Vue d’ensemble des tâches d’importation et d’exportation de données
Pour créer et gérer des tâches d’importation et d’exportation de données, vous utilisez l’espace de travail Gestion des données. Par défaut, le processus d’importation et d’exportation de données crée une table intermédiaire pour chaque entité dans la base de données cible. Les tables intermédiaires permettent de vérifier, nettoyer ou convertir des données avant de les déplacer.
Note
Cet article suppose que vous êtes familiarisé avec les entités de données.
Processus d’importation et d’exportation de données
Voici les étapes pour importer ou exporter des données.
Créez une tâche d’importation ou d’exportation en effectuant les tâches suivantes :
- Définissez la catégorie de projet.
- Identifiez les entités à importer ou exporter.
- Définissez le format de données pour la tâche.
- Séquencez les entités afin qu’elles soient traitées en groupes logiques et dans un ordre cohérent.
- Déterminez si vous souhaitez utiliser des tables intermédiaires.
Vérifiez que les données sources et cibles sont mises en correspondance correctement.
Vérifiez la sécurité de votre tâche d’importation ou d’exportation.
Exécutez la tâche d’importation ou d’exportation.
Vérifiez que la tâche a été exécutée comme prévu en examinant l’historique des tâches.
Nettoyez les tables intermédiaires.
Les autres sections de cet article fournissent plus d’informations sur chaque étape du processus.
Remarque
Afin d’actualiser l’écran Importation/exportation de données pour afficher la dernière progression, utilisez l’icône d’actualisation d’écran. L’actualisation au niveau du navigateur n’est pas recommandée, car elle interrompt les tâches d’importation/d’exportation qui ne sont pas exécutées par lots.
Créer une tâche d’importation ou d’exportation
Une tâche d’importation ou d’exportation de données peut être exécutée une ou plusieurs fois.
Définir la catégorie de projet
Nous vous recommandons de prendre le temps de sélectionner une catégorie de projet appropriée pour votre tâche d’importation ou d’exportation. Les catégories de projet peuvent vous aider à gérer les tâches associées.
Identifier les entités à importer ou exporter
Vous pouvez ajouter des entités spécifiques à une tâche d’importation ou d’exportation ou sélectionner un modèle à appliquer. Les modèles remplissent une tâche avec une liste d’entités. L’option Appliquer un modèle n’est disponible qu’après avoir attribué un nom à la tâche et enregistré la tâche.
Définir le format de données pour la tâche
Quand vous sélectionnez une entité, vous devez sélectionner le format des données à exporter ou importer. Définissez des formats à l’aide de la vignette Paramétrage de sources de données. Un format de données sources est une combinaison de Type, de Format de fichier, de Séparateur de ligne et de Séparateur de colonne. Il existe d’autres attributs, mais ceux-ci sont les principaux attributs à comprendre. Le tableau suivant répertorie les combinaisons valides.
| Format de fichier | Séparateur de colonnes/lignes | Style XML |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | Élément XML Attribut XML |
| Délimité, largeur fixe | Virgule, point-virgule, onglet, barre verticale, deux points | -NA- |
Remarque
Il est important de sélectionner la valeur appropriée pour Séparateur de ligne, Séparateur de colonne, et Qualificatif de texte, si l’option Format de fichier est définie sur Délimité. Assurez-vous que vos données ne contiennent pas le caractère utilisé comme délimiteur ou qualificateur, car cela peut entraîner des erreurs au moment de l’importation et de l’exportation.
Note
Pour les formats de fichiers basés sur XML, veillez à n’utiliser que des caractères légaux. Pour plus d’informations sur les caractères valides, voir Caractères valides dans XML 1.0. XML 1.0 n’autorise aucun caractère de contrôle à l’exception des tabulations, des retours chariot et des sauts de ligne. Des exemples de caractères illégaux sont les crochets, les accolades et les barres obliques inverses.
Pour importer ou exporter des données, utilisez Unicode au lieu d’une page de code spécifique. Cela aide à fournir les résultats les plus cohérents et à éliminer les échecs des tâches de gestion des données, car elles incluent des caractères Unicode. Les formats de données source définis par le système qui utilisent Unicode ont tous Unicode dans le nom de la source. Le format Unicode est appliqué en sélectionnant une page de code ANSI de codage Unicode comme Page de code dans l’onglet Paramètres régionaux. Sélectionnez l’une des pages de codes suivantes pour Unicode :
| Page de codes | Nom d’affichage |
|---|---|
| 1 200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Pour plus d’informations sur les pages de code, voir Identificateurs de page de code.
Séquencer les entités
Les entités peuvent être séquencées dans un modèle de données, ou dans des tâches d’importation et d’exportation. Quand vous exécutez une tâche qui contient plusieurs entités de données, vous devez vous assurer que les entités de données sont correctement séquencées. Séquencez principalement les entités afin de pouvoir traiter les dépendances fonctionnelles entre les entités. Si les entités n’ont aucune dépendance fonctionnelle, elles peuvent être planifiées pour l’importation ou l’exportation parallèle.
Unités, niveaux et séquences d’exécution
L’unité d’exécution, le niveau dans l’unité d’exécution, et la séquence d’une entité permettent de contrôler l’ordre dans lequel les données sont exportées ou importés.
- Dans chaque unité d’exécution, les entités sont traitées en parallèle.
- Dans chaque unité d’exécution, les entités sont traitées en parallèle si elles ont le même niveau.
- À chaque niveau, les entités sont traitées en fonction de leur numéro de séquence à ce niveau-là.
- Une fois qu’un niveau est traité, on passe au niveau suivant.
Reséquençage
Vous pouvez reséquencer vos entités dans les cas suivants :
- Si une seule tâche de données est utilisée pour toutes vos modifications, vous pouvez utiliser les options de reséquençage pour optimiser le temps d’exécution de la tâche complète. Dans ces cas, vous pouvez utiliser l’unité d’exécution pour représenter le module, le niveau pour représenter la zone de la fonction dans le module, et la séquence pour représenter l’entité. Grâce à cette approche, vous pouvez travailler dans plusieurs modules en parallèle, mais vous pouvez continuer à travailler dans l’ordre du module. Pour vous assurer que les opérations parallèles sont réussies, vous devez examiner toutes les dépendances.
- Si plusieurs tâches de données sont utilisées (par exemple, une tâche pour chaque module), vous pouvez utiliser le séquençage pour affecter le niveau et la séquence des entités à des fins d’exécution optimale.
- S’il n’existe aucune dépendance du tout, vous pouvez séquencer les entités aux différentes unités d’exécution pour une optimisation maximale.
Le menu Reséquençage est disponible si plusieurs entités sont sélectionnées. Vous pouvez effectuer un reséquençage en fonction des options d’unité, de niveau ou de séquence d’exécution. Vous pouvez définir un incrément pour reséquencer les entités sélectionnées. L’unité, le niveau et/ou le numéro de séquence qui est sélectionné pour chaque entité est mis à jour par l’incrément spécifié.
Tri
Vous pouvez utiliser l’option Trier par pour afficher la liste des entités dans l’ordre séquentiel.
Troncation
Pour les projets d’importation, vous pouvez choisir de tronquer des enregistrements dans les entités avant l’importation. Cette opération est utile si vos enregistrements doivent être importés dans un nouvel ensemble de tables. Ce paramètre est désactivé par défaut.
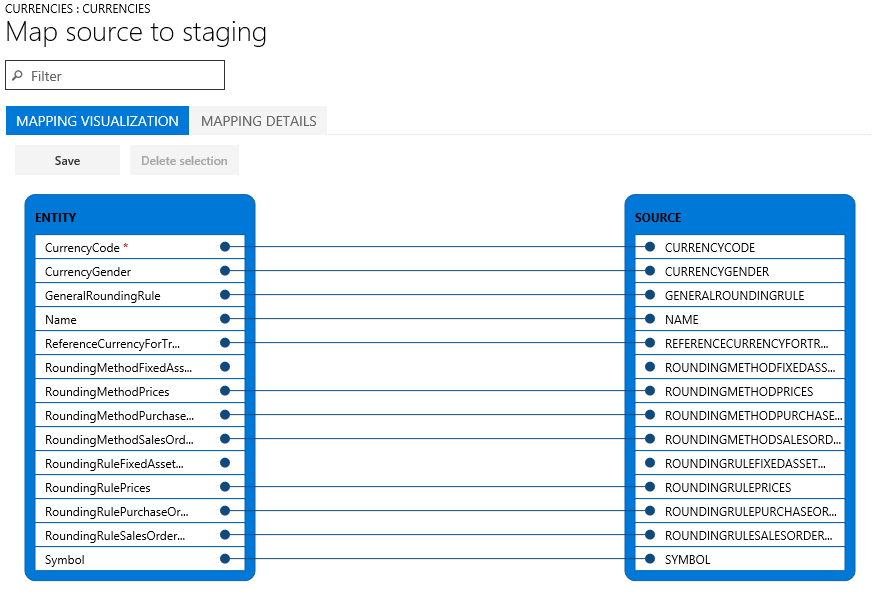
Vérifier que les données sources et cibles sont mises en correspondance correctement
La mise en correspondance est une fonction qui s’applique aux tâches d’importation et d’exportation.
- Dans le contexte d’une tâche d’importation, la mise en correspondance décrit quelles colonnes dans le fichier source deviennent les colonnes dans la table intermédiaire. Par conséquent, le système peut déterminer quelles données de colonne dans le fichier source doivent être copiées dans la colonne de la table intermédiaire.
- Dans le contexte d’une tâche d’exportation, la mise en correspondance décrit quelles colonnes de la table intermédiaire (autrement dit, la table source) deviennent les colonnes dans le fichier cible.
Si les noms de colonne dans la table intermédiaire et le fichier correspondent, le système crée automatiquement la mise en correspondance en fonction des noms. Toutefois, si les noms sont différents, les colonnes ne sont pas mises en correspondance automatiquement. Dans ces cas, vous devez effectuer la mise en correspondance en sélectionnant l’option Afficher le mappage sur l’entité dans la tâche de données.
Il existe deux vues de mappage : Visualisation de la mise en correspondance, qui est la vue par défaut, et Détails de la mise en correspondance. Un astérisque rouge (*) identifie les champs obligatoires dans l’entité. Ces champs doivent être mis en correspondance avant de pouvoir utiliser l’entité. Si nécessaire, vous pouvez supprimer la mise en correspondance d’autres champs quand vous utilisez l’entité. Pour supprimer la mise en correspondance d’un champ, sélectionnez le champ dans la colonne Entité ou la colonne Source, puis sélectionnez Supprimer la sélection. Sélectionnez Enregistrer pour enregistrer vos modifications, puis fermez la page pour revenir au projet. Vous pouvez utiliser le même processus pour modifier la mise en correspondance de la table source avec la table intermédiaire après votre importation.
Vous pouvez générer une mise en correspondance sur la page en sélectionnant Générer la mise en correspondance de la source. Une mise en correspondance générée se comporte comme une mise en correspondance automatique. Par conséquent, vous devez mettre en correspondance manuellement tous les champs non mis en correspondance.
Vérifier la sécurité de votre tâche d’importation ou d’exportation
L’accès à l’espace de travail Gestion des données peut être limité, afin que les utilisateurs non-administrateurs puissent accéder uniquement à des tâches de données spécifiques. L’accès à une tâche de données implique un accès complet à l’historique d’exécution de cette tâche et l’accès aux tables intermédiaires. Par conséquent, vous devez vous assurer que les contrôles d’accès appropriés sont en place quand vous créez une tâche de données.
Sécuriser une tâche en fonction des rôles et des utilisateurs
Utilisez le menu Rôles applicables pour restreindre la tâche à un ou plusieurs rôles de sécurité. Seuls les utilisateurs disposant de ces rôles ont accès à la tâche.
Vous pouvez également limiter une tâche à des utilisateurs spécifiques. Quand vous sécurisez une tâche en fonction des utilisateurs et non des rôles, cela offre plus de contrôle si plusieurs utilisateurs sont affectés à un rôle.
Sécuriser une tâche par une entité juridique
Les tâches de données sont globales en nature. Par conséquent, si une tâche de données a été créée et utilisée dans une entité juridique, la tâche est visible dans les autres entités juridiques du système. Ce comportement par défaut peut être préféré dans certains scénarios d’application. Par exemple, une organisation qui permet d’importer des factures à l’aide d’entités de données peut fournir une équipe chargée du traitement centralisé des factures pour la gestion des erreurs de toutes les divisions de l’organisation. Dans ce cas, il est utile que l’équipe de traitement centralisé des factures ait accès aux tâches d’importation de factures de toutes les entités juridiques. Par conséquent, le comportement par défaut correspond aux exigences d’une perspective d’entité juridique.
Cependant, une organisation peut vouloir avoir des équipes de traitement des factures par entité légale. Dans ce cas, une équipe au sein d’une entité juridique doit avoir accès uniquement à la tâche d’importation de facture dans sa propre entité juridique. Pour répondre à cette exigence, vous pouvez configurer le contrôle d’accès basé sur l’entité juridique pour les tâches de données à l’aide du menu Entités juridiques applicables dans la tâche de données. Une fois la configuration effectuée, les utilisateurs peuvent afficher uniquement les tâches qui sont disponibles dans l’entité juridique à laquelle ils sont connectés. Pour afficher les tâches d’une autre entité juridique, les utilisateurs doivent afficher cette entité juridique.
Une tâche peut être sécurisée par des rôles, des utilisateurs et une entité juridique en même temps.
Exécuter la tâche d’importation ou d’exportation
Vous pouvez exécuter une tâche ponctuelle en sélectionnant le bouton Importer ou Exporter après avoir défini la tâche. Pour paramétrer une tâche régulière, sélectionnez Créer une tâche de données répétitive.
Note
Une tâche d’importation ou d’exportation peut être exécutée en sélectionnant le bouton Importer ou Exporter. Cette action planifie l’exécution d’une tâche par lots une seule fois. Le travail peut ne pas s’exécuter immédiatement si le service de traitement par lots est limité en raison de la charge sur le service de traitement par lots. Les tâches peuvent être exécutées également de manière synchrone en sélectionnant Importer maintenant ou Exporter maintenant. Cela lance la tâche immédiatement et est utile si le traitement par lots ne se lance pas en raison d’un étranglement. Les tâches peuvent également être planifiées pour s’exécuter ultérieurement. Cela peut être fait en choisissant l’option Exécuter par lots. Les ressources par lots sont sujettes à l’étranglement, aussi le traitement par lots pourrait ne pas se lancer immédiatement. L’utilisation d’un lot est l’option recommandée, car elle aide également avec de grands volumes de données qui doivent être importés ou exportés. Les traitements par lots peuvent être prévus pour une exécution sur un groupe de lots spécifique, ce qui permet un plus grand contrôle depuis une perspective d’équilibrage de charge.
Vérifier que la tâche a été exécutée comme prévu
L’historique des tâches est disponible pour dépanner et rechercher des tâches d’importation et d’exportation. Les exécutions d’historique des tâches sont planifiées par périodes.
Chaque exécution de tâche fournit les informations suivantes :
- Détails de l’exécution
- Journal des exécutions
Les détails de l’exécution indiquent l’état de chaque entité de données que la tâche a traitée. Par conséquent, vous pouvez rapidement rechercher les informations suivantes :
- Les entités qui ont été traitées.
- Pour une entité, le nombre d’enregistrements ayant été correctement traités et le nombre ayant échoué.
- Les enregistrements intermédiaires pour chaque entité.
Vous pouvez télécharger les données intermédiaires dans un fichier pour les tâches d’exportation, ou vous pouvez les télécharger sous la forme d’un module pour les tâches d’importation et d’exportation.
Les détails d’exécution vous permettent également d’ouvrir le journal d’exécution.
Importations parallèles
Pour accélérer l’importation de données, le traitement parallèle de l’importation d’un fichier peut être activé si l’entité prend en charge les importations parallèles. Pour configurer l’importation parallèle pour une entité, les étapes suivantes doivent être suivies.
Allez dans Administration système > Espaces de travail > Gestion des données.
Dans la section Importer/Exporter, sélectionnez la vignette Paramètres du cadre pour ouvrir la page Paramètres du cadre d’importation/exportation de données.
Sur l’onglet Paramètres d’entité, sélectionnez Configurer les paramètres d’exécution d’entité pour ouvrir la page Paramètres d’exécution d’importation d’entité.
Définissez les champs suivants pour configurer l’importation parallèle pour une entité :
- Sélectionnez l’entité dans le champ Entité. Si le champ d’entité est vide, il est utilisé comme paramètre par défaut pour toutes les importations ultérieures, si l’entité prend en charge l’importation parallèle.
- Dans le champ Importer le nombre d’enregistrements de seuil, entrez le nombre d’enregistrement de seuil pour l’importation. Cela détermine le nombre d’enregistrements à traiter par un thread. Si un fichier contient 10 000 enregistrements, un nombre de 2 500 enregistrements avec un nombre de 4 tâches signifie que chaque thread va traiter 2 500 enregistrements.
- Dans le champ Importer le nombre de tâches, entrez le nombre de tâches d’importation. Ce nombre ne doit pas dépasser le nombre maximal de threads de lots alloués pour le traitement par lots dans Administration du système > Configuration du serveur.
Remarque
L’ajout de trop de tâches parallèles oblige l’infrastructure sous-jacente à utiliser la capacité des ressources à 100 %, ce qui a un impact sur les performances de l’environnement et d’autres opérations. Il est suggéré de comprendre la capacité des ressources de l’environnement et de la consommation en fonction des tâches d’importation parallèle configurées et de limiter le nombre de tâches.
Nettoyage de l’historique des tâches
Par défaut, les entrées de l’historique des tâches et les données de table intermédiaire associées datant de plus de 90 jours sont automatiquement supprimées. La fonctionnalité de nettoyage de l’historique des tâches dans la gestion des données peut être utilisée pour configurer un nettoyage périodique de l’historique d’exécution avec une période de conservation inférieure à cette valeur par défaut. Cette fonctionnalité remplace la fonctionnalité précédente de nettoyage de table intermédiaire, qui est désormais supprimée. Les tables suivantes sont nettoyées par le processus de nettoyage.
Toutes les tables intermédiaires
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
La fonctionnalité Nettoyage de l’historique des exécutions est accessible à partir de Gestion des données > Nettoyage de l’historique des tâches.
Paramètres de planification
Lorsque vous planifiez le processus de nettoyage, les paramètres suivants doivent être spécifiés pour définir les critères de nettoyage.
Nombre de jours pour conserver l’historique – Ce paramètre permet de contrôler la quantité d’historique d’exécution à préserver. Il s’agit d’un nombre de jours spécifié. Quand la tâche de nettoyage est planifiée en tant que traitement par lots récurrent, ce paramètre agit comme une fenêtre continuellement en mouvement, laissant ainsi l’historique intact pour le nombre de jours spécifié, tout en supprimant le reste. La valeur par défaut est de sept jours.
Nombre d’heures pour exécuter la tâche : Selon la quantité d’historique à nettoyer, le temps total d’exécution de la tâche de nettoyage peut varier de quelques minutes à quelques heures. Ce paramètre doit être défini sur le nombre d’heures d’exécution de la tâche. Une fois la tâche de nettoyage exécutée pour le nombre d’heures spécifié, elle se ferme et reprend le nettoyage lors de sa prochaine exécution en fonction de la périodicité.
Vous pouvez spécifier une durée d’exécution maximale en définissant une limite maximale sur le nombre d’heures d’exécution du travail à l’aide de ce paramètre. La logique de nettoyage passe en revue un ID d’exécution de travail à la fois, dans une séquence classée dans l’ordre chronologique, le plus ancien étant le premier pour le nettoyage de l’historique d’exécution associé. Elle arrête de sélectionner les nouveaux ID d’exécution à nettoyer quand la durée restante d’exécution sera comprise dans les 10 % restants de la durée spécifiée. Dans certains cas, il faut s’attendre à ce que la tâche de nettoyage se poursuive au-delà de la durée maximale spécifiée. Cela dépend en grande partie du nombre d’enregistrements à supprimer pour l’ID d’exécution en cours qui a été démarré avant que le seuil de 10 % ne soit atteint. Le nettoyage qui a été lancé doit être terminé pour garantir l’intégrité des données, ce qui signifie que le nettoyage se poursuit malgré le dépassement de la limite spécifiée. Une fois cette opération terminée, les nouveaux ID ne sont pas récupérés et le travail de nettoyage est terminé. L’historique d’exécution restant, qui n’a pas été nettoyé faute de temps d’exécution suffisant, sera récupéré lors de la prochaine planification du travail de nettoyage. La valeur par défaut et la valeur minimale pour ce paramètre est définie sur 2 heures.
Traitement par lots récurrent : La tâche de nettoyage peut être exécutée en tant qu’exécution manuelle unique ou peut également être planifiée pour une exécution récurrente par lot. Le traitement par lots peut être planifié à l’aide des paramètres Exécuter à l’arrière-plan, qui est le paramétrage de traitement par lots standard.
Remarque
Si la fonctionnalité de nettoyage de l’historique des tâches n’est pas utilisée, l’historique d’exécution datant de plus de 90 jours est quand même automatiquement supprimé. Le nettoyage de l’historique des tâches peut être exécuté en plus de cette suppression automatique. Assurez-vous que la tâche de nettoyage est planifiée pour s’exécuter de manière récurrente. Comme expliqué ci-dessus, au moment de l’exécution du nettoyage, la tâche va nettoyer autant d’ID d’exécution que possible dans le nombre maximal d’heures indiqué.
Nettoyage et archivage de l’historique des tâches
La fonctionnalité de nettoyage et d’archivage de l’historique des tâches remplace les versions précédentes de la fonctionnalité de nettoyage. Cette section explique ces nouvelles fonctionnalités.
L’un des principaux changements apportés à la fonctionnalité de nettoyage est l’utilisation du traitement par lots du système pour nettoyer l’historique. L’utilisation du traitement par lots système permet aux applications de finances et d’opérations d’obtenir que le traitement par lots de nettoyage soit automatiquement planifié et exécuté dès que le système est prêt. Il n’est plus nécessaire de planifier manuellement le traitement par lots. Dans ce mode d’exécution par défaut, le traitement par lots s’exécutera toutes les heures à partir de minuit et conservera l’historique d’exécution des sept jours les plus récents. L’historique purgé est archivé pour une récupération ultérieure. À partir de la version 10.0.20, cette fonctionnalité est toujours activée.
Le deuxième changement dans le processus de nettoyage est l’archivage de l’historique d’exécution purgé. La tâche de nettoyage archive les enregistrements supprimés dans le stockage d’objets blob que DIXF utilise pour les intégrations régulières. Le fichier archivé sera au format de package DIXF et sera disponible pendant sept jours dans le blob pendant lequel il pourra être téléchargé. La longévité par défaut de sept jours pour le fichier archivé peut être modifiée à un maximum de 90 jours dans les paramètres.
Modification des paramètres par défaut
Cette fonctionnalité est actuellement en version préliminaire et doit être explicitement activée en activant le déploiement en mode Flighting DMFEnableExecutionHistoryCleanupSystemJob. La fonction de nettoyage intermédiaire doit également être activée dans la gestion des fonctionnalités.
Pour modifier le paramètre par défaut de longévité du fichier archivé, accédez à l’espace de travail de gestion des données et sélectionnez Nettoyage de l’historique des tâches. Définissez Jours de conservation du package dans le blob sur une valeur comprise entre 7 et 90 (inclus). Cela prend effet sur les archives créées après cette modification.
Téléchargement du package archivé
Cette fonctionnalité est actuellement en version préliminaire et doit être explicitement activée en activant le déploiement en mode Flighting DMFEnableExecutionHistoryCleanupSystemJob. La fonction de nettoyage intermédiaire doit également être activée dans la gestion des fonctionnalités.
Pour télécharger l’historique d’exécution archivé, accédez à l’espace de travail de gestion des données et sélectionnez Nettoyage de l’historique des tâches. Sélectionnez Historique de sauvegarde des packages pour ouvrir le formulaire d’historique. Ce formulaire affiche la liste de tous les packages archivés. Une archive peut être sélectionnée et téléchargée en sélectionnant Télécharger le package. Le package téléchargé est au format de package DIXF et contient les fichiers suivants :
- Fichier de la table de mise en lots des entités
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Tri des données d’entité composite à l’aide de XSLT
Cette fonctionnalité vous permet d’exporter une entité composite et d’appliquer un fichier xslt pour trier les données dans ce fichier.
Pour trier les données d’entité composite à l’aide de xslt, suivez ces étapes.
- Créez un fichier xslt pour trier les données au format XML. Par exemple, si vous disposez d’un fichier XSLT pour l’entité prête à l’emploi Commandes fournisseur composite V3, vous pouvez trier les données au format d’attribut XML dans l’ordre par INVOICEVENDORACCOUNTNUMBER pour PURCHPURCHASEORDERHEADERV2ENTITY et trier par LINENUMBER pour PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Accédez à l’espace de travail Gestion des données.
- Dans la liste des projets d’exportation de données, sélectionnez un projet avec une source de données XML, puis sélectionnez Afficher le mappage.
- Sélectionnez Afficher le mappage pour toute entité.
- Accédez à l’onglet Transformations
- Sélectionnez Nouveau et chargez le fichier xslt créé à l’étape 1.