Appliquer des aperçus dans Power BI pour découvrir des variations dans les distributions
S’APPLIQUE À :![]() ️ Power BI Desktop
️ Power BI Desktop ![]() Service Power BI
Service Power BI
Quand vous examinez un point de données dans un visuel, vous vous demandez souvent si la distribution serait la même pour d’autres catégories. Grâce aux Aperçus de Power BI, vous pouvez obtenir la réponse en quelques clics.
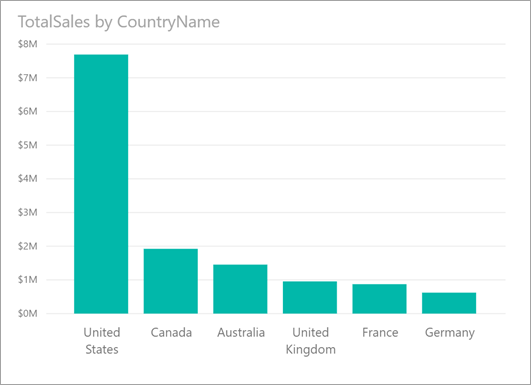
Penchons-nous sur le visuel suivant présentant TotalSales par CountryName. La plupart des ventes sont réalisées aux États-Unis, qui représentent 57 % des ventes totales, la part des autres pays/régions étant plus faible. En pareil cas, il est souvent intéressant de savoir si cette distribution serait identique pour des sous-populations différentes. Par exemple, le résultat est-il le même pour toutes les années, tous les canaux de vente et toutes les catégories de produits ? Même s’il est possible d’appliquer des filtres différents et de comparer les résultats visuellement, cette opération s’avère fastidieuse et sujette à des erreurs.
Vous pouvez demander à Power BI de localiser les différences de distribution et obtenir une analyse automatique, rapide et révélatrice de vos données. Cliquez avec le bouton droit sur un point de données, puis sélectionnez Analyser>Localiser les différences de répartition. Des insights vous sont présentés dans une fenêtre simple d’utilisation.
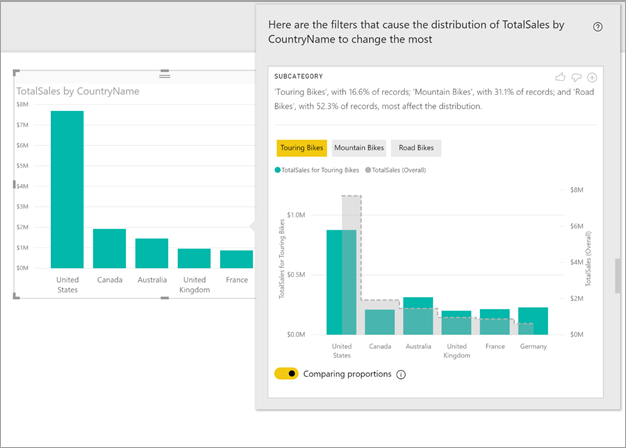
Dans cet exemple, l’analyse automatisée montre que les ventes de Touring Bikes (Vélos de cyclotourisme) aux États-Unis et au Canada sont proportionnellement inférieures à celles observées dans les autres pays ou régions.
Utiliser des insights
Pour localiser les différences de distribution sur les graphiques, cliquez avec le bouton droit sur un point de données ou sur le visuel tout entier. Sélectionnez ensuite Analyser>Rechercher où cette distribution est différente.
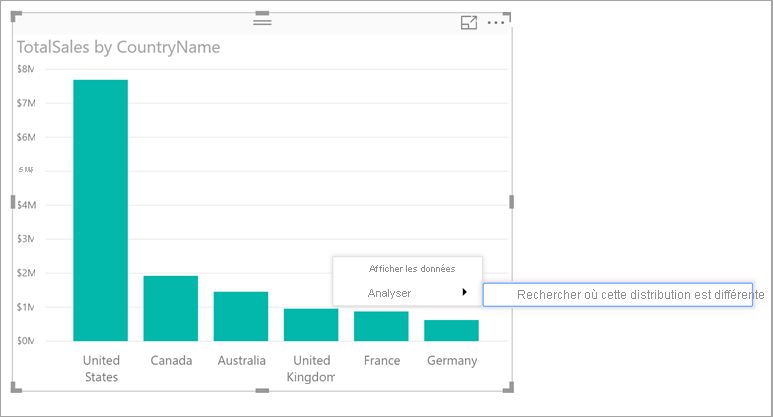
Power BI exécute ses algorithmes d’apprentissage automatique sur les données. Il fait ensuite apparaître dans une fenêtre un visuel et une description des catégories (colonnes) et des valeurs de ces catégories qui produisent la distribution la plus significativement différente. Les aperçus sont fournis sous forme d’histogramme, comme le montre l’image suivante :
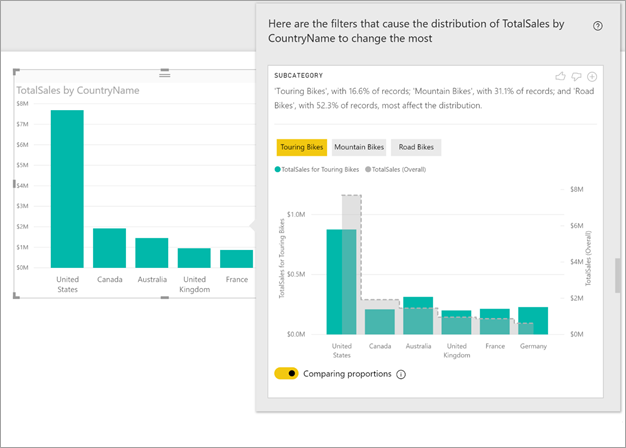
Les valeurs auxquelles le filtre sélectionné est appliqué s’affichent dans la couleur par défaut. Les valeurs globales, telles qu’elles sont représentées dans le visuel initial, sont affichées en gris pour faciliter la comparaison. Il est possible d’appliquer jusqu’à trois filtres différents (en l’occurrence, Touring Bikes (Vélos de cyclotourisme), Mountain Bikes (VTT) et Road Bikes (Vélos de route)), ainsi que de choisir différents filtres en sélectionnant un point de données ou en utilisant la combinaison de Ctrl-clic pour en sélectionner plusieurs.
Pour les mesures additives simples, comme Total Sales (Total des ventes) dans cet exemple, la comparaison s’effectue à partir de valeurs relatives, et non absolues. Si les ventes de vélos de cyclotourisme sont plus faibles que les ventes globales dans toutes les catégories, par défaut, le visuel utilise un axe double pour permettre de comparer la proportion des ventes dans les différents pays ou régions. Ceci à trait aux vélos de cyclotourisme par rapport à toutes les catégories de vélos. En actionnant le bouton bascule situé au bas du visuel, vous pouvez afficher les deux valeurs sur le même axe, ce qui vous permet de comparer facilement les valeurs absolues, comme le montre l’image suivante :
Le texte descriptif indique également le niveau d’importance qui peut être associé à une valeur de filtre, compte tenu du nombre d’enregistrements qui correspondent à celui-ci. Dans cet exemple, vous voyez que, même si la distribution pour la catégorie Touring Bikes (Vélos de cyclotourisme) est différente, elle ne représente que 16,6 % des enregistrements.
Les icônes de pouce levé et de pouce baissé en haut de la page vous permettent de commenter le visuel et la fonctionnalité. Toutefois, cela n’a pas pour effet d’effectuer l'apprentissage de l’algorithme pour influencer les résultats qui seront retournés la prochaine fois que vous utiliserez la fonctionnalité.
Surtout, le bouton + en haut d’un visuel vous permet d’ajouter le visuel sélectionné à votre rapport, exactement comme si vous créiez le visuel manuellement. Vous pouvez ensuite mettre en forme ou ajuster le visuel ajouté, comme vous le feriez pour tout autre visuel figurant sur votre rapport. Lorsque vous modifiez un rapport dans Power BI Desktop, vous ne pouvez ajouter qu’un seul visuel d’information sélectionné.
Vous pouvez utiliser des aperçus lorsque votre rapport est en mode lecture ou édition. Cela a pour effet de le rendre polyvalent tant pour l'analyse de données que pour la création de visuels que vous pouvez ajouter à vos rapports.
Détails des résultats retournés
Vous pouvez vous représenter l'algorithme comme prenant toutes les autres colonnes du modèle et, pour toutes les valeurs de celles-ci, les appliquant comme des filtres au visuel d'origine. L'algorithme trouve ensuite parmi ces valeurs de filtre celle qui produit le résultat qui diffère le plus de l'original.
Vous vous demandez probablement ce que l’on entend par différent. Par exemple, supposons que la distribution globale des ventes entre les États-Unis et le Canada est la suivante :
| Pays/Région | Ventes (en millions de dollars) |
|---|---|
| États-Unis | 15 |
| Canada | 5 |
Pour une catégorie de produit déterminée (Road Bikes) (Vélos de route), les ventes pourraient être réparties comme suit :
| Pays/Région | Ventes (en millions de dollars) |
|---|---|
| États-Unis | 3 |
| Canada | 1 |
Même si les chiffres sont différents dans chacun de ces tableaux, les valeurs relatives entre les États-Unis et le Canada sont identiques, soit respectivement 75 % et 25 % pour les ventes globales et de vélos de route. Par conséquent, ils ne sont pas considérés comme différents. Pour des mesures additives simples comme celles-ci, l’algorithme recherche des différences dans les valeurs relatives.
En revanche, considérez une mesure telle que la marge calculée comme un profit/coût. Si les marges globales des États-Unis et du Canada étaient les suivantes :
| Pays/Région | Marge (%) |
|---|---|
| États-Unis | 15 |
| Canada | 5 |
Pour une catégorie de produit déterminée (Road Bikes) (Vélos de route), les ventes pourraient être réparties comme suit :
| Pays/Région | Marge (%) |
|---|---|
| États-Unis | 3 |
| Canada | 1 |
Compte tenu de la nature de ces mesures, il s'agit d'une différence intéressante. Pour des mesures non additives telles que cet exemple de marge, l’algorithme recherche des différences dans la valeur absolue.
Les visuels affichés ont donc pour but de montrer les différences trouvées entre la distribution globale, telle que présentée dans le visuel d’origine, et la valeur après application du filtre spécifique.
Pour des mesures additives, comme Sales (Ventes) dans l’exemple précédent, un graphique avec histogramme et courbe est utilisé. Dans ce cas, l'utilisation d'un axe double avec une mise à l'échelle appropriée est telle que les valeurs relatives peuvent être comparées. Les colonnes indiquent la valeur avec le filtre appliqué, et la ligne indique la valeur globale. L'axe des colonnes est à gauche, et l'axe des lignes à droite, comme d'habitude. La ligne s’affiche avec un style en escalier, avec une ligne en pointillés, remplie de gris. Pour l’exemple précédent, si la valeur maximale de l’axe des colonnes est 4 et que la valeur maximale de l’axe des lignes est 20, les valeurs relatives entre les États-Unis et le Canada sont faciles à comparer pour les valeurs filtrées et les valeurs globales.
De la même façon, pour les mesures non additives comme la marge dans l’exemple précédent, un graphique avec histogramme et courbe est utilisé, où l’utilisation d’un axe unique signifie que les valeurs absolues peuvent être facilement comparées. La ligne remplie de gris indique la valeur globale. Qu’il s’agisse de comparer des valeurs réelles ou des valeurs relatives, il ne suffit pas de calculer la différence entre les valeurs pour déterminer le degré de différence entre deux distributions. Par exemple :
Quand la taille de la population est prise en compte, une différence est statistiquement moins significative et moins intéressante quand elle s’applique à une faible proportion de la population globale. Par exemple, la distribution des ventes entre les pays/régions peut être différente pour un produit particulier. Cela ne serait pas intéressant s'il y avait des milliers de produits. Ce produit particulier ne représentait donc qu'un faible pourcentage des ventes globales.
Les différences concernant les catégories dont les valeurs d’origine étaient élevées ou proches de zéro ont plus de poids que les autres. Par exemple, si la part globale des ventes dans un pays ou une région se limite à 1 %, mais que la part pour un type de produit est de 6 %, il s’agit d’un élément statistiquement plus significatif et donc comme plus intéressant qu’un pays ou une région dont la part est passée de 50 % à 55 %.
Diverses méthodes heuristiques sélectionnent les résultats les plus significatifs, par exemple en prenant en considération d’autres relations entre les données.
Après examen des différentes colonnes et des valeurs de chacune de ces colonnes, c’est l’ensemble de valeurs qui présentent les plus grandes différences qui est choisi. Pour faciliter la compréhension, ces valeurs sont sorties et regroupées par colonne, la colonne dont les valeurs présentent la plus grande différence étant répertoriée en premier. Chaque colonne contient au maximum trois valeurs, mais peut en présenter moins si le nombre de valeurs ayant un effet important est moindre ou si certaines valeurs ont beaucoup plus d’impact que d’autres.
Toutes les colonnes du modèle n’étant pas nécessairement examinées pendant la période disponible, il n’est pas garanti que les colonnes et les valeurs ayant le plus fort impact soient affichées. Cependant, diverses méthodes heuristiques garantissent que les colonnes les plus probables sont examinées en premier. Par exemple, supposons qu’après examen de toutes les colonnes, il soit établi que les colonnes/valeurs suivantes ont le plus fort impact sur la distribution (ordre décroissant) :
Subcategory = Touring Bikes
Channel = Direct
Subcategory = Mountain Bikes
Subcategory = Road Bikes
Subcategory = Kids Bikes
Channel = Store
La sortie obtenue en fonction de l’ordre des colonnes est la suivante :
Subcategory: Touring Bikes, Mountain Bikes, Road Bikes (seulement trois listées avec la mention «...amongst others » (entre autres) pour indiquer qu’il y en a plus de trois qui ont un impact significatif)
Channel = Direct (seul Direct est indiqué si son impact était bien plus fort que celui de Store)
Observations et limitations
La liste suivante répertorie les scénarios actuellement non pris en charge pour la fonctionnalités d’affichage d’informations :
- Filtres TopN
- Filtres de mesures
- Mesures non numériques
- Utilisation de « Afficher la valeur comme »
- Mesures filtrées : les mesures filtrées sont des calculs effectués au niveau du visuel auxquels est appliqué un filtre spécifique, comme Total des ventes pour la France. Elles sont utilisées dans certains visuels créés par la fonctionnalité d’aperçus.
De plus, les sources de données et les types de modèles suivants ne sont actuellement pas pris en charge pour la fonctionnalité d’affichage d’informations :
- DirectQuery
- Live Connect
- Reporting Services en local
- Incorporation
Contenu connexe
Pour plus d’informations, consultez l’article suivant :
- Qu’est-ce que Power BI Desktop ?
- Présentation des requêtes dans Power BI Desktop
- Sources de données dans Power BI Desktop
- Connexion à des sources de données dans Power BI Desktop
- Tutoriel : Mettre en forme et combiner des données dans Power BI Desktop
- Effectuer des tâches de requête courantes dans Power BI Desktop