Comprendre les concepts de Deep Learning
Dans votre cerveau, vous avez des cellules nerveuses appelées neurones, qui sont connectées les unes aux autres par des extensions nerveuses qui passent des signaux électrochimiques via le réseau.

Lorsque le premier neurone du réseau est stimulé, le signal d’entrée est traité, et s’il dépasse un seuil particulier, le neurone est activé et transmet le signal aux neurones auxquels il est connecté. Ces neurones peuvent ensuite être activés et transmettre le signal au reste du réseau. Au fil du temps, les connexions entre les neurones sont renforcées par une utilisation fréquente, car vous apprenez à réagir efficacement. Par exemple, si vous voyez une image d’un pingouin, vos connexions neuronales vous permettent de traiter les informations contenues dans l’image et votre connaissance des caractéristiques d’un pingouin pour l’identifier comme tel. Au fil du temps, si vous voyez plusieurs images de différents animaux, le réseau de neurones impliqués dans l’identification des animaux en fonction de leurs caractéristiques se renforce. En d’autres termes, vous parvenez à identifier de mieux en mieux différents animaux avec justesse.
Le Deep Learning émule ce processus biologique à l’aide de réseaux neuronaux artificiels qui traitent des entrées numériques plutôt que des stimulis électrochimiques.
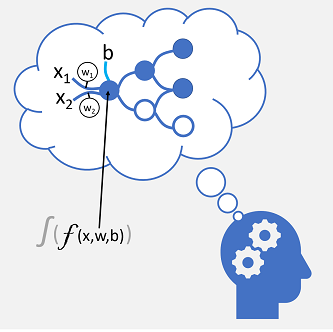
Les connexions de nerfs entrantes sont remplacées par des entrées numériques qui sont généralement identifiées comme x. Quand il existe plusieurs valeurs d’entrée, x est considéré comme un vecteur avec des éléments nommés x1, x2, et ainsi de suite.
Une pondération weight (w) est associée à chaque valeur x pour renforcer ou affaiblir l’effet de la valeur x afin de simuler l’apprentissage. En outre, une entrée de biais bias (b) est ajoutée pour permettre un contrôle affiné sur le réseau. Pendant le processus d’entraînement, les valeurs w et b sont ajustées pour paramétrer le réseau afin qu’il « apprenne » à produire des sorties correctes.
Le neurone lui-même encapsule une fonction qui calcule une somme pondérée de x, w et b. Cette fonction est à son tour placée dans une fonction activation qui limite le résultat (souvent à une valeur comprise entre 0 et 1) pour déterminer si le neurone passe une sortie sur la couche suivante de neurones dans le réseau.
Entraînement d’un modèle Deep Learning
Les modèles Deep Learning sont des réseaux neuronaux qui se composent de plusieurs couches de neurones artificiels. Chaque couche représente un ensemble de fonctions qui sont effectuées sur les valeurs x avec des pondérations w et des tendances b associés, et les résultats de la couche finale sur une sortie de l’étiquette y prédite par le modèle. Dans le cas d’un modèle de classification (qui prédit la catégorie ou la classe la plus probable pour les données d’entrée), la sortie est un vecteur contenant la probabilité pour chaque classe possible.
Le diagramme suivant représente un modèle Deep Learning qui prédit la classe d’une entité de données en fonction de quatre caractéristiques (les valeurs x). La sortie du modèle (les valeurs y) est la probabilité pour chacune des trois étiquettes de classe possibles.
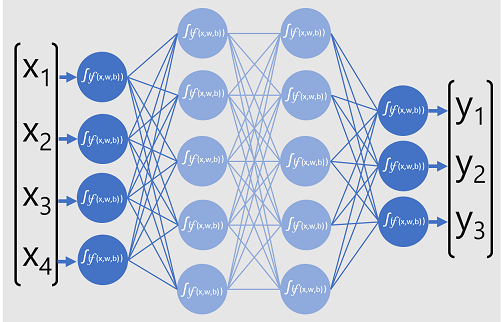
Pour entraîner le modèle, une infrastructure de Deep Learning alimente plusieurs lots de données d’entrée (pour lesquelles les valeurs d’étiquette réelles sont connues), applique les fonctions dans toutes les couches réseau et mesure la différence entre les probabilités de sortie et les étiquettes de classe connues réelles des données d’entraînement. La différence agrégée entre les sorties de prédiction et les étiquettes réelles est appelée perte.
Après avoir calculé la perte d’agrégation pour tous les lots de données, l’infrastructure de Deep Learning utilise un optimiseur pour déterminer comment les pondérations et les tendances dans le modèle doivent être ajustées afin de réduire la perte globale. Ces ajustements sont ensuite rétropropagés dans les couches du modèle de réseau neuronal, puis les données sont à nouveau transmises via le réseau et la perte est recalculée. Ce processus se répète plusieurs fois (chaque itération est appelée époque) jusqu’à ce que la perte soit réduite et que le modèle ait « appris » les pondérations et les tendances appropriées pour pouvoir effectuer des prédictions justes.
Pendant chaque époque, les pondérations et les tendances sont ajustées pour réduire la perte. Le montant en fonction duquel ils sont ajustés est régi par le taux d’entraînement que vous spécifiez à l’optimiseur. Si le taux d’entraînement est trop faible, le processus d’entraînement peut prendre beaucoup de temps pour déterminer les valeurs optimales ; mais s’il est trop élevé, l’optimiseur risque de ne jamais trouver les valeurs optimales.