Comprendre une base de données SQL hyperscale
Azure SQL Database a été limité à 4 To de stockage par base de données pendant de nombreuses années. Cette restriction est due à une limitation physique de l’infrastructure Azure. Azure SQL Database hyperscale change le paradigme et permet aux bases de données d’avoir une capacité de 100 To ou plus. Hyperscale introduit de nouvelles techniques de mise à l’échelle horizontale pour ajouter des nœuds de calcul à mesure que les tailles de données augmentent. Le coût d’hyperscale est le même que celui d’Azure SQL Database ; toutefois, il existe un coût par téraoctet pour le stockage. Notez qu’une fois qu’une base de données Azure SQL Database est convertie en hyperscale, vous ne pouvez pas la reconvertir en Azure SQL Database « standard ». Hyperscale est la capacité d’une architecture à mettre à l’échelle de manière appropriée, comme demandé.
Azure SQL Database Hyperscale est un très bon choix pour la plupart des charges de travail métier, car il offre une grande flexibilité et des performances élevées avec des ressources de calcul et de stockage scalables de manière indépendante.
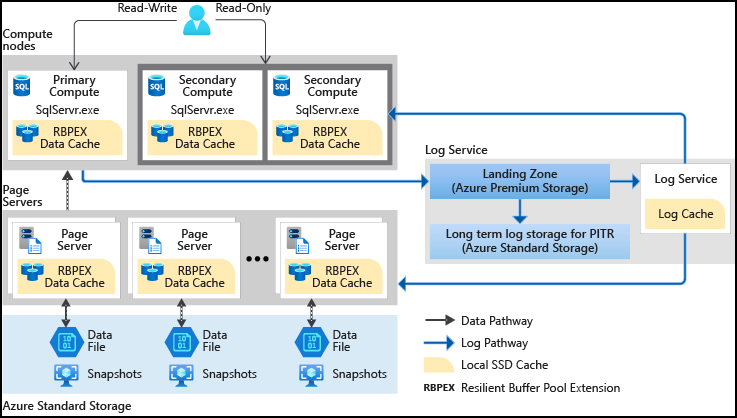
Hyperscale sépare le moteur de traitement des requêtes, où la sémantique des différents moteurs de données diverge, des composants qui assurent le stockage et la durabilité à long terme des données. De cette façon, la capacité de stockage peut être facilement mise à l’échelle pour répondre aux besoins.
Le niveau de service Hyperscale dans Azure SQL Database est le tout nouveau niveau de service du modèle d’achat vCore. Ce niveau de service est un stockage hautement scalable et un niveau de performances de calcul qui utilise Azure pour effectuer un scale-out du stockage et des ressources de calcul d’une base de données Azure SQL bien au-delà des limites disponibles des niveaux Usage général et Critique pour l’entreprise.
Avantages
Le niveau de service Hyperscale supprime de nombreuses limites pratiques traditionnellement rencontrées dans les bases de données cloud. Là où la plupart des autres bases de données sont limitées par les ressources disponibles dans un seul nœud, les bases de données du niveau de service Hyperscale n’ont pas de limite. Avec son architecture de stockage flexible, le stockage augmente en fonction des besoins. En fait, les bases de données Hyperscale sont créées sans taille maximale définie. Une base de données Hyperscale augmente en fonction des besoins, et vous êtes facturé uniquement pour la capacité que vous utilisez. Pour les charges de travail gourmandes en lecture, le niveau de service Hyperscale permet un scale-out rapide en provisionnant des réplicas supplémentaires en fonction des besoins pour les décharger.
Par ailleurs, le temps nécessaire pour créer des sauvegardes de base de données ou pour augmenter ou diminuer la puissance n’est plus lié au volume de données de la base de données. Les bases de données Hyperscale peuvent être sauvegardées instantanément. Vous pouvez aussi mettre à l’échelle une base de données de plusieurs dizaines de téraoctets en quelques minutes. Cette fonctionnalité vous évite d’être limité par votre choix de configuration initial. Hyperscale fournit également des restaurations rapides de base de données qui s’exécutent en quelques minutes au lieu de quelques heures ou jours.
Hyperscale offre une scalabilité rapide en fonction de la demande de votre charge de travail.
Scale-up/down – Vous pouvez effectuer un scale-up de la taille de calcul principale en termes de ressources, comme le processeur et la mémoire, puis effectuer un scale-down, en durée constante. Étant donné que le stockage est partagé, le scale-up et le scale-down ne sont pas liés au volume de données de la base de données.
Scale-in/out – Vous avec également la possibilité de provisionner un ou plusieurs réplicas de calcul, que vous pouvez utiliser pour répondre à vos demandes de lecture. Cela signifie que vous pouvez utiliser ces réplicas de calcul supplémentaires comme réplicas en lecture seule pour décharger votre charge de travail de lecture en dehors de la capacité de calcul principale. En plus des opérations en lecture seule, ces réplicas font également office de serveurs de secours en cas de basculement à partir du serveur principal.
Le provisionnement de chacun de ces réplicas de calcul supplémentaires peut être effectué en durée constante et est une opération en ligne. Vous pouvez vous connecter aux réplicas de calcul en lecture seule en définissant l’argument ApplicationIntent de votre chaîne de connexion sur ReadOnly. Les connexions avec l’intention d’application ReadOnly sont automatiquement routées vers l’un des réplicas de calcul en lecture seule.
L’approche Hyperscale sépare le moteur de traitement des requêtes des composants qui fournissent un stockage à long terme et une durabilité pour les données. Cette architecture offre la possibilité de mettre à l’échelle la capacité de stockage en douceur autant que nécessaire (la cible initiale est de 100 To) et de mettre à l’échelle les ressources de calcul rapidement.
Considérations relatives à la sécurité
La sécurité pour le niveau de service Hyperscale partage les mêmes grandes fonctionnalités que les autres niveaux Azure SQL Database. Elle est protégée par l’approche en couches de défense en profondeur comme illustré ci-après, et part de l’extérieur vers l’intérieur :
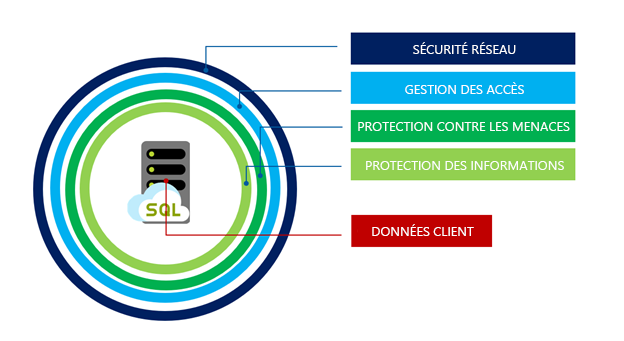
La sécurité réseau est la première couche de défense et utilise des règles de pare-feu IP pour autoriser l’accès en fonction de l’adresse IP d’origine et des règles de pare-feu Réseau virtuel dans le but de pouvoir accepter les communications envoyées des sous-réseaux sélectionnés d’un réseau virtuel.
La gestion des accès est fournie au travers des méthodes d’authentification ci-dessous pour vous assurer qu’un utilisateur est bien celui qu’il prétend être :
- Authentification SQL
- Authentification Microsoft Entra
- Authentification Windows pour les principaux Microsoft Entra (préversion)
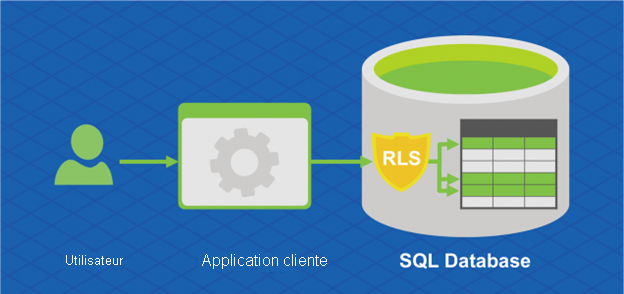
Azure SQL Database Hyperscale prend également en charge la sécurité au niveau des lignes. La sécurité au niveau des lignes permet aux clients de contrôler l'accès aux lignes d'une table de base de données en fonction des caractéristiques de l'utilisateur exécutant une requête (appartenance à un groupe ou contexte d'exécution, par exemple).
Protection contre les menaces dans les fonctionnalités d’audit et de détection des menaces. L’audit SQL Database et SQL Managed Instance suit les activités de base de données et permet d’assurer la conformité avec les normes de sécurité en enregistrant les événements de base de données dans un journal d’audit d’un compte de stockage Azure appartenant au client. Advanced Threat Protection peut être activé par serveur moyennant un supplément et analyse vos journaux pour détecter un comportement inhabituel et des tentatives potentiellement dangereuses d’accès ou d’exploitation des bases de données. Des alertes sont créées pour les activités suspectes, telles que les attaques par injection de code SQL, infiltration potentielle de données et force brute, ainsi que pour les anomalies des modèles d’accès afin d’intercepter les réaffectations de privilèges et l’utilisation d’informations d’identification ayant fait l’objet de violation de sécurité.
La protection des informations est fournie des différentes manières suivantes :
- Transport Layer Security (Chiffrement en transit)
- Transparent Data Encryption (chiffrement des données au repos)
- Gestion des clés dans Azure Key Vault
- Always Encrypted (Chiffrement en cours d’utilisation)
- Masquage dynamique des données
Considérations relatives aux performances
Le niveau de service Hyperscale est destiné aux clients qui ont de grandes bases de données SQL Server locales et qui veulent moderniser leurs applications en les déplaçant dans le cloud, ou aux clients qui utilisent déjà Azure SQL Database et qui veulent étendre considérablement le potentiel de croissance de leurs bases de données. Hyperscale est également destiné aux clients qui recherchent à la fois des hautes performances et une scalabilité élevée.
Hyperscale offre les fonctionnalités de performances suivantes :
- Sauvegardes de base de données quasi instantanées (basées sur des instantanés de fichiers conservés dans le Stockage Blob Azure), quel que soit leur taille, sans effet des E/S sur les ressources de calcul.
- Restaurations de base de données rapides (basées sur des instantanés de fichiers) en minutes plutôt qu’en heures ou en jours (opération qui ne dépend pas de la taille des données).
- Des performances globales plus élevées grâce à un débit plus important du journal des transactions et à des temps de validation des transactions plus rapides, quel que soit le volume des données.
- Effectuer un scale-out rapide : vous pouvez provisionner un ou plusieurs réplicas en lecture seule pour déplacer votre charge de travail de lecture et les utiliser comme serveurs de secours.
- Scale-up rapide : vous pouvez, en temps constant, augmenter la puissance de vos ressources de calcul pour prendre en charge des charges de travail lourdes en cas de besoin, puis la diminuer à nouveau.
Notes
SQL Database Hyperscale ne prend pas en charge les fonctionnalités suivantes :
- Instance managée SQL
- Pools élastiques
- Géoréplication
- Query Performance Insight
Déploiement d’Azure SQL Database Hyperscale
Pour déployer Azure SQL Database avec le niveau Hyperscale :
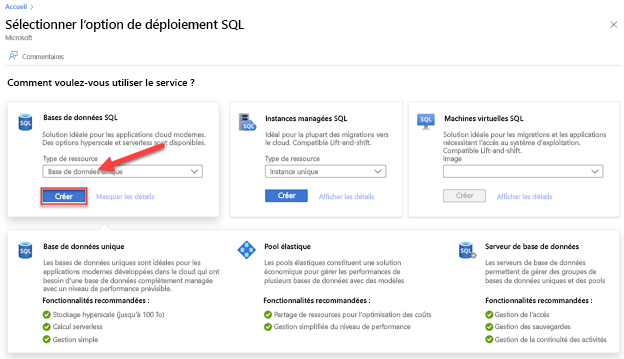
Accédez à la page Sélectionner l’option de déploiement SQL.
Sous Bases de données SQL, laissez Type de ressource défini sur Base de données unique, puis sélectionnez Créer.
Sous l’onglet Informations de base de la page Créer une base de données SQL, sélectionnez l’abonnement, le groupe de ressources et le nom de la base de données souhaités.
Sélectionnez le lien Créer nouveau pour le Serveur, puis fournissez les nouvelles informations de serveur, telles que le nom du serveur, le nom de l’administrateur du serveur et le mot de passe, et la localisation.
Sous Calcul + stockage, sélectionnez le lien Configurer la base de données.
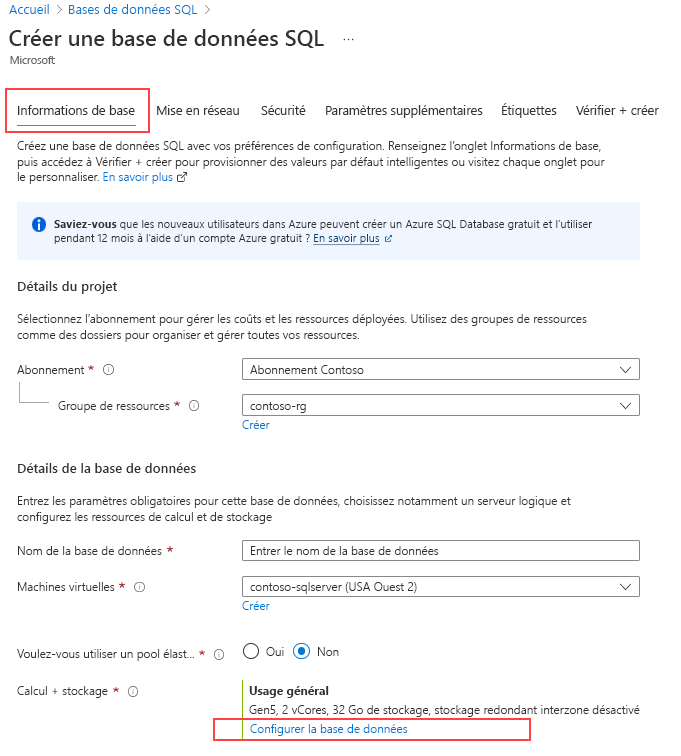
Pour Niveau service, sélectionnez Hyperscale.
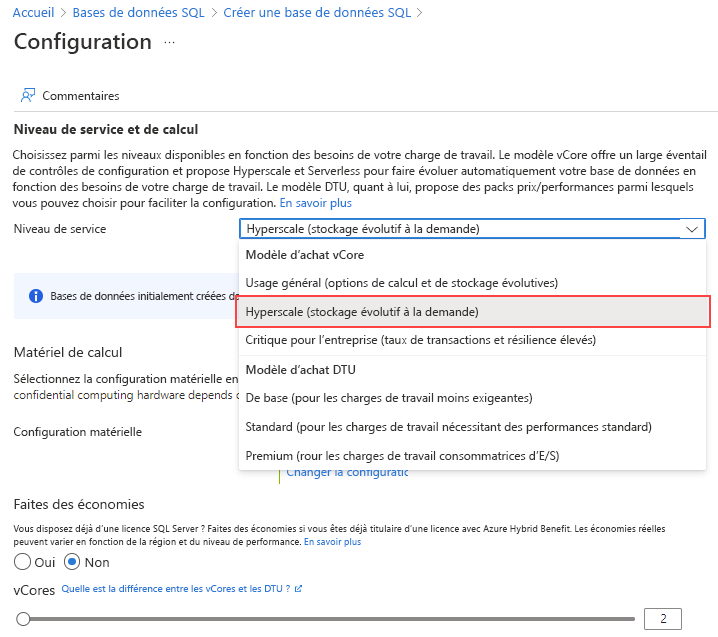
Sous Configuration matérielle, sélectionnez le lien Modifier la configuration. Passez en revue les configurations matérielles disponibles et sélectionnez la configuration la plus appropriée pour votre base de données. Pour cet exemple, nous allons sélectionner la configuration Gen5.
Sélectionnez OK pour confirmer la génération matérielle.
Si vous le souhaitez, ajustez le curseur vCores si vous souhaitez augmenter le nombre de vCores pour votre base de données. Pour cet exemple, nous allons sélectionner 2 vCores.
Ajustez le curseur Réplicas secondaires à haute disponibilité pour créer un réplica à haute disponibilité. Sélectionnez Appliquer.
Sélectionnez Suivant : Réseau en bas de la page.
Pour Règles de pare-feu sous l’onglet Réseaux, affectez la valeur Oui à Ajouter l’adresse IP actuelle du client. Laissez Autoriser les services et les ressources Azure à accéder à ce serveur avec la valeur Non.
Sélectionnez Suivant : Sécurité en bas de la page.
Sous l’onglet Review + create (Vérifier + créer) , sélectionnez Créer.
