Utiliser un modèle prédéfini pour extraire des informations à partir de documents simples dans Microsoft Syntex
Le modèle de traitement de documents simple offre une solution flexible et préentraînée pour extraire des informations à partir de documents structurés de base, notamment des informations telles que :
Paires clé-valeur : imaginez ces étiquettes et leurs informations correspondantes, telles que « Nom : Adele Vance ».
Marques de sélection : il s’agit de cases à cocher ou d’autres marques qui indiquent des choix ou des sélections dans un document.
Entités nommées : il s’agit d’éléments spécifiques tels que les noms de personnes, de lieux ou d’organisations mentionnés dans le texte d’un document.
Codes-barres : il s’agit de représentations lisibles par ordinateur de données qui peuvent être utilisées à des fins de suivi ou d’identification dans un document.
Contrairement à d’autres modèles prédéfinis avec des schémas fixes, ce modèle peut identifier les clés que d’autres utilisateurs peuvent manquer, ce qui offre une alternative précieuse à l’étiquetage et à l’entraînement des modèles personnalisés. Ce modèle prend également en charge les codes-barres et la détection de langue.
Types de documents
Le traitement de document simple fonctionne mieux avec les types de documents qui contiennent des informations structurées, telles que :
Forms : ceux-ci ont souvent des champs et des étiquettes clairs, ce qui facilite l’extraction des paires clé-valeur.
Factures : incluent généralement des dispositions cohérentes avec des tables et des paires clé-valeur.
Reçus : à l’instar des factures, ils ont des données structurées qui peuvent être facilement extraites.
Contrats : contiennent des sections et des clauses bien définies qui peuvent être analysées efficacement.
Relevés bancaires : inclut des tables et des données structurées idéales pour l’extraction.
Ces documents tirent parti des fonctionnalités de reconnaissance optique de caractères (OCR) et des processus d’apprentissage profond utilisés pour extraire des paires clé-valeur, des marques de sélection, des tables et des entités nommées.
Remarque
Actuellement, ce modèle est disponible pour les types de fichiers .pdf et image et dans plus de 100 langues. D’autres types de fichiers pris en charge seront ajoutés dans les versions ultérieures.
Pour utiliser un modèle de traitement de document simple, procédez comme suit :
- Étape 1 : Créer le modèle
- Étape 2 : Charger un exemple de fichier à analyser
- Étape 3 : Sélectionner des extracteurs pour votre modèle
- Étape 4 : Appliquer le modèle
Étape 1 : Créer le modèle
Suivez les instructions fournies dans Créer un modèle dans Syntex pour créer un modèle de traitement de document simple. Passez ensuite aux étapes suivantes pour terminer votre modèle.
Étape 2 : Charger un exemple de fichier à analyser
Dans la page Modèles , dans la section Ajouter un fichier à analyser , sélectionnez Ajouter un fichier.
Dans la page Fichiers à analyser, sélectionnez Ajouter pour rechercher le fichier que vous souhaitez utiliser.
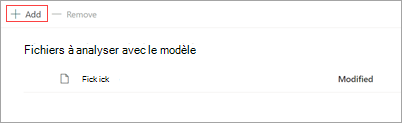
Dans la page Ajouter un fichier à partir de la bibliothèque de fichiers d’apprentissage , sélectionnez le fichier, puis sélectionnez Ajouter.
Dans la page Fichiers à analyser du modèle , sélectionnez Suivant.
Étape 3 : Sélectionner des extracteurs pour votre modèle
Dans la page des détails de l’extracteur, vous voyez la zone de document à droite de la page et le panneau Extracteurs à gauche. Le panneau Extracteurs affiche la liste des extracteurs qui ont été identifiés dans le document.
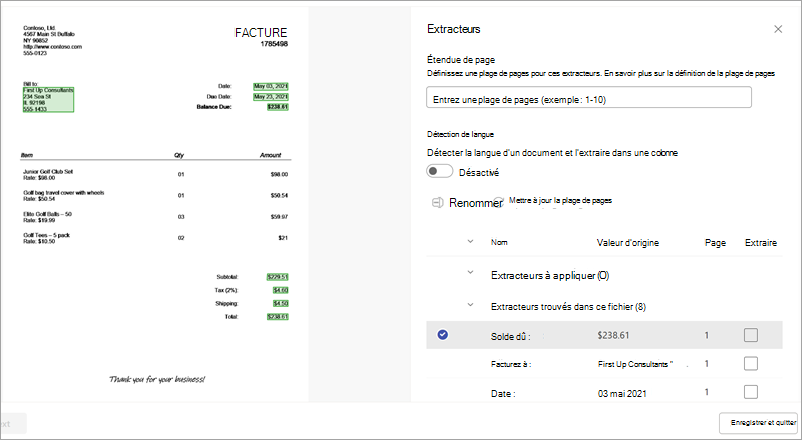
Les champs d’entité mis en surbrillance en vert dans la zone de document sont les éléments détectés par le modèle lors de l’analyse du fichier. Lorsque vous sélectionnez une entité à extraire, le champ en surbrillance devient bleu. Si vous décidez par la suite de ne pas inclure l’entité, le champ en surbrillance devient gris. Les points forts facilitent l’affichage de l’état actuel des extracteurs que vous sélectionnez.
Conseil
Pour effectuer un zoom avant ou arrière pour lire les champs d’entité, utilisez la roulette de défilement de votre souris ou les contrôles de zoom en bas de la zone de document.
Sélectionner une entité d’extracteur
Vous pouvez sélectionner un extracteur dans la zone de document ou dans le panneau Extracteurs , selon vos préférences.
- Pour sélectionner un extracteur dans la zone de document, sélectionnez le champ d’entité.
- Pour sélectionner un extracteur dans le panneau Extracteurs , dans la colonne Extraire , cochez la case correspondante à droite du nom de l’entité.
Lorsque vous sélectionnez un extracteur, la zone Sélectionner l’extracteur ? s’affiche dans la zone de document. La zone affiche le nom de clé (le nom généré pour l’extracteur), la valeur détectée (la valeur de ce champ dans le document), le type de colonne et l’option permettant de sélectionner l’entité en tant qu’extracteur.
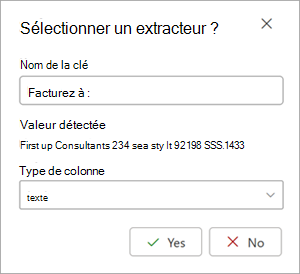
Le nom de clé est utilisé comme nom de colonne lorsque le modèle est appliqué à une bibliothèque SharePoint. Vous pouvez modifier le nom de la clé pour qu’il soit plus descriptif si vous le souhaitez. Le type de colonne indique comment les informations sont affichées dans une bibliothèque. Vous pouvez modifier le type de colonne pour afficher les informations. Lorsque le modèle est appliqué à une bibliothèque, vous pouvez utiliser la mise en forme de colonne pour spécifier l’aspect que vous souhaitez lui donner dans le document.
Continuez à sélectionner les autres extracteurs que vous souhaitez utiliser. Vous pouvez également ajouter d’autres fichiers à analyser pour cette configuration de modèle.
Renommer un extracteur
Il existe trois façons de renommer un extracteur :
Dans la zone de document de la page des détails de l’extracteur, sélectionnez le champ d’entité. Dans la zone Sélectionner l’extracteur ? , dans le champ Nom de la clé , entrez un nouveau nom pour l’extracteur.
Dans le panneau Extracteurs de la page de détails de l’extracteur, sélectionnez l’extracteur que vous souhaitez renommer, puis sélectionnez Renommer.
Dans la page d’accueil du modèle, dans la section Extracteurs , sélectionnez l’extracteur que vous souhaitez renommer, puis sélectionnez Renommer.
Définir une plage de pages pour le traitement
Pour ce modèle, vous pouvez spécifier de traiter une plage de pages pour un fichier plutôt que pour le fichier entier. Dans le panneau Extracteurs , dans la section Plage de pages, sélectionnez la page que vous souhaitez traiter. Par défaut, le paramètre Plage de pages est vide. Si aucune plage de pages n’est fournie, l’intégralité du document est traitée. Pour plus d’informations, consultez Définir une plage de pages pour extraire des informations de pages spécifiques.
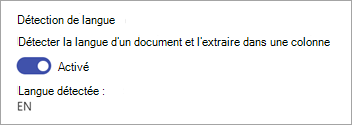
Détecter la langue d’un document
Pour ce modèle, vous pouvez détecter la langue d’un document et l’extraire dans une colonne. Dans le panneau Extracteurs , dans la section Détection de la langue , basculez pour activer la détection de langue. Il vous montre le code ISO de la langue détectée.
Vous pouvez également activer ou désactiver la détection de langue à partir du panneau Paramètres du modèle pour le modèle.
Étape 4 : Appliquer le modèle
Pour enregistrer les modifications et revenir à la page d’accueil du modèle, dans le panneau Extracteurs , sélectionnez Enregistrer et quitter.
Si vous êtes prêt à appliquer le modèle à une bibliothèque, dans la zone de document, sélectionnez Suivant. Dans le panneau Ajouter à la bibliothèque , choisissez la bibliothèque à laquelle vous souhaitez ajouter le modèle, puis sélectionnez Ajouter.