Data quality for Fabric Lakehouse data estate (private preview)
Fabric OneLake is a single, unified, logical data lake for your whole organization. A data Lake processes large volumes of data from various sources. Like OneDrive, OneLake comes automatically with every Microsoft Fabric tenant and is designed to be the single place for all your analytics data. OneLake brings customers:
- One data lake for the entire organization
- One copy of data for use with multiple analytical engines
OneLake aims to give you the most value possible out of a single copy of data without data movement or duplication. You no longer need to copy data just to use it with another engine or to break down silos so you can analyze the data with data from other sources. You can use Microsoft Purview to catalog fabric data estate and measure data quality to govern and drive improvement action.
You can use shortcut for referencing to data that stored in other file locations. These file locations can be within the same workspace or across different workspaces, within OneLake or external to OneLake in Azure Data Lake Storage (ADLS), AWS S3, or Dataverse with more target locations coming soon. Data source location doesn't matter that much, OneLake shortcuts make files and folders look like you have them stored locally. When teams work independently in separate workspaces, shortcuts enable you to combine data across different business groups and domains into a virtual data product to fit a user’s specific needs.
You can use mirroring to bring data from various sources together into Fabric Mirroring in Fabric is a low-cost and low-latency solution to bring data from various systems together into a single analytics platform. You can continuously replicate your existing data estate directly into Fabric's OneLake, including data from Azure SQL Database, Azure Cosmos DB, and Snowflake. With the most up-to-date data in a queryable format in OneLake, you can now use all the different services in Fabric. For example, running analytics with Spark, executing notebooks, data engineering, visualizing through Power BI Reports, and more. The Delta tables can then be used everywhere Fabric, allowing users to accelerate their journey into Fabric.
Configure datamap scan
To configure datamap scan, you need to register data source that you want to scan.
Register Fabric OneLake
For scanning Fabric workspace, there are no changes to the existing experience to register a Fabric tenant as a data source. To register a new data source in your data catalog, follow these steps:
- Navigate to your Microsoft Purview account in the Microsoft Purview governance portal.
- Select Data Map on the left navigation pane.
- Select Register
- On Register sources, select Fabric
Refer to same tenant and cross tenant for setup instructions.
Set up datamap scan
For scanning Lakehouse subartifacts, there are no changes to the existing experience in Purview to set up a scan. There's one another step to grant the scan credential with at least Contributor role in the Fabric workspaces to extract the schema information from supported file formats.
Currently only service principal is supported as authentication method. The MSI support is still in backlog. The Lakehouse scan feature is in private preview. You need to contact with your Microoft Account team for allow listing your tenant.
Refer to same tenant and cross tenant for setup instructions.
Set up connection for fabric lakehouse scan
After you registered fabric lakehouse as a source, you can select fabric from the list of your registered data sources and select New scan. Add connection details as highlighted in below screenshots.

- Add SPN into Credential field
- Add azure resource name.

- Add Tenant ID
- Add Service Principle ID
- Add Key Vault connection
- Add Secret name

After completed data map scan, locate a lakehouse instance from Purview Data Catalog.

Browse lakehouse tables via the tables category.

Fabric Lakehouse data quality scan prerequisites
- Shortcut, mirror, or load your data to Fabric lakehouse in delta format.

Important
If you have added new tables, files or new set of data to Fabric lakehouse via morroring or shortcut then you need to run datamap scope scan to catalog those new set of data before adding those data asset to data product for data quality assessment.
- Grant Contributor right to your workspace for Purview MSI

- Add scanned data asset from lakehouse to the data products of the governance domain. Data Profiling and DQ scanning can only be done for the data assets associated with the data products under the governance domain.

For data profiling and data quality scan, we need to create data source connection as we're using different connector to connect data source and to scan data to capture data quality facts and dimensions. To set up connection:
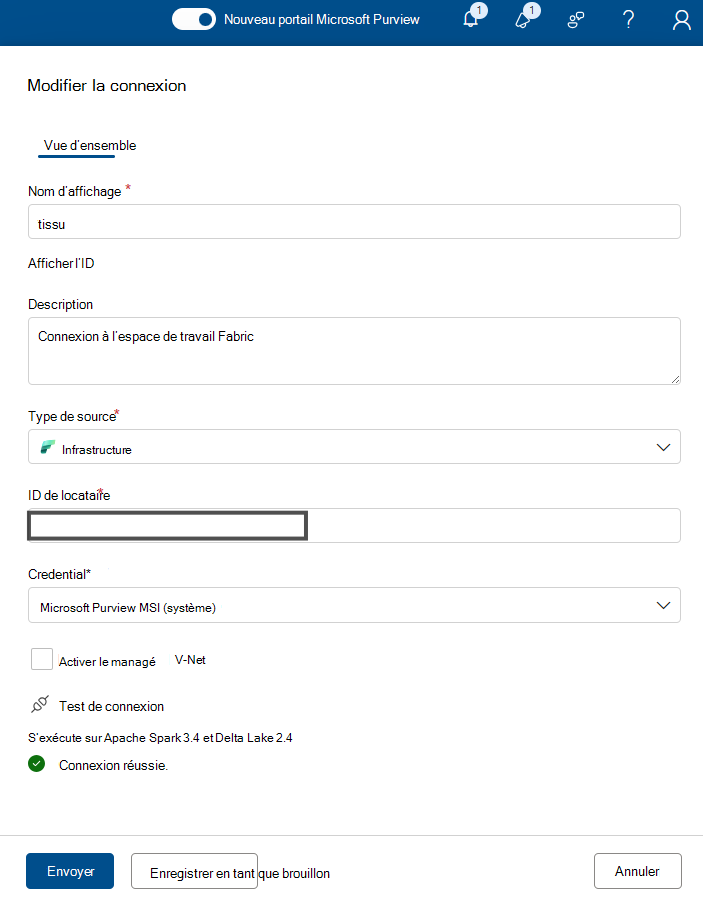
Go to Health management > Data quality > Select Governance domain > Select Manage tab > Select connection.
Select + New tab to open connection configuration page
Add connection Display name, and a good Description
Add Source type Fabric
Add Tenant ID
Add Credential - Microsoft Purview MSI
Test Connection to make sure that the configured connection is successful.

Important
- For DQ scan, purview MSI must have contributor access to Fabric workspace to connect Fabric workspace. To grant contributor access, open your fabric workspace > select three dots (...) > Select Workspace access > Add people or group > Add Purview MSI as Contributor
- Fabric tables must be in delta format.
- Fabric Lakehouse DQ scan feature is in private preview. To use this feature, please contact Microsoft accout team or Customer support team to allowlist your tenant. You need to provide these information for allow listing: Tenant ID, Organization name, Purview Account name, Purview Account ID, Azure Region, and Azure Subscription ID.
Profiling and Data Quality (DQ) scanning for data in Fabric Lakehouse
After completed connection setup successfully, you can profile, create and apply rules, and run Data Quality (DQ) scan of your data in Fabric Lakehouse. Follow the step-by-step guideline described in below:
- Associate a Lakehouse table to a data product for curation, discovery and subscription. For more details, follow the document -how to create and manage data products

- Profile Fabric lakehouse table. For more details, follow the document -how to configure and run data profiling of your data

- Configure and run data quality scan to measure data quality of a Fabric lakehouse table. For more details, follow the document - how to configure and run data quality scan

Important
- Make sure that your data are in delta format.
- Make sure the data map scan ran successfully, if not then rerun data map scan.
Limitation
Purview Data map support for fabric Lakehouse is in private preview. We need to allow-list your purview tenant to Purview data map and Fabric OneLake to enable Fabric Lakehouse table DQ scanning with Purview DQ. Contact your Microsoft account team to allowlist your tenant for Fabric Lakehouse support.
Data Quality for Parquet file is designed to support:
- A directory with Parquet Part File. For example: ./Sales/{Parquet Part Files}. The Fully Qualified Name must follow
https://(storage account).dfs.core.windows.net/(container)/path/path2/{SparkPartitions}. Make sure we do not have {n} patterns in directory/sub-directory structure, must rather be a direct FQN leading to {SparkPartitions}. - A directory with Partitioned Parquet Files, partitioned by columns within the dataset like sales data partitioned by year and month. For example: ./Sales/{Year=2018}/{Month=Dec}/{Parquet Part Files}.
Both of these essential scenarios which present a consistent parquet dataset schema are supported. Limitation: It isn't designed to or won't support N arbitrary Hierarchies of Directories with Parquet Files. We advise the customer to present data in (1) or (2) constructed structure. So recommending customer to follow the supported parquet standard or migrate their data to ACID compliant delta format.
Tip
For Data Map
- Ensure SPN has workspace permissions.
- Ensure scan connection uses SPN.
- I'd suggest running full scan if you are setting up lakehouse scan first time.
- Check that the ingested assets have been updated / refreshed
Data catalog
- DQ connection needs to use MSI credentials.
- Ideally create a new data product for first time testing lakehouse data DQ scan
- Add the ingested data assets, check that the data asset are updated.
- Try run profile, if successful, try running DQ rule. if not successful, try refreshing the asset schema (Schema> Schema management import schema)
- Some users also had to create a new Lakehouse and sample data just to check everything works from scratch. In some cases, working with assets that have been previously ingested in the data map the experience is not consistent.