Se connecter à des bases de données metastore Hive et les gérer dans Microsoft Purview
Cet article explique comment inscrire des bases de données metastore Hive et comment s’authentifier et interagir avec des bases de données de metastore Hive dans Microsoft Purview. Pour plus d’informations sur Microsoft Purview, consultez l’article d’introduction.
Fonctionnalités prises en charge
| Extraction de métadonnées | Analyse complète | Analyse incrémentielle | Analyse délimitée | Classification | Étiquetage | Stratégie d’accès | Traçabilité | Partage de données | Affichage en direct |
|---|---|---|---|---|---|---|---|---|---|
| Oui | Oui | Non | Oui | Non | Non | Non | Oui* | Non | Non |
* Outre la traçabilité des ressources au sein de la source de données, la traçabilité est également prise en charge si le jeu de données est utilisé comme source/récepteur dans le pipeline Data Factory ou Synapse.
Les versions de Hive prises en charge sont 2.x à 3.x. Les plateformes prises en charge sont Apache Hadoop, Cloudera et Hortonworks. Si vous souhaitez analyser Azure Databricks, il est recommandé d’utiliser le connecteur Azure Databricks, qui est plus compatible et plus convivial.
Lors de l’analyse de la source du metastore Hive, Microsoft Purview prend en charge :
Extraction de métadonnées techniques, notamment :
- Serveur
- Bases de données
- Tables incluant les colonnes, les clés étrangères, les contraintes uniques et la description du stockage
- Affichages, y compris les colonnes et la description du stockage
Extraction de la traçabilité statique sur les relations de ressources entre les tables et les vues.
Lors de la configuration de l’analyse, vous pouvez choisir d’analyser l’intégralité d’une base de données de metastore Hive ou d’étendre l’analyse à un sous-ensemble de schémas correspondant aux noms ou modèles de nom donnés.
Limitations connues
Lorsque l’objet est supprimé de la source de données, l’analyse suivante ne supprime pas automatiquement la ressource correspondante dans Microsoft Purview.
Configuration requise
Vous devez disposer d’un compte Azure avec un abonnement actif. Créez un compte gratuitement.
Vous devez disposer d’un compte Microsoft Purview actif.
Vous avez besoin des autorisations Administrateur de source de données et Lecteur de données pour inscrire une source et la gérer dans le portail de gouvernance Microsoft Purview. Pour plus d’informations sur les autorisations, consultez Contrôle d’accès dans Microsoft Purview.
Si votre source de données n’est pas accessible publiquement, configurez le dernier runtime d’intégration auto-hébergé.
-
Choisissez le runtime d’intégration approprié pour votre scénario :
-
Pour utiliser un runtime d’intégration auto-hébergé :
- Suivez l’article pour créer et configurer un runtime d’intégration auto-hébergé.
- Vérifiez que JDK 11 est installé sur l’ordinateur sur lequel le runtime d’intégration auto-hébergé est installé. Redémarrez la machine après avoir installé le JDK pour qu’il prenne effet.
- Vérifiez que Visual C++ Redistributable (version Visual Studio 2012 Update 4 ou ultérieure) est installé sur l’ordinateur sur lequel le runtime d’intégration auto-hébergé est en cours d’exécution. Si cette mise à jour n’est pas installée, téléchargez-la maintenant.
- Téléchargez le pilote JDBC de la base de données du metastore Hive sur l’ordinateur sur lequel votre runtime d’intégration auto-hébergé est en cours d’exécution. Par exemple, si la base de données est mssql, téléchargez le pilote JDBC de Microsoft pour SQL Server. Notez le chemin du dossier que vous utiliserez pour configurer l’analyse.
-
Pour utiliser un runtime d’intégration auto-hébergé pris en charge par Kubernetes :
- Suivez l’article pour créer et configurer un runtime d’intégration pris en charge par Kubernetes.
- Téléchargez le pilote JDBC de la base de données du metastore Hive sur l’ordinateur sur lequel votre runtime d’intégration auto-hébergé est en cours d’exécution. Par exemple, si la base de données est mssql, téléchargez le pilote JDBC de Microsoft pour SQL Server. Notez le chemin du dossier que vous utiliserez pour configurer l’analyse.
-
Pour utiliser un runtime d’intégration auto-hébergé :
Remarque
Le pilote JDBC doit être accessible par le runtime d’intégration auto-hébergé. Par défaut, le runtime d’intégration auto-hébergé utilise le compte de service local « NT SERVICE\DIAHostService ». Vérifiez qu’il dispose des autorisations « Lire et exécuter » et « Lister le contenu du dossier » sur le dossier du pilote.
-
Choisissez le runtime d’intégration approprié pour votre scénario :
Inscrire
Cette section explique comment inscrire une base de données de metastore Hive dans Microsoft Purview à l’aide du portail de gouvernance Microsoft Purview.
La seule authentification prise en charge pour une base de données de metastore Hive est l’authentification de base.
Ouvrez le portail de gouvernance Microsoft Purview en :
- Accédez directement à https://web.purview.azure.com votre compte Microsoft Purview et sélectionnez-les.
- Ouverture du Portail Azure, recherchez et sélectionnez le compte Microsoft Purview. Sélectionnez le bouton Portail de gouvernance Microsoft Purview .
Sélectionnez Data Map dans le volet gauche.
Sélectionner Inscription.
Dans Inscrire des sources, sélectionnez Metastore> HiveContinuer.
Dans l’écran Inscrire des sources (metastore Hive), procédez comme suit :
Pour Nom, entrez un nom que Microsoft Purview listera comme source de données.
Pour URL du cluster Hive, entrez une valeur que vous obtenez à partir de l’URL Ambari. Par exemple, entrez hive.azurehdinsight.net.
Pour URL du serveur de metastore Hive, entrez une URL pour le serveur. Par exemple, entrez sqlserver://hive.database.windows.net.
Sélectionnez une collection dans la liste.
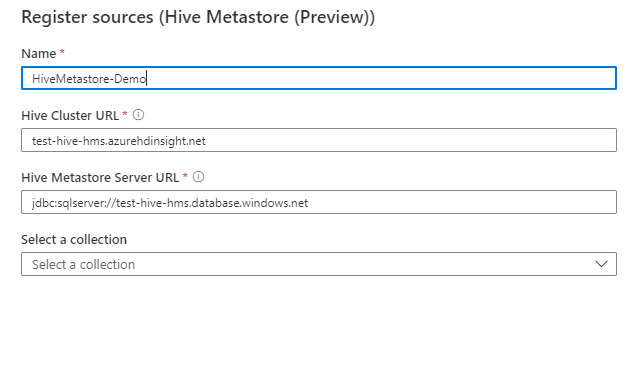
Sélectionnez Terminer.
Analyser
Conseil
Pour résoudre les problèmes liés à l’analyse :
- Vérifiez que vous avez suivi toutes les conditions préalables.
- Consultez notre documentation sur la résolution des problèmes d’analyse.
Procédez comme suit pour analyser les bases de données du metastore Hive afin d’identifier automatiquement les ressources. Pour plus d’informations sur l’analyse en général, consultez Analyses et ingestion dans Microsoft Purview.
Dans le Centre de gestion, sélectionnez Runtimes d’intégration. Assurez-vous qu’un runtime d’intégration auto-hébergé est configuré. S’il n’est pas configuré, suivez les étapes décrites dans Conditions préalables.
Accédez à Sources.
Sélectionnez la base de données Hive Metastore inscrite.
Sélectionnez + Nouvelle analyse.
Fournissez les détails suivants :
Nom : entrez un nom pour l’analyse.
Se connecter via le runtime d’intégration : sélectionnez le runtime d’intégration auto-hébergé configuré.
Informations d’identification : sélectionnez les informations d’identification pour vous connecter à votre source de données. Veillez à :
- Sélectionnez Authentification de base lors de la création d’informations d’identification.
- Indiquez le nom d’utilisateur metastore dans la zone appropriée.
- Stockez le mot de passe du metastore dans la clé secrète.
Pour plus d’informations, consultez Informations d’identification pour l’authentification source dans Microsoft Purview.
Emplacement du pilote JDBC du metastore : spécifiez le chemin d’accès à l’emplacement du pilote JDBC sur votre ordinateur où s’exécute le runtime d’intégration auto-hôte. Par exemple :
D:\Drivers\HiveMetastore.- Pour le runtime d’intégration auto-hébergé sur un ordinateur local :
D:\Drivers\HiveMetastore. Il s’agit du chemin d’accès à l’emplacement du dossier JAR valide. La valeur doit être un chemin d’accès de fichier absolu valide et ne contient pas d’espace. Assurez-vous que le pilote est accessible par le runtime d’intégration auto-hébergé ; Pour en savoir plus, consultez la section relative aux conditions préalables. - Pour le runtime d’intégration auto-hébergé pris en charge par Kubernetes :
./drivers/HiveMetastore. Il s’agit du chemin d’accès à l’emplacement du dossier JAR valide. La valeur doit être un chemin de fichier relatif valide. Reportez-vous à la documentation pour configurer une analyse avec des pilotes externes pour charger les pilotes à l’avance.
- Pour le runtime d’intégration auto-hébergé sur un ordinateur local :
Classe de pilote JDBC metastore : indiquez le nom de classe du pilote de connexion. Par exemple, entrez \com.microsoft.sqlserver.jdbc.SQLServerDriver.
URL JDBC du metastore : fournissez la valeur de l’URL de connexion et définissez la connexion à l’URL du serveur de base de données metastore. Par exemple :
jdbc:sqlserver://hive.database.windows.net;database=hive;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=300.Remarque
Lorsque vous copiez l’URL à partir dehive-site.xml, supprimez
amp;de la chaîne ou l’analyse échoue.Téléchargez le certificat SSL sur l’ordinateur du runtime d’intégration auto-hébergé, puis mettez à jour le chemin d’accès à l’emplacement du certificat SSL sur votre ordinateur dans l’URL.
Lorsque vous entrez des chemins d’accès de fichiers locaux dans la configuration de l’analyse, remplacez le caractère séparateur de chemin d’accès Windows d’une barre oblique (
\) par une barre oblique (/). Par exemple, si vous placez le certificat SSL sur le chemin de fichier local D :\Drivers\SSLCert\BaltimoreCyberTrustRoot.crt.pem, remplacez la valeur duserverSslCertparamètre par D :/Drivers/SSLCert/BaltimoreCyberTrustRoot.crt.pem.La valeur URL JDBC du metastore ressemble à cet exemple :
jdbc:mariadb://samplehost.mysql.database.azure.com:3306/XXXXXXXXXXXXXXXX?useSSL=true&enabledSslProtocolSuites=TLSv1,TLSv1.1,TLSv1.2&serverSslCert=D:/Drivers/SSLCert/BaltimoreCyberTrustRoot.crt.pemNom de la base de données metastore : indiquez le nom de la base de données du metastore Hive.
Schéma : spécifiez une liste de schémas Hive à importer. Par exemple : schema1 ; schema2.
Tous les schémas utilisateur sont importés si cette liste est vide. Tous les schémas système (par exemple, SysAdmin) et les objets sont ignorés par défaut.
Les modèles de nom de schéma acceptables qui utilisent la syntaxe d’expression SQL
LIKEincluent le signe de pourcentage (%). Par exemple,A%; %B; %C%; Dsignifie :- Commencer par A ou
- Terminer par B ou
- Contenir C ou
- Égal à D
L’utilisation de
NOTet de caractères spéciaux n’est pas acceptable.Mémoire maximale disponible : mémoire maximale (en gigaoctets) disponible sur l’ordinateur du client pour les processus d’analyse à utiliser. Cette valeur dépend de la taille de la base de données du metastore Hive à analyser.
Remarque
En règle générale, fournissez 1 Go de mémoire pour 1 000 tables.
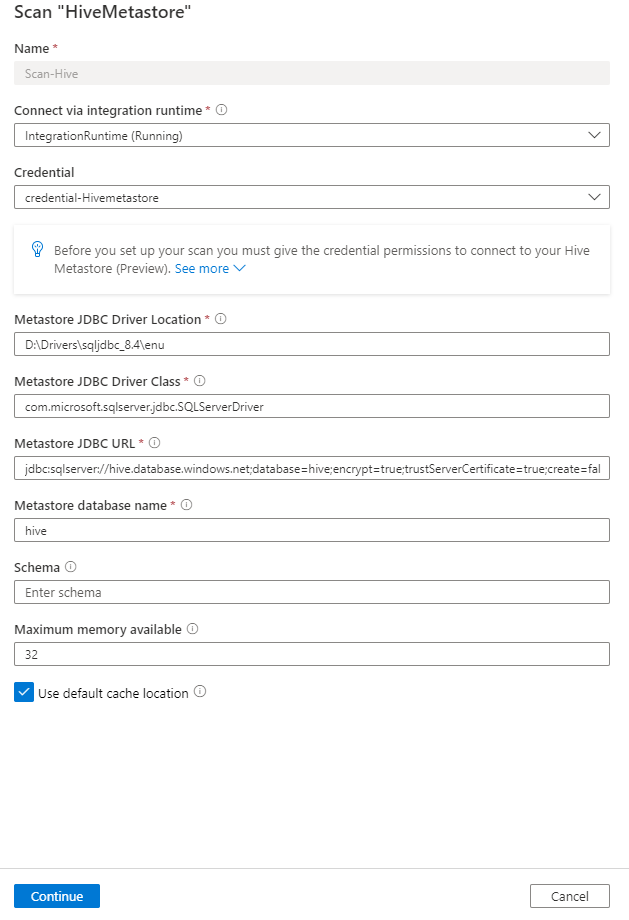
Cliquez sur Continuer.
Pour Déclencheur d’analyse, choisissez de configurer une planification ou d’exécuter l’analyse une seule fois.
Passez en revue votre analyse et sélectionnez Enregistrer et exécuter.
Afficher vos analyses et exécutions d’analyse
Pour afficher les analyses existantes :
- Accédez au portail Microsoft Purview. Dans le volet gauche, sélectionnez Mappage de données.
- Sélectionnez la source de données. Vous pouvez afficher une liste des analyses existantes sur cette source de données sous Analyses récentes, ou vous pouvez afficher toutes les analyses sous l’onglet Analyses .
- Sélectionnez l’analyse qui contient les résultats que vous souhaitez afficher. Le volet affiche toutes les exécutions d’analyse précédentes, ainsi que les status et les métriques pour chaque exécution d’analyse.
- Sélectionnez l’ID d’exécution pour case activée les détails de l’exécution de l’analyse.
Gérer vos analyses
Pour modifier, annuler ou supprimer une analyse :
Accédez au portail Microsoft Purview. Dans le volet gauche, sélectionnez Mappage de données.
Sélectionnez la source de données. Vous pouvez afficher une liste des analyses existantes sur cette source de données sous Analyses récentes, ou vous pouvez afficher toutes les analyses sous l’onglet Analyses .
Sélectionnez l’analyse que vous souhaitez gérer. Vous pouvez ensuite :
- Modifiez l’analyse en sélectionnant Modifier l’analyse.
- Annulez une analyse en cours en sélectionnant Annuler l’exécution de l’analyse.
- Supprimez votre analyse en sélectionnant Supprimer l’analyse.
Remarque
- La suppression de votre analyse ne supprime pas les ressources de catalogue créées à partir d’analyses précédentes.
Traçabilité
Après avoir analysé la source de votre metastore Hive, vous pouvez parcourir le catalogue de données ou rechercher dans le catalogue de données pour afficher les détails de la ressource.
Accédez à l’onglet Ressource -> Traçabilité, vous pouvez voir la relation de ressource le cas échéant. Reportez-vous à la section Fonctionnalités prises en charge pour les scénarios de traçabilité du metastore Hive pris en charge. Pour plus d’informations sur la traçabilité en général, consultez le guide de l’utilisateur sur la traçabilité et la traçabilité des données.
Étapes suivantes
Maintenant que vous avez inscrit votre source, utilisez les guides suivants pour en savoir plus sur Microsoft Purview et vos données :