Utiliser l’API de synthèse vocale
À l’instar des API de reconnaissance vocale, le service Azure AI Speech fournit deux API REST pour la synthèse vocale :
- L’API de synthèse vocale, qui est le principal moyen de procéder à une synthèse vocale.
- L’API de reconnaissance vocale pour audio long, conçue pour prendre en charge les opérations de traitement par lots qui convertissent de gros volumes de texte en données audio, par exemple pour générer un livre audio à partir du texte source.
Vous pouvez en apprendre plus sur les API REST dans la documentation sur l’API REST de synthèse vocale. Dans la pratique, la plupart des applications de reconnaissance vocale interactives utilisent le service Azure AI Speech via un SDK propre au langage (de programmation).
Utilisation du SDK Azure AI Speech
Comme pour la reconnaissance vocale, dans la pratique, la plupart des applications de reconnaissance vocale interactives sont créées à l’aide du SDK Azure AI Speech.
Le modèle d’implémentation de la synthèse vocale est semblable à celui de la reconnaissance vocale :
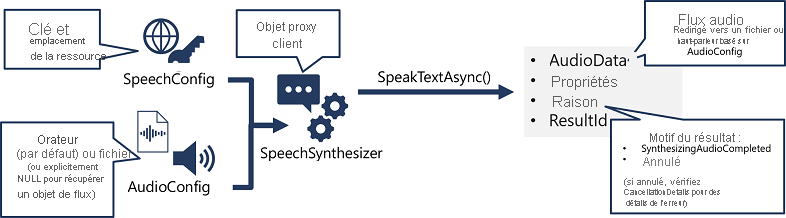
- Utilisez un objet SpeechConfig pour encapsuler les informations de connexion à votre ressource Azure AI Speech. plus précisément son emplacement et sa clé.
- Vous pouvez utiliser un objet AudioConfig afin de définir le périphérique de sortie pour le message à synthétiser. Par défaut, il s’agit du haut-parleur du système, mais vous pouvez également spécifier un fichier audio, ou si vous définissez explicitement cette valeur sur une valeur null, vous pouvez traiter l’objet de flux audio qui est retourné directement.
- Utilisez SpeechConfig et AudioConfig pour créer un objet SpeechSynthesizer. Cet objet est un client proxy pour l’API de synthèse vocale.
- Utilisez les méthodes de l’objet SpeechSynthesizer pour appeler les fonctions API sous-jacentes. Par exemple, la méthode SpeakTextAsync() utilise le service Azure AI Speech pour convertir un texte en contenu audio.
- Traitez la réponse du service Azure AI Speech. Dans le cas de la méthode SpeakTextAsync, le résultat est un objet SpeechSynthesisResult qui contient les propriétés suivantes :
- AudioData
- Propriétés
- Motif
- ResultId
Lorsque l’audio a été synthétisé avec succès, la propriété Reason est définie sur l’énumération SynthesizingAudioCompleted, et la propriété AudioData contient le flux audio (qui, selon AudioConfig peut avoir été envoyé automatiquement à un haut-parleur ou un fichier).