Stocker des vecteurs dans Azure Database pour PostgreSQL
Pour rappel, vous devez incorporer les vecteurs stockés dans une base de données vectorielle pour exécuter une recherche sémantique. Vous pouvez utiliser le serveur flexible Azure Database pour PostgreSQL comme base de données vectorielle avec l’extension vector.
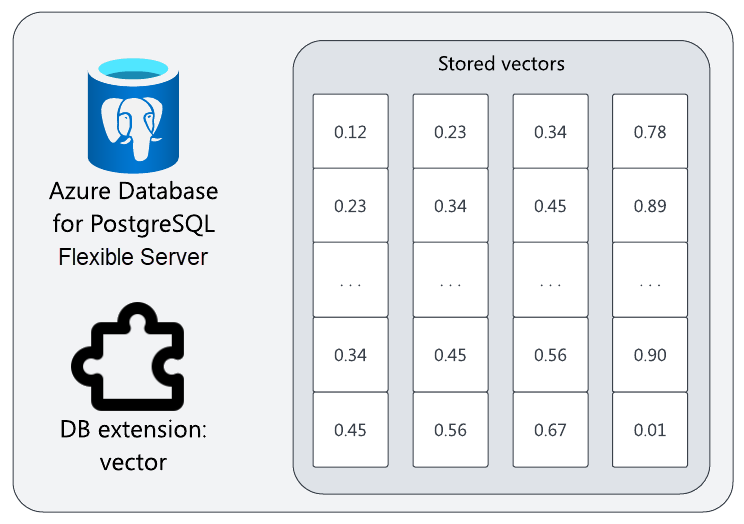
Présentation de vector
L’extension vector open source fournit le stockage de vecteurs, des requêtes de similarité et d’autres opérations vectorielles pour PostgreSQL. Une fois l’extension activée, vous pouvez créer des colonnes vector pour stocker des incorporations (ou d’autres vecteurs) aux côtés d’autres colonnes.
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
Vous pouvez ajouter des colonnes vectorielles à des tables existantes :
ALTER TABLE documents ADD COLUMN embedding vector(3);
Une fois que vous disposez de données vectorielles, vous pouvez les voir aux côtés des données de tables normales :
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
L’extension vector prend en charge plusieurs langages comme .NET, Python, Java, etc. Pour plus d’informations, consultez leurs dépôts GitHub .
Pour insérer un document avec le vecteur [1, 2, 3] à l’aide de Npgsql en C#, exécutez du code similaire au suivant :
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
Insérer et mettre à jour des vecteurs
Une fois qu’une table a une colonne vectorielle, vous pouvez ajouter des lignes avec des valeurs vectorielles, comme indiqué précédemment.
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
Vous pouvez également charger des vecteurs en bloc à l’aide de l’instruction COPY (voir l’exemple complet en Python) :
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
Vous pouvez mettre à jour les colonnes vectorielles de la même façon que les colonnes standard :
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
Effectuer une recherche à distance cosinus
L’extension vector fournit l’opérateur v1 <=> v2 pour calculer la distance cosinus entre les vecteurs v1 et v2. Le résultat est un nombre compris entre 0 et 2, où 0 signifie « sémantiquement identique » (aucune distance) et 2 « sémantiquement opposé » (distance maximale).
Notez les termes distance cosinus et similarité cosinus. Rappelez-vous que la similarité cosinus est comprise entre -1 et 1, où -1 signifie « sémantiquement opposé » et 1 « sémantiquement identique ». Notez que similarity = 1 - distance.
En conséquence, une requête classée par distance croissante retourne les résultats les moins distants (les plus similaires) en premier, tandis qu’une requête ordonnée par similarité décroissante retourne les résultats les plus similaires (les moins distants) en premier.
Voici quelques vecteurs ainsi que leurs distances et similarités pour illustrer les concepts. Vous pouvez effectuer ce calcul vous-même en exécutant une commande semblable à celle-ci :
SELECT '[1,1]' <=> '[-1,-1]';
Prenez ces vecteurs :
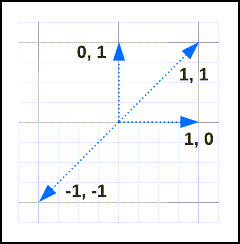
Leurs similarités et leurs distances sont les suivantes :
| v1 | V2 | distance | similarity |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
Pour obtenir les documents par ordre de proximité avec le vecteur [2, 3, 4], exécutez cette requête :
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
Résultats :
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
Le document avec id=3 est le plus similaire à la requête, suivi de peu par id=1 et enfin par id=2.
Ajoutez une clause LIMIT N à la requête SELECT pour retourner les N documents les plus similaires. Par exemple, pour obtenir le document le plus similaire :
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
Résultats :
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535