Consommer une application déployée sur Clusters Big Data SQL Server avec un service web RESTful
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Cet article décrit comment consommer une application déployée sur un cluster Big Data SQL Server avec un service web RESTful.
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Conditions préalables requises
- Cluster Big Data SQL Server
- Azure Data CLI (
azdata) - Application déployée avec azdata ou l’extension de déploiement d’application
Notes
Lorsque le fichier de spécification yaml de l’application indique une planification, l’application est déclenchée par le biais d’un travail cron. Si votre cluster Big Data est déployé sur OpenShift, le lancement du travail cron nécessite des fonctionnalités supplémentaires. Pour obtenir des instructions spécifiques, consultez les détails relatifs aux considérations de sécurité sur OpenShift.
Fonctionnalités
Après avoir déployé une application sur votre Clusters de Big Data SQL Server 2019, vous pouvez accéder à cette application et la consommer en utilisant un service web RESTful. Vous pouvez ainsi intégrer cette application à partir d’autres applications ou services (par exemple, une application mobile ou un site web). Le tableau suivant décrit les commandes de déploiement d’application que vous pouvez utiliser avec azdata pour obtenir des informations sur le service web RESTful pour votre application.
| Commande | Description |
|---|---|
azdata app describe |
Décrivez une application. |
Vous pouvez utiliser le paramètre --help pour obtenir de l’aide, comme dans l’exemple suivant :
azdata app describe --help
Les sections suivantes décrivent comment récupérer un point de terminaison pour une application et comment utiliser le service web RESTful pour l’intégration d’applications.
Récupérer le point de terminaison
Les clusters Big Data fournissent des points de terminaison auxquels vous pouvez accéder et qui consomment cette application à l’aide d’un service web RESTful ; l’objectif principal est de faciliter l’interaction avec d’autres applications web ou mobiles et d’être plus proactif pour l’architecture de ces microservices. La commande azdata app describe fournit des informations détaillées sur l’application, notamment le point de terminaison de votre cluster. Ces informations sont généralement utilisées par les développeurs pour créer une application à l’aide du client Swagger et du service web pour interagir avec l’application de manière RESTful.
Décrivez votre application en exécutant une commande similaire à l’exemple suivant :
azdata app describe --name add-app --version v1
{
"input_param_defs": [
{
"name": "x",
"type": "int"
},
{
"name": "y",
"type": "int"
}
],
"links": {
"app": "https://10.1.1.3:30080/app/addpy/v1",
"swagger": "https://10.1.1.3:30080/app/addpy/v1/swagger.json"
},
"name": "add-app",
"output_param_defs": [
{
"name": "result",
"type": "int"
}
],
"state": "Ready",
"version": "v1"
}
Notez l’adresse IP (10.1.1.3 dans cet exemple) et le numéro de port (30080) dans la sortie.
Une des autres méthodes permettant d’obtenir ces informations est de cliquer avec le bouton droit sur Gérer sur le serveur dans Azure Data Studio où se trouvent les points de terminaison des services listés.
Générer un jeton d’accès JWT
Pour accéder au service web RESTful pour l’application que vous avez déployée, vous devez d’abord générer un jeton d’accès JWT. L’URL du jeton d’accès dépend de la version du cluster Big Data.
| Version | URL |
|---|---|
| GDR1 | https://[IP]:[PORT]/docs/swagger.json |
| CU1 et versions ultérieures | https://[IP]:[PORT]/api/v1/swagger.json |
À partir du résultat de l’exemple précédent, avec la version CU4 et l’adresse IP du contrôleur (10.1.1.3 dans l’exemple) et le numéro de port (30080), l’URL ressemblera à ce qui suit :
https://10.1.1.3 :30080/api/v1/swagger.json
Pour plus d’informations sur la version, consultez l’historique des versions.
Ouvrez l’URL appropriée dans votre navigateur à l’aide de l’adresse IP et du port que vous avez récupérés en exécutant la commande describe. Connectez-vous avec les mêmes informations d’identification que celles utilisées pour azdata login.
Collez le contenu de swagger.json dans Swagger Editor pour comprendre les méthodes disponibles :
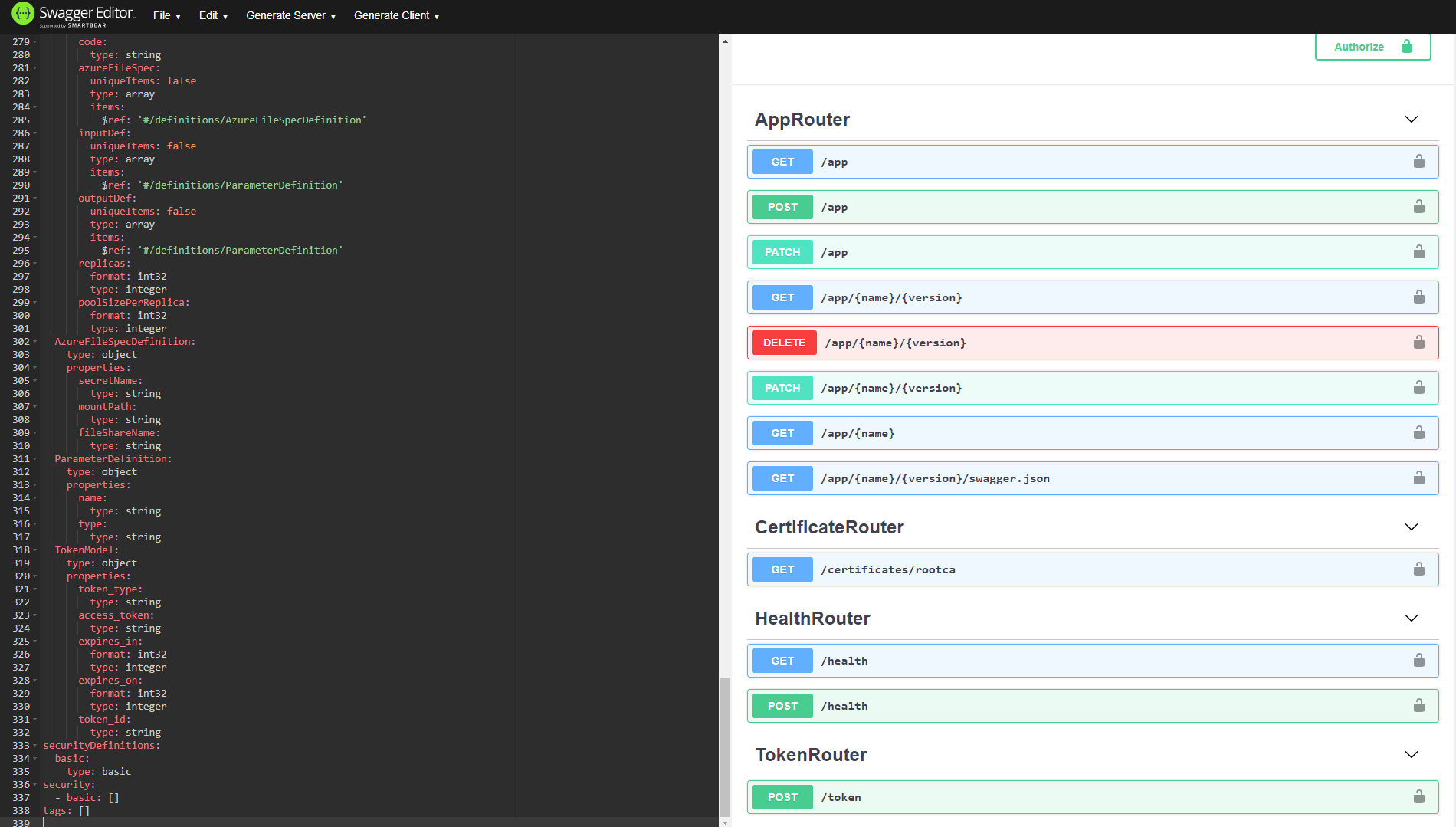
Notez que app est une méthode GET et que token utilisera une méthode POST. Comme l’authentification des applications utilise des jetons JWT, vous devez obtenir un jeton en utilisant votre outil favori pour effectuer un appel POST à la méthodetoken. Dans le même exemple, l’URL permettant d’obtenir le jeton JWT ressemblera à ce qui suit :
https://10.1.1.3 :30080/api/v1/token
Le résultat de cette demande vous donne un access_token JWT avec lequel devez appeler l’URL pour exécuter l’application.
Exécuter l’application à l’aide du service web RESTful
Il existe plusieurs façons d’utiliser une application sur des clusters Big Data SQL Server. Vous pouvez choisir d’utiliser la commande d’exécution de l’application azdata.
Vous pouvez ouvrir l’URL de swagger qui a été retournée quand vous avez exécuté azdata app describe --name [appname] --version [version] dans votre navigateur, ce qui doit être similaire à https://[IP]:[PORT]/app/[appname]/[version]/swagger.json.
Notes
Connectez-vous avec les mêmes informations d’identification que celles utilisées pour azdata login. Dans le même exemple, la commande ressemblera à ce qui suit :
azdata app describe --name add-app --version v1
Étapes suivantes
Découvrez comment Surveiller des applications sur des clusters Big Data pour plus d’informations. Vous pouvez également consulter d’autres exemples de déploiement d’application.
Pour plus d’informations sur les Clusters Big Data SQL Server, consultez Que sont les Clusters de Big Data SQL Server 2019 ?.