Explorer les pipelines d’ingestion de données
Maintenant que vous comprenez un peu l’architecture d’une solution d’entreposage de données à grande échelle et certaines des technologies de traitement distribué qui peuvent être utilisées pour gérer de grands volumes de données, il est temps d’explorer la manière dont les données sont ingérées dans un magasin de données analytique à partir d’une ou plusieurs sources.
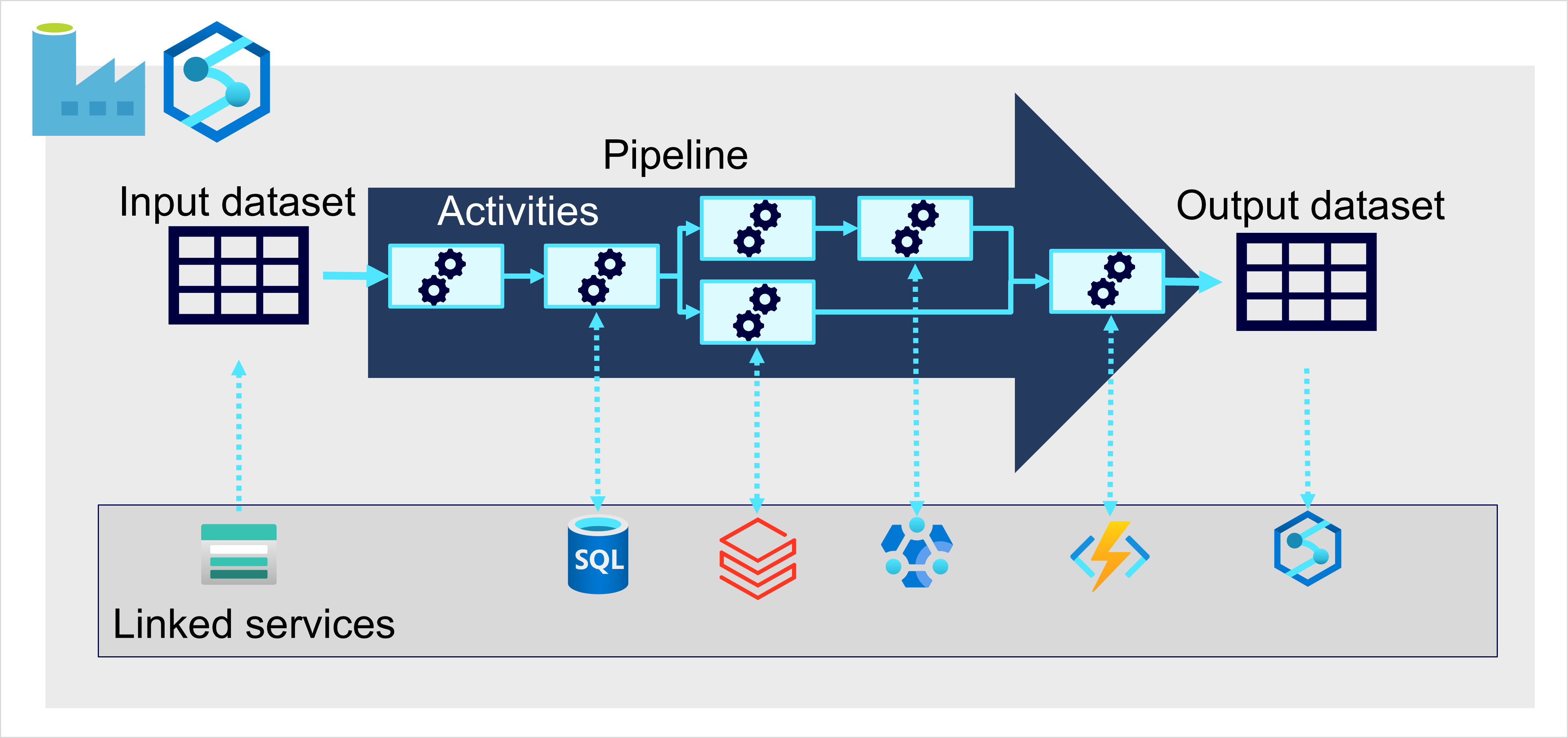
Dans Azure, l’ingestion de données à grande échelle est mieux implémentée en créant des pipelines qui orchestrent les processus ETL. Vous pouvez créer et exécuter des pipelines avec Azure Data Factory, ou vous pouvez utiliser la fonctionnalité de pipeline dans Microsoft Fabric si vous souhaitez gérer tous les composants de votre solution d’entreposage de données dans un espace de travail unifié.
Dans les deux cas, les pipelines se composent d’une ou plusieurs activités qui opèrent sur les données. Un jeu de données d’entrée fournit les données sources, et les activités peuvent être définies comme un flux de données qui manipule de manière incrémentielle les données jusqu’à ce qu’un jeu de données de sortie soit généré. Les pipelines utilisent des services liés pour charger et traiter les données, ce qui vous permet d’utiliser la technologie appropriée pour chaque étape du workflow. Par exemple, vous pouvez utiliser un service lié Magasin d’objets blob Azure pour ingérer le jeu de données d’entrée, puis utiliser des services comme Azure SQL Database pour exécuter une procédure stockée qui recherche des valeurs de données associées, avant d’exécuter une tâche de traitement des données sur Azure Databricks ou appliquer une logique personnalisée avec une fonction Azure. Enfin, vous pouvez enregistrer le jeu de données de sortie dans un service lié tel que Microsoft Fabric. Les pipelines peuvent également inclure des activités intégrées qui ne nécessitent pas de service lié.