Utiliser l’API Azure AI Speech to text
Le service Azure AI Speech prend en charge la reconnaissance vocale via deux API REST :
- L’API de reconnaissance vocale, qui constitue le principal moyen de procéder à une reconnaissance vocale.
- L’API de reconnaissance vocale pour audio court, qui est optimisée pour les flux de données audio courts (jusqu’à 60 secondes).
Vous pouvez utiliser l’une de ces API pour la reconnaissance vocale interactive, en fonction de la longueur attendue de l’entrée orale. Vous pouvez également utiliser l’API de reconnaissance vocale pour la transcription par lots, en transcrivant plusieurs fichiers audio en texte dans une opération par lots.
Vous pouvez en apprendre plus sur les API REST dans la documentation sur l’API REST de reconnaissance vocale. Dans la pratique, la plupart des applications de reconnaissance vocale interactives utilisent le service Speech via un Kit de développement logiciel (SDK) spécifique au langage.
Utilisation du SDK Azure AI Speech
Même si les détails spécifiques varient selon le kit SDK utilisé (Python, C#, etc.), il existe une constante pour utiliser l’API de reconnaissance vocale :
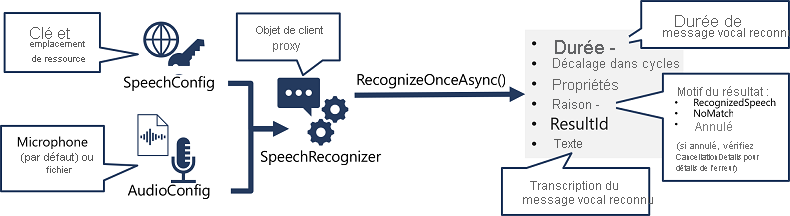
- Utilisez un objet SpeechConfig pour encapsuler les informations de connexion à votre ressource Azure AI Speech. plus précisément son emplacement et sa clé.
- Si vous le souhaitez, utilisez un objet AudioConfig pour définir la source d’entrée de l’audio à transcrire. Il s’agit par défaut du microphone système par défaut, mais vous pouvez également spécifier un fichier audio.
- Utilisez SpeechConfig et AudioConfig pour créer un objet SpeechRecognizer. Cet objet est un client proxy pour l’API de reconnaissance vocale.
- Utilisez les méthodes de l’objet SpeechRecognizer pour appeler les fonctions API sous-jacentes. Par exemple, la méthode RecognizeOnceAsync() utilise le service Azure AI Speech pour transcrire de manière asynchrone un unique énoncé parlé.
- Traitez la réponse du service Azure AI Speech. Dans le cas de la méthode RecognizeOnceAsync(), le résultat est un objet SpeechRecognitionResult qui comprend les propriétés suivantes :
- Durée
- OffsetInTicks
- Propriétés
- Motif
- ResultId
- Texte
Si l’opération a réussi, la propriété Reason affiche la valeur énumérée RecognizedSpeech, et la propriété Text contient la transcription. Les autres valeurs possibles pour Result incluent NoMatch (indiquant que l’audio a été analysé avec succès mais qu’aucun flux oral n’a été reconnu), ou Canceled, indiquant qu’une erreur s’est produite (dans ce cas, vous pouvez rechercher dans la collection Properties la propriété CancellationReason pour identifier la cause du problème).