Présentation du pool de données dans Clusters Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Cet article décrit le rôle des pools de données SQL Server dans un cluster Big Data SQL Server. Les sections suivantes décrivent l’architecture, les fonctionnalités et les scénarios d’utilisation d’un pool de données.
Cette vidéo de 5 minutes présente des pools de données et vous montre comment interroger des données à partir de pools de données :
Architecture du pool de données
Un pool de données se compose d’une ou plusieurs instances de pool de données SQL Server qui fournissent un stockage SQL Server persistant pour le cluster. Il permet d’interroger les performances des données mises en cache par rapport à des sources de données externes et de décharger le travail. Les données sont ingérées dans le pool de données à l’aide de requêtes T-SQL ou de travaux Spark. Afin d’améliorer les performances dans les jeux de données volumineux, les données ingérées sont distribuées dans partitions et stockées dans toutes les instances SQL Server du pool. Les méthodes de distributions prises en charge sont tourniquet (Round Robin) et répliquées. Pour l’optimisation de l’accès en lecture, un index columstore en cluster est créé sur chaque table de chaque instance du pool de données. Un pool de données constitue le DataMart avec scale-out des Clusters Big Data SQL Server.
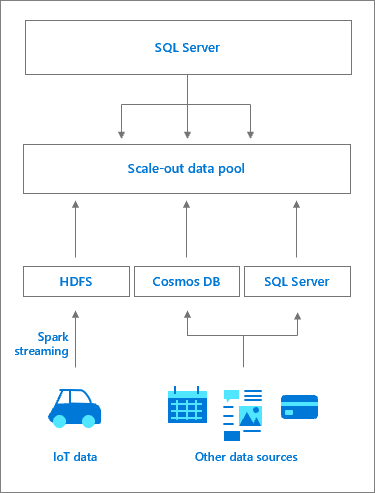
L’accès aux instances SQL Server du pool de données est géré à partir de l’instance maître SQL Server. Une source de données externe pour le pool de données est créée, avec les tables externes PolyBase pour stocker le cache de données. En arrière-plan, le contrôleur crée une base de données dans le pool de données avec des tables qui correspondent aux tables externes. À partir de l’instance maître SQL Server, le workflow est transparent : le contrôleur redirige les requêtes de table externe vers les instances SQL Server du pool de données (peut-être via le pool de calcul), exécute des requêtes et retourne le jeu de résultats. Les données du pool de données peuvent uniquement être ingérées ou interrogées et ne peuvent pas être modifiées. Toutes les actualisations de données nécessitent donc une suppression de la table, suivie de la recréation de la table et du remplissage ultérieur des données.
Scénarios de pools de données
La création de rapports est un scénario de pool de données commun. Par exemple, une requête complexe joignant plusieurs sources de données PolyBase, utilisées pour un rapport hebdomadaire, peut être déchargée dans le pool de données. Les données en cache fournissent un calcul rapide local et éliminent la nécessité de revenir aux jeux de données d’origine. De même, les données du tableau de bord qui nécessitent une actualisation périodique peuvent être mises en cache dans le pool de données pour les rapports optimisés. L’exploration de répétition Machine Learning peut également tirer parti de la mise en cache des jeux de données dans le pool de données.
Étapes suivantes
Pour en savoir plus sur les Clusters Big Data SQL Server, consultez les ressources suivantes :