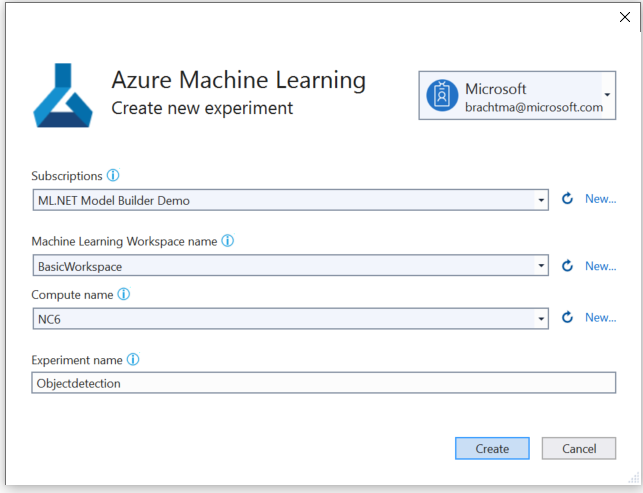
La première expérience est créée et le nom de l’expérience est inscrit dans l’espace de travail. Toutes les exécutions suivantes (si le même nom d’expérience est utilisé) sont enregistrées comme faisant partie de la même expérience. Sinon, une nouvelle expérience est créée.
Si vous êtes satisfait de votre configuration, sélectionnez le bouton Étape suivante dans Model Builder pour passer à l’étape Données.
Chargement des données
Dans l’étape Données de Model Builder, vous allez sélectionner votre jeu de données d’entraînement.
Important
Model Builder accepte actuellement seulement le format JSON généré par VoTT.
Sélectionnez le bouton dans la section Entrée et utilisez l’Explorateur de fichiers pour rechercher le fichier
StopSignObjDetection-export.json, qui doit se trouver dans le répertoire Stop-Signs/vott-json-export.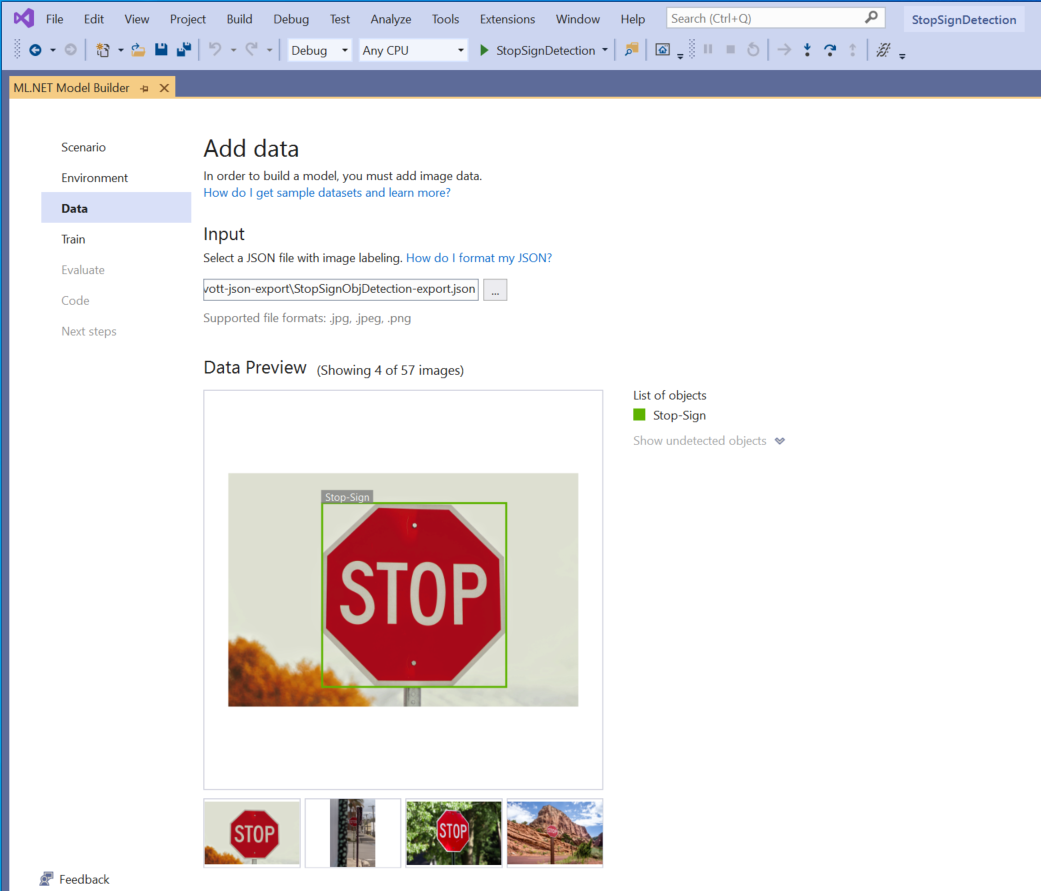
Si vos données semblent correctes dans l’Aperçu des données, sélectionnez Étape suivante pour passer à l’étape Entraîner.
Entraîner le modèle
L’étape suivante consiste à entraîner votre modèle.
Dans l’écran Entraîner de Model Builder, sélectionnez le bouton Démarrer l’entraînement.
À ce stade, vos données sont chargées dans Stockage Azure et le processus d’entraînement commence dans Azure ML.
Le processus d’entraînement prend un certain temps, et sa durée peut varier en fonction de la taille du calcul sélectionné ainsi que de la quantité de données. La première fois qu’un modèle est entraîné dans Azure, vous pouvez vous attendre à un temps d’entraînement légèrement plus long, car les ressources doivent être provisionnées. Pour cet exemple de 50 images, l’entraînement a pris environ 16 minutes.
Vous pouvez suivre la progression de vos exécutions dans le portail Azure Machine Learning en sélectionnant le lien Surveiller l’exécution actuelle dans le portail Azure dans Visual Studio.
Une fois l’entraînement terminé, sélectionnez le bouton Étape suivante pour passer à l’étape Évaluer.
Évaluer le modèle
Dans l’écran Évaluer, vous obtenez une vue d’ensemble des résultats du processus d’entraînement, y compris la justesse du modèle.
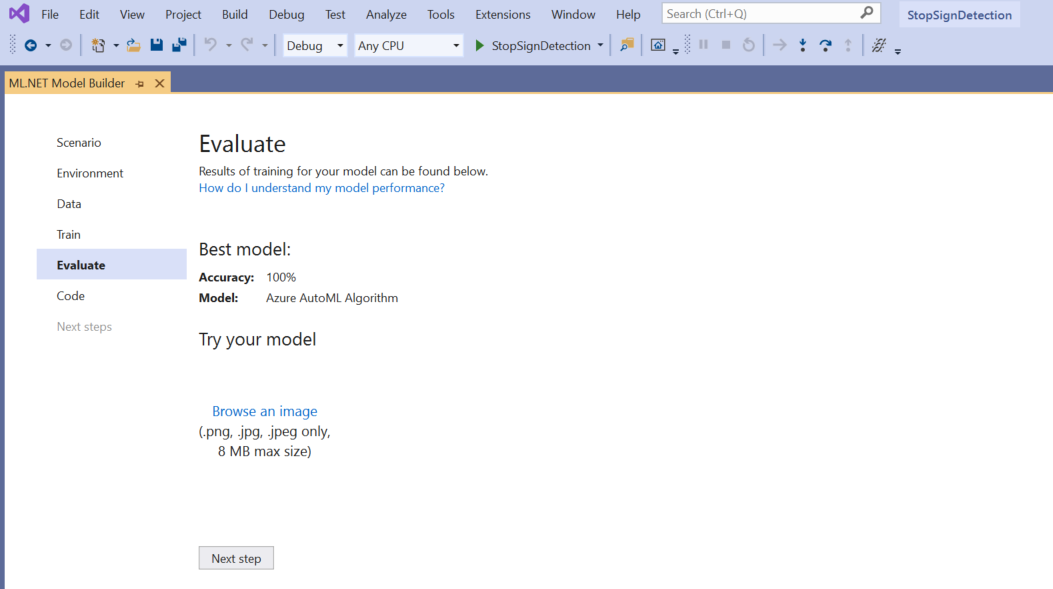
Dans le présent, la justesse indique 100 %, ce qui signifie que le modèle est plus que probablement surajusté en raison d’un trop petit nombre d’images dans le jeu de données.
Vous pouvez utiliser l’expérience Essayer votre modèle pour vérifier rapidement si votre modèle fonctionne comme prévu.
Sélectionnez Parcourir une image et fournissez une image de test, de préférence une image que le modèle n’a pas utilisée dans le cadre de l’entraînement.
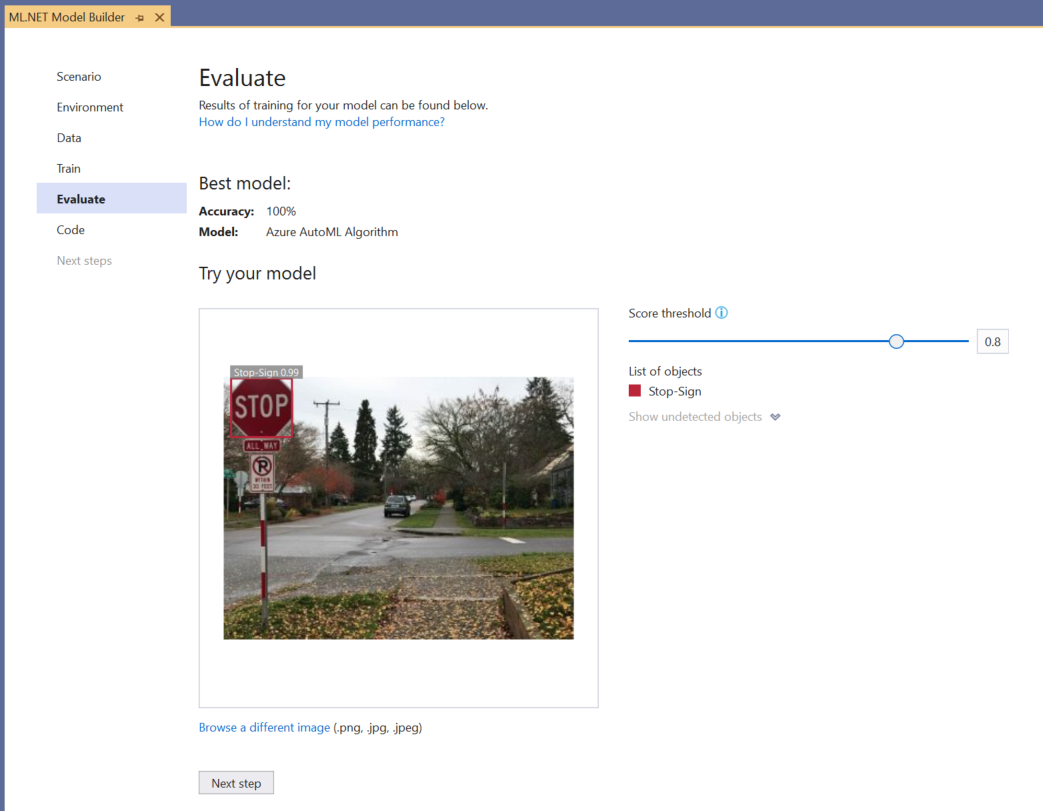
Le score affiché sur chaque cadre englobant détecté indique la confiance de l’objet détecté. Par exemple, dans la capture d’écran ci-dessus, le score dans le cadre englobant autour du signe stop indique que le modèle est sûr à 99 % que l’objet détecté est un signe stop.
Le Seuil de score, qui peut être augmenté ou diminué avec le curseur de seuil, va ajouter et supprimer les objets détectés en fonction de leur score. Par exemple, si le seuil est de 0,51, le modèle va montrer seulement les objets dont le score de confiance est de 0,51 ou plus. À mesure que vous augmentez le seuil, vous voyez moins d’objets détectés et, à mesure que vous diminuez le seuil, vous voyez plus d’objets détectés.
Si vous n’êtes pas satisfait de vos métriques de justesse, un moyen simple d’essayer d’améliorer la justesse du modèle consiste à utiliser davantage de données. Sinon, sélectionnez le lien Étape suivante pour passer à l’étape Consommer dans Model Builder.
(Facultatif) Consommer le modèle
Cette étape aura des modèles de projet que vous pouvez utiliser pour utiliser le modèle. Cette étape est facultative et vous pouvez choisir la méthode qui correspond le mieux à vos besoins sur la façon de servir le modèle.
- Application console
- API Web
Application console
Lorsque vous ajoutez une application console à votre solution, vous êtes invité à nommer le projet.
Nommez le projet de console StopSignDetection_Console.
Cliquez sur Ajouter à la solution pour ajouter le projet à votre solution actuelle.
Exécutez l’application.
La sortie générée par le programme doit se présenter comme l’extrait de code ci-dessous :
Predicted Boxes: Top: 73.225296, Left: 256.89764, Right: 533.8884, Bottom: 484.24243, Label: stop-sign, Score: 0.9970765
API Web
Lorsque vous ajoutez une API web à votre solution, vous êtes invité à nommer le projet.
Nommez le projet d’API web StopSignDetection_API.
Cliquez sur Ajouter à la solution pour ajouter le projet à votre solution actuelle.
Exécutez l’application.
Ouvrez PowerShell et entrez le code suivant, où PORT est le port d’écoute de votre application.
$body = @{ ImageSource = <Image location on your local machine> } Invoke-RestMethod "https://localhost:<PORT>/predict" -Method Post -Body ($body | ConvertTo-Json) -ContentType "application/json"Si elle réussit, la sortie doit ressembler au texte ci-dessous.
boxes labels scores boundingBoxes ----- ------ ------ ------------- {339.97797, 154.43184, 472.6338, 245.0796} {1} {0.99273646} {}- La colonne
boxesfournit les coordonnées du cadre englobant de l’objet qui a été détecté. Les valeurs présentes ici correspondent respectivement aux coordonnées gauche, haut, droite et bas. - Les
labelssont l’index des étiquettes prédites. Dans le cas présent, la valeur 1 est un signe stop. - Le
scoresdéfinit le niveau de confiance du modèle quant au fait que le cadre englobant appartient à cette étiquette.
Notes
(Facultatif) Les coordonnées du cadre englobant sont normalisées pour une largeur de 800 pixels et une hauteur de 600 pixels. Pour mettre à l’échelle les coordonnées du cadre englobant de votre image dans un post-traitement ultérieur, vous devez :
- Multipliez les coordonnées haut et bas par la hauteur de l’image d’origine, et multipliez les coordonnées gauche et droite par la largeur de l’image d’origine.
- Divisez les coordonnées haut et bas par 600, et divisez les coordonnées gauche et droite par 800.
Par exemple, étant donné les dimensions de l’image d’origine,
actualImageHeightetactualImageWidth, et unModelOutputappeléprediction, l’extrait de code suivant montre comment mettre à l’échelle les coordonnées deBoundingBox:var top = originalImageHeight * prediction.Top / 600; var bottom = originalImageHeight * prediction.Bottom / 600; var left = originalImageWidth * prediction.Left / 800; var right = originalImageWidth * prediction.Right / 800;Une image peut avoir plusieurs cadres englobants : le même processus doit donc être appliqué à chacun des cadres englobants de l’image.
- La colonne
Félicitations ! Vous avez créé un modèle Machine Learning pour détecter les signes stop dans les images en utilisant Model Builder. Le code source de ce tutoriel est disponible dans le dépôt GitHub dotnet/machinelearning-samples.
Ressources supplémentaires
Pour en savoir plus sur les rubriques mentionnées dans ce tutoriel, consultez les ressources suivantes :