Transformer des données avec Apache Spark et interroger avec SQL
Dans ce guide, vous allez :
Chargez les données dans OneLake avec l’explorateur de fichiers OneLake.
Utilisez un notebook Fabric pour lire les données sur OneLake et les mettre à jour sous forme de tableau Delta.
Analysez et transformez des données avec Spark à l'aide d'un notebook Fabric.
Interrogez une copie des données sur OneLake avec SQL.
Prérequis
Avant de commencer, vous devez :
Téléchargez et installez l'explorateur de fichiers OneLake.
Créez un espace de travail avec un élément Lakehouse.
Téléchargez le jeu de données WideWorldImportersDW. Vous pouvez utiliser Explorateur Stockage Azure pour vous connecter à
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityet télécharger l'ensemble de fichiers csv. Vous pouvez également utiliser vos propres données csv et mettre à jour les détails si nécessaire.
Remarque
Créez ou chargez systématiquement un raccourci vers les données Delta-Parquet directement dans la section Tableaux du lakehouse. N’imbriquez pas vos tableaux dans les sous-dossiers sous la section Tableaux, car le lakehouse ne les reconnaîtra pas comme tels et les étiquettera comme Non identifié.
Charger, lire, analyser et interroger des données
Dans l'explorateur de fichiers OneLake, accédez à votre lakehouse. Sous le répertoire
/Files, créez un sous-répertoire nommédimension_city.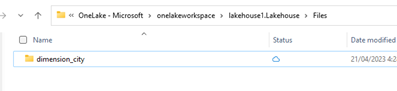
Copiez vos exemples de fichiers csv dans le répertoire OneLake
/Files/dimension_cityà l'aide de l'explorateur de fichiers OneLake.
Accédez à votre Lakehouse dans le service Power BI et affichez vos fichiers.
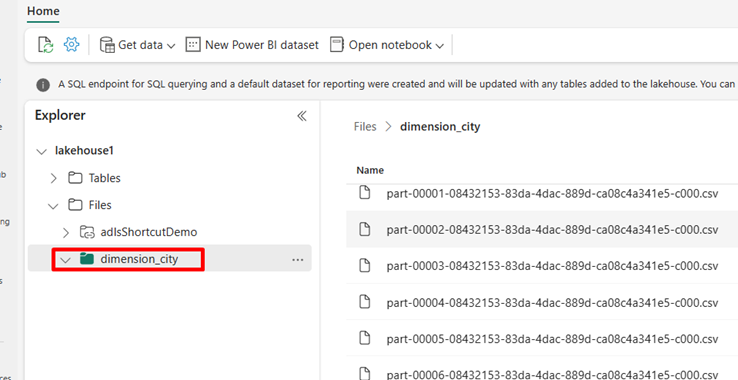
Sélectionnez Ouvrir le notebook, puis Nouveau notebook pour créer un bloc-notes.
À l'aide du notebook Fabric, convertissez les fichiers csv au format Delta. L’extrait de code suivant lit les données du répertoire
/Files/dimension_citycréé par l’utilisateur et les convertit en tableau Deltadim_city.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Pour afficher votre nouveau tableau, actualisez la vue du répertoire
/Tables.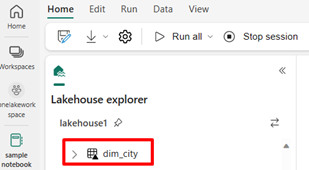
Interrogez votre table avec SparkSQL dans le même notebook Fabric.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Modifiez le tableau Delta en ajoutant une nouvelle colonne nommée newColumn avec le type de données entier. Définissez la valeur 9 pour tous les enregistrements de cette colonne nouvellement ajoutée.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;Vous pouvez également accéder à tout tableau Delta sur OneLake via un point de terminaison d’analytique SQL. Un point de terminaison d’analytique SQL fait référence à la même copie physique du tableau delta sur OneLake et offre une expérience T-SQL. Sélectionnez le point de terminaison d’analytique SQL pour lakehouse1, puis sélectionnez Nouvelle requête SQL afin d’interroger le tableau à l'aide de T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
