Tutoriel : créer et déployer un projet SQL
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Base de données SQL dans Microsoft Fabric
Base de données SQL dans Microsoft Fabric
Le cycle de développement d'un projet de base de données SQL permet d'intégrer le développement de la base de données dans un flux de travail d'intégration et de déploiement continus (CI/CD) connu comme une meilleure pratique de développement. Bien que le déploiement d'un projet de base de données SQL puisse être effectué manuellement, il est recommandé d'utiliser un pipeline de déploiement pour automatiser le processus de déploiement de manière à ce que les déploiements en cours soient exécutés en fonction de votre développement local continu sans effort supplémentaire.
Cet article décrit la création d'un projet SQL, l'ajout d'objets au projet et la mise en place d'un pipeline de déploiement continu pour générer et déployer le projet à l'aide d'actions GitHub. Ce tutoriel est un surensemble du contenu de l'article sur le démarrage des projets SQL. Bien que le tutoriel mette en œuvre le pipeline de déploiement dans les actions GitHub, les mêmes concepts s'appliquent à Azure DevOps, GitLab et à d'autres environnements d'automatisation.
Dans ce tutoriel, vous allez :
- Créer un projet SQL
- Ajouter des objets au projet
- Générer le projet localement
- Vérifier le projet dans le contrôle de code source
- Ajouter une étape de génération de projet à un pipeline de déploiement continu
- Ajouter une étape de déploiement
.dacpacà un pipeline de déploiement continu
Si vous avez déjà effectué les étapes de l'article sur le démarrage des projets SQL, vous pouvez passer à l'étape 4. À la fin de ce tutoriel, votre projet SQL sera automatiquement généré et déploiera les modifications vers une base de données cible.
Prérequis
# install SqlPackage CLI
dotnet tool install -g Microsoft.SqlPackage
# install Microsoft.Build.Sql.Templates
dotnet new install Microsoft.Build.Sql.Templates
Assurez-vous d'avoir les éléments suivants pour terminer l'installation du pipeline dans GitHub :
Un compte GitHub dans lequel vous pouvez créer un référentiel. Créez-en un gratuitement.
Les actions GitHub sont activées sur votre référentiel.
Remarque
Pour terminer le déploiement d'un projet de base de données SQL, vous devez avoir accès à une instance Azure SQL ou SQL Server. Vous pouvez développer localement et gratuitement avec l'édition SQL Server Développeur sur Windows ou dans des conteneurs.
Étape 1 : Créer un projet
Nous débutons notre projet en créant un projet de base de données SQL avant d'y ajouter manuellement des objets. Il existe d'autres manières de créer un projet qui permettent de l'alimenter immédiatement avec des objets provenant d'une base de données existante, par exemple en utilisant les outils de comparaison de schémas.
Sélectionnez Fichier, Nouveau, puis Projet.
Dans la boîte de dialogue Nouveau projet, utilisez le terme SQL Server dans la zone de recherche. Le premier résultat devrait être Projet de base de données SQL Server.

Cliquez sur Suivant pour passer à l’étape suivante. Indiquez un nom de projet, qui ne doit pas nécessairement correspondre à un nom de base de données. Vérifiez et modifiez l'emplacement du projet si nécessaire.
Sélectionnez Créer pour créer le projet. Le projet vide est ouvert et visible dans l'Explorateur de solutions pour modification.
Sélectionnez Fichier, Nouveau, puis Projet.
Dans la boîte de dialogue Nouveau projet, utilisez le terme SQL Server dans la zone de recherche. Le meilleur résultat devrait être Projet de base de données SQL Server, style SDK (préversion).

Cliquez sur Suivant pour passer à l’étape suivante. Indiquez un nom de projet, qui ne doit pas nécessairement correspondre à un nom de base de données. Vérifiez et modifiez l'emplacement du projet si nécessaire.
Sélectionnez Créer pour créer le projet. Le projet vide est ouvert et visible dans l'Explorateur de solutions pour modification.
Dans la vue Projets de base de données de VS Code ou Azure Data Studio, sélectionnez le bouton Nouveau projet.
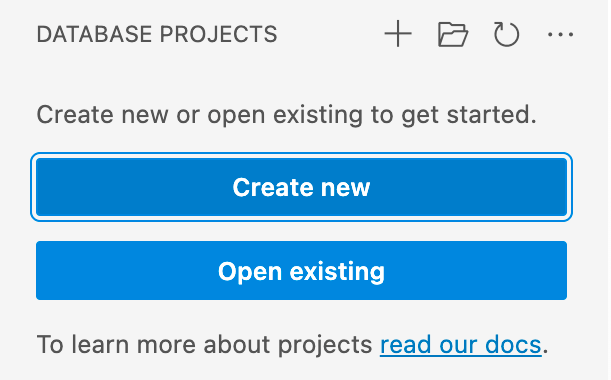
La première invite détermine le modèle de projet à utiliser, principalement selon que la plateforme cible est SQL Server ou Azure SQL. Si une version spécifique de SQL est demandée, choisissez la version qui correspond à la base de données cible, mais si la version de la base de données cible est inconnue, choisissez la dernière version, car la valeur peut être modifiée ultérieurement.
Saisissez un nom de projet dans la zone de texte qui s'affiche, qui ne doit pas nécessairement correspondre à un nom de base de données.
Dans la boîte de dialogue « Sélectionner un dossier » qui s’affiche, sélectionnez un répertoire où doivent être placés le dossier du projet, le fichier .sqlproj et tout autre contenu.
Lorsque l'invite demande s'il faut créer un projet de style SDK (aperçu), sélectionnez Oui.
Une fois terminé, le projet vide est ouvert et visible dans la vue Projets de base de données pour être modifié.
Lorsque les modèles .NET pour les projets Microsoft.Build.Sql sont installés, vous pouvez créer un projet de base de données SQL à partir de la ligne de commande. L’option -n spécifie le nom du projet et l’option -tp spécifie la plateforme cible du projet.
Utilisez l’option -h pour afficher toutes les options disponibles.
# install Microsoft.Build.Sql.Templates
dotnet new sqlproject -n MyDatabaseProject
Étape 2 : ajouter des objets au projet
Dans l'Explorateur de solutions, cliquez avec le bouton droit sur le nœud du projet et sélectionnez Ajouter, puis Table. La boîte de dialogue Ajouter un nouvel élément s'affiche et vous permet de spécifier le nom de la table. Sélectionnez Ajouter pour créer la table dans le projet SQL.
La table est ouverte dans le concepteur de tables de Visual Studio avec la définition de la table modèle, où vous pouvez ajouter des colonnes, des index et d'autres propriétés de table. Enregistrez le fichier lorsque vous avez terminé les premières modifications.
D'autres objets de base de données peuvent être ajoutés via la boîte de dialogue Ajouter un nouvel élément, tels que des vues, des procédures stockées et des fonctions. Pour accéder à la boîte de dialogue, cliquez avec le bouton droit sur le nœud du projet dans l'Explorateur de solutions et sélectionnez Ajouter, puis le type d'objet souhaité. Les fichiers du projet peuvent être organisés en dossiers grâce à l'option Nouveau dossier sous Ajouter.
Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le nœud de projet, puis sélectionnez Ajouter et Nouvel élément. La boîte de dialogue Ajouter un nouvel élément s’affiche, sélectionnez Afficher tous les modèles, puis Table. Spécifiez le nom de la table comme nom de fichier puis sélectionnez Ajouter pour créer la table dans le projet SQL.
La table est ouverte dans l’éditeur de requête de Visual Studio avec la définition de table modèle, où vous pouvez ajouter des colonnes, des index et d’autres propriétés de table. Enregistrez le fichier lorsque vous avez terminé les premières modifications.
D'autres objets de base de données peuvent être ajoutés via la boîte de dialogue Ajouter un nouvel élément, tels que des vues, des procédures stockées et des fonctions. Pour accéder à la boîte de dialogue, cliquez avec le bouton droit sur le nœud du projet dans l'Explorateur de solutions et sélectionnez Ajouter, puis le type d'objet souhaité après Afficher tous les modèles. Les fichiers du projet peuvent être organisés en dossiers grâce à l'option Nouveau dossier sous Ajouter.
Dans la vue Projets de base de données de VS Code ou Azure Data Studio, cliquez avec le bouton droit sur le nœud du projet et sélectionnez Ajouter une table. Indiquez le nom de la table dans la boîte de dialogue qui s'affiche.
La table est ouverte dans l’éditeur de texte avec la définition de table de modèle, où vous pouvez ajouter des colonnes, des index et d’autres propriétés de table. Enregistrez le fichier lorsque vous avez terminé les premières modifications.
D'autres objets de base de données peuvent être ajoutés via le menu local du nœud du projet, tels que les vues, les procédures stockées et les fonctions. Pour accéder à la boîte de dialogue, cliquez avec le bouton droit sur le nœud du projet dans la vue Projets de base de données de VS Code ou Azure Data Studio, puis sur le type d'objet souhaité. Les fichiers du projet peuvent être organisés en dossiers grâce à l'option Nouveau dossier sous Ajouter.
Les fichiers peuvent être ajoutés au projet en les créant dans le répertoire du projet ou dans des dossiers imbriqués. L'extension du fichier doit être .sql et l'organisation par type d'objet ou par schéma et type d'objet est recommandée.
Le modèle de base d'une table peut être utilisé comme point de départ pour la création d'un objet table dans le projet :
CREATE TABLE [dbo].[Table1]
(
[Id] INT NOT NULL PRIMARY KEY
)
Étape 3 : Générer le projet
Le processus de génération valide les relations entre les objets et la syntaxe par rapport à la plateforme cible spécifiée dans le fichier de projet. La production de l'artefact issu du processus de génération est un fichier .dacpac, qui peut être utilisé pour déployer le projet dans une base de données cible et qui contient le modèle compilé du schéma de la base de données.
Dans l'Explorateur de solutions, cliquez avec le bouton droit sur le nœud du projet et sélectionnez Générer.
La Fenêtre Sortie s'ouvre automatiquement pour afficher le processus de génération. Les erreurs ou avertissements éventuels sont affichés dans la fenêtre sortie. Lors d'une génération réussie, l'artefact de génération (fichier .dacpac) est créé et son emplacement est inclus dans la production de la génération (la valeur par défaut est bin\Debug\projectname.dacpac).
Dans l'Explorateur de solutions, cliquez avec le bouton droit sur le nœud du projet et sélectionnez Générer.
La Fenêtre Sortie s'ouvre automatiquement pour afficher le processus de génération. Les erreurs ou avertissements éventuels sont affichés dans la fenêtre sortie. Lors d'une génération réussie, l'artefact de génération (fichier .dacpac) est créé et son emplacement est inclus dans la production de la génération (la valeur par défaut est bin\Debug\projectname.dacpac).
Dans la vue Projets de base de données de VS Code ou Azure Data Studio, cliquez avec le bouton droit sur le nœud du projet et sélectionnez Générer.
La Fenêtre Sortie s'ouvre automatiquement pour afficher le processus de génération. Les erreurs ou avertissements éventuels sont affichés dans la fenêtre sortie. Lors d'une génération réussie, l'artefact de génération (fichier .dacpac) est créé et son emplacement est inclus dans la production de la génération (la valeur par défaut est bin/Debug/projectname.dacpac).
Les projets de base de données SQL peuvent être générés à partir de la ligne de commande à l’aide de la commande dotnet build.
dotnet build
# optionally specify the project file
dotnet build MyDatabaseProject.sqlproj
La production de la génération comprend les erreurs ou les avertissements, ainsi que les fichiers spécifiques et les numéros de ligne où ils se produisent. Lors d'une génération réussie, l'artefact de génération (fichier .dacpac) est créé et son emplacement est inclus dans la production de la génération (la valeur par défaut est bin/Debug/projectname.dacpac).
Étape 4 : vérifier le projet dans le contrôle de code source
Nous allons initialiser notre projet en tant que dépôt Git et valider les fichiers du projet dans le contrôle de code source. Cette étape est nécessaire pour permettre au projet d'être partagé avec d'autres et d'être utilisé dans un pipeline de déploiement continu.
Dans le menu Git de Visual Studio, sélectionnez Créer un référentiel Git.
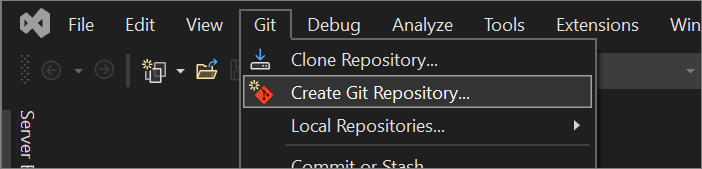
Dans la boîte de dialogue Créer un dépôt Git, sous la section Envoyer (push) vers un nouveau dépôt distant, choisissez GitHub.
Dans la section Créer un dépôt GitHub de la boîte de dialogue Créer un dépôt Git, entrez le nom du dépôt que vous souhaitez créer. (Si vous n’êtes pas encore connecté à votre compte GitHub, vous pouvez également le faire à partir de cet écran.)

Sous Initialiser un dépôt Git local, vous devez utiliser l’option Modèle .gitignore pour spécifier les fichiers dont le suivi ne doit pas être effectué, et que Git doit ignorer. Pour en savoir plus sur .gitignore, consultez Fichiers à ignorer. Et pour en savoir plus sur les licences, consultez Gestion des licences d’un dépôt.
Après vous être connecté et avoir entré les informations de votre dépôt, sélectionnez le bouton Créer et envoyer (push) pour créer votre dépôt et ajouter votre application.

Dans l’Explorateur de solutions, cliquez avec le bouton droit sur le nœud du projet et sélectionnez Publier…..
La boîte de dialogue de publication s'ouvre et vous permet d'établir la connexion à la base de données cible. Si vous ne disposez pas d'une instance SQL existante à déployer, LocalDB ((localdb)\MSSQLLocalDB) est installé avec Visual Studio et peut être utilisé pour les tests et le développement.
Spécifiez un nom de base de données et sélectionnez Publier pour déployer le projet dans la base de données cible ou Générer un script pour générer un script à réviser avant de l'exécuter.
Vous pouvez initialiser un référentiel local et le publier directement sur GitHub depuis VS Code ou Azure Data Studio. Cette action crée un nouveau référentiel sur votre compte GitHub et envoie vos modifications de code locales vers le référentiel distant en une seule étape.
Utilisez le bouton Publier sur GitHub dans la vue Contrôle de code source dans VS Code ou Azure Data Studio. Vous êtes ensuite invité à spécifier un nom et une description pour le référentiel, et à préciser s'il doit être public ou privé.

Vous pouvez également initialiser un référentiel local et l'envoyer sur GitHub en suivant les étapes fournies lors de la création d'un référentiel vide sur GitHub.
Initialisez un nouveau référentiel Git dans le répertoire du projet et validez les fichiers projet dans le contrôle de code source.
git init
git add .
git commit -m "Initial commit"
Créez un référentiel sur GitHub et envoyez le référentiel local vers le référentiel distant.
git remote add origin <repository-url>
git push -u origin main
Étape 5 : ajouter une étape de génération de projet à un pipeline de déploiement continu
Les projets SQL sont soutenus par une bibliothèque .NET et, par conséquent, les projets sont générés avec la commande dotnet build. Cette commande est un élément essentiel des pipelines d'intégration et de déploiement continus (CI/CD), même les plus basiques. L'étape de génération peut être ajoutée à un pipeline de déploiement continu que nous créons dans les actions GitHub.
À la racine du référentiel, créez un répertoire nommé
.github/workflows. Ce répertoire contient le fichier de flux de travail qui définit le pipeline de déploiement continu.Dans le répertoire
.github/workflows, créez un nouveau fichier nommésqlproj-sample.yml.Ajoutez le contenu suivant au fichier
sqlproj-sample.yml, en modifiant le nom du projet pour qu'il corresponde au nom et au chemin d'accès de votre projet :name: sqlproj-sample on: push: branches: [ "main" ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Setup .NET uses: actions/setup-dotnet@v4 with: dotnet-version: 8.0.x - name: Build run: dotnet build MyDatabaseProject.sqlprojLe fichier de flux de travail est validé dans le référentiel et les modifications sont transférées dans le référentiel distant.
Sur GitHub.com, accédez à la page principale du dépôt. Sous le nom de votre dépôt, cliquez sur Actions. Dans le volet gauche, sélectionnez le flux de travail que vous venez de créer. Une exécution récente du flux de travail doit apparaître dans la liste des exécutions de flux de travail à partir du moment où vous avez envoyé le fichier de flux de travail dans le référentiel.
Pour plus d'informations sur les principes fondamentaux de la création de votre premier flux de travail d'actions GitHub, consultez le Guide de démarrage rapide GitHub Actions.
Étape 6 : ajouter une étape de déploiement .dacpac à un pipeline de déploiement continu
Le modèle compilé d'un schéma de base de données dans un fichier .dacpac peut être déployé dans une base de données cible à l'aide de l'outil en ligne de commande SqlPackage ou d'autres outils de déploiement. Le processus de déploiement détermine les étapes nécessaires pour mettre à jour la base de données cible afin qu'elle corresponde au schéma défini dans le .dacpac, en créant ou en modifiant les objets nécessaires sur la base des objets déjà existants dans la base de données. Par exemple, pour déployer un fichier .dacpac dans une base de données cible sur la base d'une chaîne de connexion :
sqlpackage /Action:Publish /SourceFile:bin/Debug/MyDatabaseProject.dacpac /TargetConnectionString:{yourconnectionstring}

Le processus de déploiement est idempotent, ce qui signifie qu'il peut être exécuté plusieurs fois sans causer de problèmes. Le pipeline que nous créons va générer et déployer notre projet SQL à chaque fois qu'une modification est apportée à la branche main de notre référentiel. Au lieu d'exécuter la commande SqlPackage directement dans notre pipeline de déploiement, nous pouvons utiliser une tâche de déploiement qui abstrait la commande et fournit des fonctionnalités supplémentaires telles que la journalisation, la gestion des erreurs et la configuration de la tâche. La tâche de déploiement GitHub sql-action peut être ajoutée à un pipeline de déploiement continu dans les actions GitHub.
Remarque
L'exécution d'un déploiement à partir d'un environnement d'automatisation nécessite la configuration de la base de données et de l'environnement de manière à ce que le déploiement puisse atteindre la base de données et s'authentifier. Il peut être nécessaire de configurer une règle de pare-feu pour permettre à l'environnement d'automatisation de se connecter à la base de données et de fournir une chaîne de connexion avec les identifiants nécessaires pour Azure SQL Database ou SQL Server dans une machine virtuelle. La documentation sql-action de GitHub fournit des conseils à ce sujet.
Ouvrez le fichier
sqlproj-sample.ymldans le répertoire.github/workflows.Ajoutez l'étape suivante au fichier
sqlproj-sample.ymlaprès l'étape de génération :- name: Deploy uses: azure/sql-action@v2 with: connection-string: ${{ secrets.SQL_CONNECTION_STRING }} action: 'publish' path: 'bin/Debug/MyDatabaseProject.dacpac'Avant de valider les modifications, ajoutez un secret au référentiel qui contient la chaîne de connexion à la base de données cible. Dans le référentiel sur GitHub.com, naviguez vers Paramètres, puis Secrets. Sélectionnez Nouveau secret de référentiel et ajoutez un secret nommé
SQL_CONNECTION_STRINGavec la valeur de la chaîne de connexion à la base de données cible.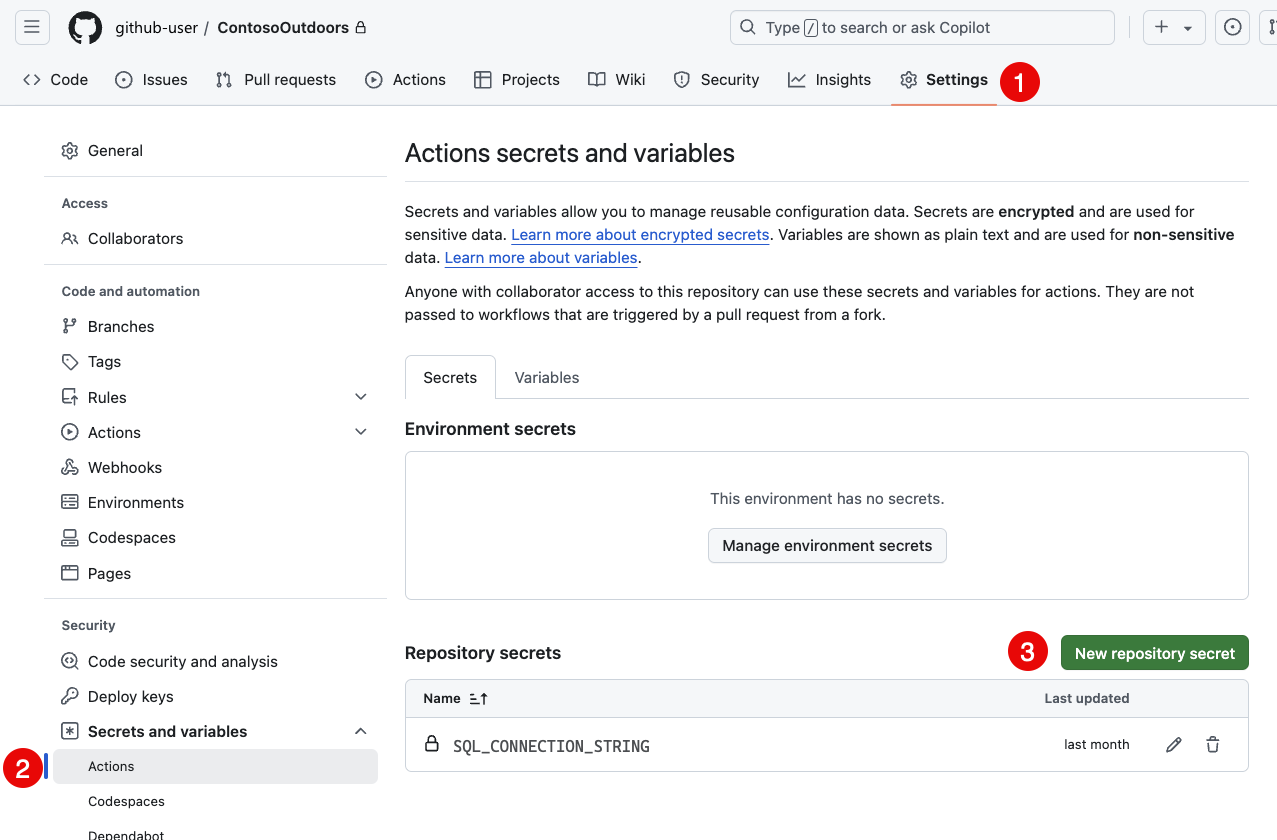
Validation des modifications de
sqlproj-sample.ymldans le référentiel et transfert des modifications dans le référentiel distant.Retournez à l'historique du flux de travail sur GitHub.com et sélectionnez l'exécution la plus récente du flux de travail. L'étape de déploiement doit être visible dans la liste des étapes de l'exécution du flux de travail et le flux de travail renvoie un code de réussite.
Vérifiez le déploiement en vous connectant à la base de données cible et en vérifiant que les objets du projet sont présents dans la base de données.

Les déploiements GitHub peuvent être davantage sécurisés en établissant une relation d'environnement dans un flux de travail et en exigeant une approbation avant l'exécution d'un déploiement. Pour plus d'informations sur la protection de l'environnement et la protection des secrets, consultez la documentation Github Actions.