Préparation des disques durs pour un travail d’importation
L’outil WAImportExport est l’outil de préparation et de réparation du lecteur que vous pouvez utiliser avec le service Microsoft Azure Import/Export. Il permet de copier les données sur des disques durs que vous allez envoyer à un centre de données Azure. Lorsqu’un travail d’importation est terminé, vous pouvez utiliser cet outil pour réparer les objets blob endommagés, manquants ou en conflit avec d’autres objets blob. Lorsque vous recevez les disques d’un travail d’exportation, vous pouvez utiliser cet outil pour réparer tous les fichiers endommagés ou manquants sur les disques. Dans cet article, nous passerons en revue l’utilisation de cet outil.
Prérequis
Configuration requise pour WAImportExport.exe
-
Configuration d’un ordinateur
- Windows 7, Windows Server 2008 R2 ou système d’exploitation Windows plus récent
- .NET framework 4 installé. Consultez les questions fréquentes (FAQ) pour savoir comment déterminer si .Net Framework est installé sur l’ordinateur.
- Clé du compte de stockage : vous devez avoir au moins une des clés du compte de stockage.
Préparation de disques en vue du travail d’importation
- BitLocker : BitLocker doit être activé sur l’ordinateur qui exécute l’outil WAImportExport. Consultez la section FAQ pour savoir comment activer BitLocker.
- Disques accessibles à partir de l’ordinateur sur lequel l’outil WAImportExport est exécuté. Consultez la section Forum Aux Questions pour savoir comment spécifier les disques.
- Fichiers sources : les fichiers que vous projetez d’importer doivent être accessibles à l’ordinateur de copie (partage réseau ou disque dur local).
Réparation d’un travail d’importation en échec partiel
- Copiez le fichier journal généré lorsque le service Azure Import/Export copie les données entre le compte de stockage et le disque. Ils se trouvent dans votre compte de stockage cible.
Réparation d’un travail d’exportation en échec partiel
- Copiez le fichier journal généré lorsque le service Azure Import/Export copie les données entre le compte de stockage et le disque. Il se trouve dans votre compte de stockage source.
- Fichier manifeste : (facultatif) situé sur le disque exporté, renvoyé par Microsoft.
Télécharger et installer WAImportExport
Téléchargez la dernière version de WAImportExport.exe. Extrayez le contenu compressé dans un répertoire de votre ordinateur.
La tâche suivante consiste à créer des fichiers CSV.
Préparer le fichier dataset.csv
Qu’est-ce que le fichier dataset.csv ?
Le fichier dataset.csv est un fichier CSV qui contient une liste de répertoires et/ou une liste de fichiers à copier sur les disques cibles. La première étape pour créer une tâche d’importation consiste à déterminer les répertoires et les fichiers que vous allez importer. Il peut s’agir d’une liste de répertoires, d’une liste de fichiers uniques ou d’une combinaison des deux. Lorsqu’un répertoire est spécifié, tous les fichiers situés dans ce répertoire et ses sous-répertoires sont importés.
Pour chaque répertoire ou fichier à importer, vous devez identifier un répertoire virtuel ou un objet blob de destination dans le service Blob Azure. Vous utiliserez ces cibles comme des entrées dans l’outil WAImportExport. Les répertoires doivent être délimités par la barre oblique « / ».
Le tableau suivant présente des exemples d’objets blob cibles :
| Fichier ou répertoire source | Répertoire virtuel ou objet blob cibles |
|---|---|
| H:\Video | https://mystorageaccount.blob.core.windows.net/video |
| H:\Photo | https://mystorageaccount.blob.core.windows.net/photo |
| K:\Temp\FavoriteVideo.ISO | https://mystorageaccount.blob.core.windows.net/favorite/FavoriteVideo.ISO |
| \myshare\john\music | https://mystorageaccount.blob.core.windows.net/music |
Exemple de fichier dataset.csv
BasePath,DstBlobPathOrPrefix,BlobType,Disposition,MetadataFile,PropertiesFile
"F:\50M_original\100M_1.csv.txt","containername/100M_1.csv.txt",BlockBlob,rename,"None",None
"F:\50M_original\","containername/",BlockBlob,rename,"None",None
Champs du fichier dataset.csv
| Champ | Description |
|---|---|
| Chemin de base |
[Obligatoire] La valeur de ce paramètre représente la source où se trouvent les données à importer. L’outil copie de manière récurrente toutes les données situées sous ce chemin d’accès. Valeurs autorisées : ce chemin d’accès (partagé ou non) doit être valide sur l’ordinateur local et accessible par l’utilisateur. Le chemin d’accès du répertoire doit être un chemin d’accès absolu (et non relatif). Si le chemin se termine par « \ », il représente un répertoire autre qu’un chemin d’accès se terminant sans « \ » représente un fichier. Aucune expression régulière n’est autorisée dans ce champ. Si le chemin d’accès contient des espaces, placez-les entre guillemets droits (" "). Exemple : "c:\Directory\c\Directory\File.txt" « \\FBaseFilesharePath.domain.net\sharename\directory » |
| DstBlobPathOrPrefix |
[Obligatoire] Chemin d’accès au répertoire virtuel cible dans votre compte de stockage Azure. Le répertoire virtuel peut déjà exister ou non. S’il n’existe pas, le service Import/Export le crée. Veillez à utiliser des noms de conteneur valides quand vous spécifiez des répertoires virtuels de destination ou des objets blob. N’oubliez pas que les noms de conteneur doivent être en minuscules. Pour connaître les règles d’affectation de noms aux conteneurs, consultez Naming and Referencing Containers, Blobs, and Metadata (Affectation de noms et références aux conteneurs, blobs et métadonnées). S’il n’est spécifié que la racine, la structure de répertoire de la source est répliquée dans le conteneur d’objets blob de destination. Si vous souhaitez une structure de répertoire différente de la source, plusieurs lignes de mappage dans le fichier CSV Vous pouvez spécifier un conteneur ou un préfixe d’objet blob comme music/70s/. Le répertoire cible doit commencer par le nom du conteneur, suivi d’une barre oblique « / » et peut spécifier un répertoire virtuel d’objets blob se terminant par « / ». Lorsque le conteneur cible est le conteneur racine, vous devez spécifier explicitement le conteneur racine et la barre oblique (exemple : $root/). Comme les objets blob du conteneur racine ne peuvent pas inclure « / » dans leur nom, les sous-répertoires du répertoire source ne seront pas copiés si le répertoire cible est le conteneur racine. Exemple Si le chemin des objets blob de destination est https://mystorageaccount.blob.core.windows.net/video, la valeur de ce champ peut être video/ |
| BlobType |
[Facultatif] bloquer | Page Pour l’instant, le service Import/Export prend en charge 2 types d’objet blob. les objets blob de pages et les objets blob de blocs. Par défaut, tous les fichiers sont importés comme des objets blob de blocs. Et *.vhd et *.vhdx seront importés en tant qu’objets blob de pagesThere est une limite sur la taille autorisée pour les objets blob de blocs et les objets blob de pages. Pour plus d’informations, consultez la page Objectifs de performance et évolutivité d’Azure Storage. |
| Disposition |
[Facultatif] renommer | sans remplacement de | Écraser Ce champ spécifie le comportement de copie lors de l’importation, c’est-à-dire lorsque les données sont chargées sur le compte de stockage à partir du disque. Les options disponibles sont : renommer|overwrite|no-overwrite. La valeur par défaut est « rename » si rien n’est spécifié. Rename : si un objet portant le même nom est présent, l’outil crée une copie dans la destination. Overwrite : remplace le fichier par sa version plus récente. Le fichier modifié en dernier est conservé. No-overwrite : ne remplace pas le fichier existant. |
| MetadataFile |
[Facultatif] Ce champ indique le fichier de métadonnées qui peut être spécifié si vous devez conserver les métadonnées des objets ou fournir des métadonnées personnalisées. Chemin d’accès au fichier des métadonnées des objets blob cibles. Pour plus d’informations, consultez le format des métadonnées et des propriétés du service Import/Export |
| PropertiesFile |
[Facultatif] Chemin d’accès au fichier des propriétés des objets blob cibles. Pour plus d’informations, consultez Format de fichier de propriétés et de métadonnées du service d’importation/exportation. |
Préparer le fichier CSV InitialDriveSet ou AdditionalDriveSet
Qu’est-ce que le fichier driveset.csv ?
La valeur de l’indicateur /InitialDriveSet ou /AdditionalDriveSet est un fichier CSV qui contient la liste des disques associés à des lettres, pour que l’outil puisse sélectionner correctement les disques à préparer. Si le volume des données dépasse la capacité d’un disque, l’outil WAImportExport répartit les données sur plusieurs disques répertoriés dans ce fichier CSV de manière optimisée.
Le nombre de disques sur lesquels les données peuvent être écrites lors d’une seule session n’est pas limité. L’outil répartit les données en fonction de la taille du disque et des dossiers. Il sélectionne le disque de manière optimisée en fonction de la taille des objets. Lors du chargement dans le compte de stockage, les données sont replacées dans l’arborescence de répertoires spécifiée dans le fichier dataset.csv. Pour créer un fichier driveset.csv, procédez comme suit :
Créer le volume de base et lui attribuer une lettre
Pour créer un volume de base et lui attribuer une lettre, suivez les instructions de « Simpler partition creation (Création de partition plus simple) » dans Overview of Disk Management (Vue d’ensemble de la gestion des disques).
Exemple de fichier CSV InitialDriveSet ou AdditionalDriveSet
DriveLetter,FormatOption,SilentOrPromptOnFormat,Encryption,ExistingBitLockerKey
G,AlreadyFormatted,SilentMode,AlreadyEncrypted,060456-014509-132033-080300-252615-584177-672089-411631
H,Format,SilentMode,Encrypt,
Champs du fichier driveset.csv
| Champs | Valeur |
|---|---|
| DriveLetter |
[Obligatoire] Chaque disque spécifié comme cible dans l’outil doit contenir un volume NTFS simple et être associé à une lettre. Exemple : R ou r |
| FormatOption |
[Obligatoire] Format | AlreadyFormatted Format : cette valeur déclenche la mise en forme de toutes les données sur le disque. AlreadyFormatted : l’outil ignore la mise en forme lorsque cette valeur est spécifiée. |
| SilentOrPromptOnFormat |
[Obligatoire] SilentMode | PromptOnFormat SilentMode : cette valeur permet à l’utilisateur d’exécuter l’outil en mode silencieux. PromptOnFormat : l’outil invite l’utilisateur à confirmer l’action pour chaque format. Si ce paramètre n’est pas défini, la commande ne s’exécute pas et affiche le message d’erreur « Incorrect value for SilentOrPromptOnFormat: none » (« Valeur incorrecte de SilentOrPromptOnFormat : aucune ») |
| Chiffrement |
[Obligatoire] Chiffrer | AlreadyEncrypted La valeur de ce champ indique le disque à chiffrer et le disque à ne pas chiffrer. Encrypt : l’outil chiffre le disque. Si le champ « FormatOption » a pour valeur « Format », cette valeur doit être « Encrypt ». Si vous spécifiez « AlreadyEncrypted » dans ce cas, l’erreur « When Format is specified, Encrypt must also be specified (Lorsque Format est spécifié, Encrypt doit aussi être spécifié) » s’affiche. AlreadyEncrypted : l’outil déchiffre le disque avec la clé BitLockerKey fournie dans le champ « ExistingBitLockerKey ». Si la valeur du champ « FormatOption » est « AlreadyFormatted », cette valeur peut être « Encrypt » ou « AlreadyEncrypted ». |
| ExistingBitLockerKey |
[Obligatoire] Si la valeur du champ « Encryption » est « AlreadyEncrypted », La valeur de ce champ est la clé BitLocker associée au disque en question. Ce champ doit être vide si la valeur du champ « Encryption » est « Encrypt ». Si la clé BitLocker est spécifiée, le message d’erreur « Bitlocker Key should not be specified (La clé BitLocker ne doit pas être spécifiée) » s’affiche. Exemple : 060456-014509-132033-080300-252615-584177-672089-411631 |
Préparation de disques en vue du travail d’importation
Pour préparer des disques en vue d’un travail d’importation, appelez l’outil WAImportExport avec la commande PrepImport. Les paramètres inclus varient selon s’il s’agit de la première session de copie ou non.
Première session
Première session de copie d’un ou de plusieurs répertoires sur un ou plusieurs disques (selon la configuration du fichier CSV) Lors de sa première exécution, la commande PrepImport de l’outil WAImportExport copie les répertoires et/ou les fichiers dans le cadre d’une nouvelle session de copie :
WAImportExport.exe PrepImport /j:<JournalFile> /id:<SessionId> [/logdir:<LogDirectory>] [/sk:<StorageAccountKey>] [/silentmode] [/InitialDriveSet:<driveset.csv>] /DataSet:<dataset.csv>
Exemple :
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#1 /sk:\*\*\*\*\*\*\*\*\*\*\*\*\* /InitialDriveSet:driveset-1.csv /DataSet:dataset-1.csv /logdir:F:\logs
Ajouter des données dans la session suivante
Dans les sessions de copie suivantes, il est inutile de spécifier les paramètres initiaux. Vous devez utiliser le même fichier journal pour que l’outil sache où il s’est arrêté dans la session précédente. L’état de cette session de copie est consigné dans le fichier journal. Voici la syntaxe à utiliser pour qu’une session suivante copie des répertoires et/ou des fichiers supplémentaires :
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<DifferentSessionId> [DataSet:<differentdataset.csv>]
Exemple :
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /DataSet:dataset-2.csv
Ajouter des disques à la dernière session
Si les données ne tiennent pas sur les disques spécifiés dans le fichier InitialDriveset, l’outil permet d’ajouter des disques supplémentaires à la même session de copie.
Notes
L’ID de session doit correspondre à l’ID de session précédent. Le fichier journal doit correspondre à celui spécifié dans la session précédente.
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<SameSessionId> /AdditionalDriveSet:<newdriveset.csv>
Exemple :
WAImportExport.exe PrepImport /j:SameJournalTest.jrn /id:session#2 /AdditionalDriveSet:driveset-2.csv
Annuler la dernière session :
Si une session de copie est interrompue et qu’il n’est pas possible de la reprendre (par exemple, si un répertoire source est inaccessible), vous devez l’annuler pour pouvoir lancer d’autres sessions de copie :
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<SameSessionId> /AbortSession
Exemple :
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /AbortSession
Seule la dernière session de copie, si elle s’est terminée anormalement, peut être annulée. Notez que vous ne pouvez pas annuler la première session de copie d’un disque. Mais, vous devez redémarrer la session de copie avec un nouveau fichier journal.
Reprise de la dernière session interrompue
Si une session de copie est interrompue pour une raison quelconque, vous pouvez la reprendre en exécutant l’outil avec le fichier journal spécifié :
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<SameSessionId> /ResumeSession
Exemple :
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /ResumeSession
Important
Lorsque vous reprenez une session de copie, ne modifiez pas les fichiers et répertoires source.
Paramètres de WAImportExport
| Paramètres | Description |
|---|---|
| /j:<Fichier_journal> |
Obligatoire Chemin d’accès au fichier journal. Un fichier journal suit un ensemble de disques et enregistre la progression de leur préparation. Ce paramètre doit toujours être spécifié. |
| /LogDir:<Répertoire_journaux> |
Facultatif. Répertoire du journal. Les fichiers journaux détaillés, ainsi que certains fichiers temporaires, sont écrits dans ce répertoire. Si ce paramètre n’est pas spécifié, le répertoire courant est utilisé comme répertoire de journaux. Le répertoire de journaux ne peut être spécifié qu’une fois pour le même fichier journal. |
| /id:<ID_session> |
Obligatoire L’ID de session permet d’identifier une session de copie. Il est utilisé pour assurer la précision de la récupération d’une session de copie interrompue. |
| /ResumeSession | facultatif. Si la dernière session de copie s’est arrêtée anormalement, ce paramètre permet de la reprendre. |
| /AbortSession | facultatif. Si la dernière session de copie s’est arrêtée anormalement, ce paramètre permet de l’annuler. |
| /sn:<Nom_compte_stockage> |
Obligatoire Applicable uniquement à RepairImport et RepairExport. Nom du compte de stockage. |
| /sk:<Clé_compte_stockage> |
Obligatoire Clé du compte de stockage. |
| /InitialDriveSet:<driveset.csv> |
Obligatoire Lors de la première session de copie Fichier CSV contenant la liste des disques à préparer. |
| /AdditionalDriveSet:<driveset.csv> |
Requis. Lors de l’ajout de disques à la session de copie en cours. Fichier CSV contenant la liste des disques supplémentaires à ajouter. |
| /r:<RepairFile> |
Obligatoire Applicable uniquement à RepairImport et RepairExport. Chemin d’accès au fichier de suivi de la progression de la réparation. Chaque disque ne doit avoir qu’un fichier de réparation. |
| /d:<Répertoires_cibles> | Requis. Applicable uniquement à RepairImport et RepairExport. Pour RepairImport, un ou plusieurs répertoires à réparer, séparés par des points-virgules ; pour RepairExport, un répertoire à réparer (par exemple, le répertoire racine du disque). |
| /CopyLogFile:<Fichier_journal_copie_disque> | Obligatoire Applicable uniquement à RepairImport et RepairExport. Chemin d’accès au fichier journal de copie du lecteur (détaillé ou erreur). |
| /ManifestFile:<Fichier_manifeste_disque> |
Obligatoire Applicable uniquement à RepairExport. Chemin d’accès au fichier manifeste du disque. |
| /PathMapFile:<Fichier_mappage_chemin_disque> |
Facultatif. Applicable uniquement à RepairImport. Chemin d’accès au fichier contenant les mappages des chemins d’accès relatifs à la racine du disque pour les emplacements des fichiers (séparés par des tabulations). Spécifié pour la première fois, il indique des chemins d’accès avec des cibles vides, ce qui signifie qu’ils sont introuvables dans les répertoires cibles, que leur accès est refusé, que leur nom est incorrect ou qu’ils existent dans plusieurs répertoires. Le fichier de mappage de chemins peut être modifié manuellement pour inclure les chemins cibles corrects et spécifié à nouveau pour que l’outil résolve correctement les chemins de fichier. |
| /ExportBlobListFile:<Fichier_liste_blobs_à_exporter> |
Requis. Applicable uniquement à PreviewExport. Chemin d’accès au fichier XML contenant la liste des chemins d’accès ou des préfixes de chemin d’accès aux objets blob à exporter. Le format du fichier est le même que celui de la liste des objets blob dans l’opération Put Job de l’API REST du service Import/Export. |
| /DriveSize:<Taille_disque> |
Requis. Applicable uniquement à PreviewExport. Taille des disques à utiliser pour l’exportation. Par exemple, 500 Go, 1,5 To. Remarque : 1 Go = 1 000 000 000 octets ; 1 To = 1 000 000 000 000 octets |
| /DataSet:<dataset.csv> |
Obligatoire Un fichier CSV contenant une liste de répertoires et/ou de fichiers à copier sur des disques cibles. |
| /silentmode |
Facultatif. Si cet argument n’est pas spécifié, l’outil demande de spécifier des disques et de confirmer chaque opération. |
Sortie de l’outil
Exemple de fichier manifeste de disque
<?xml version="1.0" encoding="UTF-8"?>
<DriveManifest Version="2011-MM-DD">
<Drive>
<DriveId>drive-id</DriveId>
<StorageAccountKey>storage-account-key</StorageAccountKey>
<ClientCreator>client-creator</ClientCreator>
<!-- First Blob List -->
<BlobList Id="session#1-0">
<!-- Global properties and metadata that applies to all blobs -->
<MetadataPath Hash="md5-hash">global-metadata-file-path</MetadataPath>
<PropertiesPath Hash="md5-hash">global-properties-file-path</PropertiesPath>
<!-- First Blob -->
<Blob>
<BlobPath>blob-path-relative-to-account</BlobPath>
<FilePath>file-path-relative-to-transfer-disk</FilePath>
<ClientData>client-data</ClientData>
<Length>content-length</Length>
<ImportDisposition>import-disposition</ImportDisposition>
<!-- page-range-list-or-block-list -->
<!-- page-range-list -->
<PageRangeList>
<PageRange Offset="1073741824" Length="512" Hash="md5-hash" />
<PageRange Offset="1073741824" Length="512" Hash="md5-hash" />
</PageRangeList>
<!-- block-list -->
<BlockList>
<Block Offset="1073741824" Length="4194304" Id="block-id" Hash="md5-hash" />
<Block Offset="1073741824" Length="4194304" Id="block-id" Hash="md5-hash" />
</BlockList>
<MetadataPath Hash="md5-hash">metadata-file-path</MetadataPath>
<PropertiesPath Hash="md5-hash">properties-file-path</PropertiesPath>
</Blob>
</BlobList>
</Drive>
</DriveManifest>
Exemple de fichier journal (XML) pour chaque lecteur
[BeginUpdateRecord][2016/11/01 21:22:25.379][Type:ActivityRecord]
ActivityId: DriveInfo
DriveState: [BeginValue]
<?xml version="1.0" encoding="UTF-8"?>
<Drive>
<DriveId>drive-id</DriveId>
<BitLockerKey>*******</BitLockerKey>
<ManifestFile>\DriveManifest.xml</ManifestFile>
<ManifestHash>D863FE44F861AE0DA4DCEAEEFFCCCE68</ManifestHash> </Drive>
[EndValue]
SaveCommandOutput: Completed
[EndUpdateRecord]
Exemple de fichier journal de session (JRN) enregistrant la trace des sessions
[BeginUpdateRecord][2016/11/02 18:24:14.735][Type:NewJournalFile]
VocabularyVersion: 2013-02-01
[EndUpdateRecord]
[BeginUpdateRecord][2016/11/02 18:24:14.749][Type:ActivityRecord]
ActivityId: PrepImportDriveCommandContext
LogDirectory: F:\logs
[EndUpdateRecord]
[BeginUpdateRecord][2016/11/02 18:24:14.754][Type:ActivityRecord]
ActivityId: PrepImportDriveCommandContext
StorageAccountKey: *******
[EndUpdateRecord]
Questions fréquentes (FAQ)
Général
Présentation de l’outil WAImportExport
L’outil WAImportExport est l’outil de préparation et de réparation de disques, que vous pouvez utiliser avec le service Microsoft Azure Import/Export. Il permet de copier des données sur des disques durs que vous allez envoyer à un centre de données Azure. Lorsqu’un travail d’importation est terminé, vous pouvez utiliser cet outil pour réparer les objets blob endommagés, manquants ou en conflit avec d’autres objets blob. Lorsque vous recevez les disques d’un travail d’exportation, vous pouvez utiliser cet outil pour réparer tous les fichiers endommagés ou manquants sur les disques.
Comment l’outil WAImportExport fonctionne-t-il sur plusieurs répertoires et disques sources ?
Si le volume des données dépasse la capacité du disque, l’outil WAImportExport répartit les données sur plusieurs disques de manière optimisée. La copie des données sur plusieurs disques s’effectue en parallèle ou séquentiellement. Le nombre de disques sur lesquels les données peuvent être écrites simultanément n’est pas limité. L’outil répartit les données en fonction de la taille du disque et des dossiers. Il sélectionne le disque de manière optimisée en fonction de la taille des objets. Lors du chargement dans le compte de stockage, les données sont replacées dans l’arborescence de répertoires spécifiée.
Où puis-je trouver la version précédente de l’outil WAImportExport ?
L’outil WAImportExport propose toutes les fonctionnalités de l’outil WAImportExport V1. Il permet aux utilisateurs de spécifier plusieurs sources et d’écrire des données sur plusieurs disques. De plus, vous pouvez gérer facilement plusieurs emplacements sources à partir desquels copier des données dans un fichier CSV. Toutefois, si vous devez prendre en charge SAS ou si vous voulez copier une source unique sur un seul disque, vous pouvez télécharger l’outil WAImportExport V1 et consulter les informations de référence sur WAImportExport V1 pour obtenir de l’aide sur l’utilisation de cet outil.
Qu’est-ce qu’un ID de session ?
L’outil attend un paramètre de session de copie (/id) identique si l’objectif est de répartir les données sur plusieurs disques. Le fait de conserver le même nom de session de copie permet à l’utilisateur de copier les données d’un ou de plusieurs emplacements sources dans un ou plusieurs disques/répertoires cibles. La réutilisation du même ID de session permet à l’outil de reprendre la copie des fichiers là où il s’était arrêté la dernière fois.
Toutefois, il est impossible d’utiliser la même session de copie pour importer des données dans différents comptes de stockage.
Si le nom de la session de copie est identique pendant plusieurs exécutions de l’outil, le fichier journal (/logdir) et la clé du compte de stockage (/sk) doivent aussi l’être.
SessionId peut se composer de lettres, 0~9, trait de soulignement (_), tiret (-) ou hachage (#), et sa longueur doit être de 3~30.
par exemple, session-1 ou session#1 ou session_1
Qu’est-ce qu’un fichier journal ?
Chaque fois que vous exécutez l’outil WAImportExport pour copier des fichiers sur le disque dur, l’outil crée une session de copie. L’état de cette session de copie est consigné dans le fichier journal. Si une session est interrompue (par exemple, suite à une coupure de courant), elle peut être reprise en relançant l’outil et en spécifiant le fichier journal sur la ligne de commande.
Pour chaque disque dur que vous préparez avec l’outil Azure Import/Export, ce dernier crée un fichier journal nommé « <DriveID>.xml », où DriveID est le numéro de série lu par l’outil sur le disque. Vous devez avoir les fichiers journaux de tous vos disques pour créer le travail d’importation. Le fichier journal permet également de reprendre la préparation du disque là où l’outil a été interrompu.
Qu’est-ce qu’un répertoire de journaux ?
Le répertoire de journaux d’activité désigne le répertoire à utiliser pour stocker les journaux d’activité détaillés et les fichiers manifestes temporaires. Si ce paramètre n’est pas spécifié, le répertoire courant est utilisé comme répertoire de journaux. Les journaux d’activité sont détaillés.
Prérequis
Quelles sont les caractéristiques de mon disque ?
Un ou plusieurs disques durs SATA II ou III, ou SSD, 2,5 ou 3,5 pouces, vides et connectés à l’ordinateur de copie.
Comment puis-je activer BitLocker sur mon ordinateur ?
Le moyen le plus simple consiste à cliquer avec le bouton droit de la souris sur le disque système. Les options de BitLocker s’affichent si la fonctionnalité est activée. Elles ne s’affichent pas si la fonctionnalité est désactivée.
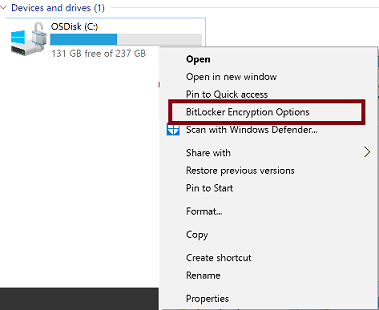
Cet article explique comment activer BitLocker.
Il est possible que votre ordinateur ne soit pas équipé d’une puce TPM. Si vous n’obtenez pas une sortie à l’aide de tpm.msc, reportez-vous à la question suivante.
Comment désactiver le module de plateforme sécurisée (TPM) de BitLocker ?
Notes
Dans le seul cas où leurs serveurs ne contiennent aucun module de plateforme sécurisée, vous devez désactiver la stratégie du module de plateforme sécurisée. Il n’est pas nécessaire de désactiver le module de plateforme sécurisée, s’il y en a déjà sur le serveur de l’utilisateur.
Pour désactiver le module de plateforme sécurisée dans BitLocker, procédez comme suit :
- Démarrez l’Éditeur de stratégie de groupe locale en tapant gpedit.msc dans une invite de commande. Si l’Éditeur de stratégie de groupe locale est indisponible, commencez par activer BitLocker. Consultez la question précédente.
- Ouvrez Stratégie ordinateur local > Configuration ordinateur > Modèles d’administration > Composants Windows> Chiffrement de lecteur BitLocker > Lecteurs du système d’exploitation.
- Modifiez la stratégie Exiger une authentification supplémentaire au démarrage.
- Réglez la stratégie sur Activé et vérifiez que la case à cocher Autoriser BitLocker sans un module de plateforme sécurisée compatible est activée.
Comment vérifier si .NET 4 ou version ultérieure est installé sur mon ordinateur ?
Toutes les versions de Microsoft .NET Framework sont installées dans le répertoire suivant : %windir%\Microsoft.NET\Framework\
Accédez à cet emplacement sur l’ordinateur censé exécuter l’outil. Recherchez le répertoire dont le nom commence par « v4 ». L’absence de ce répertoire signifie que .NET 4 n’est pas installé sur votre ordinateur. Vous pouvez télécharger .NET 4 sur votre ordinateur à l’aide de Microsoft .NET Framework 4 (programme d'installation web).
Limites
Combien de disques puis-je préparer/envoyer en même temps ?
Le nombre de disques que l’outil peut préparer n’est pas limité. Toutefois, il attend des lettres de disque en entrée. Cela le limite à 25 préparations de disque simultanées. Un travail peut gérer jusqu’à 10 disques à la fois. Si vous préparez plus de 10 disques ciblant le même compte de stockage, les disques peuvent être répartis entre plusieurs travaux.
Puis-je cibler plusieurs comptes de stockage ?
Lors d’une session de copie, un seul compte de stockage peut être utilisé par travail.
Fonctions
L’outil WAImportExport.exe chiffre-t-il mes données ?
Oui. Le chiffrement BitLocker est activé et obligatoire pour ce processus.
Comment mes données se présenteront-elles dans le compte de stockage ?
Même si elles sont réparties entre plusieurs disques, les données chargées dans le compte de stockage sont replacées dans l’arborescence de répertoires spécifiée dans le fichier dataset.csv.
Combien de disques d’entrée auront des E/S actives en parallèle pendant la copie ?
L’outil répartit les données entre les disques d’entrée, selon la taille des fichiers d’entrée. Cela dit, le nombre de disques actifs en parallèle dépend complètement de la nature des données d’entrée. En fonction de la taille de chaque fichier dans le fichier dataset.csv, un ou plusieurs disques peuvent avoir des E/S actives en parallèle. Pour plus d’informations, consultez la question suivante.
Comment l’outil répartit-il les fichiers entre les disques ?
L’outil WAImportExport lit et écrit les fichiers par lots, un lot contenant au maximum 100 000 fichiers. Cela signifie que 100 000 fichiers peuvent être écrits en parallèle. Plusieurs disques sont écrits simultanément si ces 100 000 fichiers sont répartis entre différents disques. Toutefois, l’écriture sur un ou plusieurs disques simultanément dépend de la taille totale du lot. Par exemple, si 100 000 fichiers de petite taille peuvent tenir sur un disque, l’outil ne les écrit que sur un disque pendant le traitement de ce lot.
Sortie de l’outil WAImportExport
Il existe deux fichiers journaux, lequel dois-je télécharger vers le portail Azure ?
Fichier XML : pour chaque disque dur que vous préparez avec l’outil WAImportExport, ce dernier crée un fichier journal nommé « <DriveID>.xml », où DriveID est le numéro de série lu par l’outil sur le disque. Vous devez avoir les fichiers journaux de tous vos disques pour créer le travail d’importation dans le portail Azure. Ce fichier journal permet également de reprendre la préparation du disque en cas d’interruption de l’outil.
Fichier JRN : le fichier journal portant l’extension .jrn contient l’état de toutes les sessions de copie pour un ensemble de disques durs. Il contient également les informations nécessaires à la création du travail d’importation. Vous devez toujours spécifier un fichier journal lorsque vous exécutez l’outil WAImportExport, ainsi qu’un ID de session de copie.
Étapes suivantes
- Configuration de l’outil Azure Import/Export
- Définition des propriétés et des métadonnées pendant le processus d’importation
- Exemple de workflow pour préparer des disques durs à un travail d’importation
- Référence rapide pour les commandes fréquemment utilisées
- Consultation de l’état du travail avec les fichiers journaux de copie
- Réparation d’un travail d’importation
- Réparation d’un travail d’exportation
- Résolution des problèmes associés à l’outil Azure Import-Export