Parcourir et examiner le score de qualité des données de votre patrimoine de données
Une fois que vous avez créé des règles de qualité des données et exécuté une analyse de la qualité des données, vos ressources de données reçoivent un score de qualité des données basé sur les résultats de vos règles. Cet article explique comment les scores sont calculés pour vous donner une compréhension plus approfondie de vos résultats de qualité des données et vous aider à développer des éléments d’action pour améliorer l’intégrité de vos données.
Comprendre les scores de qualité des données
L’objectif des règles de qualité des données est de fournir une description de l’état des données. En particulier, il montre à quel point les données sont éloignées de l’état idéal décrit par les règles. Chaque règle, lorsqu’elle s’exécute, produit un score qui décrit la proximité des données à l’état souhaité. La plupart des règles sont très simples ; ils divisent le nombre total de lignes qui ont réussi l’évaluation par le nombre total de lignes pour arriver au score.
La formule utilisée pour calculer le score de qualité des données d’une règle par rapport aux données d’une colonne est la suivante :
[(total number of passed records)/(passed records + failed records + miscast records + empty records + ignored records)]
- Numérateur = nombre d’enregistrements passés
- Dénominateur = nombre total d’enregistrements (nombre d’enregistrements passés + nombre d’enregistrements ayant échoué + nombre d’enregistrements de mauvaise diffusion + nombre de vides + nombre d’enregistrements ignorés)
- Passé : nombre d’enregistrements qui ont passé une règle appliquée
- Non précieux : les colonnes requises pour évaluer cette règle ne sont pas précieuses
- Échec : nombre d’enregistrements ayant échoué à une règle appliquée
- Mauvaise diffusion : le type de données de la ressource et le type que le client a répertorié comme ne correspondent pas. Il ne peut pas être converti en type exprimé.
- Vide : enregistrements null ou vides
- Ignoré : les lignes n’ont pas participé à l’évaluation de la règle. Les clients peuvent exprimer des lignes à ignorer. Comme ignorer toutes les lignes qui ont e-mail = « n/a » ou Ignorer toutes les lignes où departmentCode = 'test' ou 'internal'
Qualité des données Microsoft Purview donne ensuite une idée de l’état de chaque colonne en générant un score de colonne. Ce score est la moyenne de tous les scores des règles sur cette colonne.

Une fois les scores de colonne calculés, la formule utilisée pour calculer le score de qualité des données en pourcentage moyen pour les produits de données et les domaines de gouvernance est la suivante :
[(Percentage 1 + Percentage 2) / (Sample size 1 + Sample size 2)] x 100
(Le score est multiplié par 100 pour rendre les scores plus lisibles.)
Exemple de calcul
Imaginons qu’il existe une colonne sur laquelle la règle « Champs vides/vides » n’est pas définie. Cela implique que les valeurs Null sont autorisées pour cette colonne. Par conséquent, certaines règles, comme la règle de valeurs uniques, filtrent les valeurs Null dans ce cas.
Par exemple : si la ressource a 10 000 lignes dans une table, mais que 3 000 étaient null et que 500 n’étaient pas uniques, le score serait : ((10000 - 3000 - 500)/(10000 - 3000) )* 100 = 93
Les lignes null sont ignorées lors de l’évaluation des données et de la détermination d’un score.
Scores de règle spécifiques
Pour les règles personnalisées , il existe une fonctionnalité similaire à celle que vous pouvez voir pour la règle de valeurs uniques, mais dans ce cas, le filtre n’est pas sur les valeurs Null, mais plutôt sur l’expression de filtre.
Certaines règles, comme la règle d’actualisation, sont soit pass ou fail. Ainsi, leurs scores seront soit 0, soit 100. Et la règle d’actualisation est appliquée au niveau de la ressource de données, et non au niveau des colonnes.
Détails et historique de la règle
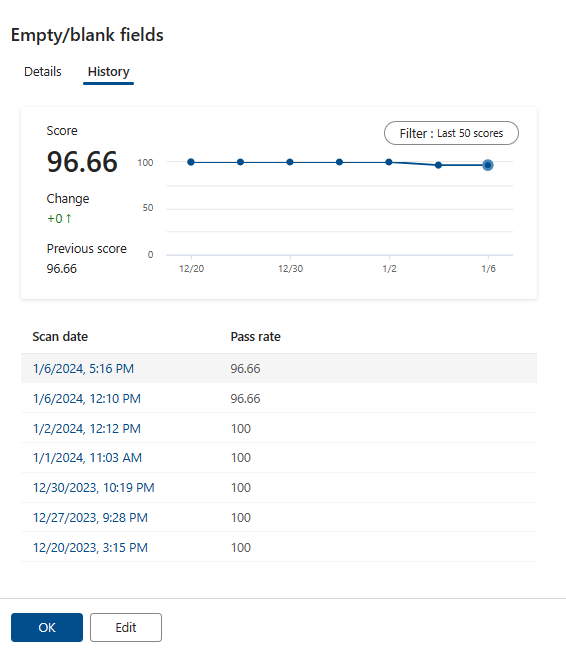
Vous pouvez afficher les détails et l’historique des scores de règle en sélectionnant une règle. En sélectionnant un nom de règle spécifique et en accédant à l’onglet Historique des règles, vous verrez la tendance des différentes exécutions d’analyse pour la règle particulière.
Les détails de la règle fournissent des informations sur le nombre de lignes passées, ayant échoué et ignorées pour les différentes exécutions de la règle particulière. Les règles qui sont à l’état brouillon (état OFF) n’auront pas leurs scores contribuer au score global. Les règles dans un état brouillon ne seront pas exécutées du tout pendant les analyses de qualité et n’auront donc pas de scores.
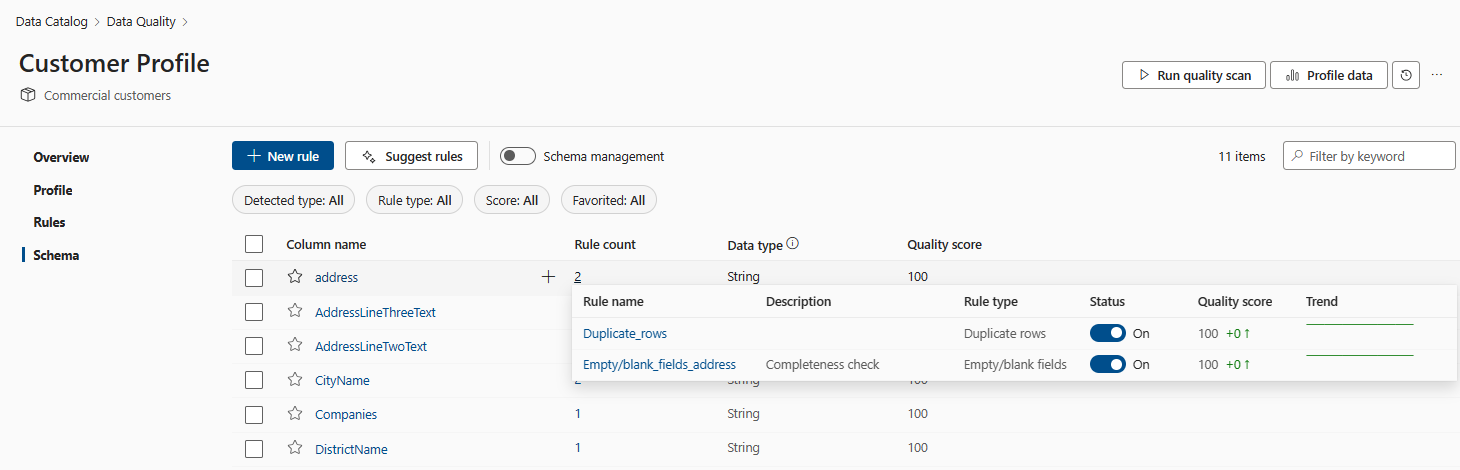
Les colonnes et les règles ont une relation plusieurs à plusieurs, la même règle peut être appliquée à plusieurs colonnes et de nombreuses règles peuvent être appliquées à la même colonne. Vous pouvez afficher le modèle de tendance de chaque règle en affichant la ligne Tendance dans le volet Schéma .
Les tendances du score de qualité des données au niveau des ressources sont disponibles pour les 50 dernières exécutions. Cette tendance de score de qualité aide les gestionnaires de la qualité des données à surveiller les tendances et les fluctuations de la qualité des données d’un mois à l’autre. La qualité des données peut également déclencher des alertes pour chaque analyse de la qualité des données si le score de qualité ne répond pas au seuil ou aux attentes de l’entreprise.

Le score global est la moyenne de toutes les règles de production définies sur la ressource. Le score global au niveau de la ressource est également relambré au niveau du produit de données et au niveau du domaine de gouvernance. Le score global est destiné à être la définition officielle de l’état de la ressource de données, du produit de données et du domaine de gouvernance dans le contexte de la qualité des données.
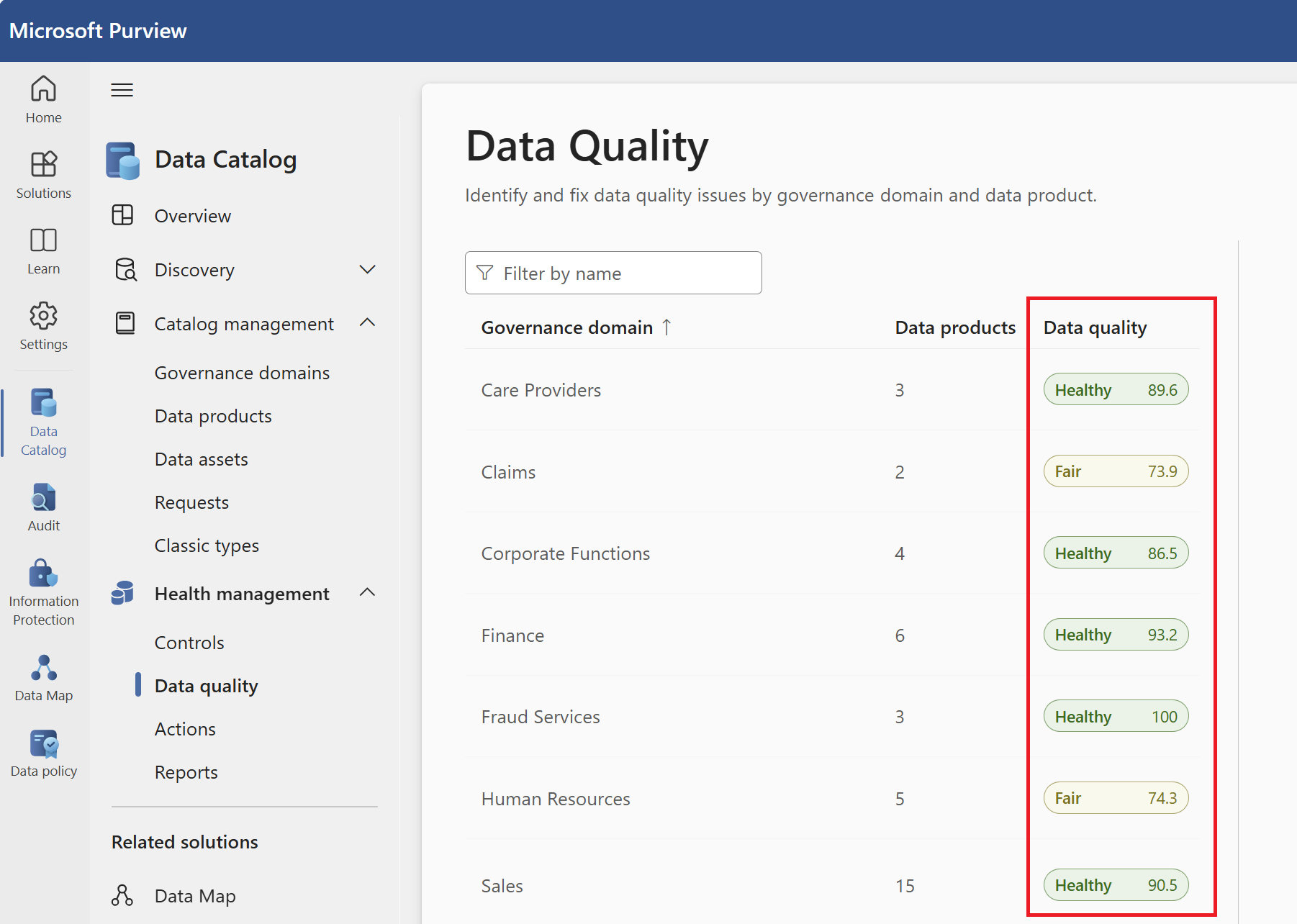
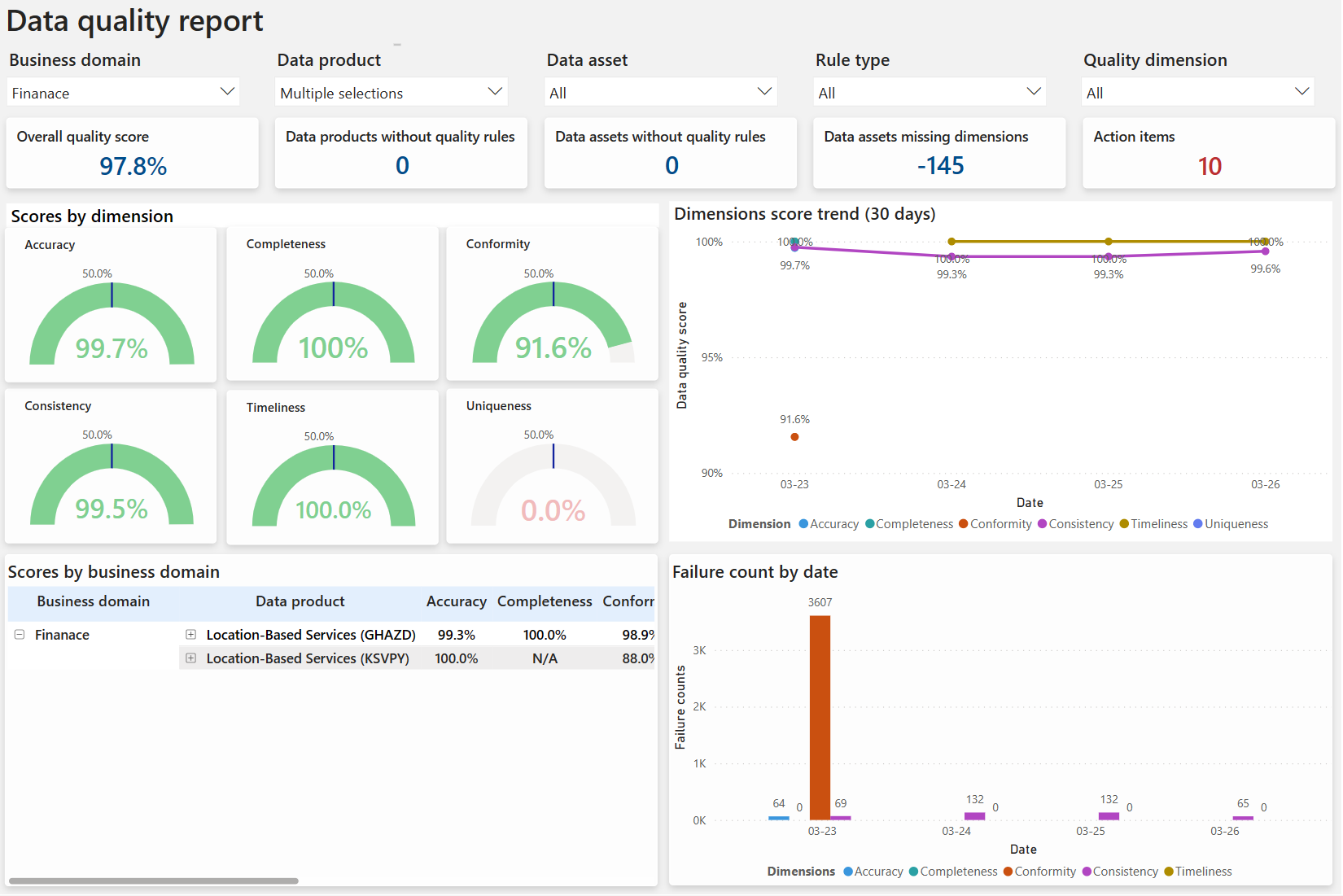
Un rapport de synthèse est créé pour les dimensions de qualité des données. Ce rapport contient le score de qualité des données pour chaque dimension de qualité des données. Le score global du domaine de gouvernance est également publié dans ce rapport. Vous pouvez parcourir le score de qualité pour chaque domaine de gouvernance, produit de données et ressource de données à partir de ce rapport Power BI.


Remarque
Les dimensions de qualité des données sont des termes reconnus utilisés par les professionnels des données pour décrire une fonctionnalité de données qui peut être mesurée ou évaluée par rapport à des normes définies afin de quantifier le niveau de qualité des données que nous utilisons pour gérer notre activité.