Exercice – Superviser l’intégrité de votre pipeline
Dans cet exercice, vous allez examiner les fonctionnalités analytiques offertes par Azure Pipelines.
Irwin souhaite savoir comment l’équipe Tailspin peut assurer des mises à en production plus rapides. La création d’un pipeline de mise en production automatisé est un grand pas vers une mise en production rapide et fiable. À mesure que vos mises en production gagnent en fréquence et en rapidité, il est important de comprendre l’intégrité et l’historique de vos mises en production. En observant régulièrement les tendances d’intégrité, vous pouvez diagnostiquer les problèmes potentiels avant qu’ils deviennent critiques.
Avant d’examiner certaines données analytiques de votre pipeline, suivons la conversation de l’équipe Tailspin à l’occasion de leur réunion matinale.
Comment suivre l’intégrité de mon pipeline ?
Le lendemain matin, Lors de la réunion d’équipe, Andy et Mara ont fini leur démonstration du pipeline de build et de mise en production qu’ils ont établi.
Amita : C’est fantastique ! Le pipeline de build était un bon début, mais j’ai quand même dû installer manuellement l’artefact de build dans mon labo pour pouvoir le tester. Si je peux transférer régulièrement ces mises en production dans mon environnement de test, je pourrai déplacer les nouvelles fonctionnalités bien plus rapidement via l’assurance qualité.
Mara : Tout à fait ! Et ne perdons pas de vue qu’il est toujours possible de développer le pipeline de mise en production afin d’y inclure des phases supplémentaires. L’objectif est de créer un workflow de déploiement complet.
Tim : Un environnement intermédiaire serait parfait. Je pourrais effectuer d’autres tests de contrainte avant de présenter les nouvelles fonctionnalités à la direction pour l’approbation finale.
L’équipe s’enthousiasme devant les possibilités offertes par ce nouveau pipeline. Tout le monde se met à parler en même temps.
Andy : Moi aussi je suis satisfait du résultat. Mais ne nous emballons pas. Oui, je pense que nous pouvons apporter toutes ces modifications et plus encore, mais il s’agit simplement d’une preuve de concept. Nous le développerons au fil du temps.
Amita : Alors, comment suivre l’intégrité de nos pipelines de mise en production ?
Andy : Vous souvenez-vous du tableau de bord que nous avons créé pour superviser l’intégrité des builds ? Nous pouvons établir le même type de système pour nos mises en production.
Tim : Cela va plaire à Irwin.
Andy : Laissons de côté la création du tableau de bord de mise en production jusqu’à ce que nous ayons un workflow de mise en production complet. Pour le moment, intéressons-nous à quelques-unes des fonctions analytiques intégrées à Azure Pipelines.
L’équipe se regroupe autour de l’ordinateur portable d’Andy.
Quelles informations l’analytique de pipeline fournit-elle ?
Chaque pipeline fournit des rapports qui comportent des métriques, des tendances et des insights. Ces rapports peuvent vous aider à améliorer l’efficacité de votre pipeline.
Voici ce que les rapports contiennent :
- Le taux de réussite global de votre pipeline.
- Le taux de réussite des tests dans votre pipeline.
- La durée moyenne des exécutions du pipeline, notamment des tâches de génération qui prennent le plus de temps.
Voici un exemple de rapport qui montre les échecs de pipeline, les échecs de test et la durée du pipeline.
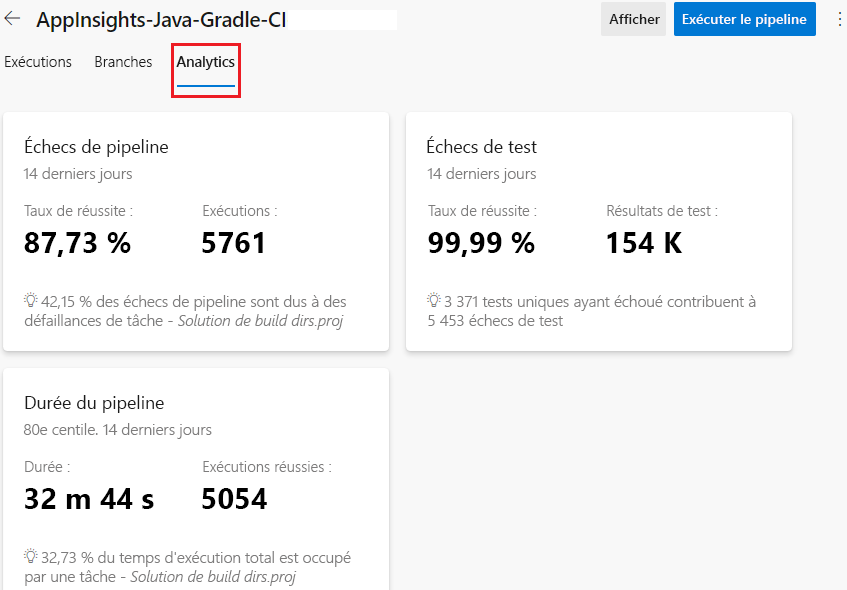
Vous pouvez filtrer les résultats pour examiner en détail une période spécifique ou l’activité globale d’une branche GitHub. Azure DevOps fournit également ces informations sous forme de flux OData. Vous pouvez utiliser ce flux pour publier des rapports et des notifications dans des systèmes tels que Power BI, Microsoft Teams ou Slack. Vous pouvez en apprendre davantage sur les flux analytiques à la fin de ce module.
Explorer l’analytique de votre pipeline
Dans Azure DevOps, sélectionnez Pipelines, puis sélectionnez votre pipeline.
Sélectionnez l’onglet Analyse.

Examinez les taux de réussite et la durée moyenne de vos exécutions de pipeline.
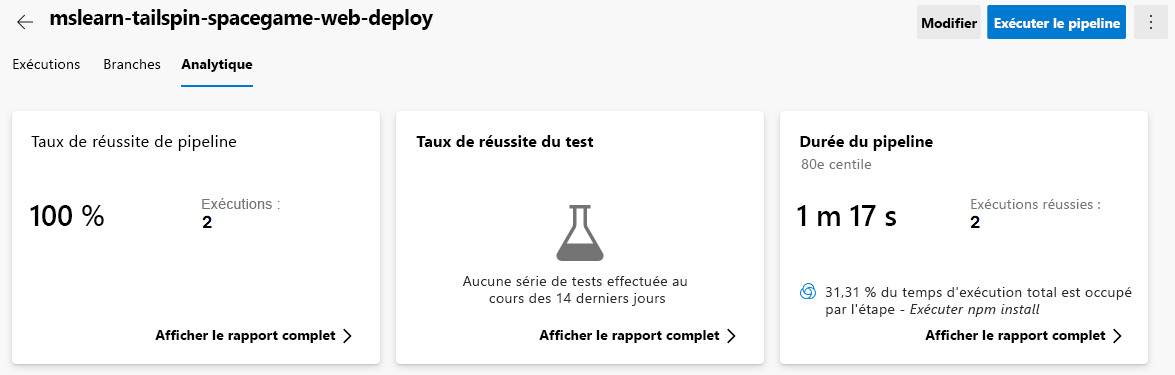
Sous Taux de réussite de pipeline, sélectionnez Afficher le rapport complet pour afficher le rapport détaillé.
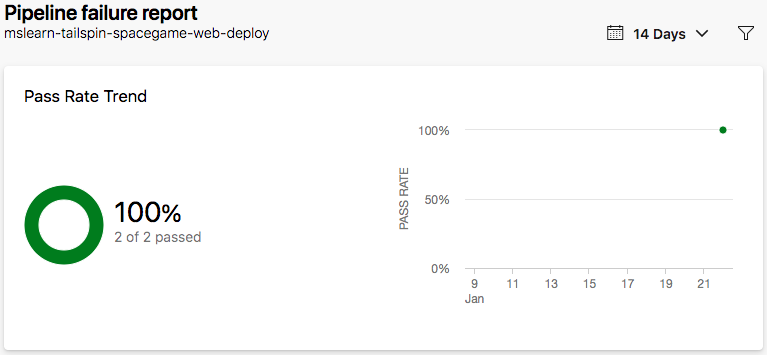
Amita : Ces informations sont utiles, mais je ne vois pas beaucoup de données pour l’instant.
Andy : C’est exact. Nous recueillerons plus de données dans le temps à mesure que nous multiplierons les exécutions. Nous utiliserons ces données pour obtenir des insights et découvrir comment nous pouvons améliorer leur efficacité.
Mara : Je vois que c’est la tâche npm install qui prend le plus de temps. Nous pouvons peut-être l’accélérer en mettant en cache les packages npm.
Andy : C’est une bonne idée. Nous pouvons examiner cela plus en détail à mesure que la quantité d’exécutions de pipeline augmente.