Conseils sur la récupération d’urgence spécifiques à l’expérience
Ce document vous fournit des conseils spécifiques à l’expérience pour récupérer vos données Fabric en cas de sinistre régional.
Exemple de scénario
Un certain nombre des sections d’aide de ce document utilise l’exemple de scénario suivant à des fins d’explication et d’illustration. Reportez-vous à ce scénario le cas échéant.
Supposons que vous avez une capacité C1 dans la région A qui a un espace de travail W1. Si vous avez activé la récupération d’urgence pour la capacité C1, les données OneLake sont répliquées dans une sauvegarde de la région B. Si la région A fait face à des interruptions, le service Fabric de C1 bascule vers la région B.
L’image suivante illustre ce scénario. La zone à gauche illustre la région interrompue. La zone du milieu représente la disponibilité continue des données après le basculement et la zone à droite montre la situation totalement couverte après l’action du client pour restaurer le fonctionnement complet de ses services.
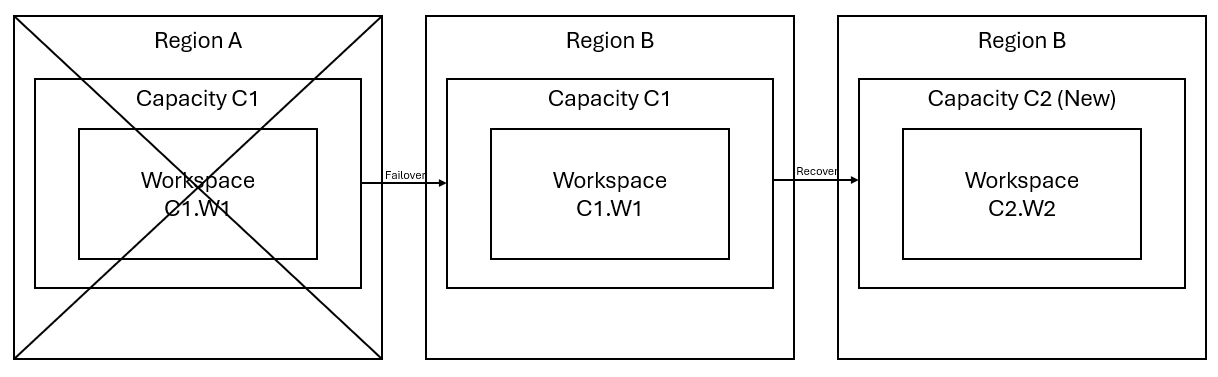
Voici le plan de récupération général :
Créez une capacité Fabric C2 dans une nouvelle région.
Créez un espace de travail W2 dans C2, incluant ses éléments correspondants avec les mêmes noms que dans C1.W1.
Copiez les données de C1.W1 à C2.W2.
Suivez les instructions dédiées de chaque composant pour restaurer les éléments afin qu’ils fonctionnent pleinement.
Plans de récupération spécifiques à l’expérience
Les sections suivantes fournissent des guides pas à pas pour chaque expérience Fabric afin d’aider les clients via le processus de récupération.
Engineering données
Ce guide vous guide tout au long des procédures de récupération pour l’expérience Ingénieurs de données. Il aborde des lakehouses, des notebooks et des définitions de tâche Spark.
Lakehouse
Les lakehouses de la région d’origine restent indisponibles aux clients. Pour récupérer un lakehouse, les clients peuvent le recréer dans un espace de travail C2.W2. Nous recommandons deux approches pour la création de lakehouses :
Approche 1 : utilisation d’un script personnalisé pour copier des fichiers et des tables Delta Lakehouse
Les clients peuvent recréer des lakehouses en utilisant un script Scala personnalisé.
Créez le lakehouse (par exemple, LH1) dans l’espace de travail C2.W2 nouvellement créé.
Créez un notebook dans l’espace de travail C2.W2.
Pour récupérer les tables et les fichiers à partir de la lakehouse d’origine, reportez-vous aux données avec des chemins OneLake tels qu’abfss (consulter Connexion à Microsoft OneLake). Vous pouvez utiliser l’exemple de code ci-dessous (voir la Présentation des utilitaires Microsoft Spark) dans le notebook pour obtenir les chemins ABFS des fichiers et des tables à partir du lakehouse d’origine. (remplacer C1.W1 par le nom d’espace de travail réel)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Utilisez l’exemple de code suivant pour copier des fichiers et des tables dans le lakehouse nouvellement créé.
Pour les tables Delta, vous devez copier une table à récupérer à la fois dans le nouveau lakehouse. Dans le cas des fichiers Lakehouse, vous pouvez copier la structure complète du fichier avec tous les dossiers sous-jacents à l’aide d’une seule exécution.
Contactez l’équipe du support technique avec le timestamp du basculement requis dans le script.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Une fois le script exécuté, les tables apparaissent dans le nouveau lakehouse.
Approche 2 : utiliser Explorateur Stockage Azure pour copier des fichiers et des tables
Pour récupérer uniquement des fichiers ou des tables Lakehouse spécifique à partir du lakehouse d’origine, utilisez Explorateur Stockage Azure. Consultez Intégrer OneLake à Explorateur Stockage Microsoft Azure pour découvrir des étapes détaillées. Pour des tailles volumineuses de données, utilisez l’Approche 1.
Remarque
Les deux approches décrites ci-dessus récupèrent les métadonnées et les données des tables au format Delta, car les métadonnées sont colocalisées et stockées avec les données dans OneLake. Pour les tables qui ne sont pas au format Delta (par exemple, CSV, Parquet, etc.) créées en utilisant des commandes/scripts de langage de définition de données (DDL) Spark, l’utilisateur est chargé de la gestion et de l’exécution des commandes/scripts DDL Spark pour les récupérer.
Notebook
Les notebooks de la région primaire restent indisponibles aux clients et le code des notebooks n’est pas répliqué dans la région secondaire. Pour récupérer du code Notebook dans la nouvelle région, il existe deux approches pour récupérer du contenu de code Notebook.
Approche 1 : redondance managée par l’utilisateur avec une intégration Git (dans la préversion publique)
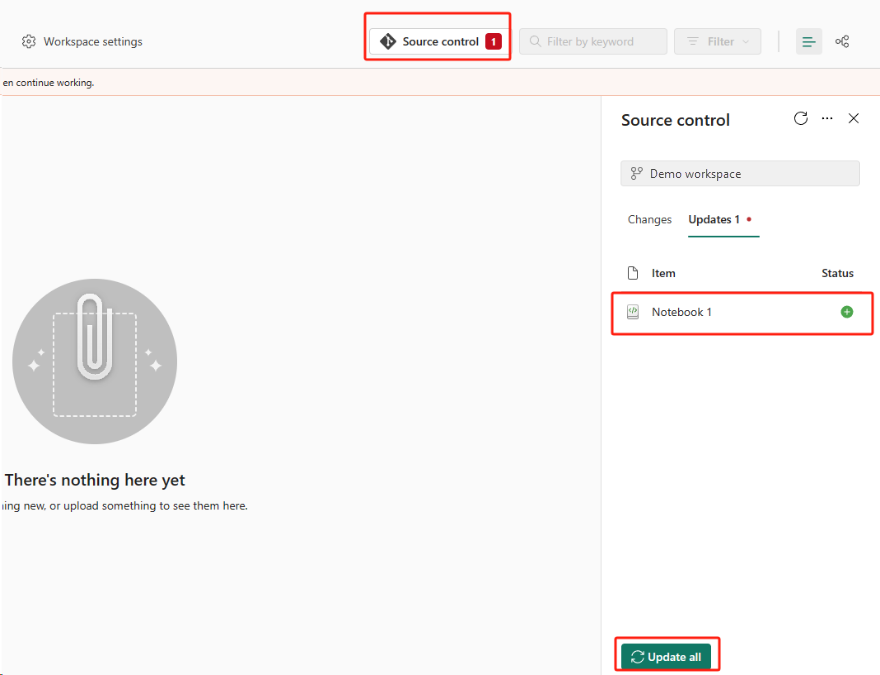
La meilleure façon de la simplifier et de l’accélérer est d’utiliser l’intégration Git Fabric, puis de synchroniser votre notebook avec votre référentiel ADO. Après le basculement du service vers une autre région, vous pouvez utiliser le référentiel pour régénérer le notebook dans l’espace de travail créé.
Configurez l’intégration Git, puis sélectionnez Connexion et synchronisation avec un référentiel ADO.
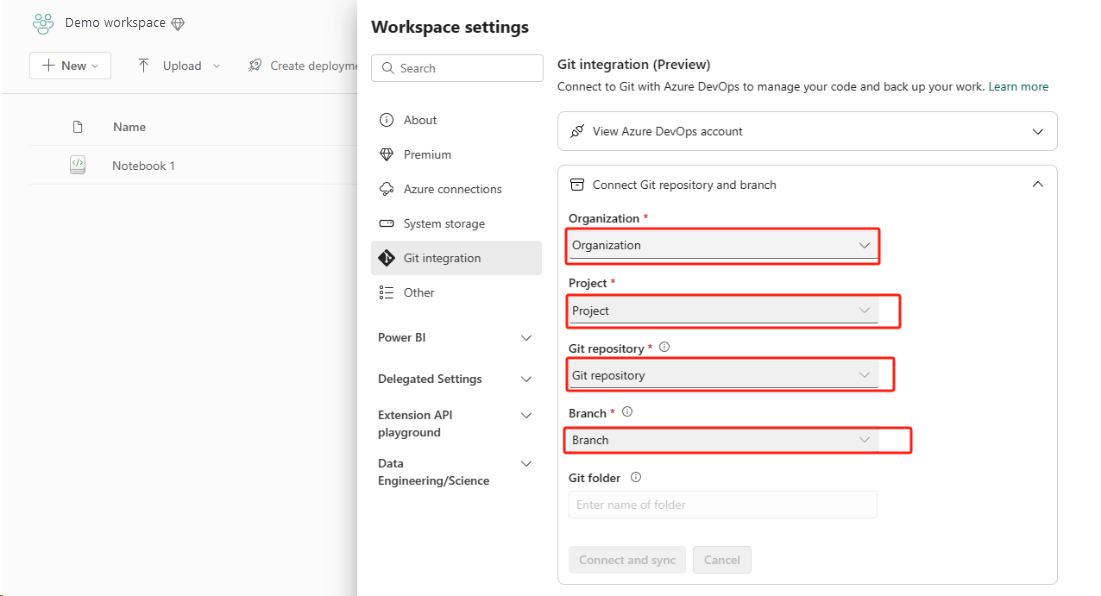
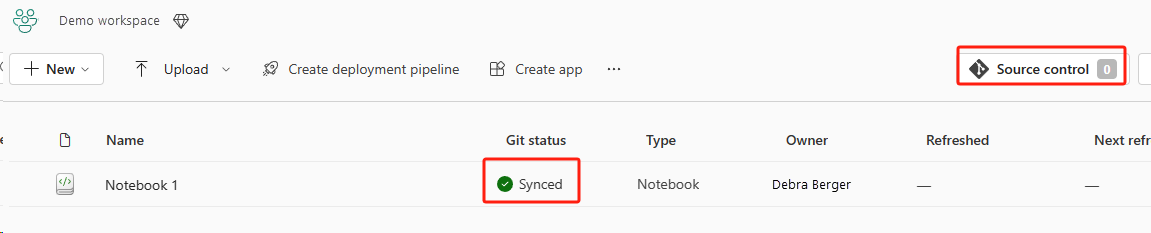
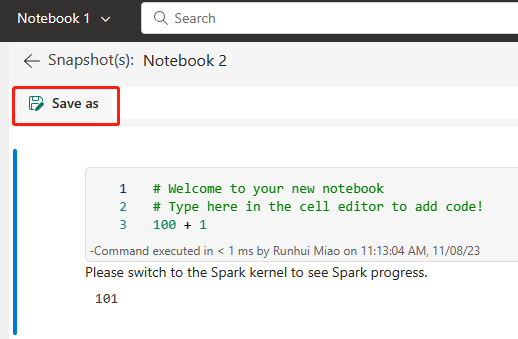
L’image suivante montre le notebook synchronisé.
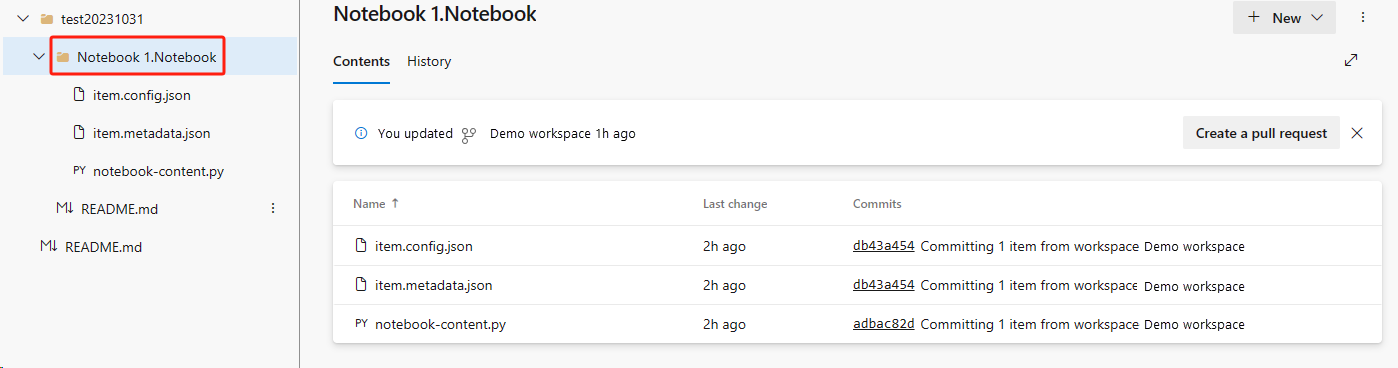
Récupérez le notebook à partir du référentiel ADO.
Dans l’espace de travail nouvellement créé, reconnectez-vous à votre référentiel ADO Azure.
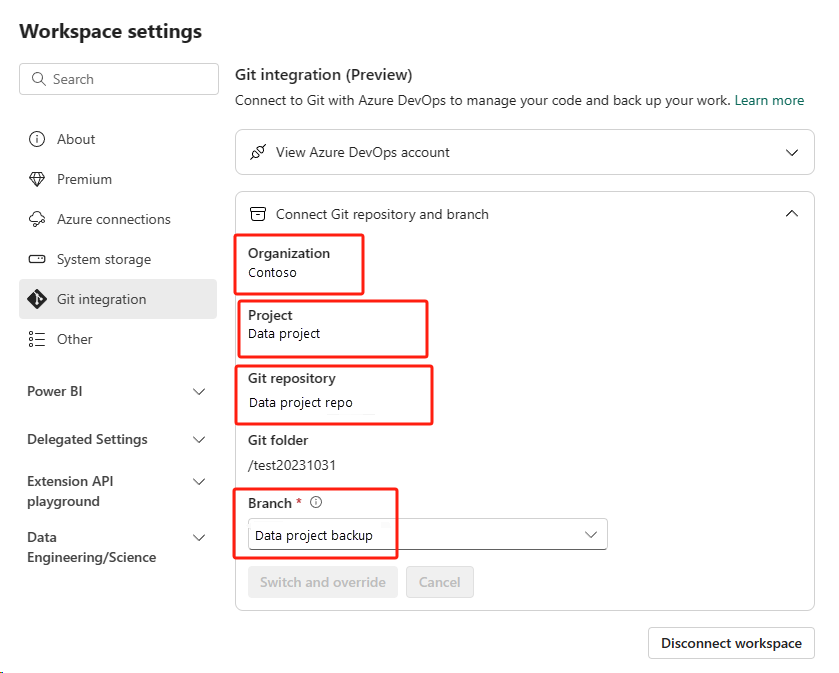
Sélectionnez le bouton Contrôle de code source. Sélectionnez ensuite la branche appropriée du référentiel. Sélectionnez ensuite Tout mettre à jour. Le notebook d’origine apparaît.
Si le notebook d’origine a un lakehouse par défaut, les utilisateurs peuvent se référer à la section Lakehouse pour récupérer le lakehouse, puis connecter le lakehouse nouvellement récupéré au notebook nouvellement récupéré.
L’intégration Git ne prend pas en charge la synchronisation de fichiers, de dossiers ou d’instantanés de notebook dans l’explorateur de ressources du notebook.
Si le notebook d’origine dispose de fichiers dans l’explorateur de ressources du notebook :
Veillez à enregistrer les fichiers ou les dossiers dans un disque local ou un autre emplacement.
Rechargez le fichier à partir de votre disque local ou de lecteurs cloud dans le notebook récupéré.
Si le notebook d’origine a un instantané de notebook, enregistrez également ce dernier dans votre système de cliché de gestion de version ou votre disque local.
Pour obtenir plus d’informations sur l’intégration Git, voir Introduction à l’intégration Git.
Approche 2 : approche manuelle de la sauvegarde du contenu de code
Si vous ne disposez pas d’une approche d’intégration Git, vous pouvez enregistrer la dernière version de votre code et de vos fichiers dans l’explorateur de ressources et l’instantané de notebook dans un système de gestion de version tel que Git, et récupérer manuellement le contenu du notebook après un sinistre :
Utilisez la fonctionnalité « Importer le notebook » pour importer le code de notebook que vous souhaitez récupérer.
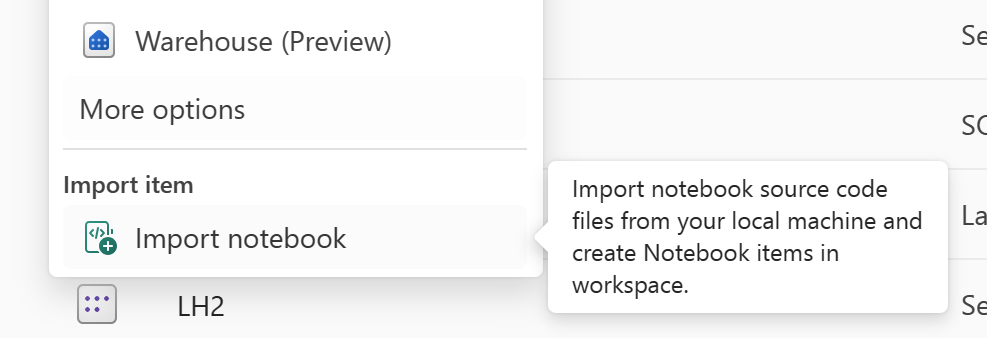
Après l’importation, accédez à l’espace de travail souhaité (par exemple, « C2.W2 ») pour y accéder.
Si le notebook d’origine a un lakehouse par défaut, consultez la section Lakehouse. Connectez ensuite le lakehouse nouvellement récupéré (qui dispose du même contenu que le lakehouse par défaut d’origine) au notebook nouvellement récupéré.
Si le notebook d’origine a des fichiers ou des dossiers dans l’explorateur de ressources, rechargez les fichiers ou dossiers enregistrés dans le système de gestion de version de l’utilisateur.
Définition de la tâche Spark
Les définitions de tâche Spark (SJD) de la région primaire restent indisponibles aux clients et le principal fichier de définition et le fichier de référence du notebook sont répliqués dans la région secondaire via OneLake. Si vous souhaitez récupérer la SJD dans la nouvelle région, vous pouvez suivre les étapes manuelles décrites ci-dessous pour la récupérer. Notez que les exécutions historiques de la SJD ne sont pas récupérées.
Vous pouvez récupérer les éléments de SJD en copiant le code à partir de la région d’origine en utilisant Explorateur Stockage Azure et en reconnectant manuellement les références Lakehouse après le sinistre.
Créez un élément de SJD (par exemple, SDJ1) dans le nouvel espace de travail C2.W2 avec les mêmes paramètres et configurations que l’élément de SJD d’origine (par exemple, le langage, l’environnement, etc.).
Utilisez Explorateur Stockage Azure pour copier des bibliothèques, des mains et des instantanés de l’élément de SJD d’origine vers le nouvel élément de SJD.
Le contenu de code apparaît dans la SJD nouvellement créée. Vous devez ajouter manuellement la référence Lakehouse nouvellement récupérée de la tâche (consultez les Étapes de récupération de lakehouses). Les utilisateurs doivent entrer à nouveau manuellement les arguments de ligne de commande d’origine.
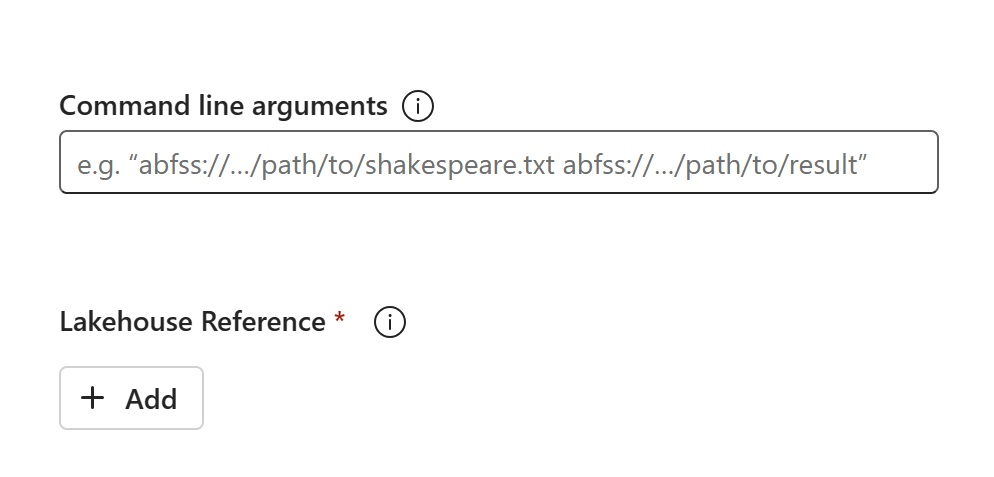
Vous pouvez maintenant exécuter ou planifier votre SJD nouvellement récupérée.
Pour obtenir plus d’informations sur l’Explorateur Stockage Azure, voir Intégrer OneLake à l’Explorateur Stockage Azure.
Science des données
Ce guide vous accompagne tout au long des procédures de récupération pour l’expérience Science des données. Il aborde les modèles et les expériences ML.
Modèle et expérience ML
Les éléments Science des données de la région primaire restent indisponibles aux clients, et le contenu et les métadonnées des modèles et expériences ML ne sont pas répliqués vers la région secondaire. Pour les récupérer complètement dans la nouvelle région, enregistrez le contenu de code dans un système de gestion de version (tel que Git) et réexécutez manuellement le contenu de code après le sinistre.
Récupérez le notebook. Consultez les Étapes de récupération de notebooks.
Les configurations, métriques d’exécutions historiques et métadonnées ne sont pas répliquées dans la région jumelée. Vous devez exécuter à nouveau chaque version de votre code de science des données pour récupérer complètement des expériences et des modèles ML après le sinistre.
entrepôt de données
Ce guide vous accompagne tout au long des procédures de récupération pour l’expérience Data Warehouse. Il aborde les entrepôts.
Entrepôt
Les entrepôts de la région d’origine restent indisponibles aux clients. Pour récupérer des entrepôts, utilisez les deux étapes suivantes.
Créez un lakehouse temporaire dans l’espace de travail C2.W2 pour les données que vous copiez à partir de l’entrepôt d’origine.
Renseignez les tables Delta de l’entrepôt en tirant parti de l’explorateur d’entrepôts et des fonctionnalités T-SQL (voir Tables dans l’entrepôt de données dans Microsoft Fabric).
Remarque
Nous vous recommandons de conserver votre code d’entrepôt (schéma, table, affichage, procédure stockée, définitions de fonction et codes de sécurité) par version et de l’enregistrer dans un emplacement sécurisé (tel que Git) en fonction de vos pratiques de développement.
Ingestion de données via un code Lakehouse et T-SQL
Dans un espace de travail C2.W2 nouvellement créé :
Créez un lakehouse temporaire « LH2 » dans C2.W2.
Récupérez les tables Delta dans le lakehouse temporaire à partir de l’entrepôt d’origine en suivant les Étapes de récupération de lakehouses.
Créez un entrepôt « WH2 » dans C2.W2.
Connectez le lakehouse provisoire à votre explorateur d’entrepôts.
En fonction de la façon dont vous allez déployer des définitions de table avant d’importer des données, le T-SQL réel utilisé pour les importations peut varier. Vous pouvez utiliser l’approche INSERT INTO, SELECT INTO ou CREATE TABLE AS SELECT pour récupérer des tables d’entrepôt à partir des lakehouses. Plus loin dans l’exemple, nous utiliserons la saveur INSERT INTO. (Si vous utilisez le code ci-dessous, remplacez les exemples par la table et les noms de colonne réels)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOEnfin, modifiez la chaîne de connexion dans les applications en utilisant votre entrepôt Fabric.
Remarque
Pour les clients qui ont besoin d’une récupération d’urgence inter-régionale et d’une continuité d’activité entièrement automatisée, nous recommandons de conserver deux configurations d’entrepôt dans des régions Fabric distinctes et de maintenir la parité des données et du code en effectuant des déploiements et des ingestions des données réguliers sur les deux sites.
Base de données miroir
Les bases de données mises en miroir de la région primaire restent indisponibles pour les clients et les paramètres ne sont pas répliqués vers la région secondaire. Pour le récupérer en de défaillance régionale, vous devez recréer votre base de données mise en miroir dans un autre espace de travail d’une autre région.
Data Factory
Les éléments Data Factory de la région primaire restent indisponibles aux clients et les paramètres et configurations dans des pipelines de données ou des éléments Dataflow Gen2 ne sont pas répliqués dans la région secondaire. Pour récupérer ces éléments en cas de défaillance régionale, vous devez recréer vos éléments Intégration de données dans un autre espace de travail à partir d’une région différente. Les sections suivantes décrivent les détails.
Flux de données Gen2
Si vous souhaitez récupérer un élément Dataflow Gen2 dans la nouvelle région, vous devez exporter un fichier PQT vers un système de gestion de version tel que Git, puis récupérer manuellement le contenu Dataflow Gen2 après le sinistre.
Dans votre élément Dataflow Gen2 sous l’onglet Accueil de l’éditeur Power Query, sélectionnez Exporter le modèle.
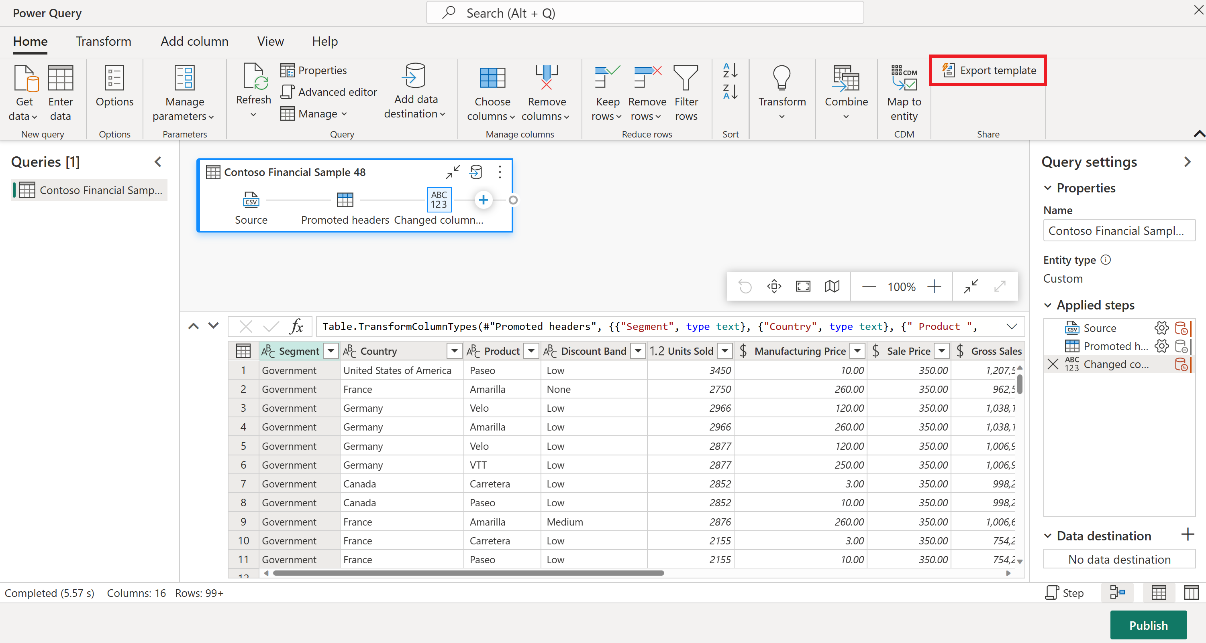
Dans la boîte de dialogue Exporter un modèle, entrez un nom (obligatoire) et une description (facultative) pour ce modèle. Une fois cette opération effectuée, sélectionnez OK.
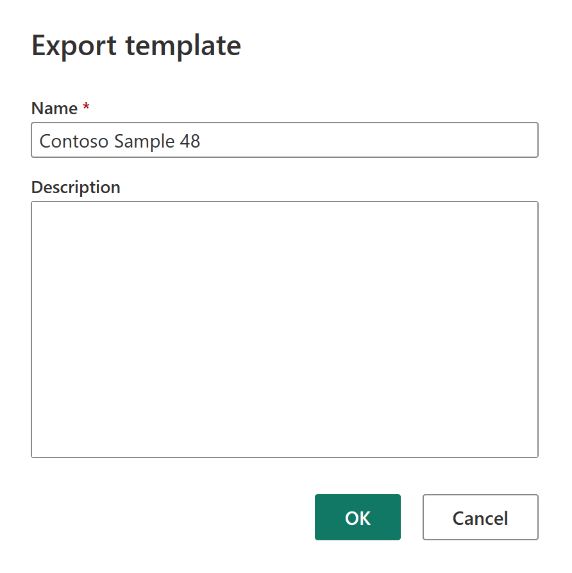
Après le sinistre, créez un élément Dataflow Gen2 dans le nouvel espace de travail « C2.W2 ».
Dans le volet d’affichage actuel de l’éditeur Power Query, sélectionnez Importer à partir d’un modèle Power Query.
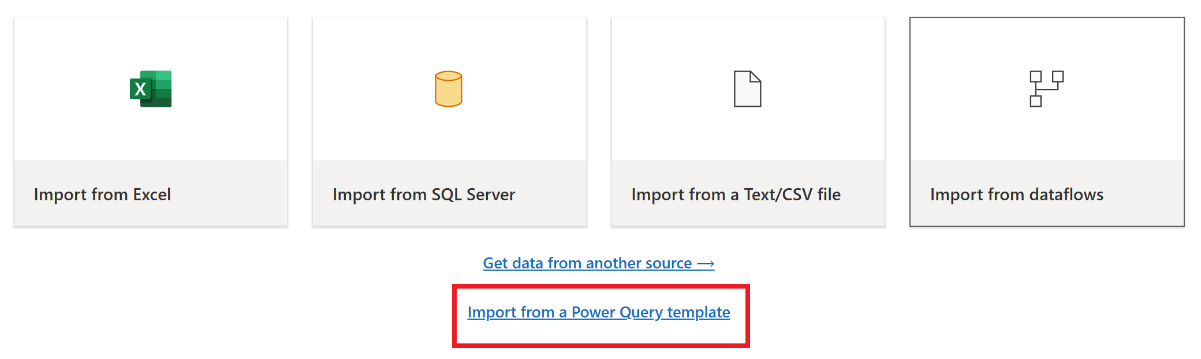
Dans la boîte de dialogue Ouvrir, accédez à votre dossier des téléchargements par défaut et sélectionnez le fichier .pqt que vous avez enregistré lors des étapes précédentes. Sélectionnez ensuite Ouvrir.
Le modèle est ensuite importé dans votre nouvel élément Dataflow Gen2.
Pipelines de données
Les clients ne peuvent pas accéder aux pipelines de données en cas de sinistre régional et les configurations ne sont pas répliquées dans la région jumelée. Nous vous recommandons de générer les pipelines de vos données critiques dans plusieurs espaces de travail de diverses régions.
Real-Time Intelligence
Ce guide vous accompagne tout au long des procédures de récupération pour l’expérience Real-Time Intelligence. Il aborde les ensembles de requêtes/bases de données KQL et des eventstreams.
Ensemble de requêtes/base de données KQL
Les utilisateurs d’ensembles de requêtes/bases de données KQL doivent prendre des mesures proactives pour se protéger contre un sinistre régional. L’approche suivante veille, en cas de sinistre régional, à ce que les données dans vos ensembles de requêtes de bases de données KQL restent sécurisés et accessibles.
Utilisez les étapes suivantes afin d’assurer une solution de récupération d’urgence efficace pour des ensembles de requêtes et des bases de données KQL.
Mise en place de bases de données KQL indépendantes : configurez au moins deux ensembles de requêtes/bases de données KQL sur des capacités Fabric dédiées. Celles-ci doivent être configurées dans deux différentes régions Azure (des régions jumelées Azure de préférence) pour optimiser la résilience.
Répliquer les activités de gestion : toute mesure de gestion prise sur une base de données KQL doit être mise en miroir dans l’autre. Cela permet aux deux bases de données de rester synchronisées. Les activités clés à répliquer incluent :
Tables : vérifiez que les définitions de schéma et les structures de table sont cohérentes dans les bases de données.
Mappage : dupliquez les mappages souhaités. Vérifiez que les sources de données et les destinations s’alignent correctement.
Stratégies : vérifiez que les deux bases de données sont une conservation des données similaire et d’autres stratégies pertinentes.
Gestion des authentifications et des autorisations : pour chaque réplica, configurez les autorisations exigées. Vérifiez que des niveaux d’autorisation corrects sont établis pour accorder l’accès au personnel requis tout en maintenant les normes de sécurité.
Ingestion de données parallèles: pour maintenir la cohérence et la préparation des données dans plusieurs régions, chargez le même jeu de données dans chaque base de données KQL en même temps que vous l’ingérer.
Eventstream
Un eventstream est un emplacement centralisé dans la plateforme Fabric pour capturer, transformer et router des événements en temps réel vers diverses destinations (par exemple, des lakehouses, des ensembles de requêtes/bases de données KQL) avec une expérience sans code. Dans la mesure où les destinations sont prises en charge par la récupération d’urgence, les eventstreams ne perdent pas de données. Par conséquent, les clients doivent utiliser les fonctionnalités de récupération d’urgence de ces systèmes de destination pour veiller à la disponibilité des données.
Les clients peuvent également obtenir une redondance géographique en déployant des charges de travail Eventstream identiques dans plusieurs régions Azure dans le cadre d’une stratégie active/active sur plusieurs sites. Grâce à l’approche active/active sur plusieurs sites, les clients peuvent accéder à leur charge de travail dans n’importe quelle région déployée. Cette approche est la plus complexe et la plus coûteuse en ce qui concerne la récupération d’urgence, mais elle peut réduire le temps de récupération à une valeur proche de zéro dans la majorité des situations. Pour être redondants géographiquement, les clients peuvent
Créer des réplicas de leurs sources de données dans différentes régions.
Créer des éléments Eventstream dans les régions correspondantes.
Connecter ces nouveaux éléments aux sources de données identiques.
Ajouter des destinations identiques pour chaque eventstream dans diverses régions.