Utiliser l’API Livy pour envoyer et exécuter des travaux par lots Livy
Remarque
L’API Livy pour Engineering données Fabric est en préversion.
S’applique à :✅ l’engineering et la science des données dans Microsoft Fabric
Envoyez des travaux par lots Spark à l’aide de l’API Livy pour Engineering données Fabric.
Prérequis
Capacité Fabric Premium ou d’évaluation avec un lakehouse.
Activez le paramètre administrateur du locataire pour l’API Livy (préversion).
Un client distant tel que Visual Studio Code avec Jupyter Notebooks, PySpark et la bibliothèque d’authentification Microsoft (MSAL) pour Python.
Un jeton d’application Microsoft Entra est nécessaire pour accéder à l’API REST Fabric. Inscrire une application à l’aide de la plateforme d’identités Microsoft.
Certaines données dans votre lakehouse. Cet exemple utilise le fichier Parquet NYC Taxi & Limousine Commission green_tripdata_2022_08 chargé dans le lakehouse.
L’API Livy définit un point de terminaison unifié pour les opérations. Remplacez les espaces réservés {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} et {Fabric_LakehouseID} par vos valeurs appropriées lorsque vous suivez les exemples de cet article.
Configurer Visual Studio Code pour votre lot d’API Livy
Sélectionnez Paramètres Lakehouse dans votre lakehouse Fabric.

Accédez à la section Point de terminaison Livy.

Copiez la chaîne de connexion du travail par lots (deuxième zone rouge dans l’image) dans votre code.
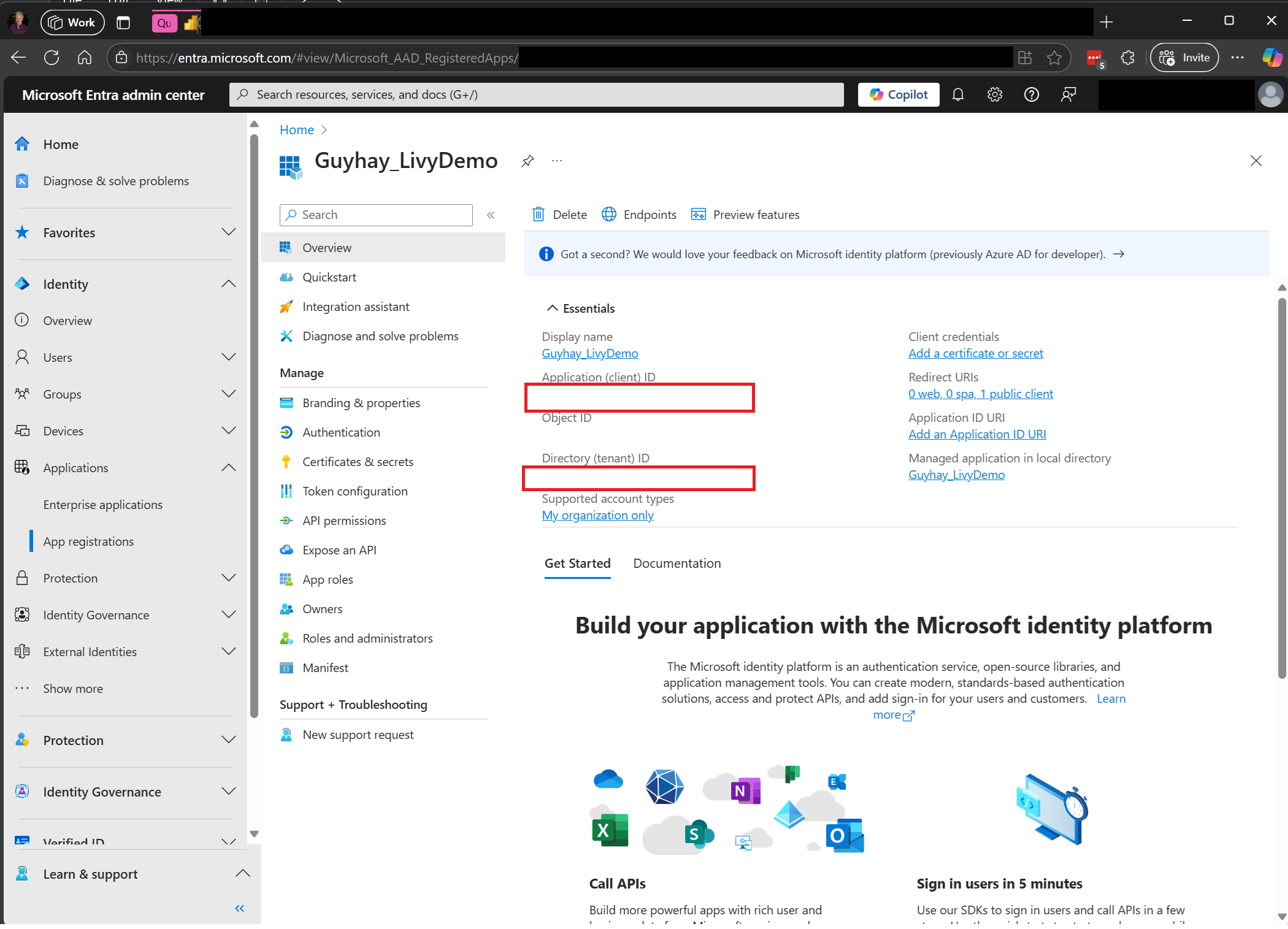
Accédez au centre d’administration Microsoft Entra et copiez l’ID d’application (client) et l’ID d’annuaire (locataire) dans votre code.



Créer une charge utile Spark à charger dans votre Lakehouse
Créez un notebook
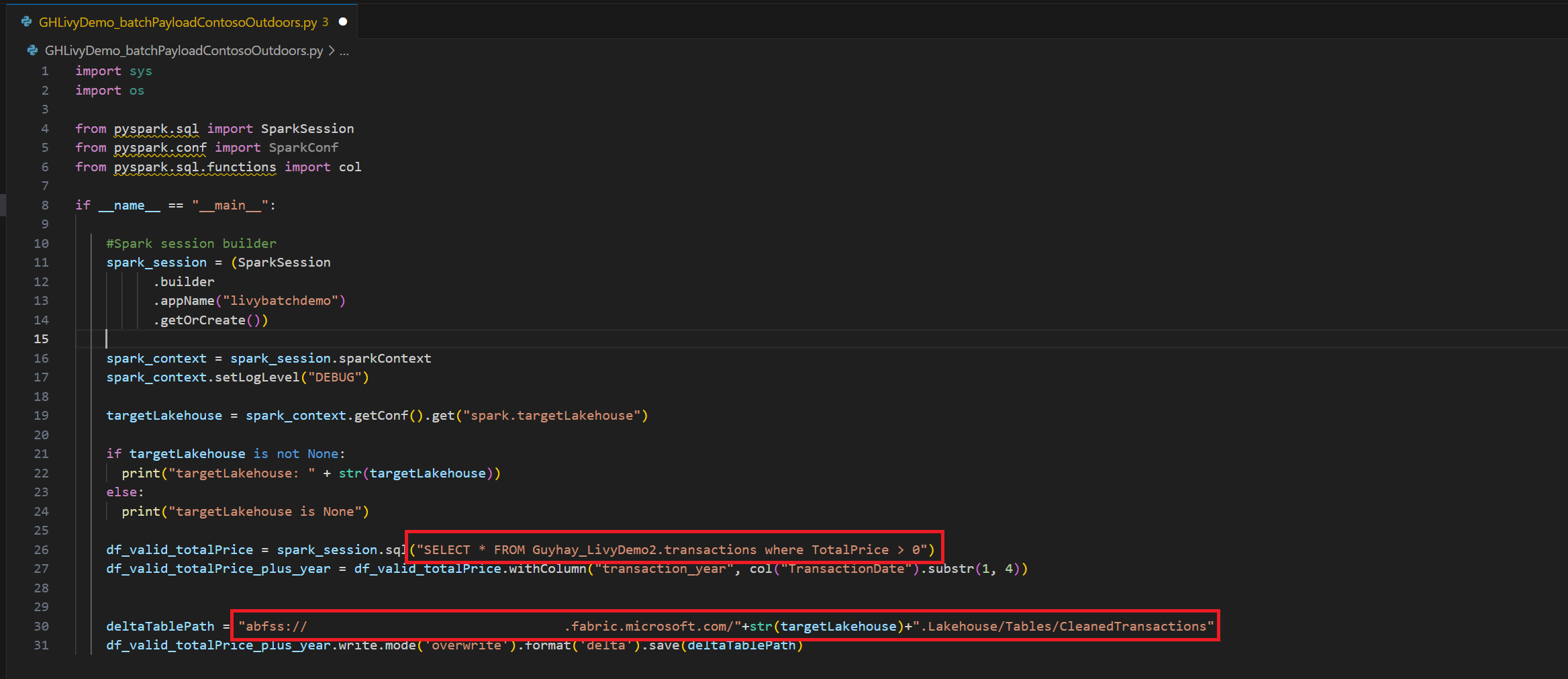
.ipynbdans Visual Studio Code et insérez le code suivant.import sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM Guyhay_LivyDemo2.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Enregistrez le fichier Python localement. Cette charge utile de code Python contient deux instructions Spark qui fonctionnent sur des données dans un Lakehouse et qui doivent être chargées dans votre Lakehouse. Vous aurez besoin du chemin ABFS de la charge utile pour référencer votre travail par lots d’API Livy dans Visual Studio Code.
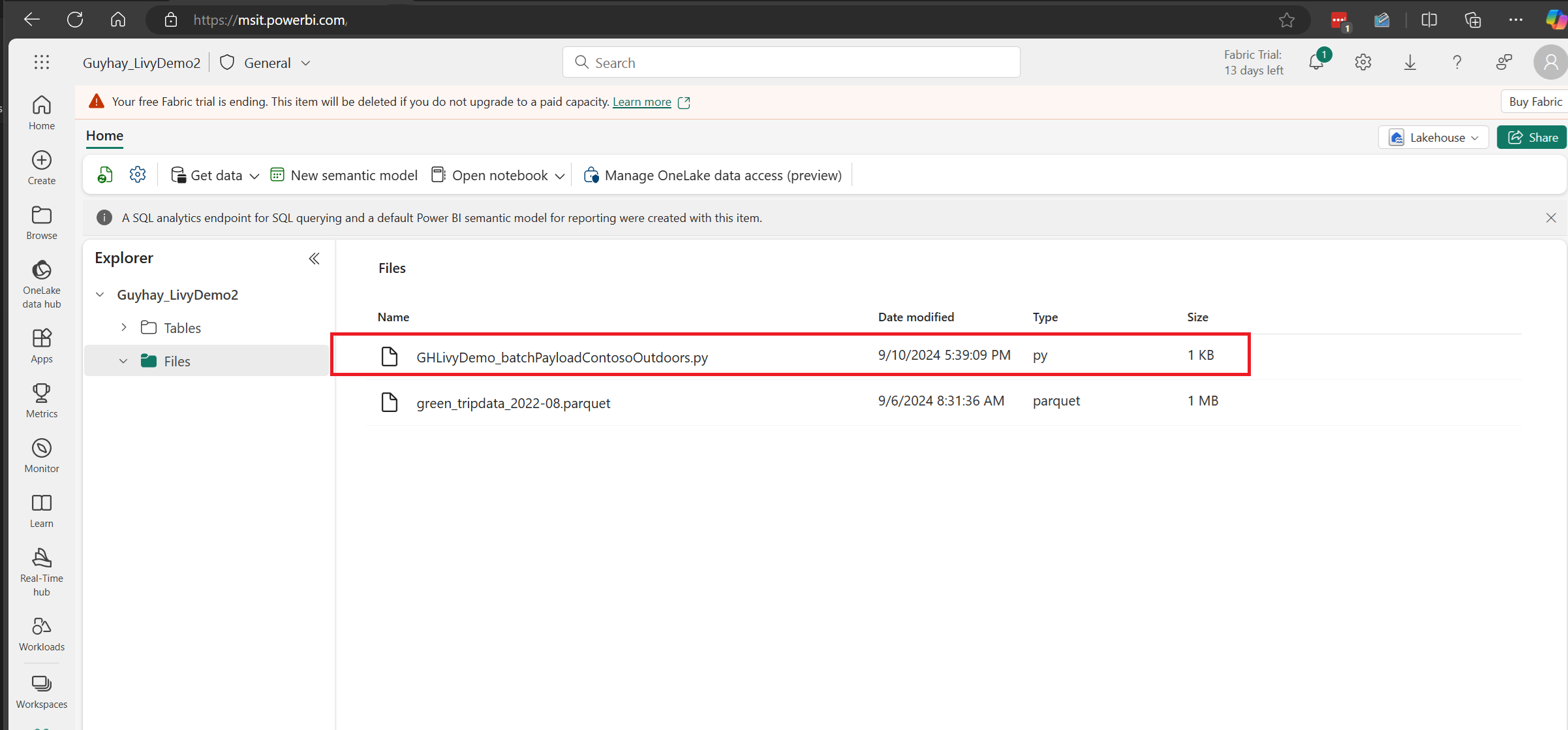
Chargez la charge utile Python dans la section des fichiers de votre Lakehouse. > Obtenir des données > Charger des fichiers > et cliquez dans la zone d’entrée Fichiers.
Une fois que le fichier est dans la section Fichiers de votre Lakehouse, cliquez sur les trois petits points à droite du nom de fichier de votre charge utile, puis sélectionnez Propriétés.
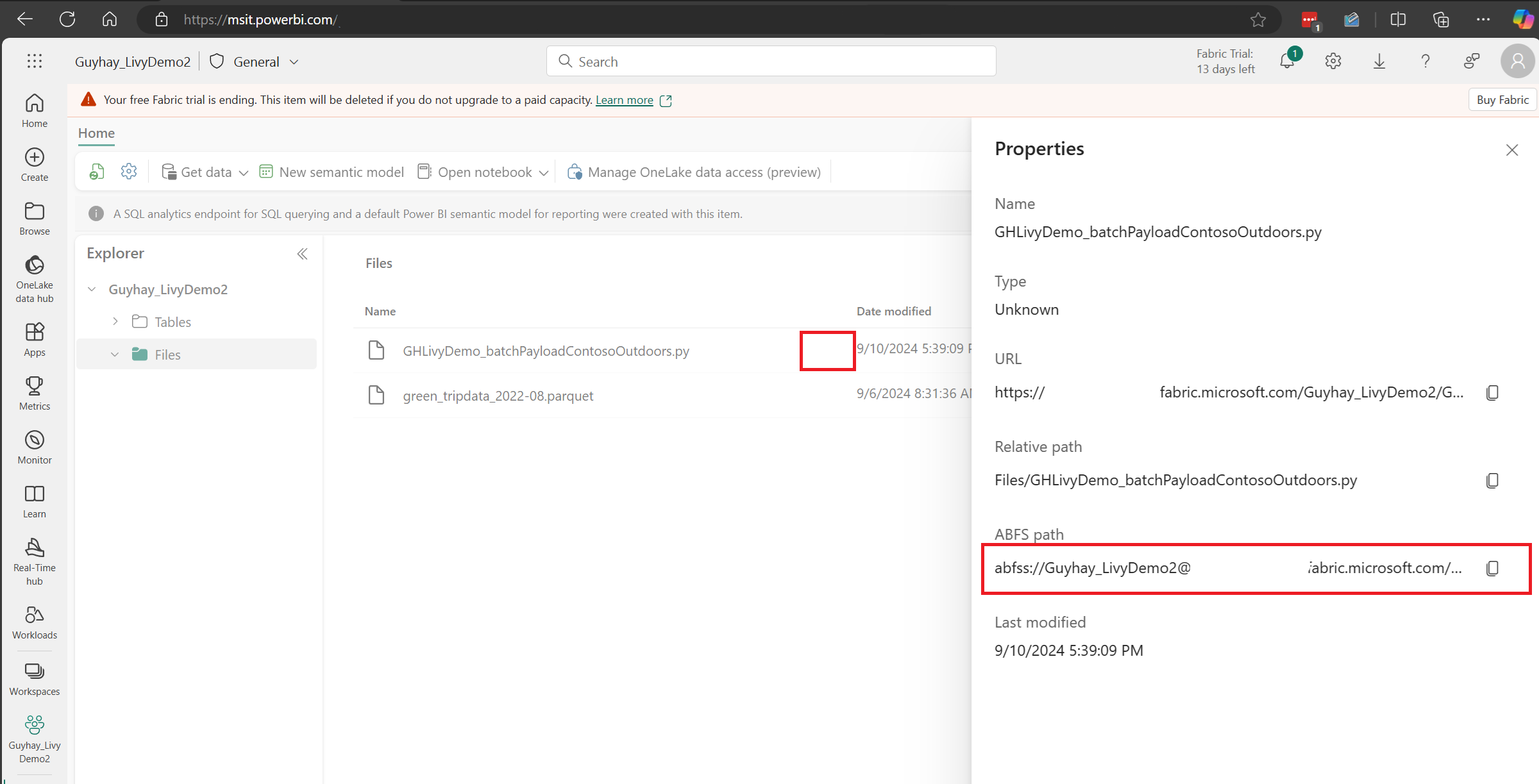
Copiez ce chemin ABFS dans votre cellule Notebook à l’étape 1.



Créer une session par lots Spark d’API Livy
Créez un notebook
.ipynbdans Visual Studio Code et insérez le code suivant.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Exécutez la cellule de notebook. Une fenêtre contextuelle devrait apparaître dans votre navigateur pour vous permettre de choisir l’identité avec laquelle vous connecter.

Une fois que vous avez choisi l’identité à utiliser pour vous connecter, vous êtes également invité à approuver les autorisations de l’API d’inscription d’application Microsoft Entra.

Fermez la fenêtre du navigateur après avoir procédé à l’authentification.

Dans Visual Studio Code, vous devriez voir le jeton Microsoft Entra retourné.
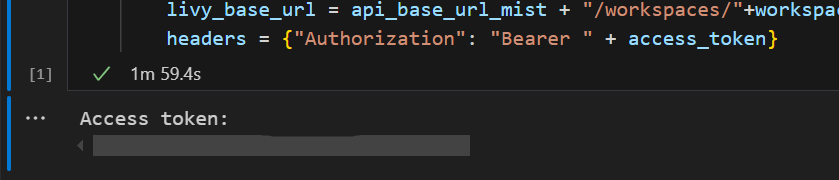
Ajoutez une autre cellule de notebook et insérez ce code.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Exécutez la cellule de notebook. Vous devriez voir deux lignes qui s’affichent lors de la création du travail par lots Livy.






Envoyer une instruction spark.sql à l’aide de la session par lots de l’API Livy
Ajoutez une autre cellule de notebook et insérez ce code.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Exécutez la cellule de notebook. Vous devriez voir plusieurs lignes qui s’affichent lors de la création et de l’exécution du travail par lots Livy.

Revenez à votre Lakehouse pour voir les changements.

Afficher vos travaux dans le hub de supervision
Vous pouvez accéder au hub de supervision pour afficher diverses activités Apache Spark en sélectionnant Superviser dans les liens de navigation de gauche.
Lorsque le travail par lots est à l’état terminé, vous pouvez voir l’état de la session en accédant à Superviser.
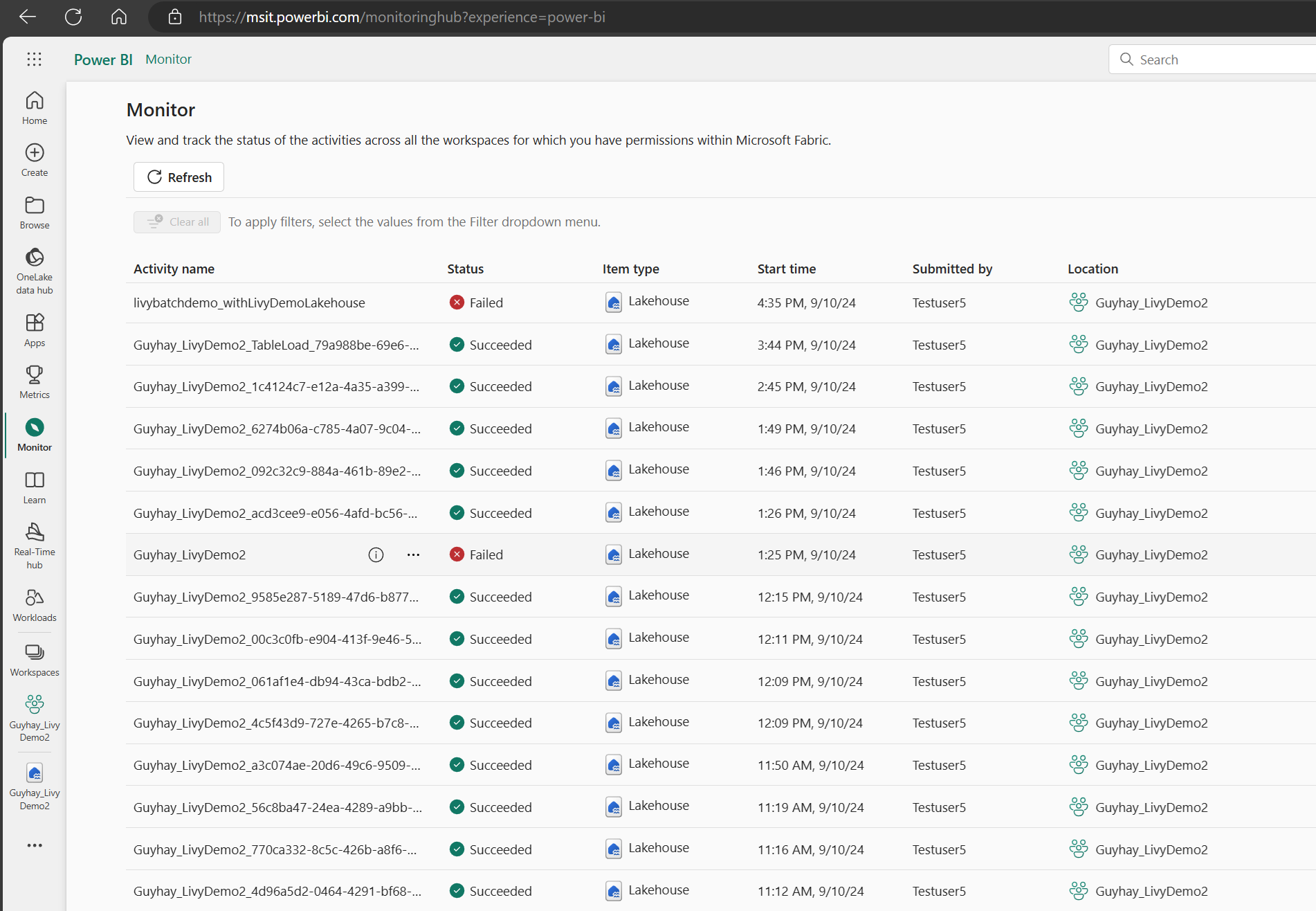
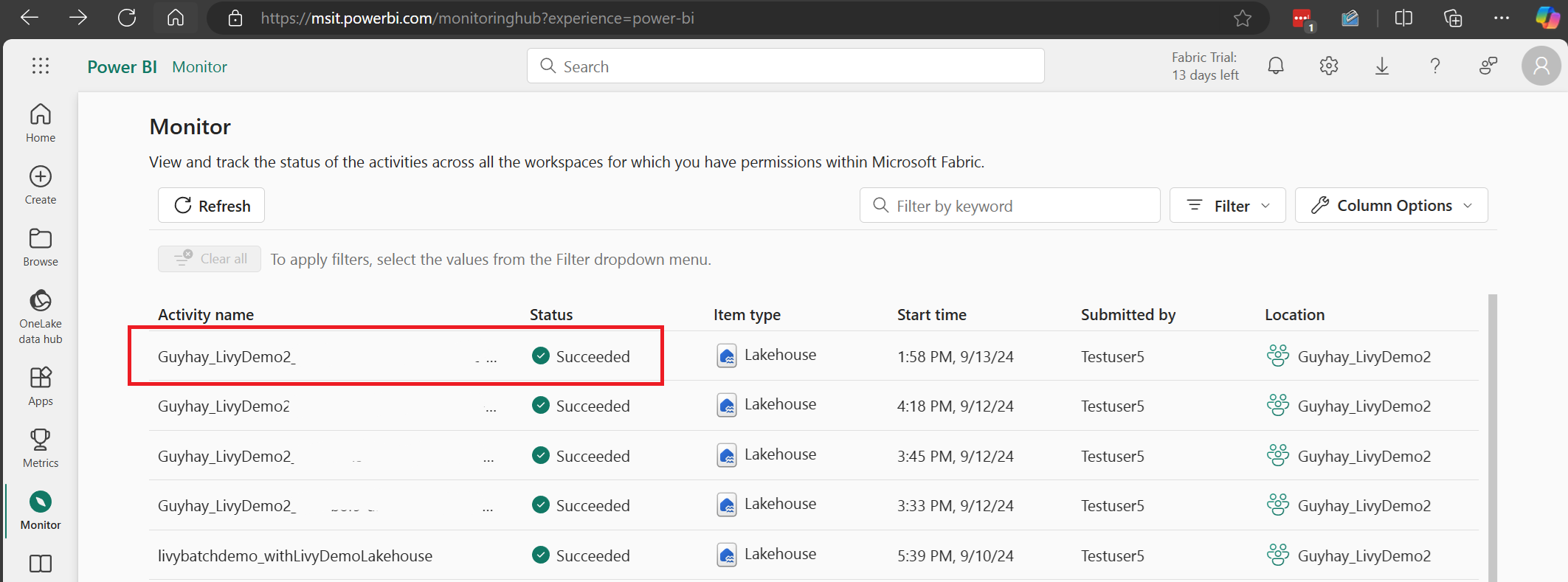
Sélectionnez et ouvrez le nom de l’activité la plus récente.
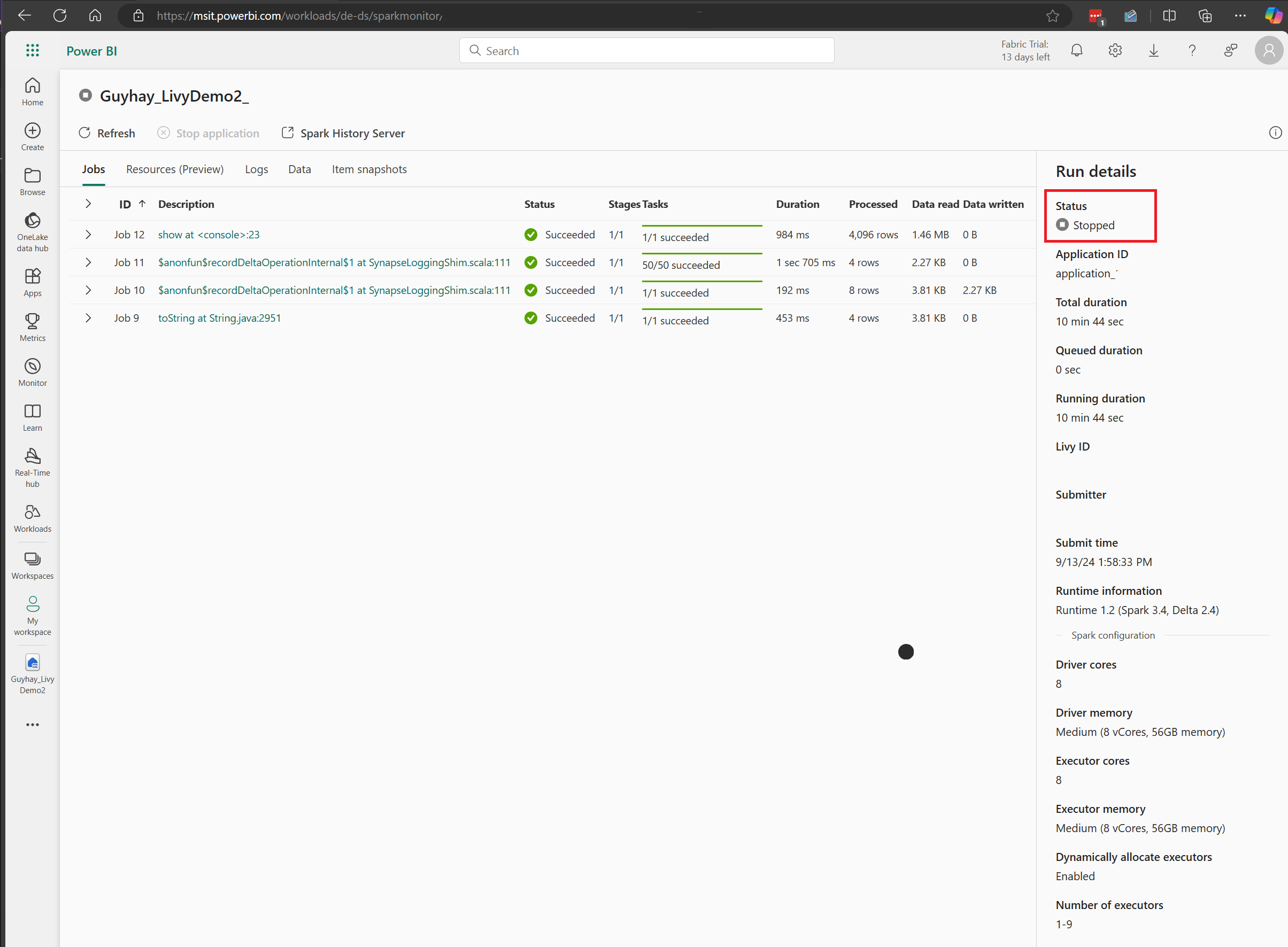
Dans ce cas de session d’API Livy, vous pouvez voir votre envoi de lot précédent, les détails d’exécution, les versions Spark et la configuration. Notez l’état Arrêté en haut à droite.
Pour récapituler l’ensemble du processus, vous avez besoin d’un client à distance tel que Visual Studio Code, d’un jeton d’application Microsoft Entra, de l’URL du point de terminaison de l’API Livy, de l’authentification auprès de votre Lakehouse, d’une charge de travail Spark dans votre Lakehouse et enfin d’une session d’API Livy par lots.