Décrire les options PaaS pour le déploiement de SQL Server dans Azure
PaaS (Platform as a Service) propose un environnement de développement et de déploiement complet dans le cloud, qui peut être utilisé pour les applications cloud simples ainsi que pour les applications d’entreprise avancées.
Azure SQL Database et Azure SQL Managed Instance font partie de l’offre PaaS pour Azure SQL.
Azure SQL Database – Fait partie d’une famille de produits reposant sur le moteur SQL Server, dans le cloud. Il offre aux développeurs une grande flexibilité pour la création de nouveaux services d’application et d’options de déploiement précises à grande échelle. SQL Database offre une solution nécessitant peu de maintenance qui peut être une option intéressante pour certaines charges de travail.
Azure SQL Managed Instance – Il est idéal pour la plupart des scénarios de migration vers le cloud, car il fournit des fonctionnalités et des services complètement managés.
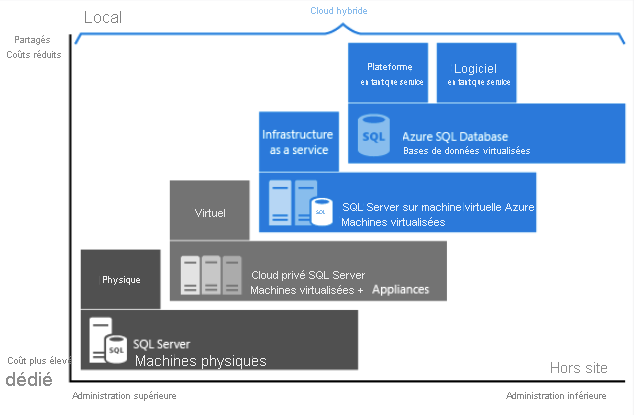
Comme vous le voyez dans l’image ci-dessus, chaque offre fournit un certain niveau d’administration dont vous disposez sur l’infrastructure, par le degré de rentabilité.
Modèles de déploiement
Azure SQL Database est disponible en deux modèles de déploiement différents :
Base de données unique – Base de données unique qui est facturée et gérée de façon individuelle. Vous gérez chacune de vos bases de données individuellement du point de vue de l’échelle et de la taille des données. Chaque base de données déployée dans ce modèle a ses propres ressources dédiées, même si elle est déployée sur le même serveur logique.
Pools élastiques – Groupe de bases de données qui sont gérées ensemble et qui partagent un ensemble commun de ressources. Les pools élastiques offrent une solution économique pour le modèle d’application SaaS (Software as a Service), car les ressources sont partagées entre toutes les bases de données. Vous pouvez configurer des ressources en fonction du modèle d’achat DTU ou du modèle d’achat vCore.
Modèle d’achat
Dans Azure, tous les services s’appuient sur du matériel physique et vous pouvez choisir parmi deux modèles d’achat différents :
DTU (Database Transaction Unit)
Les unités DTU sont calculées selon une formule combinant les ressources de calcul, de stockage et d’E/S. C’est un bon choix pour les clients qui souhaitent des options de ressources simples et préconfigurées.
Le modèle d’achat DTU est proposé dans plusieurs niveaux de service différents, comme De base, Standard et Premium. Chaque niveau a des fonctionnalités différentes, qui offrent un large éventail d’options au moment du choix de cette plateforme.
En termes de performances, le niveau De base est utilisé pour les charges de travail moins exigeantes, tandis que Premium est utilisé pour des charges de travail intensives.
Les ressources de calcul et de stockage dépendent du niveau DTU et ils offrent une gamme de fonctionnalités de performances avec une limite fixe de stockage, de conservation des sauvegardes et de coûts.
Notes
Le modèle d’achat DTU est pris en charge uniquement par Azure SQL Database.
Pour plus d’informations sur le modèle d’achat DTU, consultez Vue d’ensemble du modèle d’achat DTU.
vCore
Le modèle vCore vous permet d’acheter un nombre spécifié de vCores en fonction de vos charges de travail données. vCore est le modèle d’achat par défaut lors de l’achat de ressources Azure SQL Database. Les bases de données vCore ont une relation spécifique entre le nombre de cœurs et la quantité de mémoire et de stockage fournie à la base de données. Le modèle d’achat vCore est pris en charge par Azure SQL Database et Azure SQL Managed Instance.
Vous pouvez également acheter des bases de données vCore dans trois niveaux de service différents :
Usage général – Ce niveau est destiné aux charges de travail à usage général. Il repose sur le stockage Premium Azure. Sa latence est plus élevée que celle du niveau Critique pour l’entreprise. Il fournit également les niveaux de calcul suivants :
- Provisionné – Les ressources de calcul sont préallouées. Facturé à l’heure selon le nombre de vCores configurés.
- Serverless – Les ressources de calcul sont mises à l’échelle automatiquement. Facturé à la seconde selon le nombre de vCores utilisés.
Critique pour l’entreprise – Ce niveau est destiné aux charges de travail hautes performances et offre la latence la plus faible des deux niveaux de service. Ce niveau repose sur les disques SSD locaux et non sur le stockage Blob Azure. Il offre également la résilience la plus élevée aux pannes et fournit un réplica de base de données en lecture seule intégré qui peut être utilisé pour décharger les charges de travail de rapports.
Hyperscale – Les bases de données hyperscale peuvent être mises à l’échelle bien au-delà de la limite de 4 To des autres offres Azure SQL Database et présentent une architecture unique qui prend en charge des bases de données allant jusqu’à 100 To.
Sans serveur
Le nom « serverless » peut prêter à confusion, car vous déployez toujours Azure SQL Database sur un serveur logique auquel vous vous connectez. Azure SQL Database serverless est un niveau de calcul qui effectue automatiquement un scale-up ou un scale-down des ressources pour une base de données spécifique en fonction de la demande de charge de travail. Si la charge de travail n’a plus besoin de ressources de calcul, la base de données passe « en pause » et seul le stockage est facturé pendant la période où elle est inactive. Lorsqu’une tentative de connexion est effectuée, la base de données « reprend » et devient disponible.
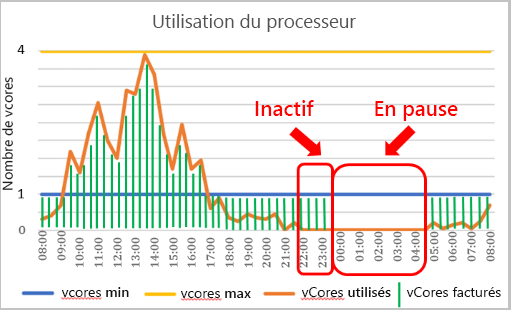
Le paramètre de contrôle de la suspension est appelé délai de pause automatique et a une valeur minimale de 60 minutes et une valeur maximale de sept jours. Si la base de données est inactive pendant ce laps de temps, elle est suspendue.
Si la base de données est inactive pendant la durée spécifiée, elle est suspendue jusqu’à une prochaine tentative de connexion. La configuration d’une plage de mise à l’échelle automatique de calcul et d’un délai de pause automatique affecte les performances de la base de données et les coûts de calcul.
Toutes les applications qui utilisent le modèle serverless doivent être configurées pour gérer les erreurs de connexion et inclure la logique de nouvelle tentative, car la connexion à une base de données suspendue génère une erreur de connexion.
Une autre différence entre le modèle vCore normal et serverless d’Azure SQL Database est que le modèle serverless vous permet de spécifier un nombre minimal et maximal de vCores. Les limites en mémoire et E/S sont proportionnelles à la plage spécifiée.
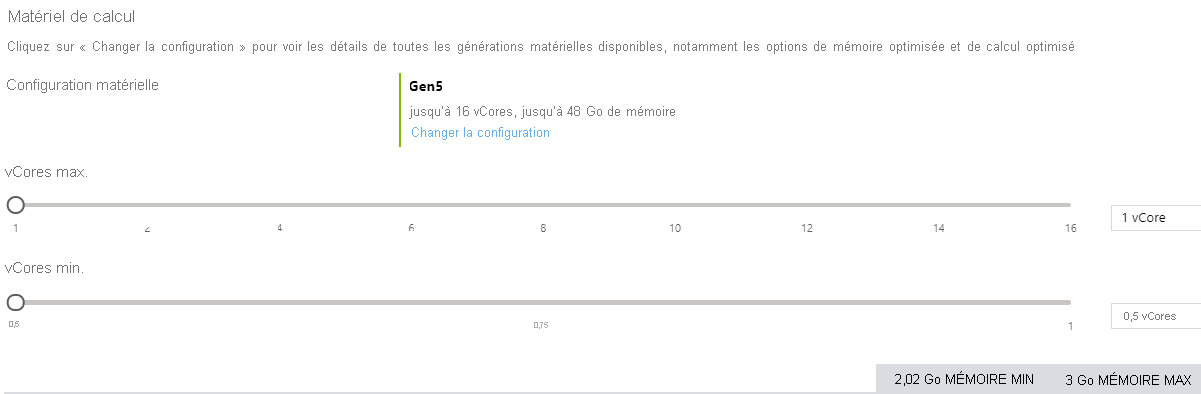
L’image ci-dessus montre l’écran de configuration d’une base de données serverless dans le portail Azure. Vous avez la possibilité de sélectionner une valeur minimale correspondant à la moitié d’un vCore et une valeur maximale correspondant à 16 vCores.
Serverless n’est pas entièrement compatible avec toutes les fonctionnalités Azure SQL Database, car certaines d’entre elles demandent des processus en arrière-plan pour s’exécuter tout le temps, par exemple :
- Géoréplication
- Rétention des sauvegardes à long terme
- Base de données de travail dans les travaux élastiques
- Base de données de synchronisation dans SQL Data Sync (Data Sync est un service qui réplique les données parmi un groupe de bases de données)
Notes
Actuellement, SQL Database serverless est juste pris en charge dans le niveau Usage général dans le modèle d’achat Vcore.
Sauvegardes
Les sauvegardes constituent l’une des fonctionnalités les plus importantes de l’offre PaaS (Platform as a Service). Dans ce cas, les sauvegardes sont effectuées automatiquement sans aucune intervention de votre part. Les sauvegardes sont placées dans le stockage Blob Azure géoredondant et sont conservées par défaut entre 7 et 35 jours, en fonction du niveau de service de la base de données. Les bases de données de base et vCore sont conservées par défaut pendant sept jours et, sur les bases de données vCore, cette valeur peut être ajustée par l’administrateur. La durée de conservation peut être étendue en configurant une conservation à long terme, ce qui vous permet de stocker les sauvegardes pendant 10 ans au maximum.
Pour assurer la redondance, vous pouvez également utiliser le stockage Blob géoredondant accessible en lecture. Ce stockage réplique vos sauvegardes de bases de données vers une région secondaire de votre préférence. Il vous permet également de lire à partir de cette région secondaire si nécessaire. Les sauvegardes manuelles des bases de données ne sont pas prises en charge et la plateforme rejette toute demande à cette fin.
Les sauvegardes de bases de données sont effectuées selon une planification donnée :
- Complète – Une fois par semaine
- Différentielle – Toutes les 12 heures
- Journal – Toutes les 5 à 10 minutes en fonction de l’activité du journal des transactions
Cette planification de sauvegarde doit répondre aux besoins de la plupart des objectifs de point/délai de récupération (RPO/RTO). Toutefois, chaque client doit déterminer s’il répond à vos besoins métier.
Il existe plusieurs options disponibles pour la restauration d’une base de données. En raison de la nature de Platform as a Service, vous ne pouvez pas restaurer manuellement une base de données à l’aide de méthodes conventionnelles, telles que l’émission de la commande RESTORE DATABASE.
Quelle que soit la méthode de restauration implémentée, il n’est pas possible d’effectuer une restauration sur une base de données existante. Si une base de données doit être restaurée, la base de données existante doit être supprimée ou renommée avant de lancer le processus de restauration. Gardez aussi à l’esprit qu’en fonction du niveau de service de la plateforme, les durées de restauration ne sont pas garanties et peuvent varier. Il est recommandé de tester le processus de restauration pour obtenir une métrique de référence sur la durée éventuelle d’une restauration.
Les options de restauration disponibles sont les suivantes :
Restaurer à l’aide du portail Azure– Le portail Azure vous donne la possibilité de restaurer une base de données sur le même serveur Azure SQL Database, ou vous pouvez utiliser la restauration pour créer une base de données sur un nouveau serveur dans n’importe quelle région Azure.
Restaurer à l’aide des langages de script – PowerShell et Azure CLI peuvent être utilisés pour restaurer une base de données.
Notes
La sauvegarde de copie uniquement vers Stockage Blob Azure est disponible pour SQL Managed Instance. SQL Database ne prend pas en charge cette fonctionnalité.
Pour plus d’informations sur les sauvegardes automatisées, consultez Sauvegardes automatisées - Azure SQL Database et Azure SQL Managed Instance.
La géoréplication active
La géoréplication est une fonctionnalité de continuité d’activité qui réplique de façon asynchrone une base de données vers quatre réplicas secondaires au maximum. Lorsque les transactions sont validées sur la base de données primaire (et ses réplicas dans la même région), elles sont envoyées aux bases de données secondaires pour être relues. Étant donné que cette communication est effectuée de façon asynchrone, l’application appelante n’a pas besoin d’attendre que le réplica secondaire valide la transaction avant que SQL Server ne retourne le contrôle à l’appelant.
Les bases de données secondaires sont accessibles en lecture et peuvent être utilisées pour décharger des charges de travail en lecture seule, ce qui permet de libérer des ressources pour les charges de travail transactionnelles sur la base de données primaire ou de rapprocher les données de vos utilisateurs finaux. En outre, les bases de données secondaires peuvent se trouver dans la même région que la base de données primaire ou dans une autre région Azure.
La géoréplication vous permet de lancer un basculement manuellement par l’utilisateur ou à partir de l’application. Si un basculement se produit, vous devrez peut-être mettre à jour les chaînes de connexion d’application pour refléter le nouveau point de terminaison de ce qui est désormais la base de données primaire.
Groupes de basculement
Les groupes de basculement s’appuient sur la technologie utilisée dans la géoréplication, mais fournissent un point de terminaison unique pour la connexion. La principale raison d’utiliser des groupes de basculement est que la technologie fournit des points de terminaison, qui permettent de router le trafic vers le réplica approprié. Votre application peut ensuite se connecter après un basculement sans modifications des chaînes de connexion.