Entraînement de modèle IA distribué dans HPC Pack
Arrière-plan
Aujourd’hui, les modèles IA évoluent pour devenir plus substantiels, nécessitant une demande croissante de matériel avancé et un cluster d’ordinateurs pour une formation efficace des modèles. HPC Pack peut simplifier le travail d’entraînement du modèle pour vous efficacement.
PyTorch Distributed Data Parallel (aka DDP)
Pour implémenter l’entraînement de modèle distribué, il est nécessaire d’utiliser une infrastructure de formation distribuée. Le choix de l’infrastructure dépend de celui utilisé pour générer votre modèle. Dans cet article, je vais vous guider sur la procédure à suivre avec PyTorch dans HPC Pack.
PyTorch offre plusieurs méthodes pour l’entraînement distribué. Parmi ceux-ci, Distributed Data Parallel (DDP) est largement préféré en raison de sa simplicité et de ses modifications de code minimales requises à partir de votre modèle d’entraînement mono-machine actuel.
Configurer un cluster HPC Pack pour l’apprentissage du modèle IA
Vous pouvez configurer un cluster HPC Pack à l’aide de vos ordinateurs locaux ou machines virtuelles sur Azure. Assurez-vous simplement que ces ordinateurs sont équipés de GPU (dans cet article, nous allons utiliser des GPU Nvidia).
En règle générale, un GPU peut avoir un processus pour un travail d’entraînement distribué. Par conséquent, si vous avez deux ordinateurs (comme des nœuds dans un cluster d’ordinateurs), chacun équipé de quatre GPU, vous pouvez obtenir 2 * 4, ce qui correspond à 8 processus parallèles pour une formation de modèle unique. Cette configuration peut potentiellement réduire le temps d’entraînement d’environ 1/8e par rapport à l’apprentissage unique des processus, en omettant certaines surcharges de synchronisation des données entre les processus.
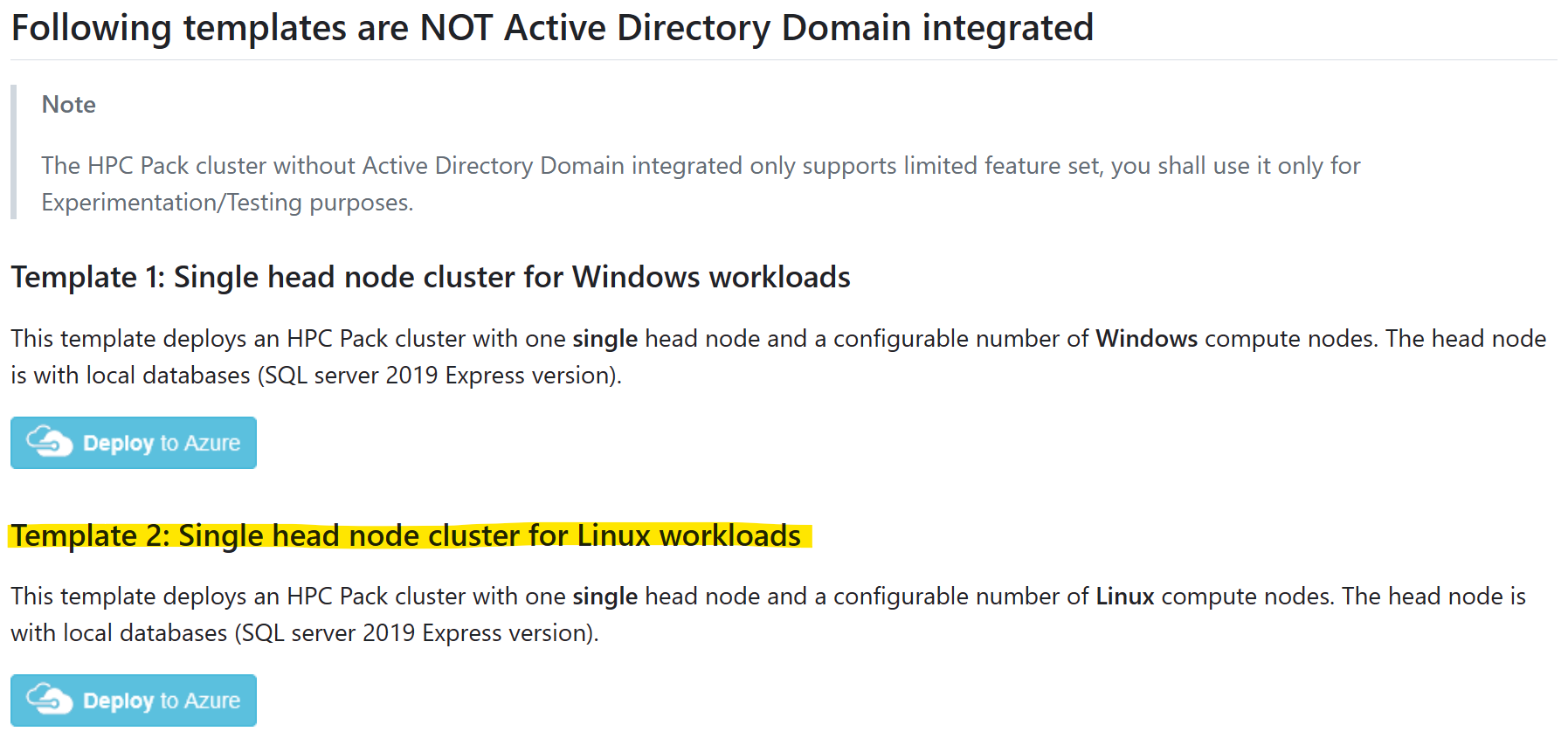
Créer un cluster HPC Pack dans un modèle ARM
Par souci de simplicité, vous pouvez démarrer un nouveau cluster HPC Pack sur Azure, dans modèles ARM sur GitHub.
Sélectionnez le modèle « Cluster à nœud principal unique pour les charges de travail Linux », puis cliquez sur « Déployer sur Azure »
Et reportez-vous aux conditions préalables pour savoir comment effectuer et charger un certificat pour l’utilisation de HPC Pack.
Veuillez noter :
Vous devez sélectionner une image de nœud de calcul marquée avec « HPC ». Cela indique que les pilotes GPU sont préinstallés dans l’image. L’échec de ce processus nécessiterait une installation manuelle du pilote GPU sur un nœud de calcul à une étape ultérieure, ce qui pourrait s’avérer une tâche difficile en raison de la complexité de l’installation du pilote GPU. Vous trouverez plus d’informations sur les images HPC ici.
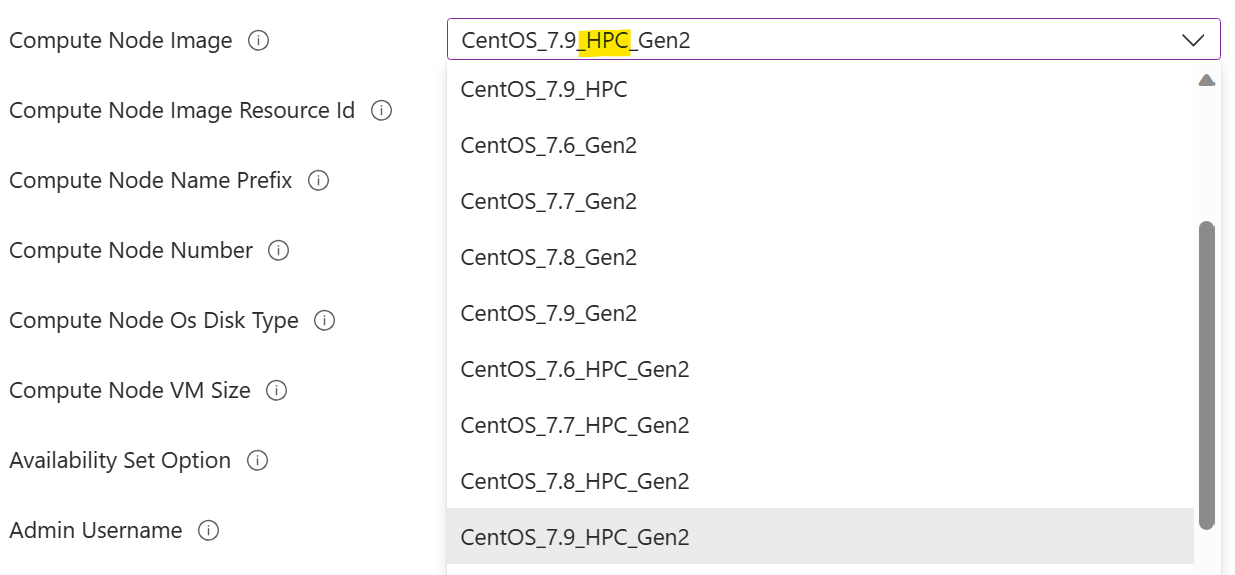
Vous devez sélectionner une taille de machine virtuelle de nœud de calcul avec GPU. C’est taille de machine virtuelle de la série N.
 GPU
GPU
Installer PyTorch sur des nœuds de calcul
Sur chaque nœud de calcul, installez PyTorch avec la commande
pip3 install torch torchvision torchaudio
Conseils : vous pouvez tirer parti de hpC Pack « Exécuter la commande » pour exécuter une commande sur un ensemble de nœuds de cluster en parallèle.
Configurer un répertoire partagé
Avant de pouvoir exécuter un travail d’entraînement, vous avez besoin d’un répertoire partagé accessible par tous les nœuds de calcul. Le répertoire est utilisé pour l’apprentissage du code et des données (jeu de données d’entrée et modèle entraîné de sortie).
Vous pouvez configurer un répertoire de partage SMB sur un nœud principal, puis le monter sur chaque nœud de calcul avec cifs, comme suit :
Sur un nœud principal, créez un répertoire
appsous%CCP_DATA%\SpoolDir, qui est déjà partagé commeCcpSpoolDirpar HPC Pack par défaut.Sur un nœud de calcul, montez le répertoire
appcommesudo mkdir /app sudo mount -t cifs //<your head node name>/CcpSpoolDir/app /app -o vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777NOTE:
- L’option
passwordpeut être omise dans un interpréteur de commandes interactif. Vous serez invité à le faire dans ce cas. - Le
dir_modeet lefile_modeest défini sur 0777, afin que tout utilisateur Linux puisse le lire/écrire. Une autorisation restreinte est possible, mais plus complexe à configurer.
- L’option
Si vous le souhaitez, rendez le montage définitivement en ajoutant une ligne dans
/etc/fstabcomme//<your head node name>/CcpSpoolDir/app cifs vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777 0 2Ici, le
passwordest requis.
Exécuter un travail d’entraînement
Supposons maintenant que nous avons deux nœuds de calcul Linux, chacun avec quatre GPU NVidia v100. Et nous avons installé PyTorch sur chaque nœud. Nous avons également configuré un répertoire partagé « app ». Maintenant, nous pouvons commencer notre travail de formation.
Ici, j’utilise un modèle de toy simple basé sur PyTorch DDP. Vous pouvez obtenir le code sur GitHub.
Téléchargez les fichiers suivants dans le répertoire partagé %CCP_DATA%\SpoolDir\app sur le nœud principal
- neural_network.py
- operations.py
- run_ddp.py
Créez ensuite un travail avec Node en tant qu’unité de ressource et deux nœuds pour le travail, comme
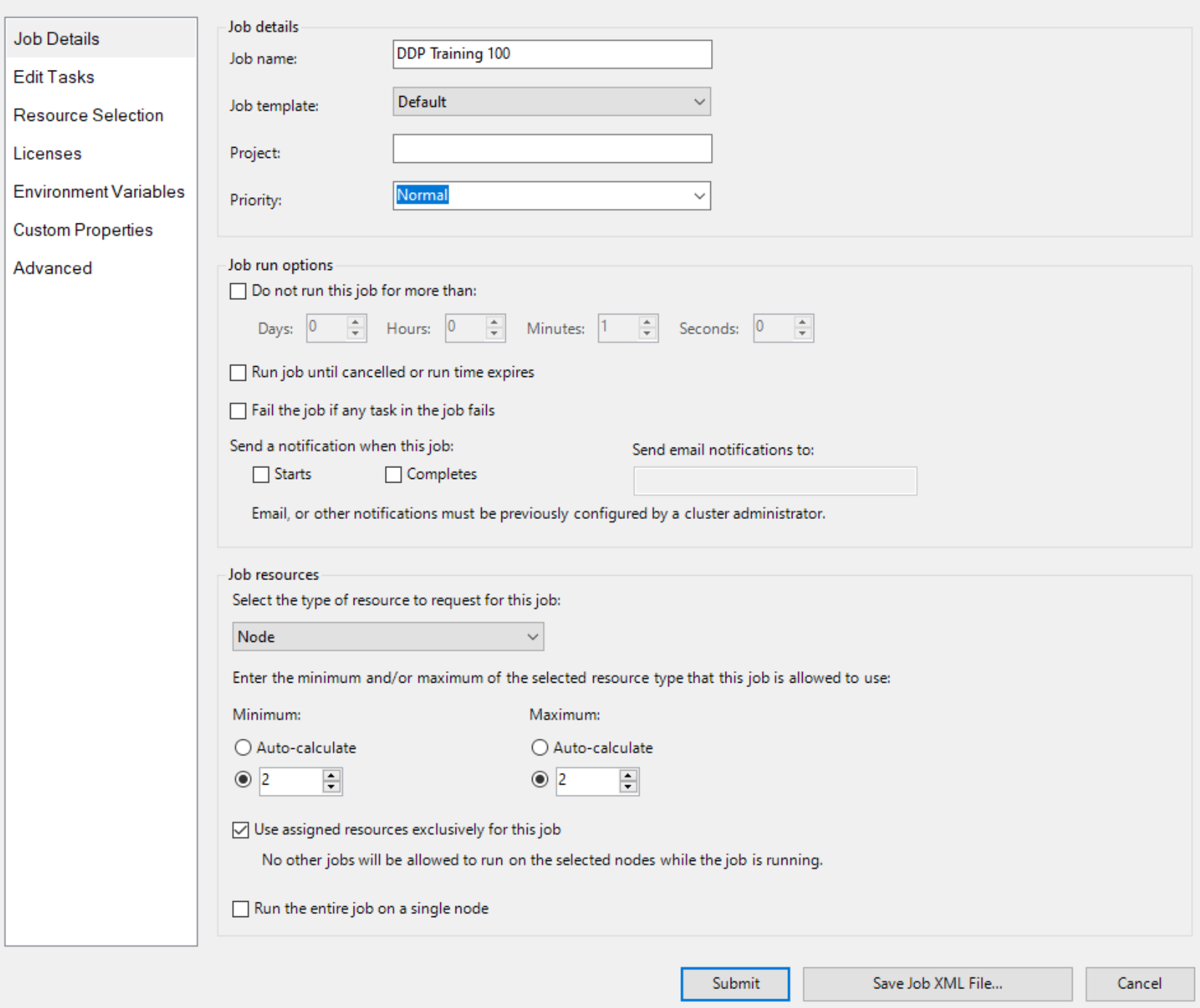
Et spécifiez explicitement deux nœuds avec GPU, comme
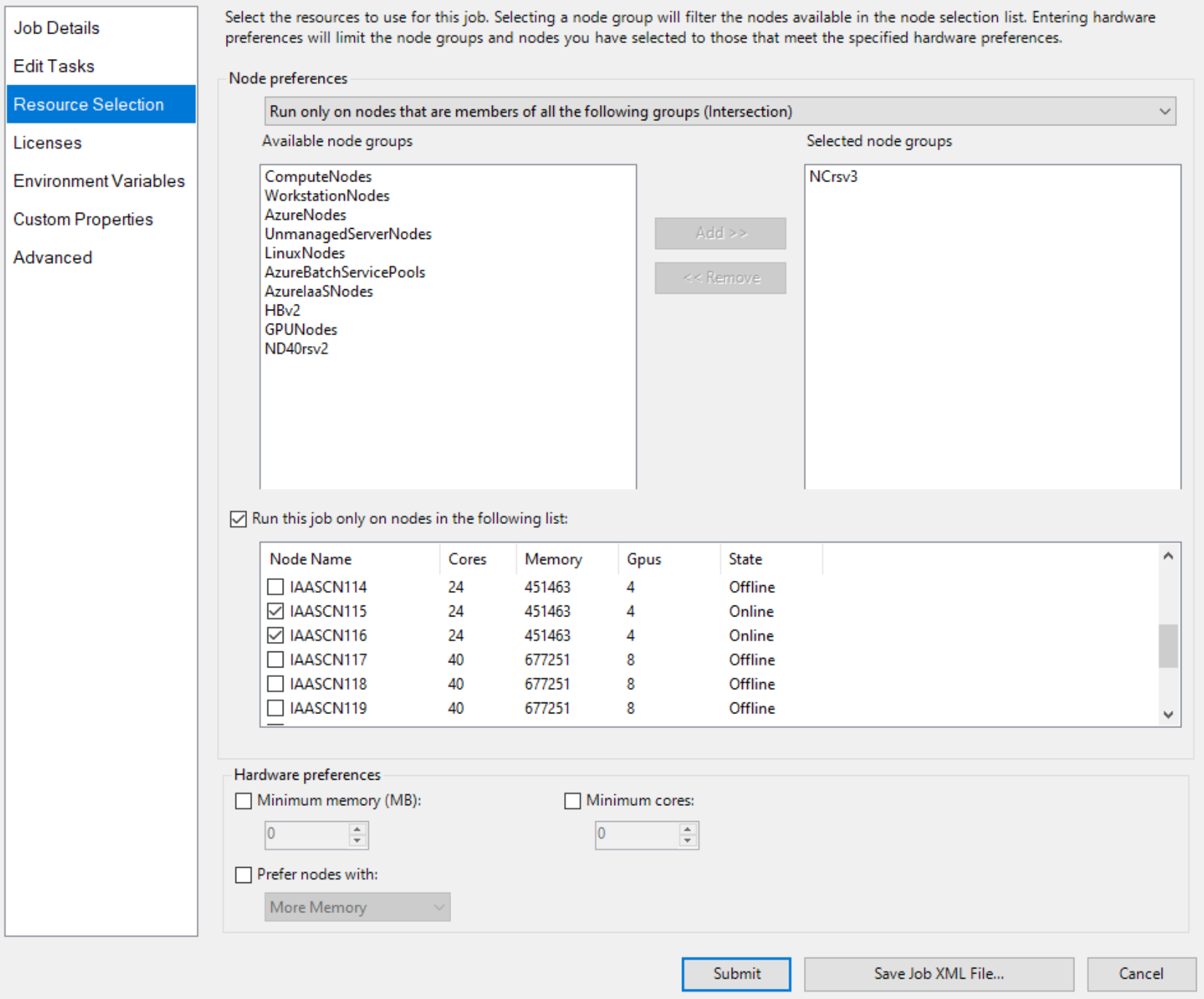
Ensuite, ajoutez des tâches de travail, comme
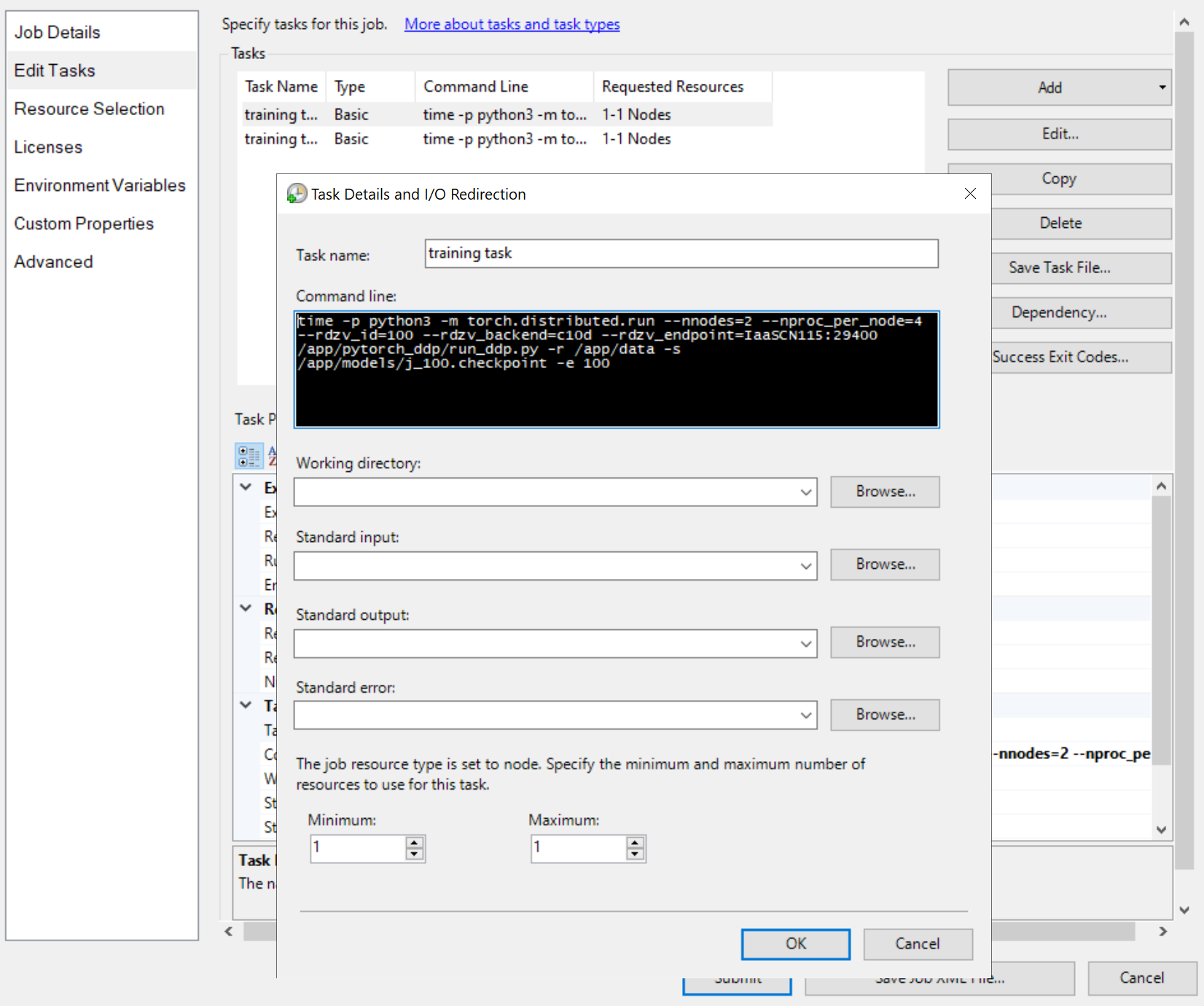
Les lignes de commande des tâches sont toutes les mêmes, comme
python3 -m torch.distributed.run --nnodes=<the number of compute nodes> --nproc_per_node=<the processes on each node> --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=<a node name>:29400 /app/run_ddp.py
-
nnodesspécifie le nombre de nœuds de calcul pour votre travail d’entraînement. -
nproc_per_nodespécifie le nombre de processus sur chaque nœud de calcul. Il ne peut pas dépasser le nombre de GPU sur un nœud. Autrement dit, un GPU peut avoir un processus au maximum. -
rdzv_endpointspécifie un nom et un port d’un nœud qui joue le rôle de Rendezvous. Tout nœud du travail d’entraînement peut fonctionner. - « /app/run_ddp.py » est le chemin d’accès à votre fichier de code d’entraînement. N’oubliez pas que
/appest un répertoire partagé sur le nœud principal.
Envoyez le travail et attendez le résultat. Vous pouvez afficher les tâches en cours d’exécution, comme
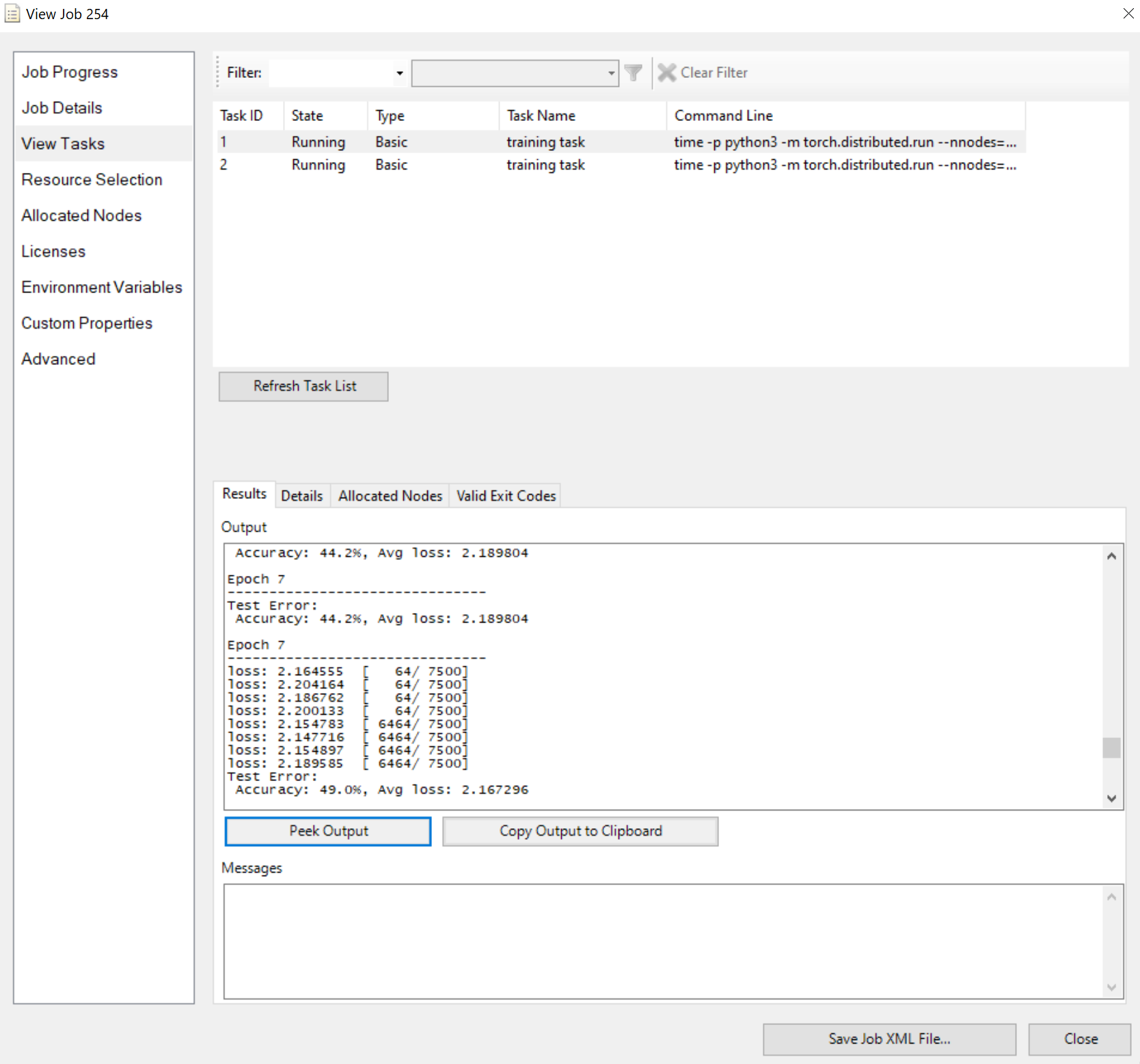
Notez que le volet Résultats affiche une sortie tronquée si elle est trop longue.
C’est tout pour ça. J’espère que vous obtenez les points et HPC Pack peut accélérer votre travail d’entraînement.