Ressources d’administration pour les Clusters Big Data SQL Server 2019
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Cet article explique comment afficher l’état d’un cluster Big Data à l’aide d’Azure Data Studio, de notebooks et de commandes Azure Data CLI (azdata).
Connaître votre architecture
À compter de SQL Server 2019 (15.x), les Clusters Big Data SQL Server vous permettent de déployer des clusters scalables de conteneurs SQL Server, Spark et HDFS exécutés sur Kubernetes. Pour obtenir une vue d’ensemble, consultez Que sont les Clusters Big Data SQL Server ?
Les Clusters Big Data SQL Server assurent des fonctionnalités d’autorisation et d’authentification uniformes et cohérentes. Pour obtenir une vue d’ensemble de la sécurité des clusters Big Data, consultez Concepts de sécurité pour Clusters Big Data SQL Server.
Gérer et utiliser des outils
Les articles suivants expliquent comment gérer et utiliser Clusters Big Data :
- Se connecter à un cluster Big Data SQL Server avec Azure Data Studio
- Gérer les clusters Big Data pour le tableau de bord du contrôleur SQL Server
- Gérer des Clusters Big Data SQL Server avec des notebooks Azure Data Studio
- Notebooks opérationnels pour les clusters Big Data SQL Server
- Exécuter un exemple de notebook avec Spark
Analyser avec des outils
Les articles suivants expliquent comment surveiller les clusters Big Data :
- Surveiller l’état des clusters Big Data à l’aide d’Azure Data Studio
- Surveiller des clusters Big Data en utilisant azdata et kubectl
- Surveiller les clusters Big Data à l’aide d’azdata et du tableau de bord Grafana
- Gérer des clusters Big Data (BDC) avec des notebooks Jupyter et Azure Data Studio
Important
Le navigateur Internet Explorer et les navigateurs Microsoft Edge plus anciens ne sont pas compatibles avec Grafana ou Kibana. Envisagez d’utiliser Microsoft Edge basé sur Chromium, ou passez en revue les navigateurs pris en charge pour Grafana ou les navigateurs pris en charge pour Kibana.
Analyser et inspecter les journaux avec des notebooks
Les articles suivants répertorient un grand nombre de notebooks Jupyter disponibles dans Azure Data Studio :
- Surveiller des clusters à l’aide de notebooks
- Collecte et analyse des journaux dans un cluster à l’aide de notebooks
Où trouver les notebooks d’administration des Clusters Big Data SQL Server
Les Clusters Big Data SQL Server proposent une expérience d’administration complète via Jupyter Notebook. Les notebooks fournis couvrent les opérations de cluster, la gestion, la supervision, la journalisation et la résolution des problèmes.
Pour ajouter le référentiel du notebook opérationnel de GitHub à Azure Data Studio, vous pouvez utiliser un raccourci clavier Ctrl+Maj+P ou sélectionner Affichage puis Palette de commandes. Sélectionnez Ajouter un livre distant.
Dans la boîte de dialogue Ajouter un livre distant, sélectionnez la version la plus récente souhaitée pour les notebooks opérationnels. Sélectionnez Ajouter comme illustré ci-dessous :
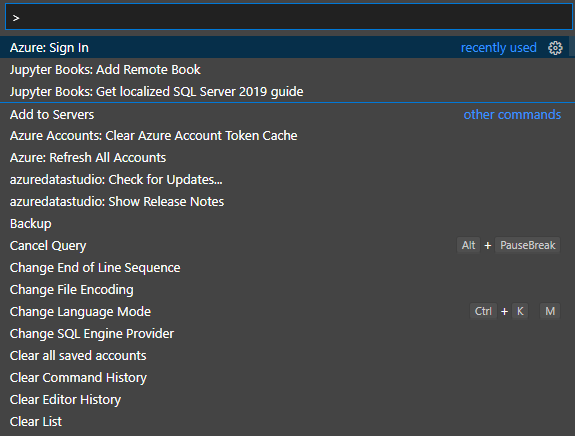
Sélectionnez Jupyter Books: Add Remote Book. Une fenêtre s’ouvre et vous permet de sélectionner un notebook.
Notes
Veillez à sélectionner la bonne version du Notebook. Elle doit correspondre à la version de mise à jour cumulative de votre cluster Big Data.
Sélectionnez la version de la base de Notebooks sur la mise à jour cumulative de votre cluster Big Data :
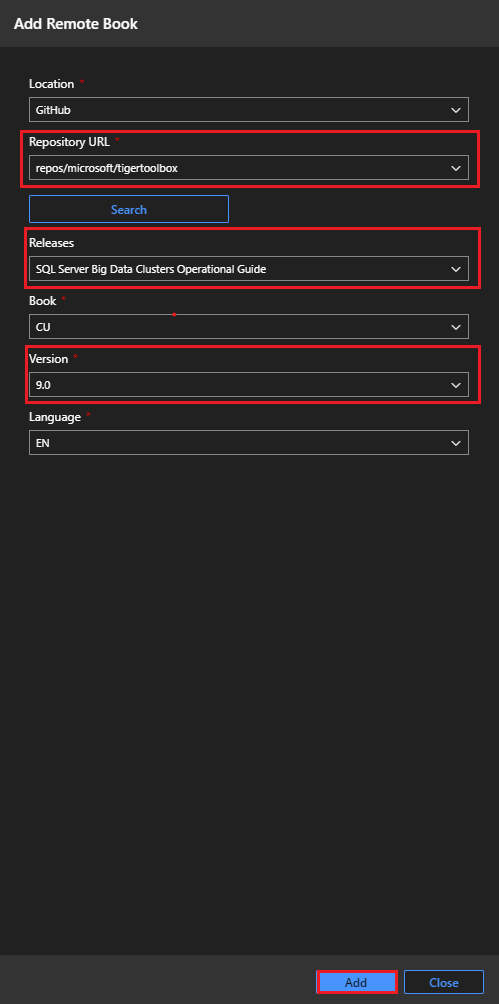
Lorsque vous sélectionnez Ajouter, vous accédez à tous les notebooks de la version choisie dans l’onglet Notebooks d’Azure Data Studio :
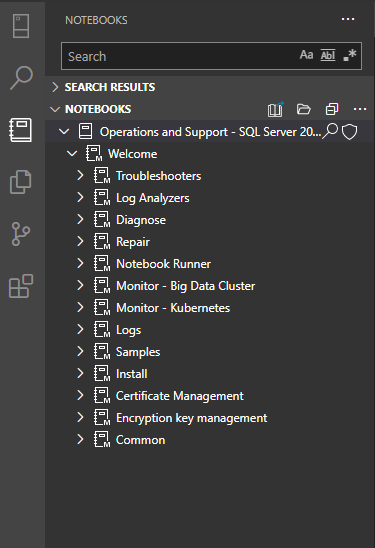
Comment utiliser ces notebooks
Pour savoir comment utiliser les notebooks, consultez les articles suivants :
- Gérer des clusters Big Data (BDC) avec des notebooks Jupyter et Azure Data Studio
- Collecte et analyse des journaux dans un cluster Big Data à l’aide de notebooks
- Résoudre les problèmes du notebook pyspark
- Résolution des problèmes liés aux clusters Big Data avec des notebooks Jupyter et Azure Data Studio
Ressources de résolution des problèmes des Clusters Big Data
Les articles suivants expliquent comment résoudre les problèmes liés aux clusters Big Data :
- Résoudre les problèmes liés aux clusters Big Data à l’aide de l’utilitaire kubectl
- Résoudre les problèmes du notebook pyspark
- Résolution des problèmes liés aux clusters Big Data avec des notebooks Jupyter et Azure Data Studio
- Restauration des autorisations HDFS
- Résoudre des problèmes de HDFS dans des Clusters Big Data SQL Server
Les articles suivants expliquent comment résoudre les problèmes liés aux clusters Big Data déployés en mode Active Directory :
- Résolution des problèmes d’intégration à Active Directory des clusters Big Data SQL Server
- Résoudre les problèmes de connexion en mode Active Directory
- Résoudre les problèmes d’arrêt de déploiement en mode Active Directory de clusters Big Data SQL Server