Indexer des données JSON
S’applique à : ![]() SQL Server 2016 (13.x) et versions ultérieures
SQL Server 2016 (13.x) et versions ultérieures ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Vous pouvez optimiser vos requêtes sur les documents JSON en utilisant des index standards. SQL Server n’a pas d’index JSON personnalisés.
- Actuellement, dans SQL Server json n’est pas un type de données intégré.
- Actuellement, le type de données JSON est disponible dans Azure SQL Database.
Les index fonctionnent de la même façon sur les données JSON dans varchar/nvarchar ou le type de données json natif.
Les index de base de données permettent d’améliorer les performances des opérations de filtrage et de tri. Sans index, SQL Server doit effectuer une analyse de table complète chaque fois que vous interrogez des données.
Indexer les propriétés JSON à l’aide des colonnes calculées
Quand vous stockez des données JSON dans SQL Server, cela signifie généralement que vous souhaitez filtrer ou trier les résultats de la requête en fonction d’une ou de plusieurs propriétés des documents JSON.
Exemple
Dans cet exemple, supposons que la table AdventureWorks.SalesOrderHeader comporte une colonne Info contenant plusieurs informations au format JSON sur des commandes client. Par exemple, elle contient des données non structurées sur le client, le vendeur, les adresses de livraison et de facturation, etc. Vous pouvez utiliser les valeurs de la colonne Info pour filtrer les commandes d’un client particulier.
Par défaut, la colonne Info utilisée n’existe pas. Elle peut être créée dans la base de données AdventureWorks avec le code suivant. Les exemples suivants ne s’appliquent pas à la série d’exemples AdventureWorksLT de bases de données.
IF NOT EXISTS(SELECT * FROM sys.columns WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]') AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader] ADD [Info] NVARCHAR(MAX) NULL
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Requête à optimiser
Voici un exemple de type de requête à optimiser à l’aide d’un index.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell'
Exemple d’index
Pour accélérer vos filtres ou vos clauses ORDER BY sur une propriété d’un document JSON, vous pouvez utiliser les mêmes index que ceux que vous utilisez déjà sur d’autres colonnes. Toutefois, vous ne pouvez pas référencer directement des propriétés dans les documents JSON.
- D’abord, créer une « colonne virtuelle » qui retourne les valeurs à utiliser pour le filtrage.
- Ensuite, créer un index sur cette colonne virtuelle.
L’exemple suivant crée une colonne calculée qui peut être utilisée pour l’indexation. Il crée ensuite un index sur la nouvelle colonne calculée. Cet exemple crée une colonne qui affiche le nom du client, stocké dans le chemin $.Customer.Name des données JSON.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info,'$.Customer.Name')
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
Cette instruction retourne l’avertissement suivant :
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
La fonction JSON_VALUE peut retourner des valeurs de texte allant jusqu’à 8 000 octets (par exemple, comme le type nvarchar(4000)). Toutefois, les valeurs de plus de 1 700 octets ne peuvent pas être indexées. Si vous essayez d’entrer la valeur dans la colonne calculée indexée qui dépasse 1 700 octets, l’opération langage de manipulation de données (DML) échoue.
Pour de meilleures performances, essayez de caster la valeur que vous exposez à l’aide de la colonne calculée dans le plus petit type applicable. Utilisez les types int et datetime2 au lieu des types chaîne.
Plus d’informations sur la colonne calculée
Une colonne calculée n’est pas persistante. Une colonne informatique calculée uniquement lorsque l'index doit être reconstruit. Elle n’occupe pas d’espace supplémentaire dans la table.
Il est important de créer la colonne calculée avec la même expression que celle que vous comptez utiliser dans vos requêtes. Ici, par exemple, il s’agit de l’expression JSON_VALUE(Info, '$.Customer.Name').
Vous n’avez pas besoin de réécrire vos requêtes. Si vous utilisez des expressions avec la fonction JSON_VALUE, comme indiqué dans l’exemple de requête précédent, SQL Server détecte qu’il existe une colonne calculée équivalente avec la même expression et applique un index si possible.
Plan d’exécution pour cet exemple
Voici le plan d’exécution de la requête utilisée dans cet exemple.
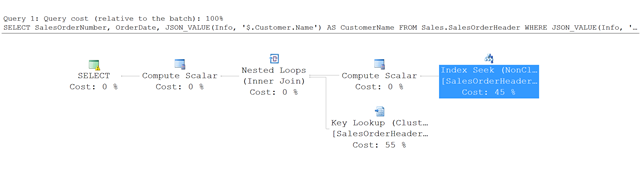
Au lieu d’une analyse de table complète, SQL Server effectue une recherche dans l’index non-cluster et recherche les lignes qui répondent aux conditions spécifiées. Il utilise ensuite une recherche de clé dans la table SalesOrderHeader pour extraire les autres colonnes référencées dans la requête. Dans cet exemple, il s’agit de SalesOrderNumber et OrderDate.
Optimiser davantage l’index avec les colonnes incluses
Si vous ajoutez les colonnes nécessaires dans l’index, vous pouvez éviter cette recherche supplémentaire dans la table. Vous pouvez ajouter ces colonnes en tant que colonnes incluses standard, comme indiqué dans l’exemple suivant, ce qui étend l’exemple CREATE INDEX précédent.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber,OrderDate)
Dans ce cas, SQL Server n’a pas à lire d’autres données de la table SalesOrderHeader, car tout ce dont il a besoin est inclus dans l’index JSON non-cluster. Ce type d’index est un bon moyen de combiner des données JSON et des données de colonne dans les requêtes, et de créer des index optimaux pour votre charge de travail.
Les index JSON prennent en charge le classement
Les index des données JSON présentent une caractéristique importante : ils prennent en charge le classement. Le résultat de la fonction JSON_VALUE que vous utilisez quand vous créez la colonne calculée est une valeur texte qui hérite son classement de l’expression d’entrée. Ainsi, les valeurs de l’index sont triées à l’aide des règles de classement définies dans les colonnes sources.
Pour démontrer que les index prennent en charge le classement, l’exemple suivant crée une table de collection simple avec une clé primaire et un contenu JSON.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR(MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON]
CHECK(ISJSON(json)>0)
)
La commande précédente spécifie le classement serbe cyrillique pour la colonne json. L’exemple suivant remplit la table et crée un index sur la propriété de nom.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}')
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json,'$.name')
CREATE INDEX idx_name
ON JsonCollection(vName)
Les commandes précédentes créent un index standard sur la colonne calculée vName, qui représente la valeur de la propriété JSON $.name. Dans la page de codes cyrilliques serbes, l’ordre des lettres est А, Б, В, Г, Д, Ђ, Е, etc. L’ordre des éléments de l’index est compatible avec les règles cyrilliques serbes, car le résultat de la fonction JSON_VALUE hérite son classement de la colonne source. L’exemple suivant interroge cette collection et trie les résultats par nom.
SELECT JSON_VALUE(json,'$.name'),*
FROM JsonCollection
ORDER BY JSON_VALUE(json,'$.name')
Si vous examinez le plan d’exécution, vous pouvez constater qu’il utilise les valeurs triées de l’index non-cluster.

Bien que la requête comporte une clause ORDER BY, le plan d’exécution n’utilise pas d’opérateur de tri. L’index JSON est déjà trié selon les règles cyrilliques serbes. Par conséquent, SQL Server peut utiliser l’index non-cluster dans lequel les résultats sont déjà triés.
Toutefois, si vous changez le classement de l’expression ORDER BY, par exemple en ajoutant COLLATE French_100_CI_AS_SC après la fonction JSON_VALUE, vous obtenez un autre plan d’exécution de requête.

Étant donné que l’ordre des valeurs de l’index n’est pas compatible avec les règles de classement françaises, SQL Server ne peut pas utiliser l’index pour trier les résultats. Par conséquent, il ajoute un opérateur de tri qui trie les résultats à l’aide des règles de classement françaises.
Vidéos Microsoft
Remarque
Certains des liens vidéo de cette section peuvent ne pas fonctionner pour l’instant. Microsoft migre le contenu précédemment disponible sur Channel 9 vers une nouvelle plateforme. Nous allons mettre à jour les liens au fur et à mesure que les vidéos sont migrées vers la nouvelle plateforme.
Pour obtenir une présentation visuelle de la prise en charge intégrée de JSON dans SQL Server et Azure SQL Database, consultez les vidéos suivantes :