Développer, évaluer et noter un modèle de prévision des ventes pour les grandes surfaces
Ce tutoriel présente un exemple de bout en bout d'un flux de travail science des données Synapse dans Microsoft Fabric. Le scénario construit un modèle de prévision qui utilise les données historiques des ventes pour prédire les ventes d'une catégorie de produits dans une grande surface.
La prévision est un actif crucial dans les ventes. Il combine des données historiques et des méthodes prédictives pour fournir des insights sur les tendances futures. Les prévisions permettent d'analyser les ventes passées afin d'identifier des tendances et de tirer des enseignements du comportement des consommateurs pour optimiser les stratégies de stock, de production et de marketing. Cette approche proactive améliore l’adaptabilité, la réactivité et les performances globales des entreprises dans un marché dynamique.
Ce didacticiel couvre ces étapes :
- Chargement des données
- Utiliser l'analyse de données exploratoire pour comprendre et traiter les données
- Entraînez un modèle Machine Learning avec un package logiciel Open Source, et suivez les expériences avec MLflow et la fonction d'autologisation Fabric
- Enregistrez le modèle Machine Learning final et effectuez des prédictions
- Afficher la performance du modèle avec des visualisations Power BI
Prérequis
Obtenir un abonnement Microsoft Fabric. Ou, inscrivez-vous pour un essai gratuit de Microsoft Fabric.
Connectez-vous à Microsoft Fabric.
Utilisez le sélecteur d'expérience sur le côté gauche de votre page d'accueil pour passer à l'expérience science des données Synapse.

- Si nécessaire, créez un lakehouse Microsoft Fabric comme décrit dans Créer une lakehouse dans Microsoft Fabric.
Suivez l'évolution dans un notebook
Vous pouvez choisir l'une de ces options pour suivre l'évolution de la situation dans un notebook :
- Ouvrez et exécutez le notebook intégré dans l'expérience science des données Synapse
- Chargez votre notebook à partir de GitHub vers l’expérience science des données Synapse
Ouvrir le notebook intégré
L'exemple de notebook sur les prévisions des ventes accompagne ce tutoriel.
Pour ouvrir l’exemple de notebook intégré au tutoriel dans l’expérience science des données Synapse :
Accédez à la page d'accueil science des données Synapse.
Sélectionnez Utiliser un échantillon.
Sélectionnez l’échantillon correspondant :
- À partir de l’onglet par défaut Workflows de bout en bout (Python), si l’exemple concerne un tutoriel Python.
- À partir de l’onglet Workflows de bout en bout (R), si l’exemple concerne un tutoriel R.
- À partir de l’onglet Tutoriels rapides, si l’exemple concerne un tutoriel rapide.
Attachez un lakehouse au notebook avant de commencer à exécuter le code.
Importer le notebook à partir de GitHub
Le notebook AIsample - Superstore Forecast.ipynb accompagne ce tutoriel.
Pour ouvrir le notebook d'accompagnement de ce tutoriel, suivez les instructions fournies dans Préparer votre système pour la science des données afin d'importer le notebook dans votre espace de travail.
Si vous préférez copier et coller le code de cette page, vous pouvez créer un nouveau notebook.
Assurez-vous d'attacher un lakehouse au notebook avant de commencer à exécuter du code.
Étape 1 : Chargement des données
Le jeu de données contient 9 995 instances de ventes de différents produits. Il inclut également 21 attributs. Cette table est tirée du fichier Superstore.xlsx utilisé dans ce notebook :
| ID de ligne | Référence de commande | Date commande | Ship Date | Mode d’expédition | ID client | Nom du client | Segment | Pays ou région | Ville | Région | Code postal | Région | ID de produit | Catégorie | Sous-catégorie | Nom du produit | Vente | Quantité | Remise | Bénéfices |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Classe standard | SO-20335 | Sean O’Donnell | Consommateur | États-Unis | Fort Lauderdale | Floride | 33311 | Sud | FUR-TA-10000577 | Meubles | Tables | Table rectangulaire étroite série Bretford CR4500 | 957.5775 | 5 | 0,45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Classe standard | Classe standard | Brosina Hoffman | Consommateur | États-Unis | Los Angeles | Californie | 90032 | West | FUR-TA-10001539 | Meubles | Tables | Tables de conférence rectangulaires Chromcraft | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Classe standard | TB-21520 | Tracy Blumstein | Consommateur | États-Unis | Philadelphie | Pennsylvanie | 19140 | Est | OFF-EN-10001509 | Fournitures de bureau | Enveloppes | Enveloppes à ficelle en polyéthylène | 3.264 | 2 | 0.2 | 1.1016 |
Définissez ces paramètres pour pouvoir utiliser ce notebook avec différents jeux de données :
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Télécharger le jeu de données et le charger dans le lakehouse
Ce code télécharge une version du jeu de données disponible au public, puis la stocke dans un lakehouse Fabric :
Important
Assurez-vous d’ajouter un lakehouse au notebook avant de l’exécuter. Sinon, une erreur s’affiche.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Configurer le suivi des expériences MLflow
Microsoft Fabric capture automatiquement les valeurs des paramètres d'entrée et des métriques de sortie d'un modèle Machine Learning au fur et à mesure que vous l'entraînez. Cela étend les fonctionnalités de mise en place automatique de MLflow. Les informations sont ensuite enregistrées dans l'espace de travail, où vous pouvez y accéder et les visualiser à l'aide des API MLflow ou de l'expérience correspondante dans l'espace de travail. Pour en savoir plus sur l’autologging, consultez autologging dans Microsoft Fabric.
Pour désactiver l'autologging de Microsoft Fabric dans une session notebook, appelez mlflow.autolog() et définissez disable=True :
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Lire des données brutes à partir du lakehouse
Lisez les données brutes de la section Fichiers du lakehouse. Ajoutez des colonnes supplémentaires pour les différentes parties de la date. Les mêmes informations sont utilisées pour créer une table delta partitionnée. Étant donné que les données brutes sont stockées sous forme de fichier Excel, vous devez utiliser pandas pour les lire :
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Étape 2 : Effectuer une analyse exploratoire des données
Importer des bibliothèques
Avant toute analyse, importez les bibliothèques nécessaires :
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Afficher les données brutes
Passez en revue manuellement un sous-ensemble de données, afin de mieux comprendre le jeu de données lui-même, et utilisez la fonction display pour imprimer le DataFrame. En outre, les vues Chart permettent de visualiser facilement les sous-ensembles du jeu de données.
display(df)
Ce notebook se concentre principalement sur la prévision des ventes de la catégorie Furniture. Cela accélère le calcul et permet de montrer la performance du modèle. Toutefois, ce notebook utilise des techniques adaptables. Vous pouvez étendre ces techniques pour prédire les ventes d’autres catégories de produits.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Prétraiter les données
Dans le monde réel, les entreprises doivent souvent prévoir les ventes dans trois catégories distinctes :
- Une catégorie de produit spécifique
- Une catégorie de client spécifique
- Une combinaison spécifique de la catégorie de produits et de la catégorie de clients
Tout d’abord, supprimez les colonnes inutiles pour prétraiter les données. Certaines des colonnes (Row ID, Order ID,Customer ID, et Customer Name) ne sont pas nécessaires, car elles n’ont aucun impact. Nous voulons prévoir les ventes globales, dans l’état et la région, pour une catégorie de produit spécifique (Furniture), afin que nous puissions supprimer les colonnes State, Region, Country, City, et Postal Code. Pour prévoir les ventes pour un lieu ou une catégorie spécifique, vous devrez peut-être adapter l'étape de prétraitement en conséquence.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Le jeu de données est structuré quotidiennement. Nous devons rééchantillonner la colonne Order Date, car nous voulons développer un modèle pour prévoir les ventes sur une base mensuelle.
Tout d’abord, regroupez la catégorie Furniture par Order Date. Ensuite, calculez la somme de la colonne Sales pour chaque groupe, afin de déterminer les ventes totales pour chaque valeur Order Date unique. Rééchantillonner la colonne Sales avec la fréquence MS pour agréger les données par mois. Enfin, calculez la valeur moyenne des ventes pour chaque mois.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Démontrez l’impact de Order Date sur Sales pour la catégorie Furniture :
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Avant toute analyse statistique, vous devez importer le module Python statsmodels. Il fournit des classes et des fonctions pour l’estimation de nombreux modèles statistiques. Il fournit également des classes et des fonctions pour effectuer des tests statistiques et l’exploration des données statistiques.
import statsmodels.api as sm
Effectuer une analyse statistique
Une série chronologique suit ces éléments de données à des intervalles déterminés, afin de déterminer la variation de ces éléments dans le modèle de la série chronologique :
Niveau : la composante fondamentale représentant la valeur moyenne pour une période de temps spécifique
Tendance : décrit si la série chronologique diminue, est constante ou augmente au fil du temps
Saisonnalité : décrit le signal périodique dans la série chronologique et recherche les occurrences cycliques qui ont un impact sur les modèles croissants ou décroissants de la série chronologique
Bruit/résiduel : fait référence aux fluctuations aléatoires et à la variabilité des données de série chronologique que le modèle ne peut pas expliquer.
Dans ce code, vous observez ces éléments pour votre jeu de données après le prétraitement :
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Les graphiques décrivent la saisonnalité, les tendances et le bruit dans les données de prévision. Vous pouvez capturer les modèles sous-jacents et développer des modèles qui permettent de faire des prévisions précises et qui résistent aux fluctuations aléatoires.
Étape 3 : Effectuer l’apprentissage d’un modèle et le suivre
Maintenant que vous disposez des données disponibles, définissez le modèle de prévision. Dans ce notebook, appliquez le modèle de prévision des appelé moyenne mobile intégrée autorégressive saisonnière avec des facteurs exogènes (SARIMAX). SARIMAX combine les composantes autorégressives (AR) et de moyenne mobile (MA), la différenciation saisonnière et les prédicteurs externes pour établir des prévisions précises et flexibles pour les données de séries chronologique.
Vous utilisez également MLflow et Fabric autologging pour suivre les expériences. Ici, chargez la table delta à partir du lakehouse. Vous pourriez utiliser d'autres tables delta qui considèrent le lakehouse comme la source.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Optimiser les hyperparamètres
SARIMAX prend en compte les paramètres impliqués dans le mode régulier de la moyenne mobile intégrée autorégressive (ARIMA) (p, d, q), et ajoute les paramètres de saisonnalité (P, D, Q, s). Ces arguments du modèle SARIMAX sont appelés respectivement ordre (p, d, q) et ordre saisonnièr (P, D, Q, s). Par conséquent, pour former le modèle, nous devons d'abord régler sept paramètres.
Les paramètres d’ordre :
p: l'ordre de la composante AR, qui représente le nombre d'observations passées dans la série temporelle utilisée pour prédire la valeur actuelle.En règle générale, ce paramètre doit être un entier non négatif. Les valeurs courantes sont comprises entre
0et3, bien que des valeurs plus élevées soient possibles, en fonction des caractéristiques spécifiques des données. Une valeurpplus élevée indique une mémoire plus longue des valeurs passées dans le modèle.d: l’ordre de différenciation, qui représente le nombre de fois que la série temporelle doit être différenciée pour atteindre la stationnarité.Ce paramètre doit être un entier non négatif. Les valeurs courantes sont comprises entre
0et2. Une valeurdde0signifie que la série chronologique est déjà stationnaire. Des valeurs plus élevées indiquent le nombre d'opérations de différentiation nécessaires pour le rendre stationnaire.q: l'ordre de la composante MA, qui représente le nombre de termes d'erreur à bruit blanc passés utilisés pour prédire la valeur actuelle.Ce paramètre doit être un entier non négatif. Les valeurs courantes sont comprises entre
0et3, mais des valeurs plus élevées peuvent être nécessaires pour certaines série chronologique. Une valeurqplus élevée indique une plus forte dépendance vis-à-vis des termes d’erreur passés pour effectuer des prédictions.
Les paramètres d'ordre saisonnier :
P: l’ordre saisonnier de la composante AR, similaire àpmais pour la partie saisonnièreD: l'ordre saisonnier de différentiation, similaire àdmais pour la partie saisonnièreQ: l’ordre saisonnier de la composante MA, similaire àqmais pour la partie saisonnières: le nombre d’intervalles de temps par cycle saisonnier (par exemple, 12 pour les données mensuelles avec une saisonnalité annuelle)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX a d’autres paramètres :
enforce_stationarity: si le modèle doit ou non imposer la stationnarité aux données de la série chronologique, avant d'ajuster le modèle SARIMAX.Si
enforce_stationarityest défini surTrue(par défaut), cela indique que le modèle SARIMAX doit appliquer la stationnarité aux données de la série chronologique. Le modèle SARIMAX applique ensuite automatiquement une différenciation aux données, afin de les rendre stationnaires, comme spécifié par les ordresdetD, avant d'ajuster le modèle. Il s’agit d’une pratique courante, car de nombreux modèles de série chronologique, y compris SARIMAX, supposent que les données sont stationnaires.Pour une série chronologique non stationnaire (par exemple, elle présente des tendances ou une saisonnalité), il est conseillé de définir
enforce_stationarityàTrueet de laisser le modèle SARIMAX se charger de la différenciation pour atteindre la stationnarité. Pour une série chronologique stationnaire (par exemple, une série sans tendance ni saisonnalité), définirenforce_stationaritysurFalsepour éviter une différenciation inutile.enforce_invertibility: contrôle si le modèle doit ou non imposer l'inversibilité des paramètres estimés au cours du processus d'optimisation.Si
enforce_invertibilityest défini surTrue(par défaut), cela indique que le modèle SARIMAX doit imposer l'inversibilité des paramètres estimés. L'inversion garantit que le modèle est bien défini et que les coefficients AR et MA estimés se situent dans la plage de stationnarité.L'application de l'inversion permet de s'assurer que le modèle SARIMAX respecte les exigences théoriques d'un modèle de série chronologique stable. Il permet également d’éviter les problèmes liés à l’estimation et à la stabilité du modèle.
Le modèle par défaut est le modèle AR(1). Cela fait référence à (1, 0, 0). Toutefois, il est courant d'essayer différentes combinaisons de paramètres d'ordre et de paramètres d'ordre saisonnier, et d'évaluer les performances du modèle pour un jeu de données. Les valeurs appropriées peuvent varier d’une série chronologique à une autre.
La détermination des valeurs optimales implique souvent l’analyse de la fonction de correction automatique (ACF) et la fonction de correction automatique partielle (PACF) des données de série chronologique. Il implique également souvent l’utilisation de critères de sélection de modèle, par exemple, le critère d’information Akaike (AIC) ou le critère d’information bayésien (BIC).
Réglez les hyperparamètres :
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Après évaluation des résultats précédents, vous pouvez déterminer les valeurs des paramètres d’ordre et des paramètres d’ordre saisonniers. Le choix est order=(0, 1, 1) et seasonal_order=(0, 1, 1, 12), qui offre le niveau AIC le plus bas (par exemple, 279,58). Utilisez ces valeurs pour former le modèle.
Formation du modèle
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Ce code visualise une prévision de série chronologique pour les données de ventes de meubles. Les résultats tracés indiquent à la fois les données observées et la prévision d’une étape à l’avance, avec une région ombrée pour l’intervalle de confiance.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Utilisez predictions pour évaluer la performance du modèle, en la contrastant avec les valeurs réelles. La valeur predictions_future indique la prévision future.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Étape 4 : Noter le modèle et enregistrer les prédictions
Intégrez les valeurs réelles aux valeurs prévisionnelles pour créer un rapport Power BI. Conservez ces résultats dans une table à l'intérieur du lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Étape 5 : Visualiser dans Power BI
Le rapport Power BI affiche un pourcentage d'erreur absolue moyenne (MAPE) de 16,58. La métrique MAPE définit l’exactitude d’une méthode de prévision. Il représente la précision des quantités prévues, par rapport aux quantités réelles.
La MAPE est une métrique simple. Un MAPE de 10 % signifie que l'écart moyen entre les valeurs prévues et les valeurs réelles est de 10 %, que l'écart soit positif ou négatif. Les normes de valeurs MAPE souhaitables varient selon les secteurs d’activité.
La ligne bleue claire de ce graphique représente les valeurs de ventes réelles. La ligne bleue foncée représente les valeurs de ventes prévues. La comparaison des ventes réelles et prévisionnelles révèle que le modèle prédit efficacement les ventes de la catégorie Furniture au cours des six premiers mois de 2023.
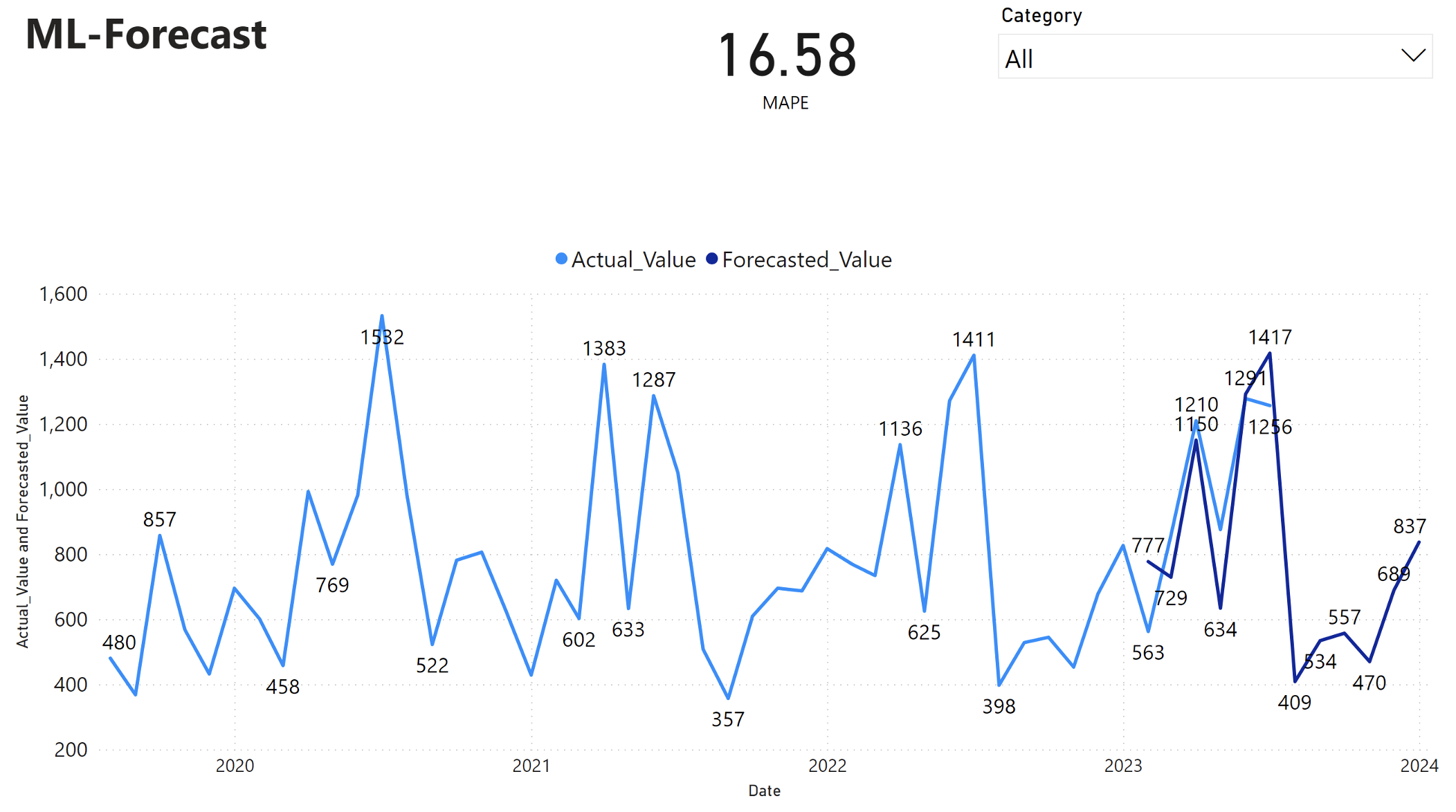
Sur la base de cette observation, nous pouvons avoir confiance dans les capacités de prévision du modèle, pour l'ensemble des ventes des six derniers mois de 2023, et se prolongeant en 2024. Cette confiance peut éclairer les décisions stratégiques concernant la gestion des stocks, l'achat de matières premières et d'autres considérations liées à l'entreprise.