Flux de données en streaming (préversion)
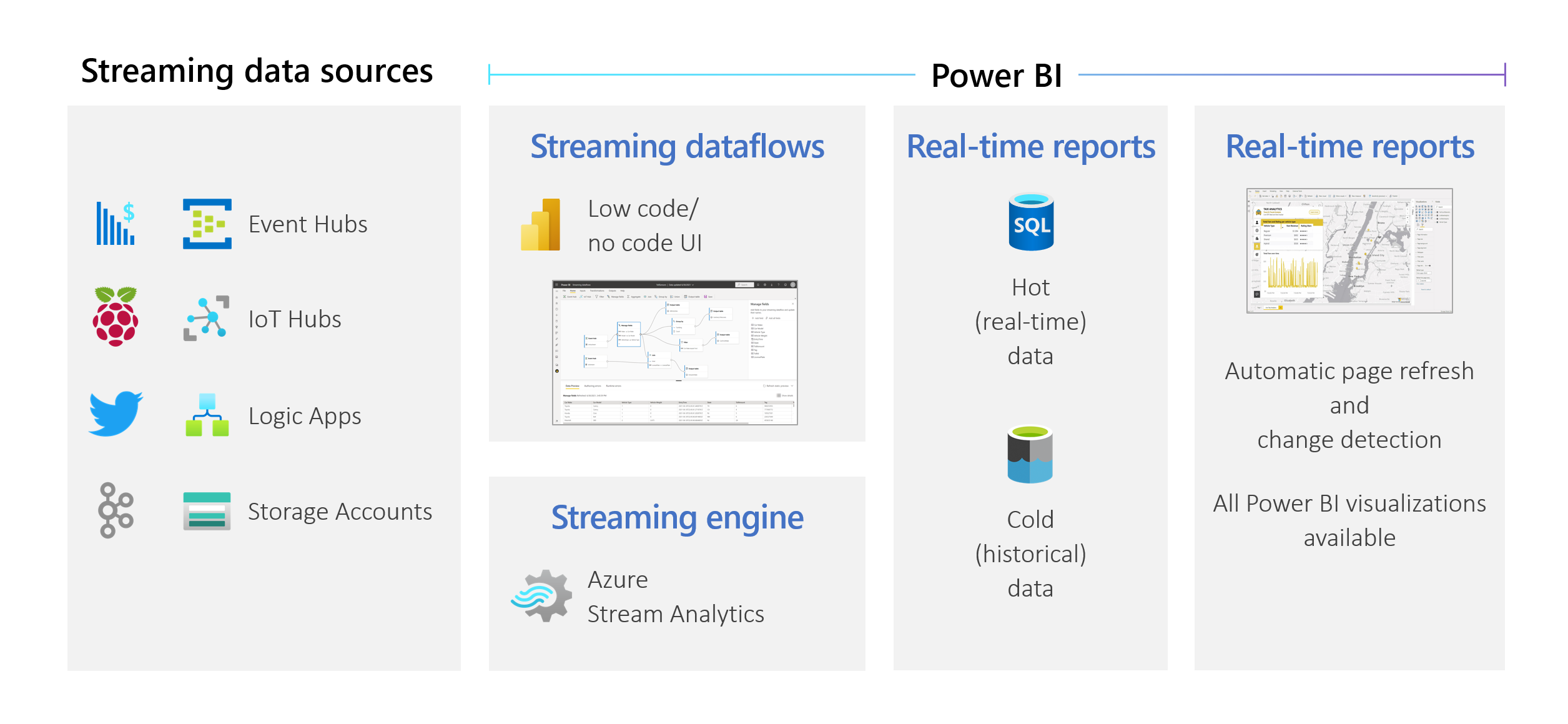
Les organisations souhaitent travailler avec les données à mesure qu’elles arrivent, non des jours ou des semaines plus tard. La vision de Power BI est simple : la distinction actuelle entre les données par lot, en temps réel et en streaming n’a pas lieu d’être. Les utilisateurs doivent pouvoir utiliser toutes les données dès qu’elles sont disponibles. Les analystes ont généralement besoin d’une aide technique pour gérer les sources de données en streaming, la préparation des données, les opérations complexes à durée définie et l’aperçu des données en temps réel. Les services informatiques s’appuient souvent sur des systèmes personnalisés et une combinaison de technologies de différents fournisseurs pour pouvoir effectuer en temps opportun des analyses sur les données. Sans cette complexité, ils ne peuvent pas fournir d’informations en quasi-temps réel aux décisionnaires.
Les flux de données en streaming permettent aux auteurs de se connecter à des données en streaming en quasi-temps réel, de les ingérer, les combiner et les modéliser, et de créer des rapports directement dans le service Power BI. Le service permet des expériences de type glisser-déplacer, sans code. Vous pouvez assortir des données en streaming avec des données par lot si vous avez besoin d’utiliser une interface utilisateur (IU) qui inclut une vue de diagramme pour faciliter le mélange des données. L’élément final produit est un flux de données qui peut être consommé en temps réel pour créer des rapports très interactifs en quasi-temps réel. Toutes les fonctionnalités de visualisation des données de Power BI se comportent de la même manière avec des données en streaming qu’avec des données par lot.
Important
Les flux de données en streaming ont été mis hors service et ne sont plus disponibles. Azure Stream Analytics a fusionné les fonctionnalités des flux de données en streaming. Pour plus d’informations sur la mise hors service des flux de données de streaming, consultez l’annonce de mise hors service.
 Les utilisateurs peuvent effectuer des opérations de préparation des données telles que des jointures et des filtres. Ils peuvent également effectuer des agrégations de fenêtre temporelle (par exemple, bascule, saut et fenêtres de session) pour les opérations group-by.
Les flux de données en streaming de Power BI aident les organisations à :
Les utilisateurs peuvent effectuer des opérations de préparation des données telles que des jointures et des filtres. Ils peuvent également effectuer des agrégations de fenêtre temporelle (par exemple, bascule, saut et fenêtres de session) pour les opérations group-by.
Les flux de données en streaming de Power BI aident les organisations à :
- prendre des décisions en quasi-temps réel : Les organisations peuvent se montrer plus agiles et prendre des mesures explicites sur la base d’insights actualisés.
- démocratiser les données en streaming : Les organisations peuvent rendre les données plus accessibles et plus faciles à interpréter avec une solution sans code. Cette accessibilité réduit les ressources informatiques.
- Accélérez le temps d’analyse grâce à une solution de bout en bout d’analytique en streaming avec stockage de données intégré et business intelligence.
Les flux de données en streaming prennent en charge DirectQuery et l’actualisation automatique des pages/la détection des modifications. Ce support permet aux utilisateurs de créer des rapports qui se mettent à jour en quasi-temps réel (potentiellement toutes les secondes) à l’aide de n’importe quel visuel disponible dans Power BI.
Configuration requise
Avant de créer votre premier flux de données en streaming, assurez-vous de remplir toutes les conditions suivantes :
Pour créer et exécuter un flux de données en streaming, vous avez besoin d’un espace de travail faisant partie d’une capacité Premium ou d’une licence Premium par utilisateur (PPU) .
Important
Si vous utilisez une licence PPU et que vous souhaitez que d’autres utilisateurs consomment des rapports créés avec des flux de données en streaming mis à jour en temps réel, ils ont également besoin d’une licence PPU. Ils peuvent ensuite consommer les rapports à la même fréquence d’actualisation que celle que vous avez configurée, si cette actualisation est inférieure à toutes les 30 minutes.
Activez les flux de données pour votre locataire. Pour plus d’informations, consultez Activation des flux de données dans Power BI Premium.
Le moteur de calcul avancé doit être activé pour que les flux de données en streaming fonctionnent dans votre capacité Premium. Le moteur est activé par défaut, mais les administrateurs de capacité Power BI peuvent le désactiver. Si c’est le cas, contactez votre administrateur pour l’activer.
Le moteur de calcul amélioré n’est disponible que dans les capacités Premium P, Embedded A3 et supérieures. Pour utiliser des flux de données en streaming, il vous faut une licence Premium par utilisateur, une capacité Premium P (quelle que soit sa taille) ou bien une capacité Embedded A3 ou supérieure. Pour plus d’informations sur les références SKU Premium et leurs spécifications, consultez Capacité et références SKU dans Power BI Embedded Analytics.
Pour créer des rapports qui sont mis à jour en temps réel, assurez-vous que votre administrateur (capacité ou Power BI pour PPU) a activé l’actualisation automatique des pages. Assurez-vous également que l’administrateur a autorisé un intervalle minimal d’actualisation qui correspond à vos besoins. Pour plus d’informations, consultez Actualisation automatique des pages dans Power BI.
Création d’un flux de données en streaming
Tout comme un flux de données classique, un flux de données en streaming consiste en une collection d’entités (tables) créées et gérées dans les espaces de travail du service Power BI. Une table est un ensemble de champs permettant de stocker des données, à l’instar d’une table dans une base de données.
Vous pouvez ajouter et modifier les tables de votre flux de données en streaming directement dans l’espace de travail où celui-ci a été créé. La principale différence avec les flux de données normaux est que vous n’avez pas besoin de vous soucier des actualisations ou de la fréquence. En raison de la nature des données de streaming, il y a un flux entrant continu. L’actualisation est constante ou infinie, sauf si vous l’arrêtez.
Notes
Il ne peut y avoir qu’un seul type de flux de données par espace de travail. Si vous disposez déjà d’un flux de données classique dans votre espace de travail Premium, vous ne pouvez pas créer de flux de données en streaming (et inversement).
Pour créer un flux de données en streaming :
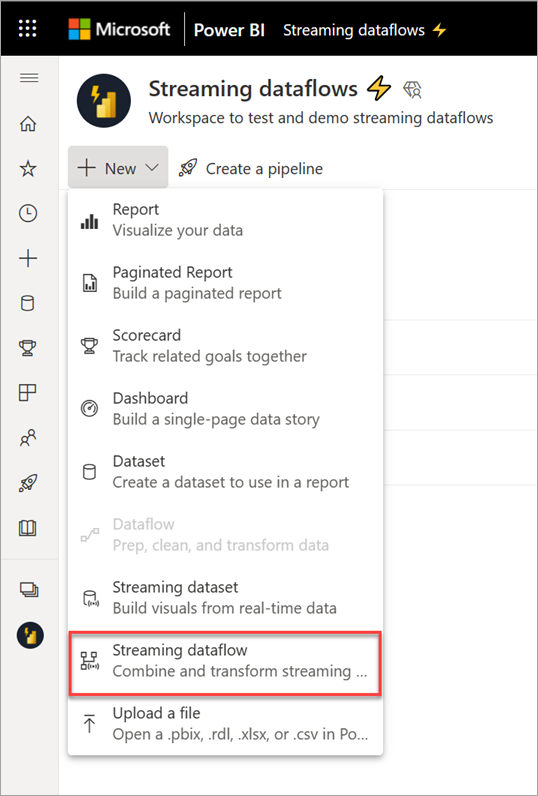
Ouvrez le service Power BI dans un navigateur, puis sélectionnez un espace de travail compatible Premium. (Les flux de données en streaming, comme les flux de données standard, ne sont pas disponibles dans Mon espace de travail.)
Sélectionnez le menu déroulant Nouveau, puis choisissez Flux de données en streaming.
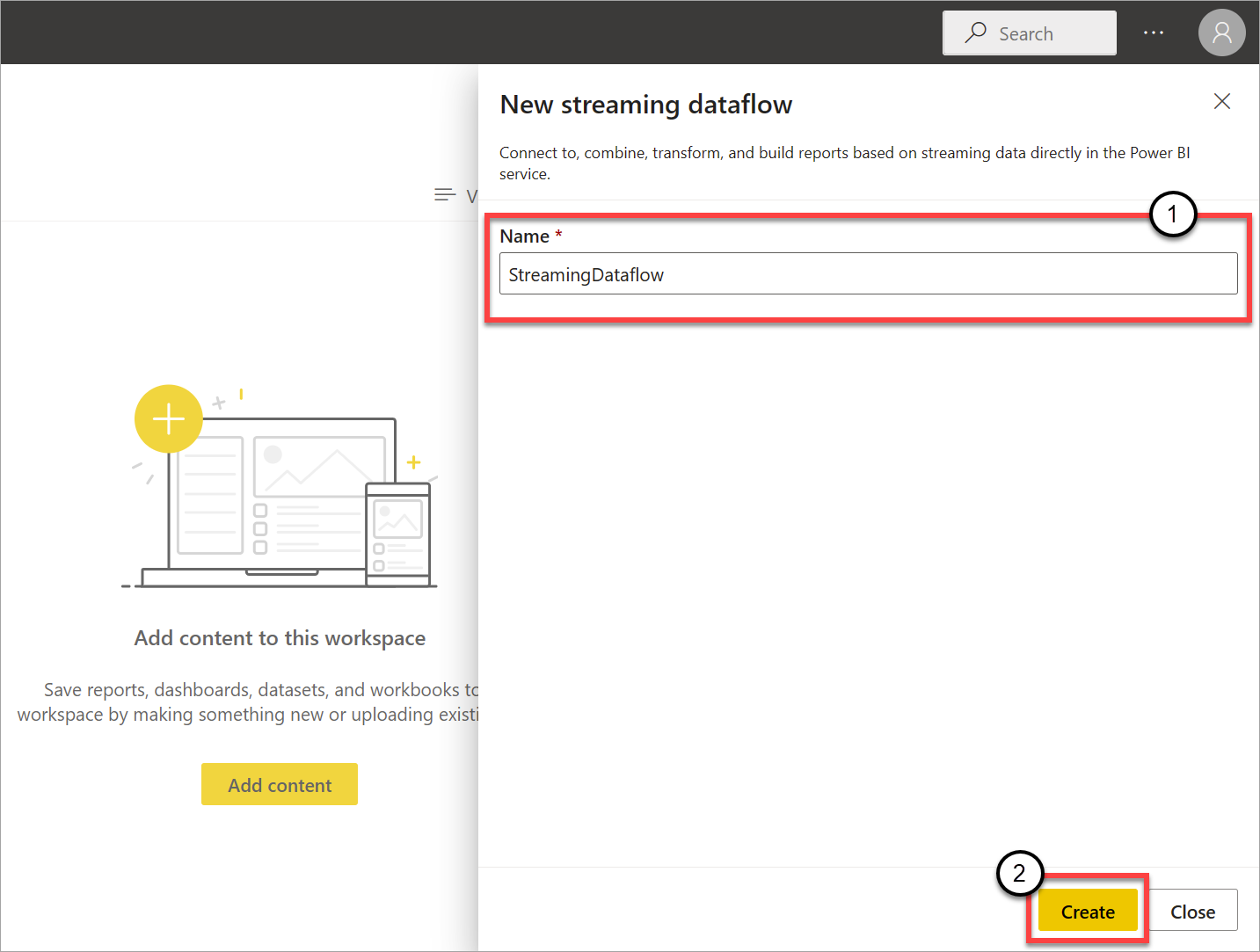
Dans le volet latéral qui s’ouvre, vous devez nommer votre flux de données en streaming. Entrez un nom dans la zone Nom (1), puis sélectionnez Créer (2).
L’affichage des diagrammes vide pour les flux de données en streaming s’affiche.
La capture d’écran suivante montre un flux de données terminé. Elle met en évidence toutes les sections à votre disposition pour la création dans l’interface utilisateur de flux de données en streaming.

Ruban : dans le ruban, les sections suivent l’ordre d’un processus d’analyse « classique » : les entrées (également appelées sources de données), les transformations (opérations ETL de streaming), les sorties et un bouton pour enregistrer votre progression.
Vue de diagramme : représentation graphique de votre flux de données, des entrées aux sorties en passant par les opérations.
Volet latéral : selon le composant sélectionné dans la vue de diagramme, il comprend des paramètres permettant de modifier chaque entrée, transformation et sortie.
Onglets d’aperçu des données, erreurs de création et erreurs d’exécution : pour chaque carte affichée, l’aperçu des données présente les résultats de cette étape (en direct pour les entrées et à la demande pour les transformations et les sorties).
Cette section résume également les éventuelles erreurs de création et les potentiels avertissements des flux de données. Sélectionnez une erreur ou un avertissement pour sélectionner cette transformation. Vous avez également accès aux erreurs d’exécution (par exemple les messages supprimés) après l’exécution du flux de données.
Vous pouvez toujours réduire cette section des flux de données en streaming en sélectionnant la flèche située dans le coin supérieur droit.
Un flux de données en streaming repose sur trois composants principaux : les entrées de streaming, les transformations et les sorties. Vous pouvez avoir autant de composants que vous le souhaitez, notamment plusieurs entrées, des branches parallèles comportant plusieurs transformations et plusieurs sorties.
Ajouter une entrée de streaming
Pour ajouter une entrée de streaming, sélectionnez l’icône dans le ruban et fournissez les informations nécessaires dans le volet latéral pour la configurer. À compter de juillet 2021, l’aperçu des flux de données en streaming prend en charge les entrées Azure Event Hubs et Azure IoT Hub.
Les services Azure Event Hubs et Azure IoT Hub s’appuient sur une architecture commune pour faciliter, accélérer et faire évoluer l’ingestion et la consommation d’événements. En particulier, IoT Hub est conçu comme un hub de messages central pour les communications bidirectionnelles entre une application IoT et les appareils attachés.
Azure Event Hubs
Azure Event Hubs est une plateforme de streaming de Big Data et un service d’ingestion d’événements. Il peut recevoir et traiter des millions d’événements par seconde. Les données envoyées à un Event Hub peuvent être transformées et stockées à l’aide de n’importe quel fournisseur d’analyse en temps réel. Vous pouvez également utiliser le traitement par lot ou des adapteurs de stockage.
Pour configurer un Event Hub en tant qu’entrée pour les flux de données en streaming, sélectionnez l’icône Event Hub. Une carte apparaît dans l’affichage des diagrammes, y compris un volet latéral pour sa configuration.
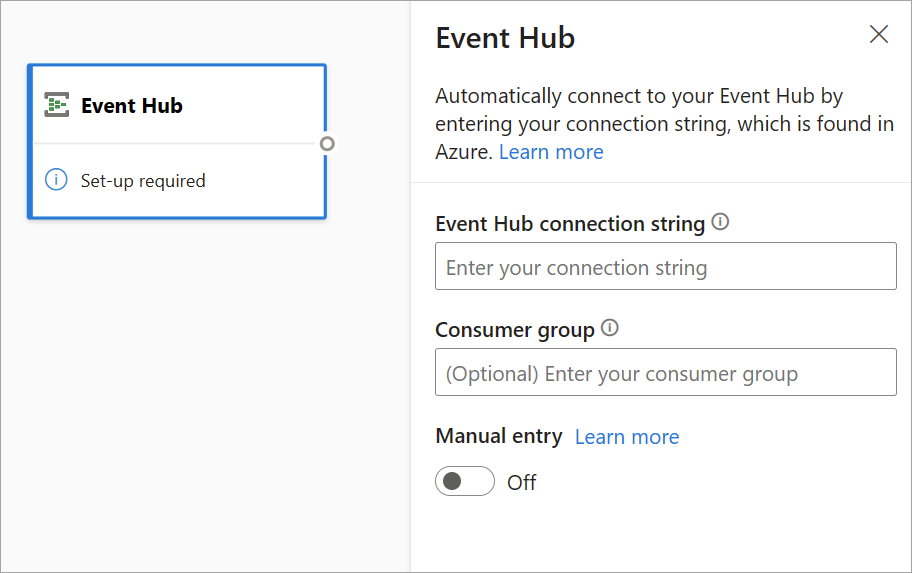
Vous avez la possibilité de coller la chaîne de connexion Event Hubs. Les flux de données en streaming remplissent toutes les informations nécessaires, y compris le groupe de consommateurs facultatif (par défaut $Default). Si vous souhaitez entrer tous les champs manuellement, vous pouvez activer le bouton bascule d’entrée manuelle pour les spécifier. Pour plus d’informations, consultez Obtenir une chaîne de connexion Event Hubs.
Après avoir configuré vos informations d’identification Event Hubs et sélectionné Connecter, vous pouvez ajouter des champs manuellement à l’aide de l’option + Ajouter un champ si vous connaissez les noms de champs. Vous pouvez également détecter automatiquement les types de champs et de données en fonction d’un échantillon des messages entrants. Pour cela, sélectionnez Détection automatique des champs. Sélectionnez l’icône d’engrenage pour modifier les informations d’identification si nécessaire.
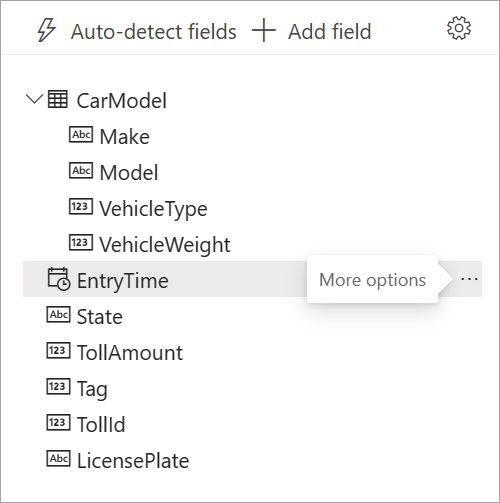
Les champs apparaissent dans la liste à mesure que les flux de données en streaming les détectent. Par ailleurs, un aperçu instantané des messages entrants s’affiche dans la table Aperçu des données sous la vue de diagramme.
Vous pouvez toujours modifier le nom des champs et supprimer ou modifier le type de données en sélectionnant Plus d’options (...) situé à côté de chaque champ. Vous avez également la possibilité de développer, de sélectionner et de modifier les champs imbriqués des messages entrants, comme illustré sur l’image suivante.
Azure IoT Hub
IoT Hub est un service géré hébergé dans le cloud. Il joue le rôle de hub de messages central pour les communications bidirectionnelles entre une application IoT et ses appareils attachés. Vous pouvez connecter des millions d’appareils et leurs solutions back-end de manière fiable et sécurisée. Presque tous les appareils peuvent être connectés à un hub IoT.
La configuration d’IoT Hub est similaire à celle d’Event Hubs en raison de leur architecture commune. Il existe toutefois quelques différences, notamment l’emplacement où trouver la chaîne de connexion compatible Event Hubs pour le point de terminaison intégré. Pour plus d’informations, consultez Lire des messages appareil-à-cloud à partir du point de terminaison intégré.
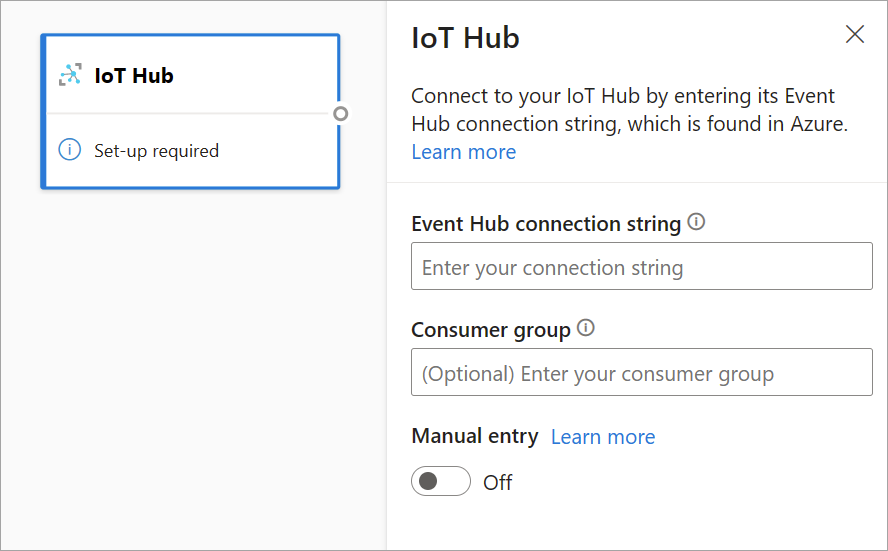
Une fois que vous collez la chaîne de connexion du point de terminaison intégré, toutes les fonctionnalités de sélection, d’ajout, de détection automatique et de modification des champs provenant d’IoT Hub sont les mêmes que dans Event Hubs. Vous pouvez également modifier les informations d’identification en sélectionnant l’icône d’engrenage.
Conseil
Si vous avez accès à Event Hubs ou à IoT Hub sur le portail Azure de votre organisation et que vous souhaitez l’utiliser comme entrée de votre flux de données en streaming, vous trouverez les chaînes de connexion aux emplacements suivants :
Pour Event Hubs :
- Dans la section Analyse, sélectionnez Tous les services>Event Hubs.
- Sélectionnez Espace de noms Event Hubs>Entités/Event Hubs, puis sélectionnez le nom de l’Event Hub.
- Dans la liste Stratégies d’accès partagé, sélectionnez une stratégie.
- Sélectionnez Copier dans le presse-papiers en regard du champ Chaîne de connexion-clé principale.
Pour IoT Hub :
- Dans la section Internet des objets, sélectionnez Tous les services>IoT Hubs.
- Sélectionnez l’IoT Hub auquel vous souhaitez vous connecter, puis sélectionnez Points de terminaison intégrés.
- Sélectionnez Copier dans le presse-papiers en regard du point de terminaison compatible Event Hub.
Si vous utilisez des données en streaming provenant d’Event Hubs ou d’IoT Hub, vous avez accès aux champs de métadonnées temporelles suivants dans votre flux de données en streaming :
- EventProcessedUtcTime : date et heure de traitement de l’événement.
- EventEnqueuedUtcTime : date et heure de réception de l’événement.
Aucun de ces champs ne s’affiche dans l’aperçu de l’entrée. Vous devez les ajouter manuellement.
Stockage d'objets blob
Le stockage Blob Azure est la solution de stockage d’objet de Microsoft pour le cloud. Stockage Blob est optimisé pour le stockage d’immenses quantités de données non structurées. Les données non structurées sont des données qui n’obéissent pas à un modèle ou une définition de données en particulier, comme des données texte ou binaires.
Vous pouvez utiliser des objets blob Azure comme entrée de streaming ou de référence. Les mises à jour des objets blob de streaming sont vérifiées toutes les secondes. Contrairement à un objet blob de streaming, un objet blob de référence n’est chargé qu’au début de l’actualisation. Il s’agit de données statiques qui ne sont pas censées changer. La limite recommandée pour les données statiques est de 50 Mo.
Power BI s’attend à ce que les objets blob de référence soient utilisés avec des sources de streaming, par exemple, par le biais d’un JOIN. Par conséquent, un flux de données de streaming avec un objet blob de référence doit également comporter une source de streaming.
La configuration des objets blob Azure est légèrement différente de celle d’un nœud Azure Event Hubs. Pour rechercher votre chaîne de connexion d’objet blob Azure, consultez Afficher les clés d’accès au compte.
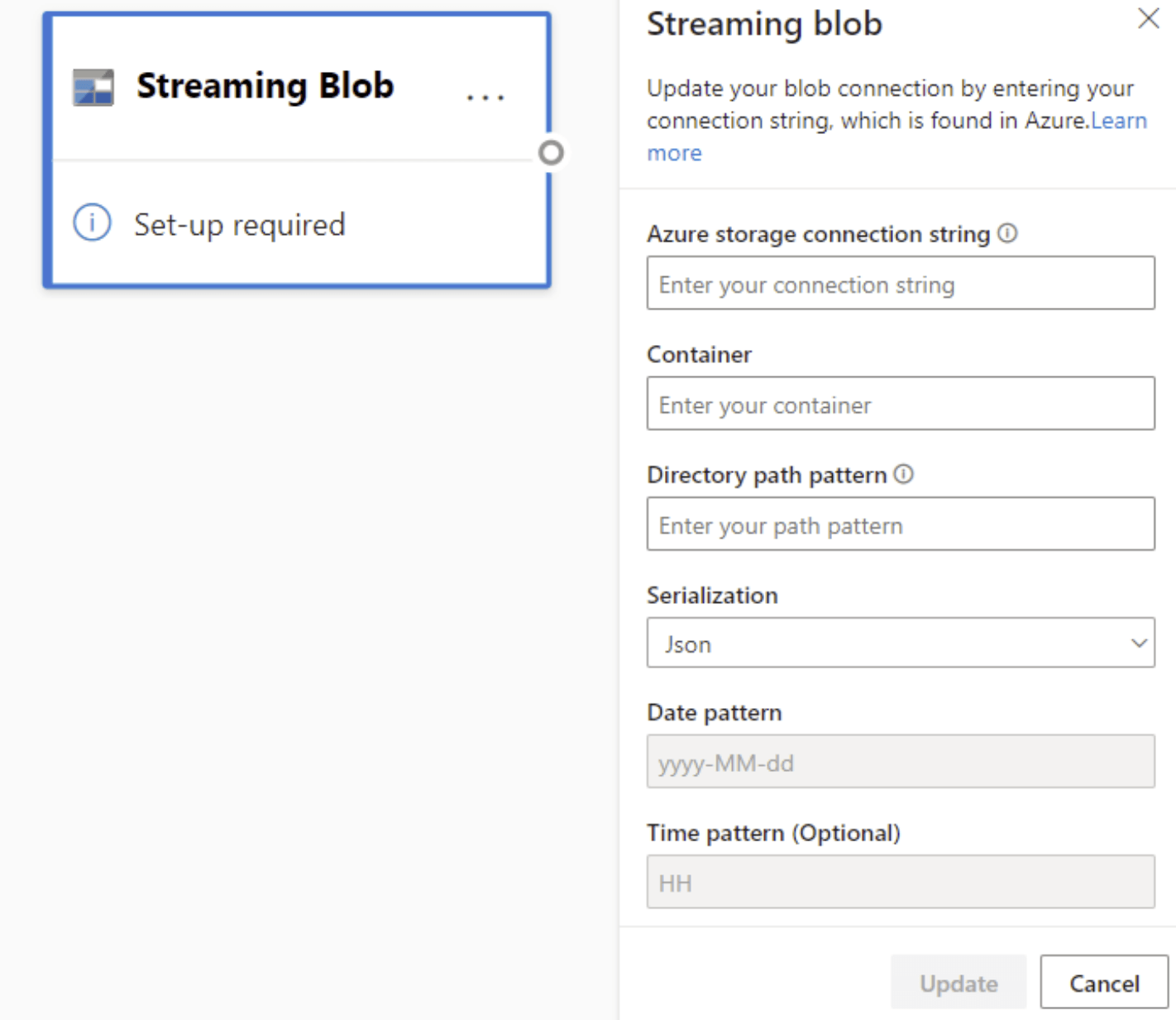
Après avoir entré la chaîne de connexion Blob, vous devez fournir le nom de votre conteneur. Vous devez également saisir le modèle de chemin d'accès dans votre répertoire pour accéder aux fichiers que vous voulez définir comme source de votre flux de données.
Pour les objets blob de streaming, le modèle de chemin de répertoire est censé être une valeur dynamique. La date doit faire partie du chemin de fichier de l’objet blob, sous la forme {date}. En outre, l’astérisque (*) dans le modèle de chemin d’accès, comme {date}/{time}/*.json, n’est pas pris en charge.
Imaginons un objet blob appelé ExampleContainer. Vous y stockez des fichiers .json imbriqués, où le premier niveau correspond à la date de création et le second à l’heure de création (par exemple, aaaa-mm-jj/hh). Votre entrée de conteneur serait « ExampleContainer ». Le modèle de chemin de répertoire « {date}/{time} » où vous pouvez modifier le modèle de date et d’heure.

Une fois l’objet blob connecté au point de terminaison, toutes les fonctionnalités de sélection, d’ajout, de détection automatique et de modification des champs provenant d’Azure Blob sont les mêmes que dans Event Hubs. Vous pouvez également modifier les informations d’identification en sélectionnant l’icône d’engrenage.
Lorsque l’on travaille avec des données en temps réel, elles sont souvent condensées, et des identificateurs sont utilisés pour représenter l’objet. Un cas d’usage possible pour les objets blob peut également de servir de données de référence pour vos sources de streaming. Les données de référence vous permettent de joindre des données statiques à des données de streaming pour enrichir vos flux à des fins d’analyse. Pour illustrer l’utilité de cette fonctionnalité, vous pouvez installer des capteurs dans différents grands magasins pour mesurer le nombre de personnes entrant dans le magasin à un moment donné. En règle générale, l’ID de capteur doit être joint à une table statique pour indiquer dans quel grand magasin et à quel emplacement se trouve le capteur. Avec les données de référence, il est possible de joindre ces données pendant la phase d’ingestion pour permettre d’identifier plus facilement le magasin présentant le plus grand nombre d’utilisateurs.
Notes
Un travail de flux de données en streaming extrait des données d’une entrée Stockage Blob Azure ou ADLS Gen2 toutes les secondes si le fichier blob est disponible. Si le fichier blob n’est pas disponible, il existe une interruption exponentielle avec un délai maximal de 90 secondes.
Types de données
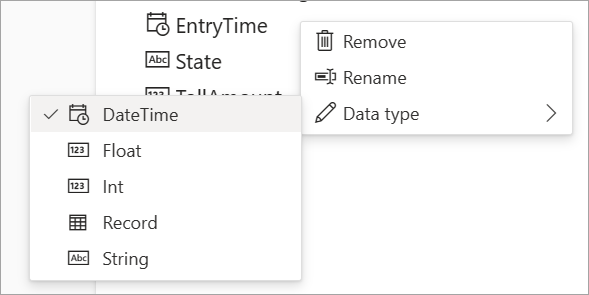
Les types de données disponibles pour les champs des flux de données en streaming incluent :
- DateHeure : date et heure au format ISO
- Flottant : nombre décimal
- Entier : nombre entier
- Enregistrement : objet imbriqué comportant plusieurs enregistrements
- Chaîne : texte
Important
Les types de données sélectionnés pour une entrée de streaming ont des implications importantes en aval de vos flux de données en streaming. Sélectionnez le type de données le plus tôt possible dans votre flux de données afin de ne pas avoir à l’arrêter ultérieurement pour le modifier.
Ajouter une transformation de données de streaming
Les transformations de données de streaming sont fondamentalement différentes des transformations de données par lots. Quasiment toutes les données de streaming comprennent un composant de temps, qui affecte les tâches de préparation des données impliquées.
Pour ajouter une transformation de données de streaming à votre flux de données, sélectionnez l’icône de transformation sur le ruban pour cette transformation. La carte correspondante apparaît dans la vue de diagramme. Lorsque vous la sélectionnez, vous voyez apparaître le volet latéral permettant de configurer cette transformation.
À compter de juillet 2021, les flux de données en streaming prennent en charge les transformations en streaming suivantes.
Filtrer
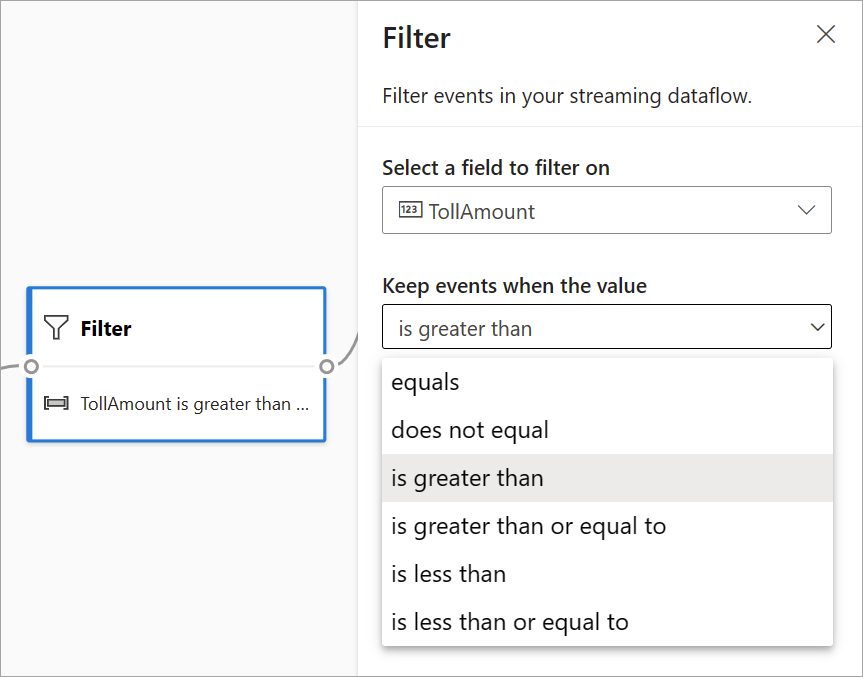
Utilisez la transformation Filtrer pour filtrer les événements en fonction de la valeur d’un champ dans l’entrée. Selon le type de données (nombre ou texte), la transformation conserve les valeurs qui correspondent à la condition sélectionnée.
Notes
À l’intérieur de chaque carte figurent des informations sur les autres éléments requis pour que la transformation soit prête. Par exemple, le message « Configuration obligatoire » apparaît lorsque vous ajoutez une nouvelle carte. S’il vous manque un connecteur de nœud, vous verrez un message « Erreur » ou « Avertissement ».
Gérer les champs
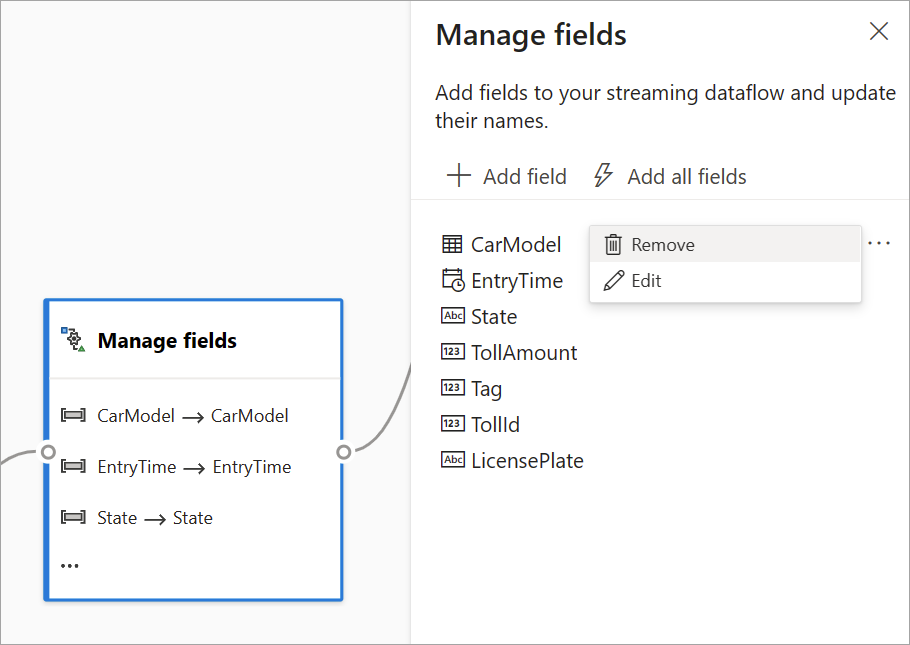
La transformation Gestion des champs permet d’ajouter, de supprimer et de renommer des champs provenant d’une entrée ou d’une autre transformation. Les paramètres dans le volet latéral vous donnent la possibilité d’en ajouter un nouveau en sélectionnant Ajouter un champ ou d’ajouter tous les champs à la fois.
Conseil
Après avoir configuré la carte, un aperçu des paramètres apparaît à l’intérieur de la carte proprement dite dans l’affichage des diagrammes. Par exemple, vous pouvez voir dans la zone Gestion des champs de l’image précédente les trois premiers champs gérés et les nouveaux noms qui leur sont attribués. Chaque carte contient des informations correspondantes.
Agrégat
Vous pouvez utiliser la transformation Agrégation pour calculer une agrégation (Somme, Minimum, Maximum ou Moyenne) chaque fois qu’un nouvel événement se produit sur une période donnée. Cette opération vous offre également la possibilité de filtrer ou de découper l’agrégation en fonction d’autres dimensions de vos données. Il peut y avoir plusieurs agrégations dans la même transformation.
Pour ajouter une agrégation, sélectionnez l’icône de transformation. Ensuite, connectez une entrée, sélectionnez l’agrégation, ajoutez des dimensions de filtre ou de tranche, puis choisissez la période pendant laquelle vous souhaitez calculer l’agrégation. Dans cet exemple, nous calculons la somme de la valeur de péage en fonction de l’État dans lequel le véhicule se trouve au cours des 10 dernières secondes.
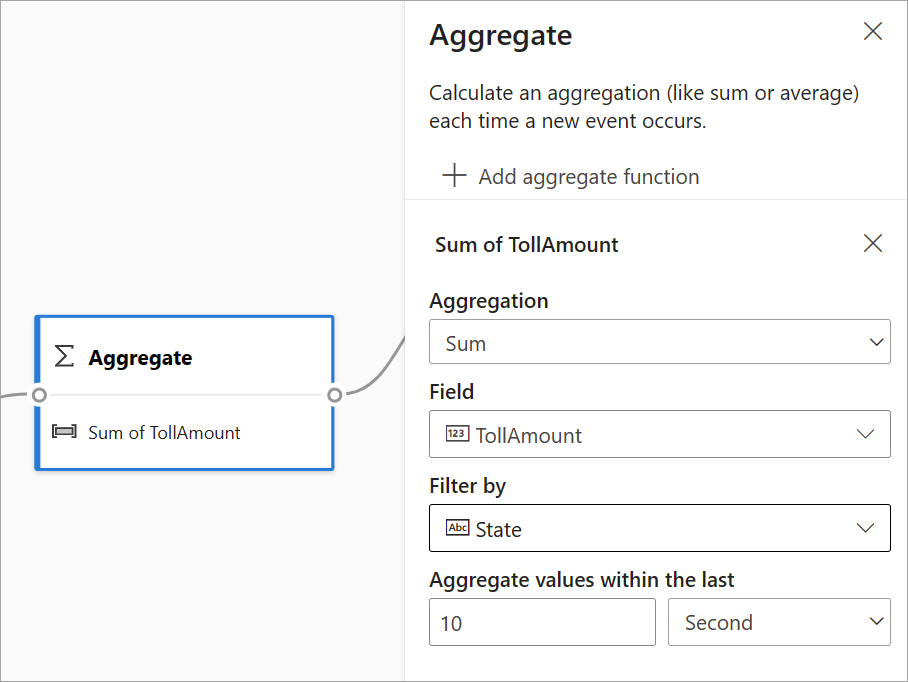
Pour ajouter une autre agrégation à la même transformation, sélectionnez Ajouter une fonction d’agrégation. Gardez à l’esprit que le filtre ou la tranche s’applique à toutes les agrégations de la transformation.
Join
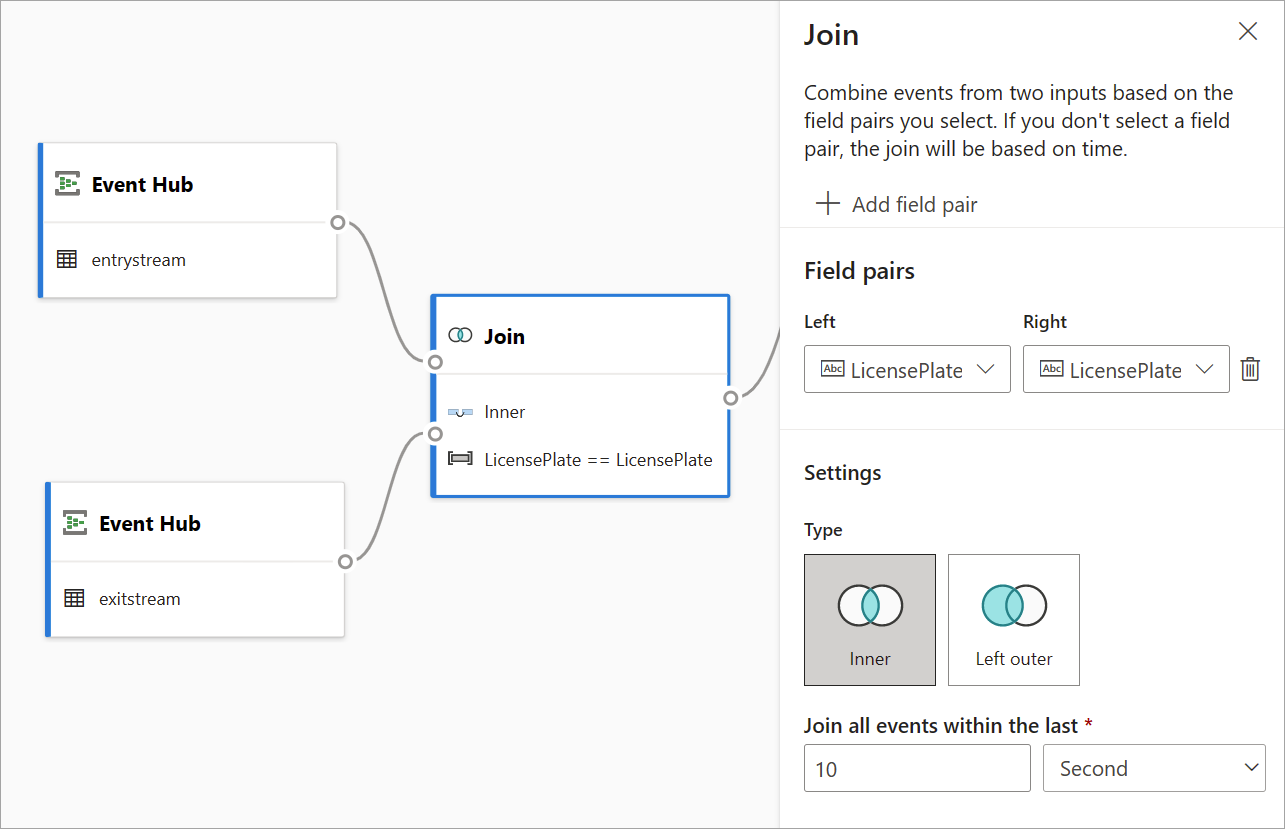
Utilisez la transformation Jointure pour combiner des événements de deux entrées en fonction des paires de champs que vous sélectionnez. Si vous ne sélectionnez pas de paire de champs, la jointure est basée par défaut sur l’heure. La valeur par défaut est ce qui rend cette transformation différente de celle d’un lot.
Comme avec les jointures classiques, vous disposez de différentes options pour votre logique de jointure :
- Jointure interne : inclure uniquement les enregistrements des deux tables correspondant à la paire. Dans cet exemple, où la plaque de licence correspond aux deux entrées.
- Jointure externe gauche : inclure tous les enregistrements de la table de gauche (la première) et uniquement les enregistrements de la deuxième table correspondant à la paire de champs. Si aucune correspondance n’est trouvée, les champs de la deuxième entrée sont vides.
Pour sélectionner le type de jointure, sélectionnez l’icône correspondant au type préféré dans le volet latéral.
Enfin, sélectionnez la période sur laquelle la jointure doit être calculée. Dans cet exemple, les 10 dernières secondes sont examinées. Gardez à l’esprit que, plus la période est longue, moins la sortie est fréquente et plus les ressources de traitement utilisées pour la transformation seront importantes.
Par défaut, tous les champs des deux tables sont inclus. Les préfixes à gauche (premier nœud) et à droite (second nœud) dans la sortie vous aident à différencier la source.
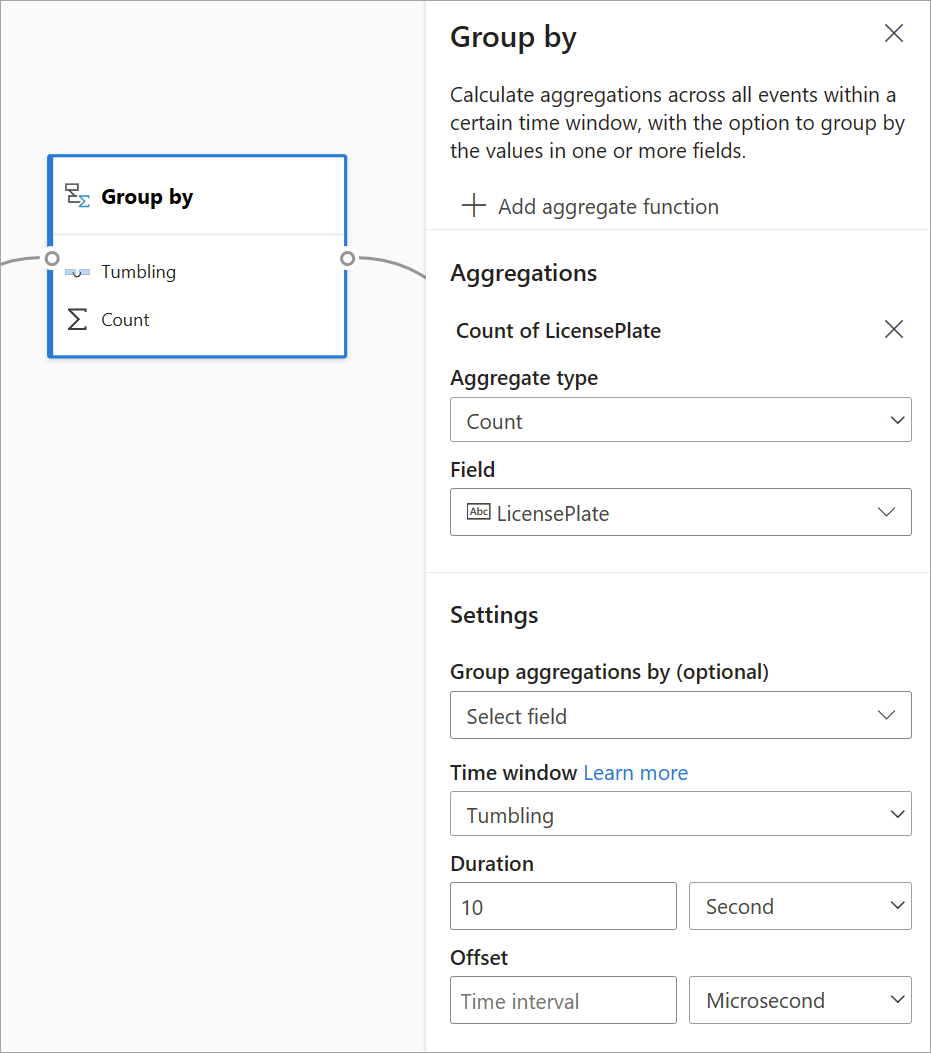
Regrouper par
Utilisez la transformation Regrouper par pour calculer les agrégations sur tous les événements d’une fenêtre de temps donnée. Vous pouvez regrouper par les valeurs d’un ou plusieurs champs. Elle est similaire à la transformation Agrégation, mais fournit plus d’options pour les agrégations. Elle comprend également des options de fenêtre de temps plus complexes. Comme avec Agrégation, il est possible d’ajouter plusieurs agrégations par transformation.
Les agrégations disponibles dans cette transformation sont les suivantes : Moyenne, Nombre, Maximum, Minimum, Centile (continu et discret), Écart type, Somme et Variance.
Pour configurer cette transformation :
- Sélectionnez votre agrégation par défaut.
- Choisissez le champ sur lequel vous souhaitez effectuer l’agrégation.
- Sélectionnez un champ group-by si vous souhaitez obtenir le calcul d’agrégation sur une autre dimension ou catégorie (par exemple, État).
- Choisissez votre fonction pour les fenêtres de temps.
Pour ajouter une autre agrégation à la même transformation, sélectionnez Ajouter une fonction d’agrégation. Gardez à l’esprit que le champ Regrouper par et la fonction de fenêtrage s’appliquent à toutes les agrégations de la transformation.
Un horodatage de fin de la fenêtre de temps est fourni à titre indicatif dans la sortie de la transformation.
Une section plus loin dans cet article explique chaque type de fenêtre de temps disponible pour cette transformation.
Union
Utilisez la transformation Union pour connecter deux entrées ou plus afin d’ajouter des événements comportant des champs partagés (même nom et même type de données) dans une table. Les champs qui ne correspondent pas ne sont pas inclus dans la sortie.
Configurer des fonctions de fenêtre de temps
Les fenêtres de temps constituent l’un des concepts les plus complexes du streaming de données. Ce concept se trouve au cœur de l’analyse du streaming.
Avec les flux de données en streaming, vous pouvez configurer des fenêtres de temps lorsque vous agrégez des données en tant qu’option pour la transformation Regrouper par.
Notes
Gardez à l’esprit que les résultats de sortie de toutes les opérations de fenêtrage sont calculés à la fin de la fenêtre de temps. La sortie de la fenêtre sera un événement unique qui dépend de la fonction d’agrégation. Cet événement possède l’horodatage de fin de la fenêtre et toutes les fonctions de fenêtrage sont définies avec une longueur fixe.
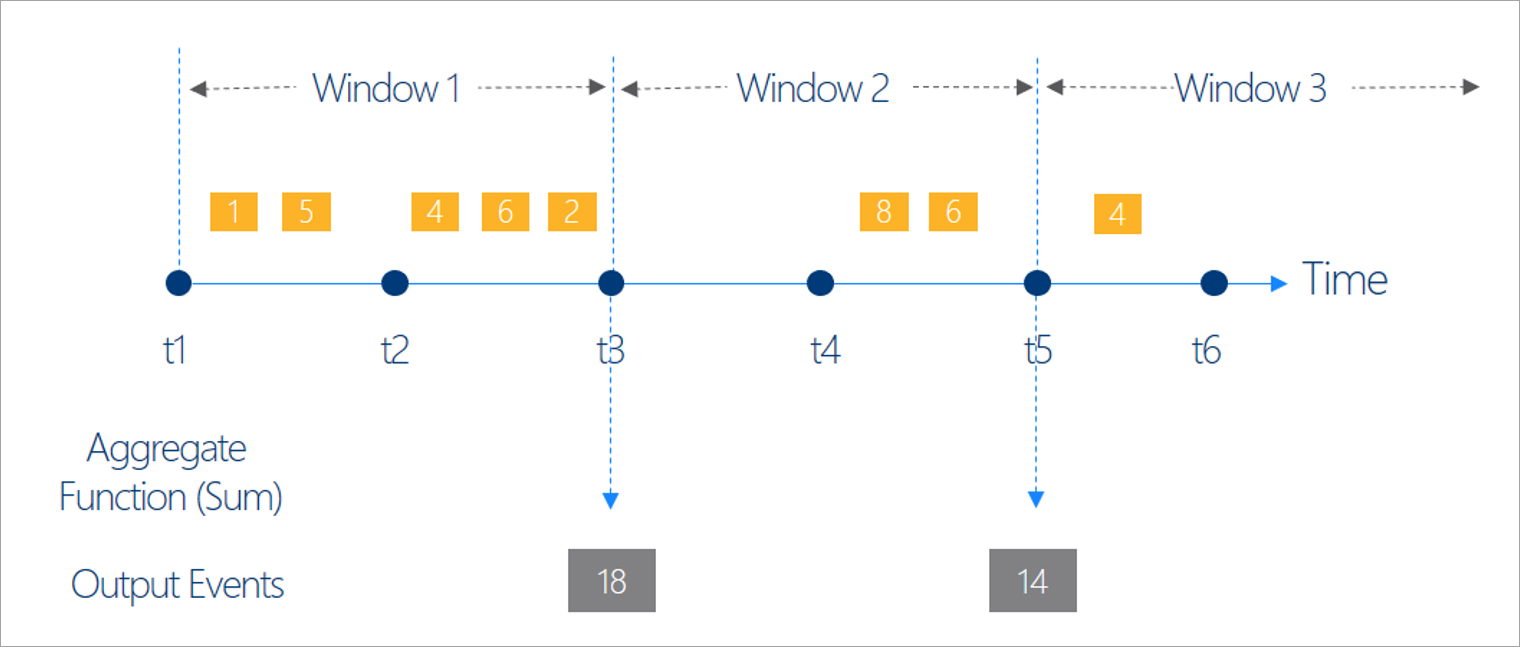
Vous avez le choix entre cinq types de fenêtres de temps : bascule, saut, glissement, session et instantané.
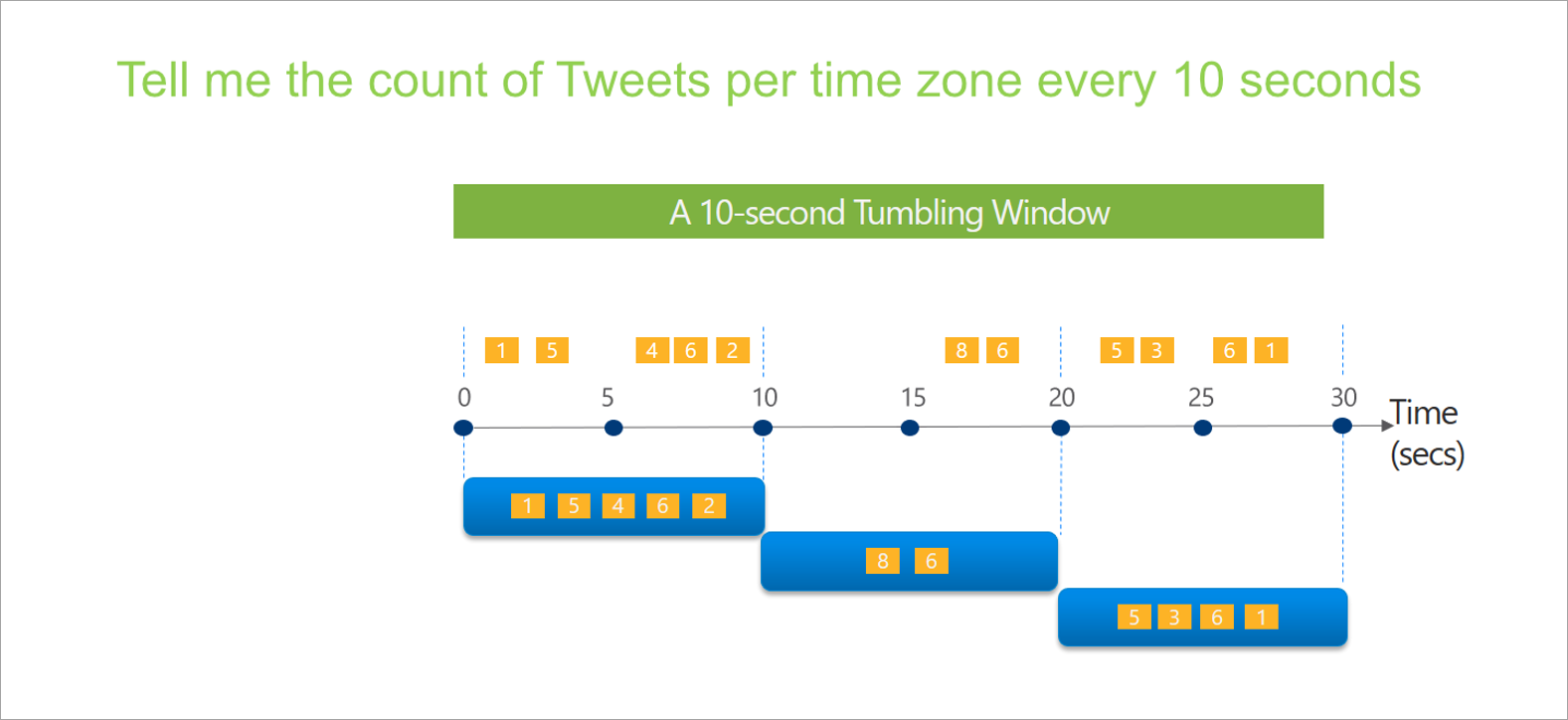
Fenêtre bascule
La bascule est le type le plus courant de fenêtre de temps. Les principales caractéristiques des fenêtres bascules sont qu’elles se répètent, ont la même durée et ne se chevauchent pas. Un événement ne peut pas appartenir à plus d’une fenêtre bascule.
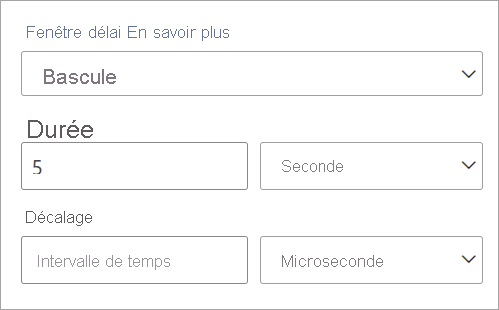
Lorsque vous configurez une fenêtre bascule dans des flux de données en streaming, vous devez indiquer la durée de la fenêtre (même chose pour toutes les fenêtres dans ce cas). Vous pouvez également spécifier un décalage (facultatif). Par défaut, la fin de la fenêtre bascule est incluse et le début exclu. Vous pouvez utiliser ce paramètre pour modifier ce comportement, en incluant les événements du début de la fenêtre et en excluant ceux à la fin.
Fenêtre récurrente
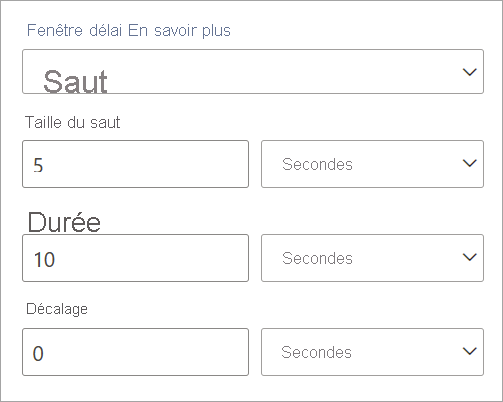
Les fenêtres récurrentes effectuent un « saut » dans le temps d’une période fixe. Vous pouvez les considérer comme des fenêtres bascules qui peuvent se chevaucher et être émises plus souvent que la taille de la fenêtre. Les événements peuvent appartenir à plus d’un jeu de résultats pour une fenêtre récurrente. Pour créer une fenêtre récurrente identique à une fenêtre bascule, vous pouvez spécifier une taille de saut égale à celle de la fenêtre.
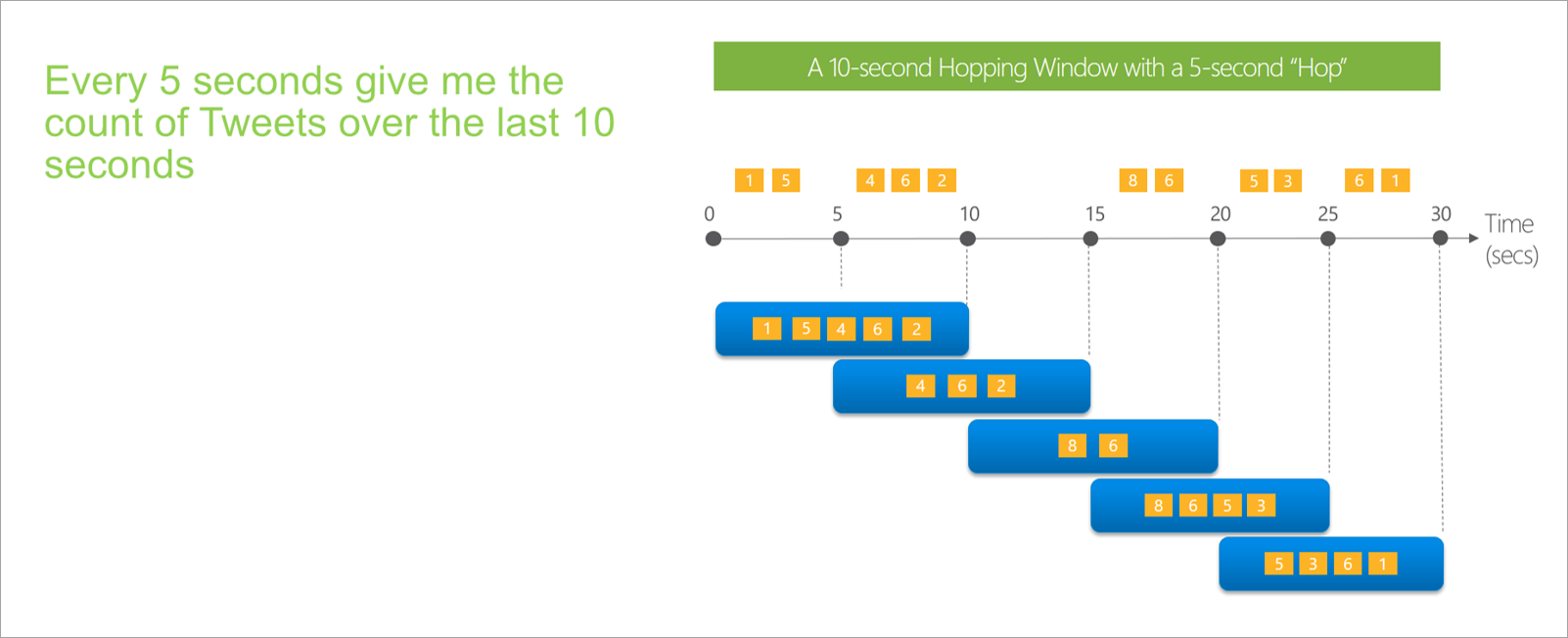
Lorsque vous configurez une fenêtre récurrente dans des flux de données en streaming, vous devez spécifier la durée de la fenêtre (même chose que pour les fenêtres bascules). Vous devez également spécifier la taille de saut, qui indique aux flux de données en streaming la fréquence à laquelle vous souhaitez que l’agrégation soit calculée pour la durée définie.
Le paramètre de décalage est également disponible dans les fenêtres de saut pour la même raison que les fenêtres bascules. Il définit la logique d’inclusion et d’exclusion d’événements pour le début et la fin de la fenêtre de saut.
Fenêtre glissante
À la différence des fenêtres bascules et des fenêtres récurrentes, les fenêtres glissantes ne calculent l’agrégation que pour les points dans le temps où le contenu de la fenêtre change réellement. Lorsqu’un événement entre dans la fenêtre ou en sort, l’agrégation est calculée. Par conséquent, chaque fenêtre affiche au moins un événement. Comme pour les fenêtres récurrentes, les événements peuvent appartenir à plusieurs fenêtres glissantes.
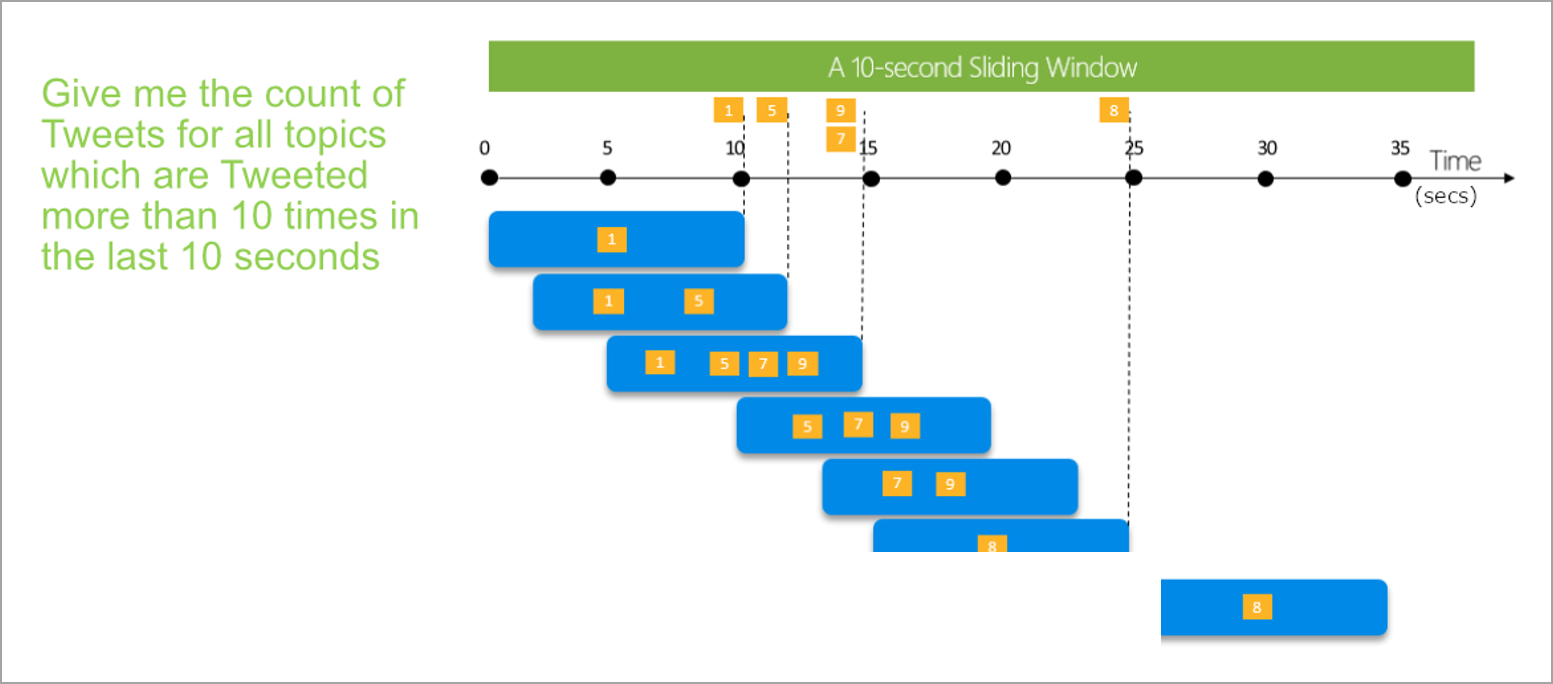
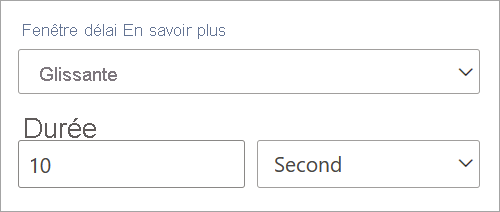
Le seul paramètre dont vous avez besoin pour une fenêtre glissante est la durée, car ce sont les événements eux-mêmes qui définissent le début de la fenêtre. Aucune logique de décalage n’est nécessaire.
Fenêtre session
Les fenêtres de session constituent le type le plus complexe. Elles regroupent les événements qui arrivent à peu près au même moment, en filtrant les périodes de temps où il n’existe aucune donnée. Pour cela, il est nécessaire de fournir les éléments suivants :
- Délai d’attente : durée d’attente en l’absence de nouvelles données.
- Durée maximale : durée de calcul de l’agrégation la plus longue si des données continuent à affluer.
Si vous le souhaitez, vous pouvez également définir une partition.
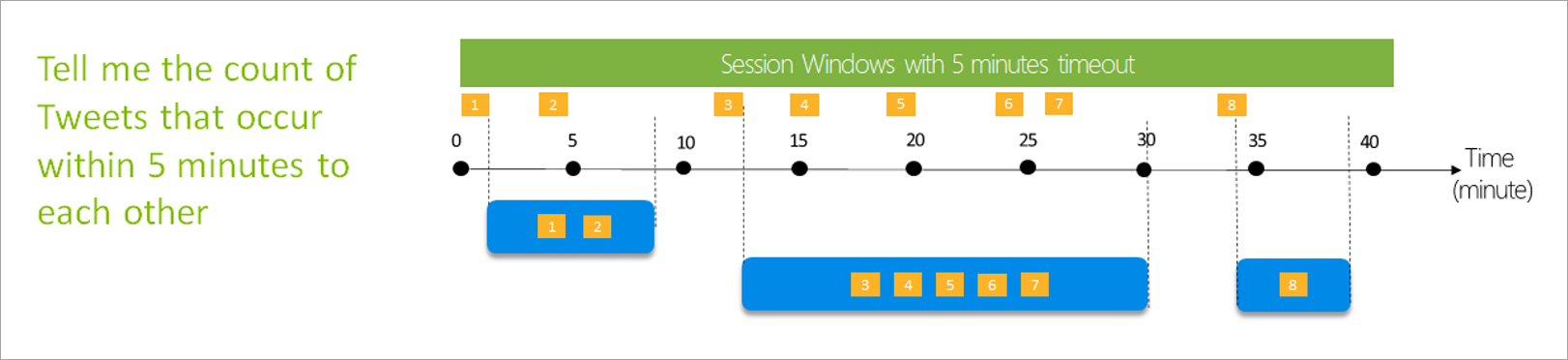
Vous configurez une fenêtre de session directement dans le volet latéral de la transformation. Si vous indiquez une partition, l’agrégation ne regroupe que les événements de la même clé.
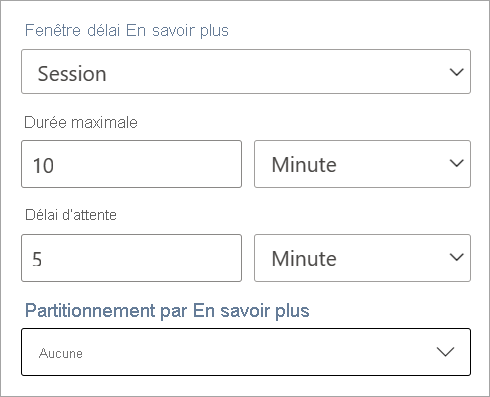
Fenêtre d’instantané
Les fenêtres d’instantanés regroupent les événements qui ont le même horodatage. Contrairement aux autres fenêtres, un instantané ne nécessite aucun paramètre, car il utilise l’heure du système.
Définir les sorties
Après avoir configuré les entrées et les transformations, il vous reste à définir une ou plusieurs sorties. Depuis juillet 2021, les flux de données en streaming prennent en charge les tables Power BI comme seul type de sortie.
Cette sortie correspond à une table de flux de données (à savoir une entité) que vous pouvez utiliser pour créer des rapports dans Power BI Desktop. Vous devez joindre les nœuds de l’étape précédente avec la sortie que vous créez pour qu’elle fonctionne. Ensuite, donnez un nom à la table.
Lorsque la connexion avec votre flux de données est établie, cette table est disponible pour vous permettre de créer des visuels qui se mettent à jour en temps réel dans vos rapports.
Aperçu des données et erreurs
Les flux de données en streaming fournissent des outils pour vous aider à créer un pipeline d’analyse, à résoudre ses problèmes et à évaluer son niveau de performance pour les données de streaming.
Aperçu instantané des données pour les entrées
Lorsque vous vous connectez à un Event Hub ou hub IoT et que vous sélectionnez sa carte dans la vue de diagramme (l’onglet Aperçu des données), vous obtenez un aperçu instantané des données entrantes si toutes les conditions suivantes sont remplies :
- Les données sont en cours de transmission de type push.
- L’entrée est configurée correctement.
- Des champs ont été ajoutés.
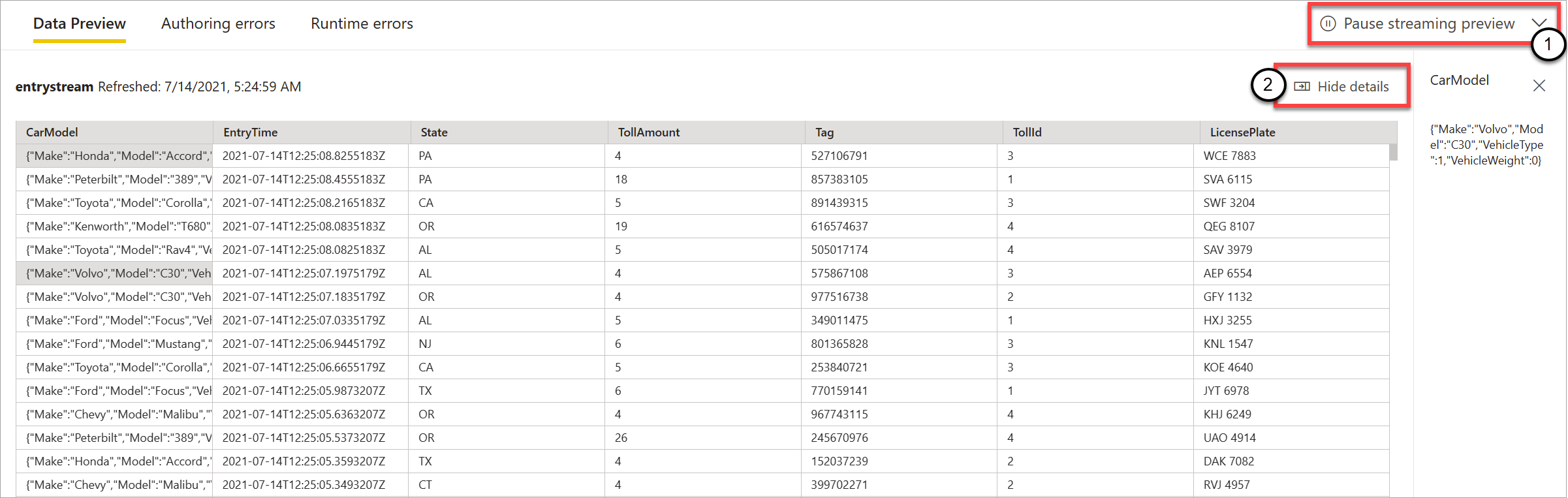
Comme illustré dans la capture d’écran suivante, si vous souhaitez afficher ou accéder à une section spécifique, vous pouvez suspendre l’aperçu (1). Vous pouvez également le redémarrer si vous avez terminé.
Vous pouvez également afficher les détails d’un enregistrement spécifique (une « cellule » dans la table) en le sélectionnant, puis en sélectionnant Afficher les détails ou Masquer les détails (2). La capture d’écran montre la vue détaillée d’un objet imbriqué dans un enregistrement.
Aperçu statique pour les transformations et les sorties
Une fois que vous avez ajouté et configuré des étapes dans la vue de diagrammes, vous pouvez tester leur comportement en sélectionnant le bouton de données statiques.

Les flux de données en streaming évaluent ensuite si toutes les transformations et sorties sont configurées correctement. Les flux de données en streaming affichent alors les résultats dans l’aperçu des données statique, comme illustré dans l’image suivante.
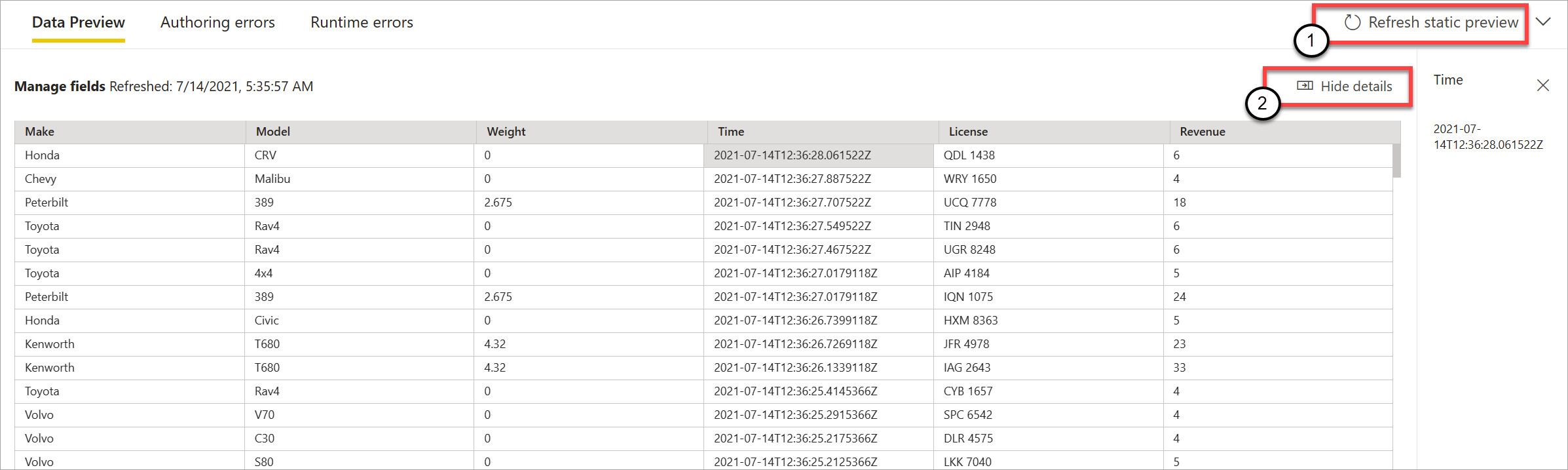
Vous pouvez actualiser l’aperçu en sélectionnant Actualiser l’aperçu statique (1). Lorsque vous procédez ainsi, les flux de données de diffusion en continu prennent de nouvelles données à partir de l’entrée et évaluent à nouveau toutes les transformations et sorties avec toutes les mises à jour que vous pouvez effectuer. L’option Afficher ou masquer les détails est également disponible (2).
Erreurs de création
Si vous avez des erreurs ou des avertissements de création, l’onglet Erreurs de création (1) les répertorie, comme illustré dans la capture d’écran suivante. La liste inclut les détails de l’erreur ou de l’avertissement, le type de carte (entrée, transformation ou sortie), le niveau d’erreur et une description de l’erreur ou de l’avertissement (2). Lorsque vous sélectionnez l’une des erreurs ou l’un des avertissements, la carte correspondante est sélectionnée, et le volet latéral de configuration s’ouvre pour vous permettre d’apporter les modifications nécessaires.

Erreurs d’exécution
Le dernier onglet disponible dans l’aperçu est Erreurs d’exécution (1), comme illustré dans la capture d’écran suivante. Cet onglet répertorie toutes les erreurs dans le processus d’ingestion et d’analyse du flux de données en streaming après son démarrage. Par exemple, vous pouvez obtenir une erreur d’exécution si un message entrant est endommagé et que le flux de données n’a pas pu l’ingérer et effectuer les transformations définies.
Étant donné que les flux de données peuvent s’exécuter pendant une longue période, cette table offre la possibilité de filtrer sur un intervalle de temps, de télécharger la liste d’erreurs et de l’actualiser si nécessaire (2).

Modifier les paramètres des flux de données en streaming
Comme pour les flux de données classiques, les paramètres des flux de données en streaming peuvent être modifiés en fonction des besoins des propriétaires et des auteurs. Les paramètres suivants sont propres aux flux de données en streaming. Pour les paramètres restants, vous pouvez supposer que l’utilisation est la même en raison de l’infrastructure commune aux deux types de flux de données.
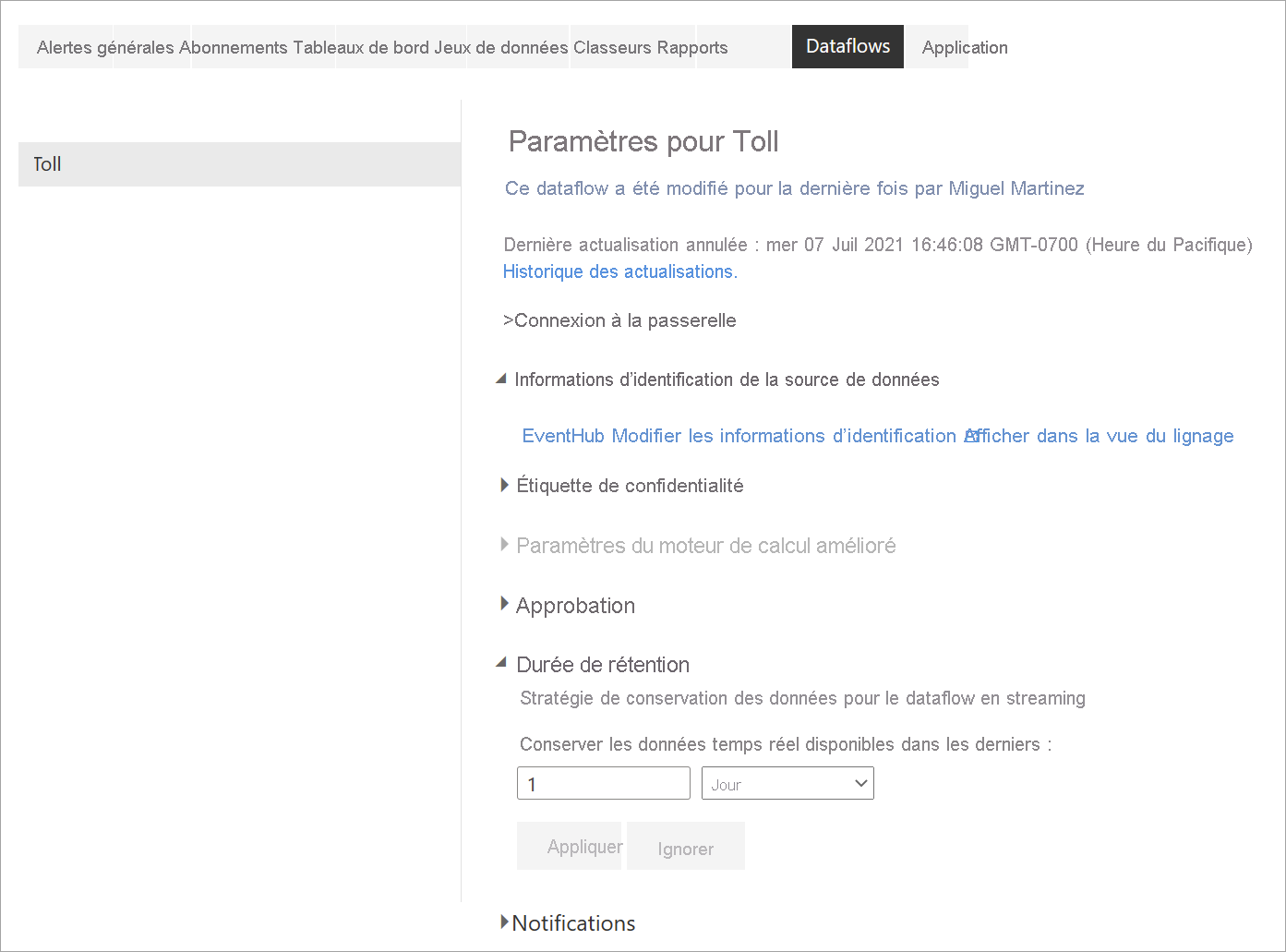
Historique des actualisations : étant donné que les flux de données en streaming s’exécutent en continu, l’historique des actualisations affiche uniquement des informations sur le moment où le flux de données est lancé, est annulé ou échoue (avec des détails et des codes d’erreur le cas échéant). Ces informations sont similaires à celles qui s’affichent pour les flux de données classiques. Vous pouvez utiliser ces informations pour résoudre les problèmes ou fournir au support de Power BI les détails demandés.
Informations d’identification de la source de données : ce paramètre affiche les entrées qui ont été configurées pour un flux de données en streaming spécifique.
Paramètres du moteur de calcul avancé : les flux de données en streaming ont besoin du moteur de calcul avancé pour fournir des visuels en temps réel. Ce paramètre est donc activé par défaut et ne peut pas être modifié.
Durée de rétention : ce paramètre est propre aux flux de données en streaming. Vous pouvez définir ici la durée pendant laquelle vous souhaitez conserver les données en temps réel qui apparaissent dans les rapports. Les données d’historique sont enregistrées par défaut dans le Stockage Blob Azure. Ce paramètre est propre à l’aspect en temps réel de vos données (stockage chaud). La valeur minimale est d’un jour ou 24 heures.
Important
La quantité de données chaudes stockées par cette durée de rétention influence directement le niveau de performance des visuels en temps réel lorsque vous créez des rapports sur ces données. Plus la rétention est grande, plus les visuels en temps réel des rapports risquent d’être affectés par un faible niveau de performance. Si vous devez effectuer une analyse historique, vous devriez utiliser le stockage froid fourni pour les flux de données en streaming.
Exécuter et modifier un flux de données en streaming
Après avoir enregistré et configuré votre flux de données en streaming, tout est prêt à être exécuté. Vous pouvez ensuite commencer à ingérer des données dans Power BI avec la logique d’analyse de streaming que vous avez définie.
Exécution du flux de données en streaming
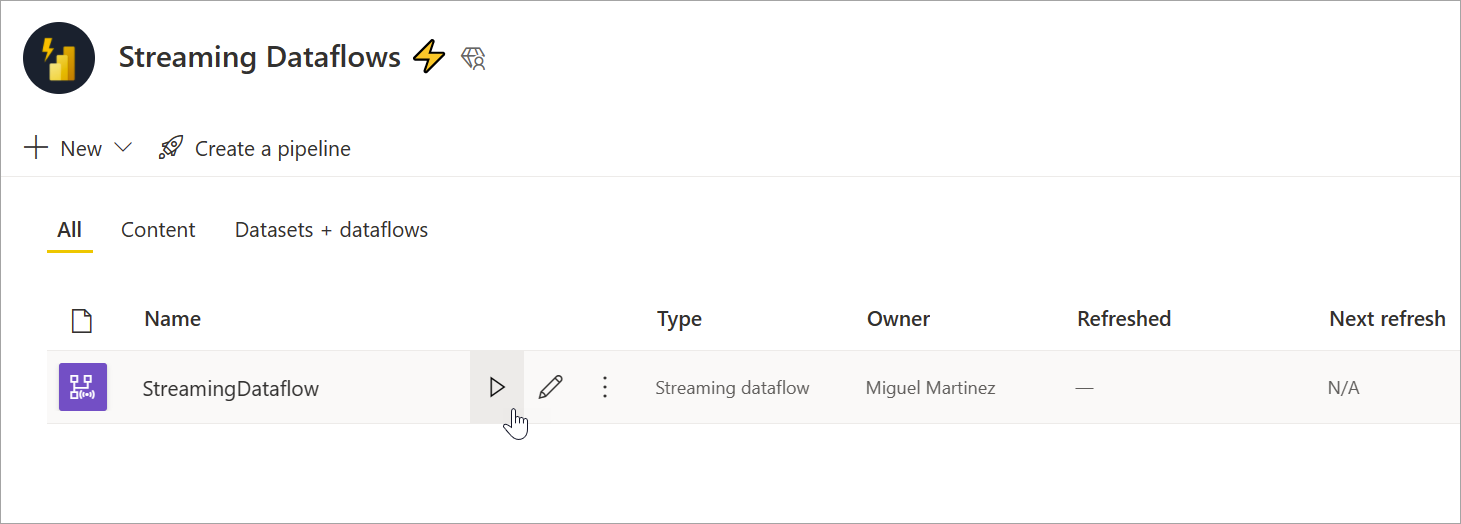
Pour démarrer votre flux de données en streaming, enregistrez d’abord votre flux de données et accédez à l’espace de travail où vous l’avez créé. Pointez sur le flux de données en streaming et sélectionnez le bouton de lecture qui apparaît. Un message contextuel vous indique que le flux de données en streaming est en cours de démarrage.
Notes
Le démarrage de l’ingestion et de l’affichage des données permettant de créer des rapports et des tableaux de bord dans Power BI Desktop peut prendre jusqu’à cinq minutes.
Modification du flux de données en streaming
Lorsqu’un flux de données en streaming est en cours d’exécution, il ne peut pas être modifié. Vous pouvez toutefois accéder à un flux de données en streaming dans un état en cours d’exécution et afficher la logique d’analyse sur laquelle le flux de données est basé.
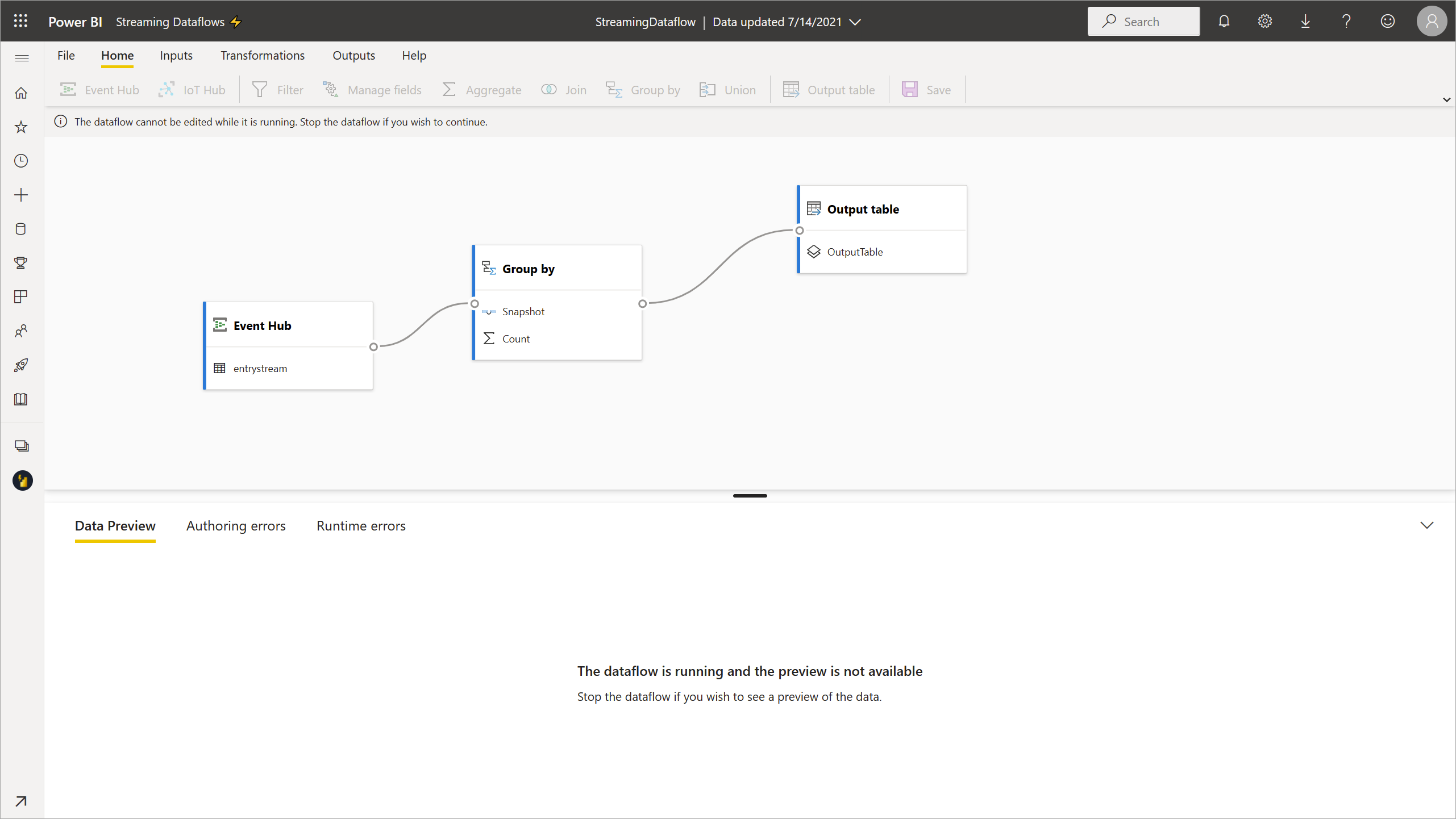
Lorsque vous accédez à un flux de données en streaming, toutes les options de modification sont désactivées et un message s’affiche : « Impossible de modifier le flux de données lorsqu’il est en cours d’exécution. Arrêtez le flux de données si vous souhaitez continuer. » L’aperçu des données est également désactivé.
Pour modifier votre flux de données en streaming, vous devez l’arrêter. Un flux de données arrêté entraîne des données manquantes.
La seule expérience disponible pendant l’exécution d’un flux de données en streaming est l’onglet Erreurs d’exécution : vous pouvez surveiller tous les messages supprimés et des situations similaires dans le comportement de votre flux de données.
Prise en compte du stockage des données lors de la modification du flux de données
Lorsque vous modifiez un flux de données, vous devez prendre en compte d’autres considérations. À l’instar des modifications apportées dans un schéma de flux de données classiques, le fait d’apporter des modifications à une table de sortie entraîne une perte des données déjà envoyées (push) et enregistrées dans Power BI. L’interface fournit des informations claires sur les conséquences de l’une de ces modifications dans votre flux de données en streaming, ainsi que des options pour les modifications que vous apportez avant l’enregistrement.
Prenons un exemple pour illustrer cette expérience. La capture d’écran suivante montre le message obtenu après avoir ajouté une colonne à la première table, modifié le nom d’une deuxième et laissé une troisième table telle quelle.

Dans cet exemple, les données déjà enregistrées dans les deux tables qui comportent un changement de schéma ou de nom sont supprimées si vous enregistrez les modifications. Dans le cas de la table restée identique, vous pouvez supprimer toutes les anciennes données et commencer de zéro ou les enregistrer pour une analyse ultérieure avec les nouvelles données à venir.
Gardez à l’esprit ces nuances lorsque vous modifiez votre flux de données en streaming, en particulier si vous avez besoin de données historiques disponibles ultérieurement pour une analyse plus poussée.
Consommation d’un flux de données en streaming
Lorsque votre flux de données en streaming en cours d’exécution, vous pouvez commencer à créer du contenu en plus de vos données de streaming. Aucune modification structurelle n’est nécessaire par rapport à ce que vous devez faire pour créer des rapports qui sont mis à jour en temps réel. Il existe quelques nuances et mises à jour à prendre en compte pour tirer parti de ce nouveau type de préparation des données pour la diffusion de données en continu.
Configurer le stockage de données
Comme nous l’avons déjà mentionné, les flux de données en streaming enregistrent les données dans les deux emplacements suivants. Le choix entre ces sources dépend du type d’analyse visé.
- Stockage chaud (analyse en temps réel) : à mesure qu’elles passent des flux de données en streaming à Power BI, les données sont stockées dans un emplacement à chaud accessible avec des visuels en temps réel. La quantité de données enregistrées dans ce stockage dépend de la valeur que vous définissez pour Durée de rétention dans les paramètres des flux de données en streaming. La valeur par défaut (et minimum) est de 24 heures.
- Stockage froid (analyse historique) : chaque période qui ne se situe pas dans la période que vous avez définie pour Durée de rétention est enregistrée dans le stockage à froid (blobs) dans Power BI, accessible pour consommation si nécessaire.
Notes
Ces deux emplacements de stockage de données se chevauchent. Si vous devez utiliser les deux emplacements en même temps (par exemple, un changement de pourcentage sur un jour), vous devrez peut-être dédupliquer vos enregistrements. Cela dépend des calculs d’intelligence temporelle que vous effectuez et de la stratégie de rétention.
Connexion à des flux de données en streaming à partir de Power BI Desktop
Power BI Desktop propose un connecteur appelé Dataflows que vous pouvez utiliser. Dans ce connecteur pour les flux de données en streaming, vous verrez deux tables correspondant au stockage des données décrit précédemment.
Pour vous connecter aux données de vos flux de données en streaming :
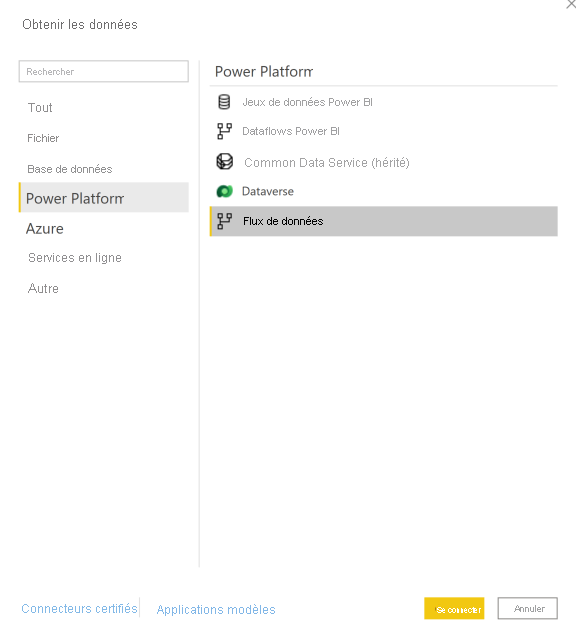
Accédez à Obtenir des données, sélectionnez Power Platform, puis choisissez le connecteur Flux de données.
Connectez-vous avec vos informations d’identification Power BI.
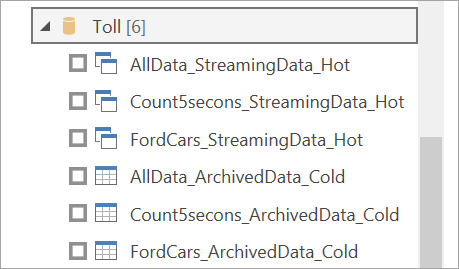
Sélectionnez des espaces de travail. Recherchez celui qui contient votre flux de données en streaming et sélectionnez ce flux de données. (Dans cet exemple, le flux de données en streaming est appelé Toll.)
Notez que toutes vos tables de sortie apparaissent deux fois : une fois pour les données de streaming (à chaud) et une fois pour les données archivées (à froid). Vous pouvez les différencier grâce aux étiquettes ajoutées après le nom de la table et par les icônes.
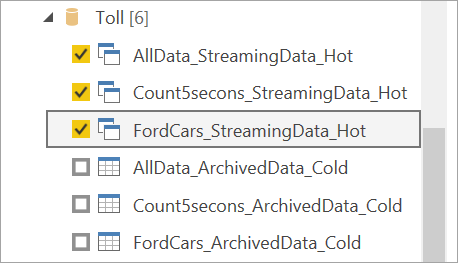
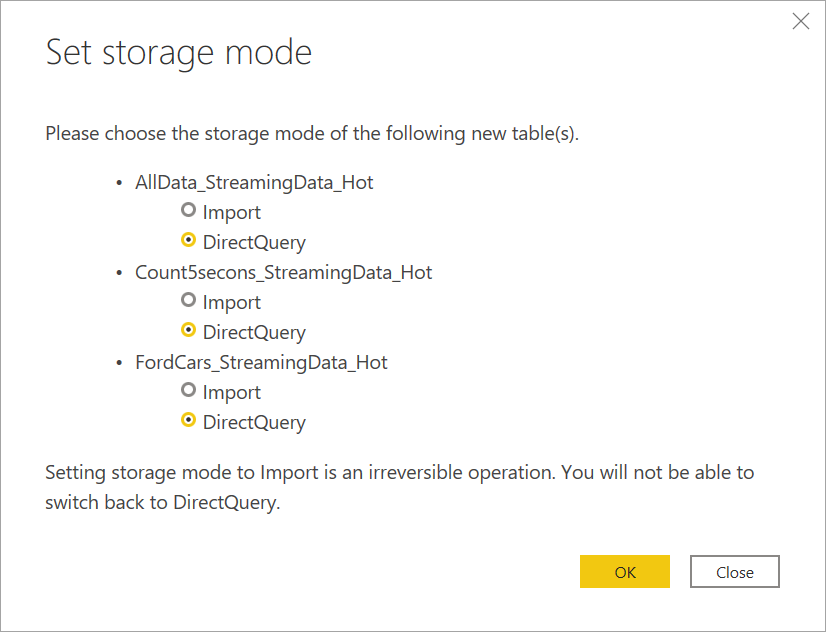
Connectez-vous aux données de streaming. Le cas des données archivées est le même que celui disponible en mode Import uniquement. Sélectionnez les tables qui incluent les étiquettes Streaming et Chaud, puis sélectionnez Charger.
Lorsque cela vous est demandé, sélectionnez DirectQuery comme mode de stockage si votre objectif est de créer des visuels en temps réel.
Vous pouvez maintenant créer des visuels, des mesures, etc., à l’aide des fonctionnalités disponibles dans Power BI Desktop.
Notes
Le connecteur de flux de données Power BI classique est toujours disponible. Il fonctionne avec les flux de données en streaming, avec deux réserves :
- Il permet seulement de se connecter au stockage chaud.
- Dans le connecteur, l’aperçu des données ne fonctionne pas avec les flux de données en streaming.
Activation de l’actualisation automatique des pages pour les visuels en temps réel
Lorsque votre rapport est prêt et que vous avez ajouté tout le contenu que vous souhaitez partager, il ne vous reste plus qu’à vous assurer que vos visuels sont mis à jour en temps réel. Vous pouvez utiliser une caractéristique appelée actualisation automatique de la page. Cette caractéristique vous permet d’actualiser toutes les secondes les visuels provenant d’une source DirectQuery.
Pour plus d’informations sur cette caractéristique, consultez Actualisation automatique des pages dans Power BI. Cet article vous explique comment les utiliser, comment les configurer et comment contacter votre administrateur si vous rencontrez des problèmes. Voici les principes de base de la configuration :
Accédez à la page de rapport sur laquelle vous souhaitez mettre à jour les visuels en temps réel.
Effacez tous les visuels de la page. Si possible, sélectionnez l’arrière-plan de la page.
Accédez au volet du format (1) et activez Actualisation de la page (2).
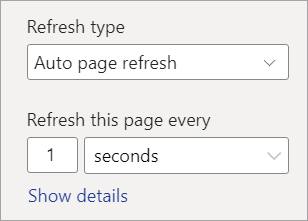
Configurez la fréquence souhaitée (potentiellement toutes les secondes si votre administrateur l’a autorisé).
Pour partager un rapport en temps réel, commencez par le publier sur le service Power BI. Vous pouvez ensuite configurer vos informations d’identification de flux de données pour le modèle sémantique et le partage.
Conseil
Si votre rapport n’est pas mis à jour aussi rapidement que vous en avez besoin ou en temps réel, consultez la documentation sur l’actualisation automatique des pages. Suivez les FAQ et les instructions de résolution des problèmes pour déterminer la raison pour laquelle ce problème peut se produire.
Considérations et limitations
Limitations générales
- Un abonnement Power BI Premium (capacité ou PPU) est requis pour créer et exécuter des flux de données en streaming.
- Un seul type de flux de données est autorisé par espace de travail.
- Il n’est pas possible de lier des flux de données classiques et des flux de données en streaming.
- Les capacités inférieures à A3 ne permettent pas d’utiliser des flux de données en streaming.
- Si les flux de données ou le moteur de calcul avancé ne sont pas activés dans un locataire, vous ne pouvez pas créer ni exécuter des flux de données en streaming.
- Les espaces de travail connectés à un compte de stockage ne sont pas pris en charge.
- Chaque flux de données en streaming peut offrir un débit pouvant atteindre 1 Mo/s.
Disponibilité
L’aperçu des flux de données en streaming n’est pas disponible dans les régions suivantes :
- Inde centrale
- Allemagne Nord
- Norvège Est
- Norvège Ouest
- Émirats arabes unis Centre
- Afrique du Sud Nord
- Afrique du Sud Ouest
- Suisse Nord
- Suisse Ouest
- Brésil Sud-Est
Licences
Le nombre de flux de données en streaming autorisés par locataire dépend de la licence utilisée :
Pour les capacités standard, utilisez la formule suivante pour calculer le nombre maximal de flux de données en streaming autorisés dans une capacité :
Nombre maximal de flux de données en streaming par capacité = nombre de vCore de la capacité × 5
Par exemple : P1 comprend 8 vCore -> 8 × 5 = 40 flux de données en streaming.
Pour Premium par utilisateur, un seul flux de données en streaming est autorisé par utilisateur. Si un autre utilisateur souhaite consommer un flux de données en streaming dans un espace de travail PPU, il doit également avoir une licence PPU.
Création de dataflows
Lorsque vous créez des flux de données en streaming, prenez en considération les points suivants :
- Le propriétaire d’un flux de données en streaming ne peut apporter des modifications que si le flux de données n’est pas en cours d’exécution.
- Les flux de données en streaming ne sont pas disponibles dans Mon espace de travail.
se connecter à partir de Power BI Desktop
Vous ne pouvez accéder au stockage froid qu’avec le connecteur Flux de données disponible à compter de la mise à jour de juillet 2021 de Power BI Desktop. Le connecteur de flux de données Power BI précédent autorise uniquement les connexions de stockage de données de streaming (chaud). L’aperçu des données du connecteur ne fonctionne pas.
Contenu connexe
Cet article vous a donné une vue d’ensemble de la préparation des données de streaming en libre-service avec des flux de données en streaming. Les articles suivants fournissent des informations sur le test de cette fonctionnalité et comment utiliser d’autres caractéristiques des données de streaming dans Power BI :