Scénarios plus avancés pour la télémétrie
Remarque
Cet article utilise le tableau de bord Aspire pour l’illustration. Si vous préférez utiliser d’autres outils, reportez-vous à la documentation de l’outil que vous utilisez dans les instructions de configuration.
Appel automatique de fonction
L’appel automatique de fonction est une fonctionnalité de noyau sémantique qui permet au noyau d’exécuter automatiquement des fonctions lorsque le modèle répond avec des appels de fonction et de fournir les résultats au modèle. Cette fonctionnalité est utile pour les scénarios où une requête nécessite plusieurs itérations d’appels de fonction pour obtenir une réponse finale en langage naturel. Pour plus d’informations, consultez ces exemples GitHub.
Remarque
L’appel de fonction n’est pas pris en charge par tous les modèles.
Conseil
Vous entendez le terme « outils » et « appel d’outils » parfois utilisé de manière interchangeable avec « fonctions » et « appel de fonction ».
Prérequis
- Un déploiement d’achèvement de conversation Azure OpenAI qui prend en charge l’appel de fonction.
- Docker
- Dernier SDK .Net pour votre système d’exploitation.
- Un déploiement d’achèvement de conversation Azure OpenAI qui prend en charge l’appel de fonction.
- Docker
- Python 3.10, 3.11 ou 3.12 installé sur votre ordinateur.
Remarque
L’observabilité du noyau sémantique n’est pas encore disponible pour Java.
Programme d’installation
Créer une application console
Dans un terminal, exécutez la commande suivante pour créer une application console en C# :
dotnet new console -n TelemetryAutoFunctionCallingQuickstart
Accédez au répertoire du projet nouvellement créé une fois la commande terminée.
Installer les packages nécessaires
Noyau sémantique
dotnet add package Microsoft.SemanticKernelOpenTelemetry Console Exporter
dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol
Créer une application simple avec le noyau sémantique
Dans le répertoire du projet, ouvrez le Program.cs fichier avec votre éditeur favori. Nous allons créer une application simple qui utilise le noyau sémantique pour envoyer une invite à un modèle d’achèvement de conversation. Remplacez le contenu existant par le code suivant et renseignez les valeurs requises pour deploymentName, endpointet apiKey:
using System.ComponentModel;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using OpenTelemetry;
using OpenTelemetry.Logs;
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
namespace TelemetryAutoFunctionCallingQuickstart
{
class BookingPlugin
{
[KernelFunction("FindAvailableRooms")]
[Description("Finds available conference rooms for today.")]
public async Task<List<string>> FindAvailableRoomsAsync()
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return ["Room 101", "Room 201", "Room 301"];
}
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return $"Room {room} booked.";
}
}
class Program
{
static async Task Main(string[] args)
{
// Endpoint to the Aspire Dashboard
var endpoint = "http://localhost:4317";
var resourceBuilder = ResourceBuilder
.CreateDefault()
.AddService("TelemetryAspireDashboardQuickstart");
// Enable model diagnostics with sensitive data.
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnosticsSensitive", true);
using var traceProvider = Sdk.CreateTracerProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddSource("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var meterProvider = Sdk.CreateMeterProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddMeter("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var loggerFactory = LoggerFactory.Create(builder =>
{
// Add OpenTelemetry as a logging provider
builder.AddOpenTelemetry(options =>
{
options.SetResourceBuilder(resourceBuilder);
options.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint));
// Format log messages. This is default to false.
options.IncludeFormattedMessage = true;
options.IncludeScopes = true;
});
builder.SetMinimumLevel(LogLevel.Information);
});
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddSingleton(loggerFactory);
builder.AddAzureOpenAIChatCompletion(
deploymentName: "your-deployment-name",
endpoint: "your-azure-openai-endpoint",
apiKey: "your-azure-openai-api-key"
);
builder.Plugins.AddFromType<BookingPlugin>();
Kernel kernel = builder.Build();
var answer = await kernel.InvokePromptAsync(
"Reserve a conference room for me today.",
new KernelArguments(
new OpenAIPromptExecutionSettings {
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
}
)
);
Console.WriteLine(answer);
}
}
}
Dans le code ci-dessus, nous définissons d’abord un plug-in de réservation de salle de conférence fictif avec deux fonctions : FindAvailableRoomsAsync et BookRoomAsync. Nous créons ensuite une application console simple qui inscrit le plug-in au noyau et demandez au noyau d’appeler automatiquement les fonctions si nécessaire.
Créer un environnement virtuel Python
python -m venv telemetry-auto-function-calling-quickstart
Activez l’environnement virtuel.
telemetry-auto-function-calling-quickstart\Scripts\activate
Installer les packages nécessaires
pip install semantic-kernel opentelemetry-exporter-otlp-proto-grpc
Créer un script Python simple avec le noyau sémantique
Créez un script Python et ouvrez-le avec votre éditeur favori.
New-Item -Path telemetry_auto_function_calling_quickstart.py -ItemType file
Nous allons créer un script Python simple qui utilise le noyau sémantique pour envoyer une invite à un modèle d’achèvement de conversation. Remplacez le contenu existant par le code suivant et renseignez les valeurs requises pour deployment_name, endpointet api_key:
import asyncio
import logging
from typing import Annotated
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.metrics import set_meter_provider
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.metrics.view import DropAggregation, View
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.semconv.resource import ResourceAttributes
from opentelemetry.trace import set_tracer_provider
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.prompt_execution_settings import PromptExecutionSettings
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.functions.kernel_function_decorator import kernel_function
class BookingPlugin:
@kernel_function(
name="find_available_rooms",
description="Find available conference rooms for today.",
)
def find_available_rooms(self,) -> Annotated[list[str], "A list of available rooms."]:
return ["Room 101", "Room 201", "Room 301"]
@kernel_function(
name="book_room",
description="Book a conference room.",
)
def book_room(self, room: str) -> Annotated[str, "A confirmation message."]:
return f"Room {room} booked."
# Endpoint to the Aspire Dashboard
endpoint = "http://localhost:4317"
# Create a resource to represent the service/sample
resource = Resource.create({ResourceAttributes.SERVICE_NAME: "telemetry-aspire-dashboard-quickstart"})
def set_up_logging():
exporter = OTLPLogExporter(endpoint=endpoint)
# Create and set a global logger provider for the application.
logger_provider = LoggerProvider(resource=resource)
# Log processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
logger_provider.add_log_record_processor(BatchLogRecordProcessor(exporter))
# Sets the global default logger provider
set_logger_provider(logger_provider)
# Create a logging handler to write logging records, in OTLP format, to the exporter.
handler = LoggingHandler()
# Add filters to the handler to only process records from semantic_kernel.
handler.addFilter(logging.Filter("semantic_kernel"))
# Attach the handler to the root logger. `getLogger()` with no arguments returns the root logger.
# Events from all child loggers will be processed by this handler.
logger = logging.getLogger()
logger.addHandler(handler)
logger.setLevel(logging.INFO)
def set_up_tracing():
exporter = OTLPSpanExporter(endpoint=endpoint)
# Initialize a trace provider for the application. This is a factory for creating tracers.
tracer_provider = TracerProvider(resource=resource)
# Span processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
tracer_provider.add_span_processor(BatchSpanProcessor(exporter))
# Sets the global default tracer provider
set_tracer_provider(tracer_provider)
def set_up_metrics():
exporter = OTLPMetricExporter(endpoint=endpoint)
# Initialize a metric provider for the application. This is a factory for creating meters.
meter_provider = MeterProvider(
metric_readers=[PeriodicExportingMetricReader(exporter, export_interval_millis=5000)],
resource=resource,
views=[
# Dropping all instrument names except for those starting with "semantic_kernel"
View(instrument_name="*", aggregation=DropAggregation()),
View(instrument_name="semantic_kernel*"),
],
)
# Sets the global default meter provider
set_meter_provider(meter_provider)
# This must be done before any other telemetry calls
set_up_logging()
set_up_tracing()
set_up_metrics()
async def main():
# Create a kernel and add a service
kernel = Kernel()
kernel.add_service(AzureChatCompletion(
api_key="your-azure-openai-api-key",
endpoint="your-azure-openai-endpoint",
deployment_name="your-deployment-name"
))
kernel.add_plugin(BookingPlugin(), "BookingPlugin")
answer = await kernel.invoke_prompt(
"Reserve a conference room for me today.",
arguments=KernelArguments(
settings=PromptExecutionSettings(
function_choice_behavior=FunctionChoiceBehavior.Auto(),
),
),
)
print(answer)
if __name__ == "__main__":
asyncio.run(main())
Dans le code ci-dessus, nous définissons d’abord un plug-in de réservation de salle de conférence fictif avec deux fonctions : find_available_rooms et book_room. Nous créons ensuite un script Python simple qui inscrit le plug-in au noyau et demandez au noyau d’appeler automatiquement les fonctions si nécessaire.
Variables d'environnement
Reportez-vous à cet article pour plus d’informations sur la configuration des variables d’environnement requises pour permettre au noyau d’émettre des étendues pour les connecteurs IA.
Remarque
L’observabilité du noyau sémantique n’est pas encore disponible pour Java.
Démarrer le tableau de bord Aspire
Suivez les instructions ci-dessous pour démarrer le tableau de bord. Une fois le tableau de bord en cours d’exécution, ouvrez un navigateur et accédez à http://localhost:18888 l’accès au tableau de bord.
Exécuter
Exécutez l’application console avec la commande suivante :
dotnet run
Exécutez le script Python avec la commande suivante :
python telemetry_auto_function_calling_quickstart.py
Remarque
L’observabilité du noyau sémantique n’est pas encore disponible pour Java.
Le résultat doit ressembler à ce qui suit :
Room 101 has been successfully booked for you today.
Inspecter les données de télémétrie
Après avoir exécuté l’application, accédez au tableau de bord pour inspecter les données de télémétrie.
Recherchez la trace de l’application sous l’onglet Traces . Vous devez avoir cinq étendues dans la trace :
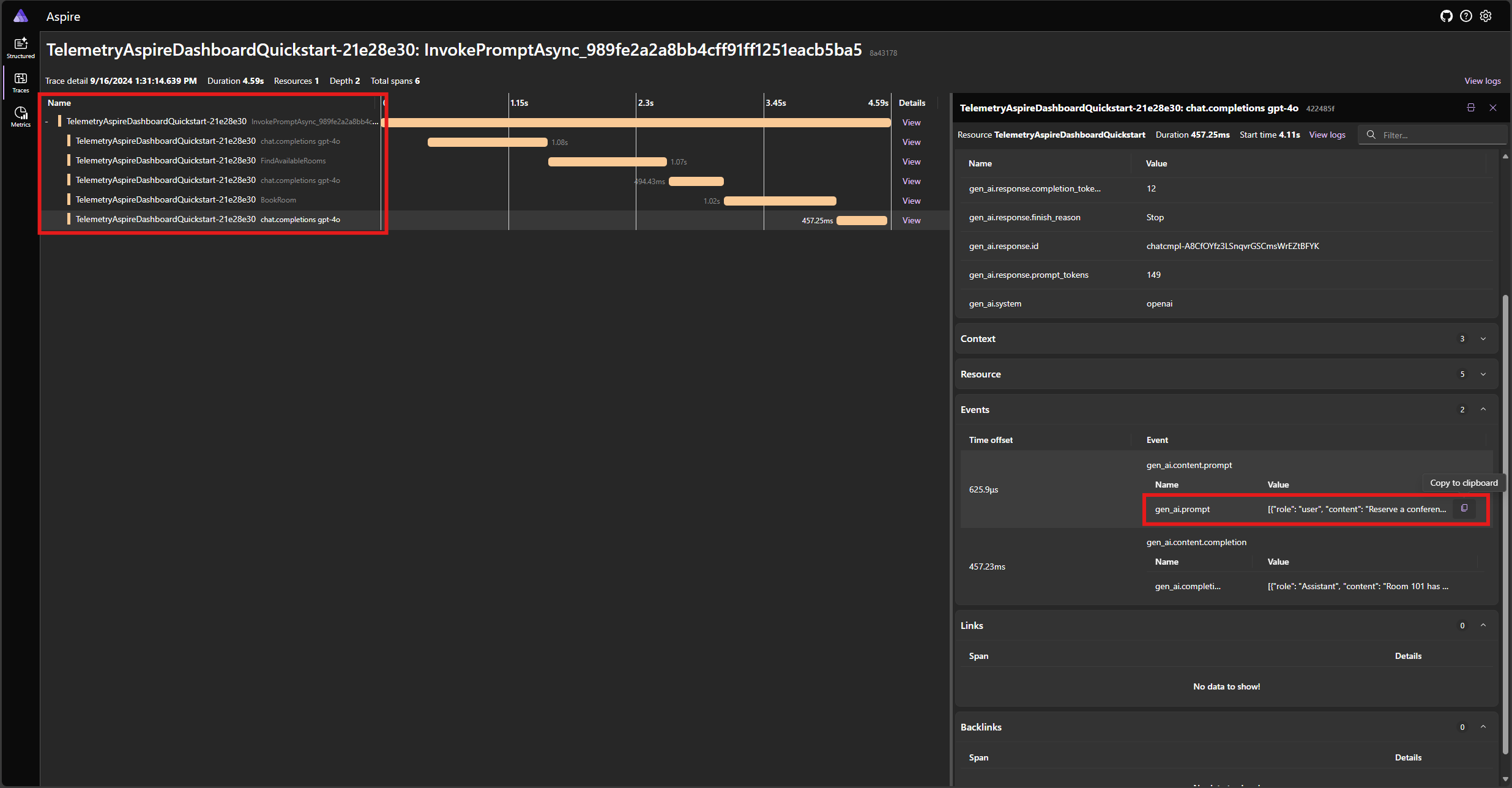
Ces 5 étendues représentent les opérations internes du noyau avec l’appel de fonction automatique activé. Il appelle d’abord le modèle, qui demande un appel de fonction. Ensuite, le noyau exécute automatiquement la fonction FindAvailableRoomsAsync et retourne le résultat au modèle. Le modèle demande ensuite un autre appel de fonction pour effectuer une réservation, et le noyau exécute automatiquement la fonction BookRoomAsync et retourne le résultat au modèle. Enfin, le modèle retourne une réponse en langage naturel à l’utilisateur.
Et si vous cliquez sur la dernière étendue et recherchez l’invite dans l’événement gen_ai.content.prompt , vous devez voir quelque chose de similaire à ce qui suit :
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_NtKi0OgOllJj1StLkOmJU8cP",
"function": { "arguments": {}, "name": "FindAvailableRooms" },
"type": "function"
}
]
},
{
"role": "tool",
"content": "[\u0022Room 101\u0022,\u0022Room 201\u0022,\u0022Room 301\u0022]"
},
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_mjQfnZXLbqp4Wb3F2xySds7q",
"function": { "arguments": { "room": "Room 101" }, "name": "BookRoom" },
"type": "function"
}
]
},
{ "role": "tool", "content": "Room Room 101 booked." }
]
Il s’agit de l’historique des conversations qui se construit en tant que modèle et que le noyau interagissent les uns avec les autres. Il est envoyé au modèle dans la dernière itération pour obtenir une réponse en langage naturel.
Recherchez la trace de l’application sous l’onglet Traces . Vous devez avoir cinq étendues dans la trace regroupée sous l’étendue AutoFunctionInvocationLoop :
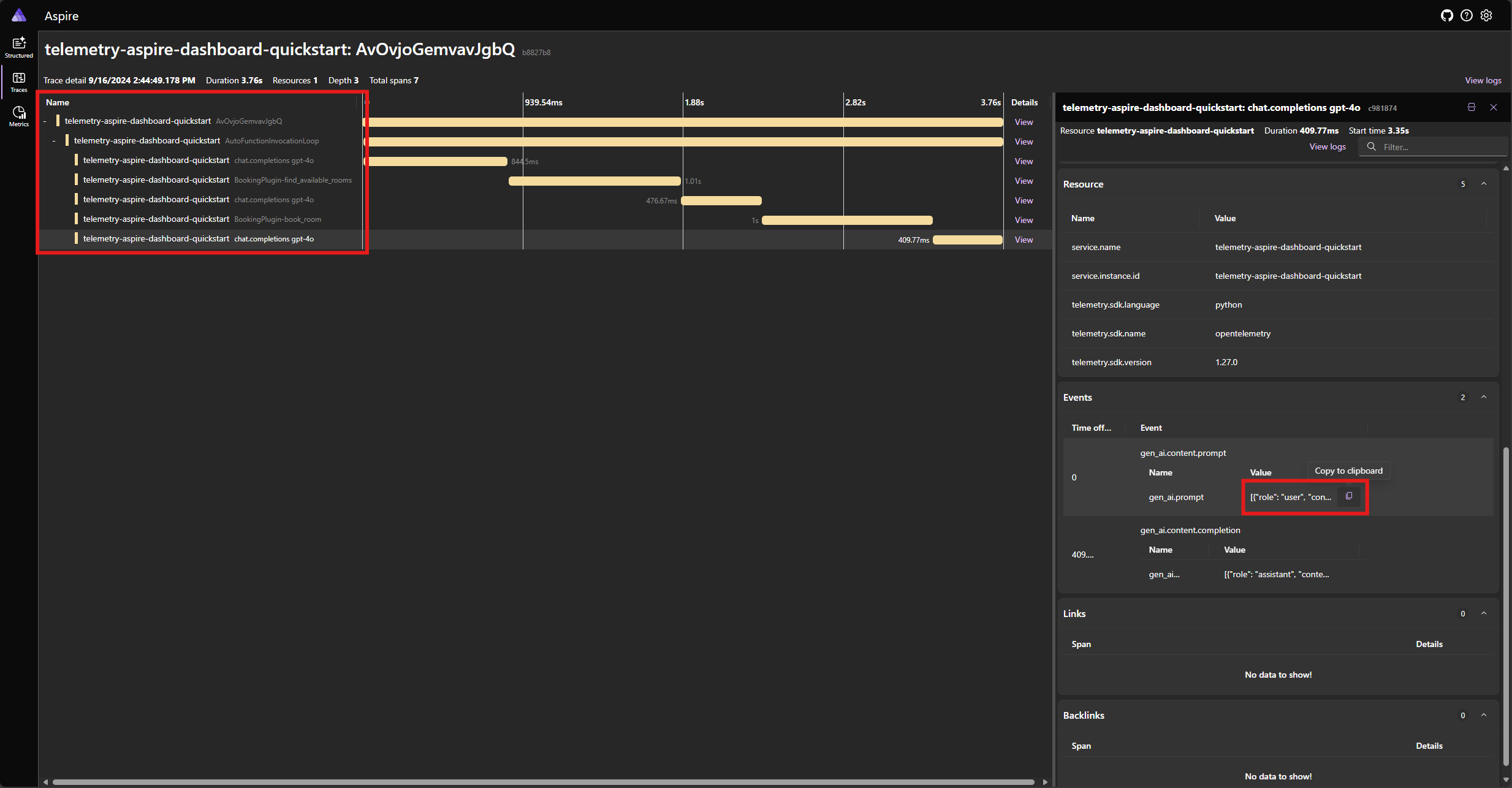
Ces 5 étendues représentent les opérations internes du noyau avec l’appel de fonction automatique activé. Il appelle d’abord le modèle, qui demande un appel de fonction. Ensuite, le noyau exécute automatiquement la fonction find_available_rooms et retourne le résultat au modèle. Le modèle demande ensuite un autre appel de fonction pour effectuer une réservation, et le noyau exécute automatiquement la fonction book_room et retourne le résultat au modèle. Enfin, le modèle retourne une réponse en langage naturel à l’utilisateur.
Et si vous cliquez sur la dernière étendue et recherchez l’invite dans l’événement gen_ai.content.prompt , vous devez voir quelque chose de similaire à ce qui suit :
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_ypqO5v6uTRlYH9sPTjvkGec8",
"type": "function",
"function": {
"name": "BookingPlugin-find_available_rooms",
"arguments": "{}"
}
}
]
},
{
"role": "tool",
"content": "['Room 101', 'Room 201', 'Room 301']",
"tool_call_id": "call_ypqO5v6uTRlYH9sPTjvkGec8"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_XDZGeTfNiWRpYKoHoH9TZRoX",
"type": "function",
"function": {
"name": "BookingPlugin-book_room",
"arguments": "{\"room\":\"Room 101\"}"
}
}
]
},
{
"role": "tool",
"content": "Room Room 101 booked.",
"tool_call_id": "call_XDZGeTfNiWRpYKoHoH9TZRoX"
}
]
Il s’agit de l’historique des conversations qui se construit en tant que modèle et que le noyau interagissent les uns avec les autres. Il est envoyé au modèle dans la dernière itération pour obtenir une réponse en langage naturel.
Remarque
L’observabilité du noyau sémantique n’est pas encore disponible pour Java.
Gestion des erreurs
Si une erreur se produit pendant l’exécution d’une fonction, le noyau intercepte automatiquement l’erreur et retourne un message d’erreur au modèle. Le modèle peut ensuite utiliser ce message d’erreur pour fournir une réponse en langage naturel à l’utilisateur.
Modifiez la BookRoomAsync fonction dans le code C# pour simuler une erreur :
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
throw new Exception("Room is not available.");
}
Réexécutez l’application et observez la trace dans le tableau de bord. Vous devez voir l’étendue représentant l’appel de fonction du noyau avec une erreur :
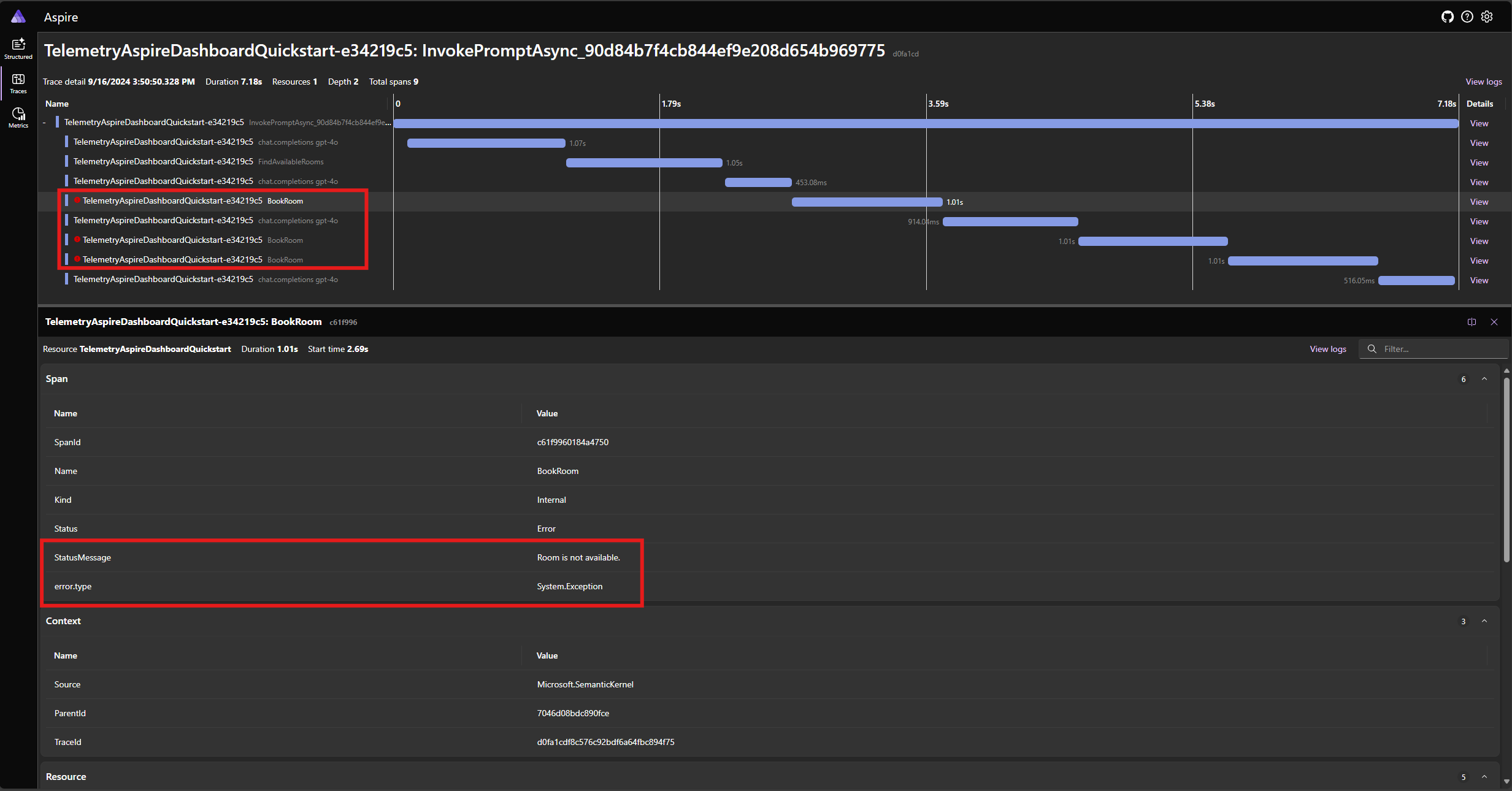
Remarque
Il est très probable que les réponses du modèle à l’erreur peuvent varier chaque fois que vous exécutez l’application, car le modèle est stochastique. Vous pouvez voir le modèle réserver les trois chambres en même temps, ou réserver une la première fois puis réserver les deux autres la deuxième fois, etc.
Modifiez la book_room fonction dans le code Python pour simuler une erreur :
@kernel_function(
name="book_room",
description="Book a conference room.",
)
async def book_room(self, room: str) -> Annotated[str, "A confirmation message."]:
# Simulate a remote call to a booking system
await asyncio.sleep(1)
raise Exception("Room is not available.")
Réexécutez l’application et observez la trace dans le tableau de bord. Vous devez voir l’étendue représentant l’appel de fonction du noyau avec une erreur et la trace de pile :
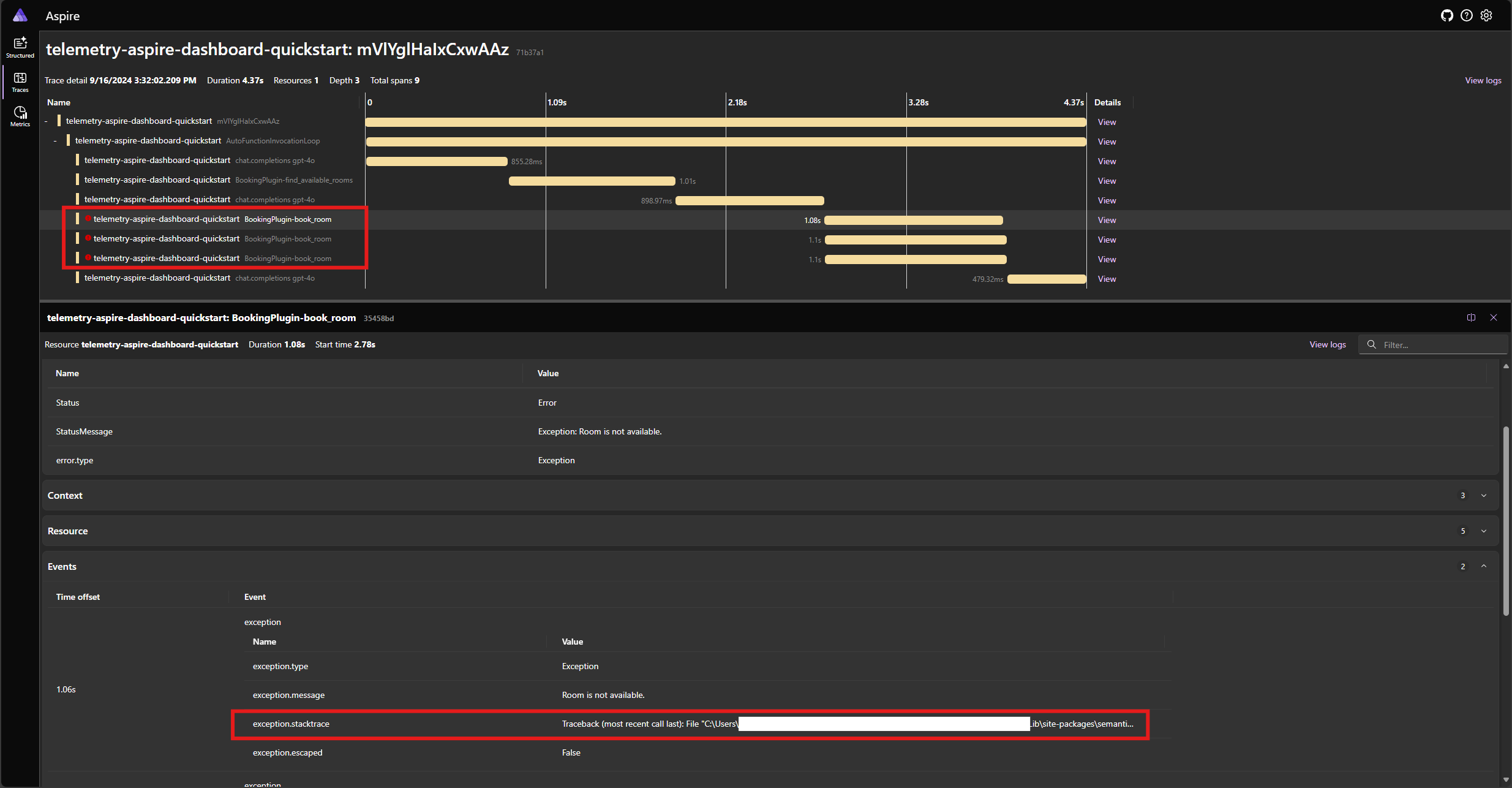
Remarque
Il est très probable que les réponses du modèle à l’erreur peuvent varier chaque fois que vous exécutez l’application, car le modèle est stochastique. Vous pouvez voir le modèle réserver les trois chambres en même temps, ou réserver une la première fois puis réserver les deux autres la deuxième fois, etc.
Remarque
L’observabilité du noyau sémantique n’est pas encore disponible pour Java.
Étapes suivantes et lecture ultérieure
En production, vos services peuvent obtenir un grand nombre de demandes. Le noyau sémantique génère une grande quantité de données de télémétrie. certaines d’entre elles ne sont peut-être pas utiles pour votre cas d’usage et entraînent des coûts inutiles pour stocker les données. Vous pouvez utiliser la fonctionnalité d’échantillonnage pour réduire la quantité de données de télémétrie collectées.
L’observabilité dans le noyau sémantique s’améliore constamment. Vous trouverez les dernières mises à jour et nouvelles fonctionnalités dans le dépôt GitHub.