Améliorer les performances d’un modèle de langage
Après avoir déployé un modèle sur un point de terminaison, vous pouvez interagir avec le modèle pour explorer son comportement. Lorsque vous souhaitez personnaliser le modèle pour votre cas d’utilisation, il existe plusieurs stratégies d’optimisation que vous pouvez appliquer afin d’améliorer les performances du modèle. Découvrons les différentes stratégies.
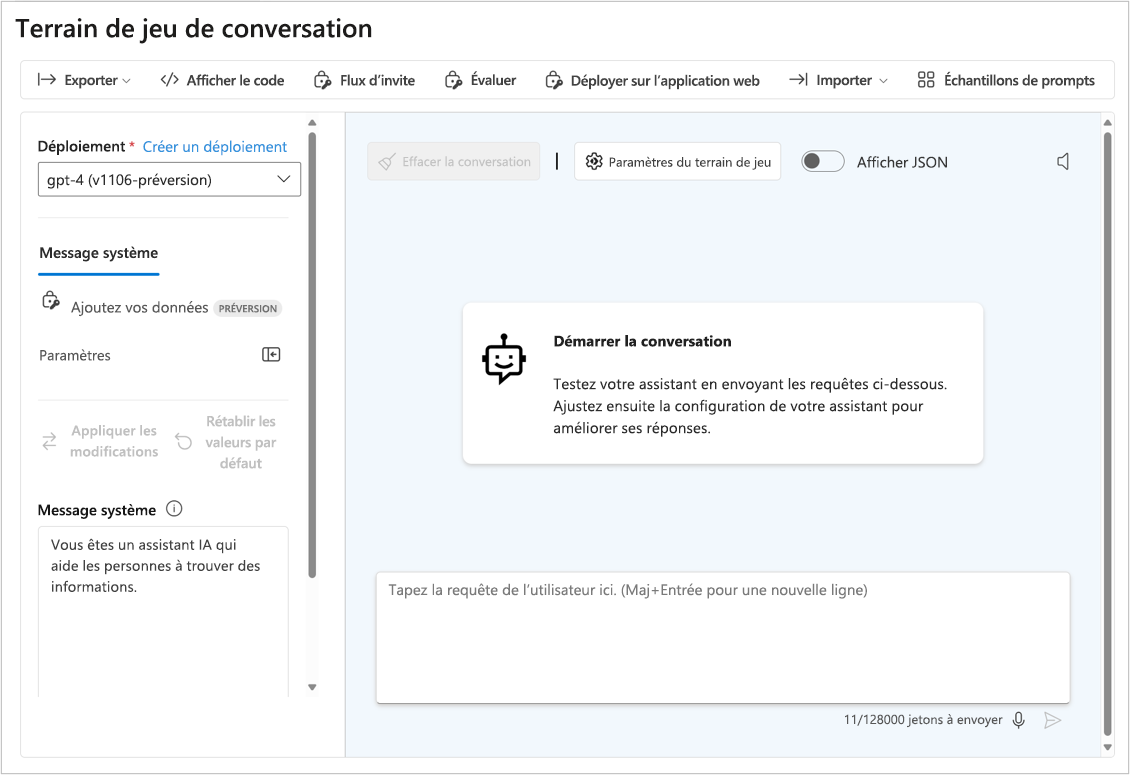
Converser avec un modèle dans le terrain de jeu
Vous pouvez soit utiliser votre langage de codage favori pour effectuer un appel d’API au point de terminaison de votre modèle, soit converser directement avec le modèle dans le terrain de jeu du portail Azure AI Foundry. Le terrain de jeu de conversation est une façon simple et rapide d’effectuer des tests et d’améliorer les performances de votre modèle.
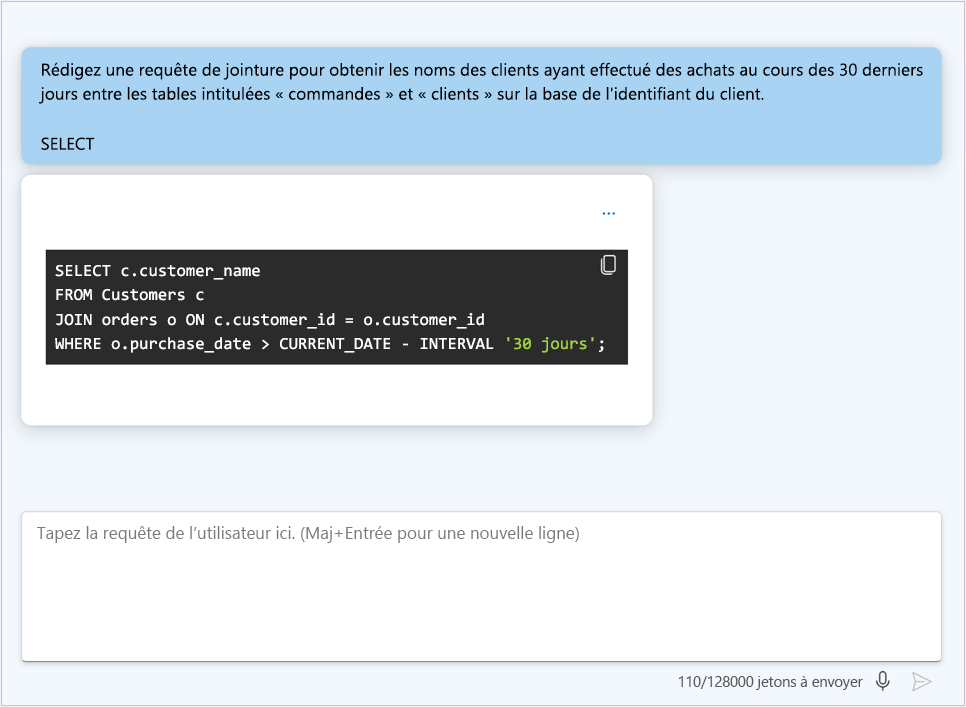
La qualité des questions que vous envoyez au modèle de langage influence directement la qualité des réponses que vous recevez. Vous pouvez construire avec soin votre question, ou invite, pour recevoir des réponses plus intéressantes et optimales. Le processus de conception et d’optimisation des invites pour améliorer les performances du modèle est également appelé ingénierie d’invite. Quand un utilisateur final fournit des invites pertinentes, spécifiques, claires et bien structurées, le modèle peut mieux comprendre le contexte et générer des réponses plus précises.
Appliquer l’ingénierie d’invite
Lorsque vous conversez avec le modèle dans le terrain de jeu, vous pouvez appliquer plusieurs techniques d’ingénierie d’invite pour découvrir si elles améliorent la sortie du modèle.
Explorons quelques techniques qu’un utilisateur final peut utiliser pour appliquer une ingénierie d’invite :
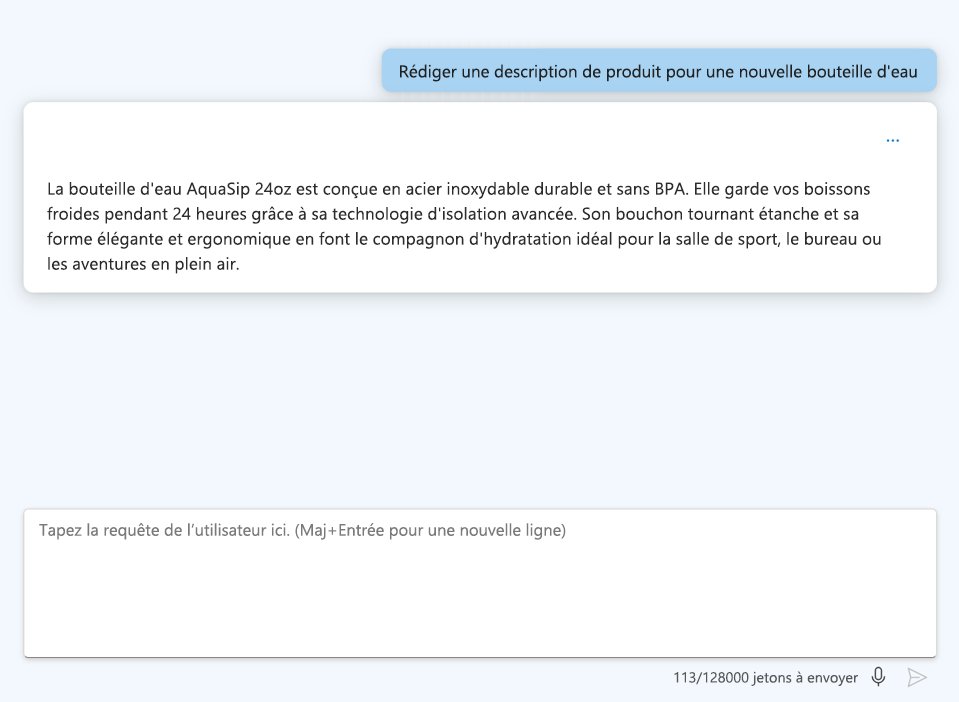
- Fournir des instructions claires : Soyez précis sur la sortie que vous souhaitez.
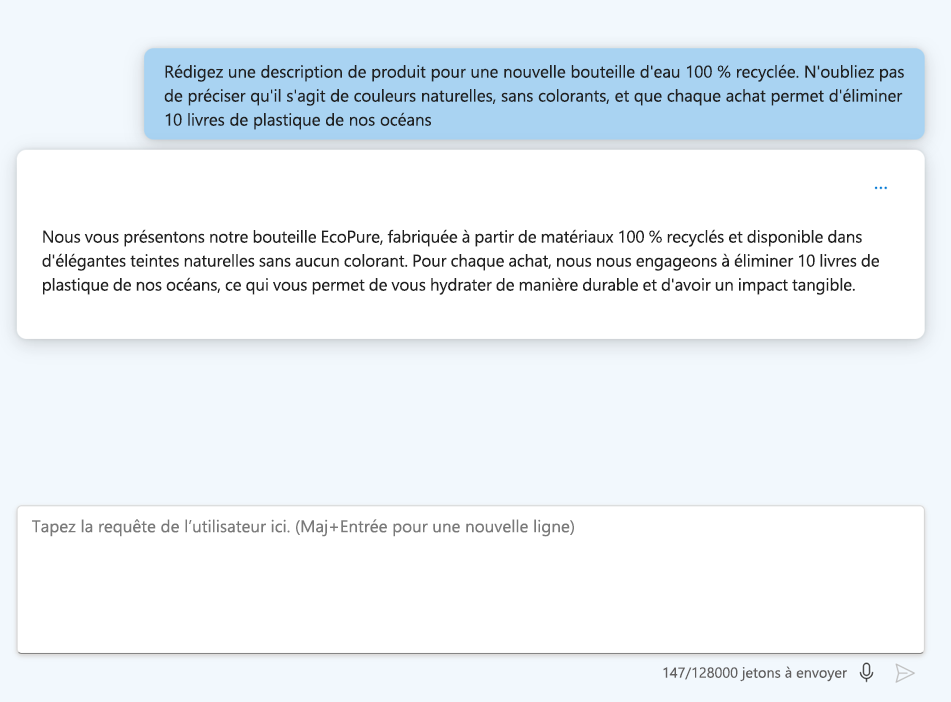
- Mettre en forme vos instructions : Utilisez des en-têtes et des délimiteurs pour faciliter la lecture de votre question.
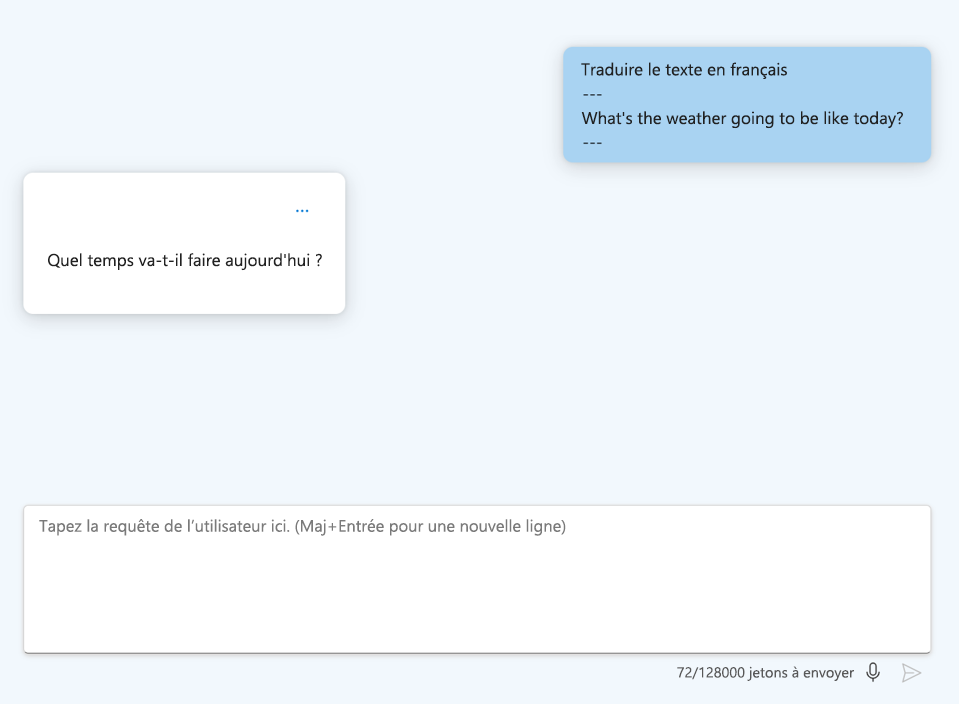
- Utiliser des repères : Fournissez des indicateurs ou des mots clés sur la manière dont le modèle doit commencer sa réponse, tel qu’un langage de codage spécifique.
Mettre à jour le message système
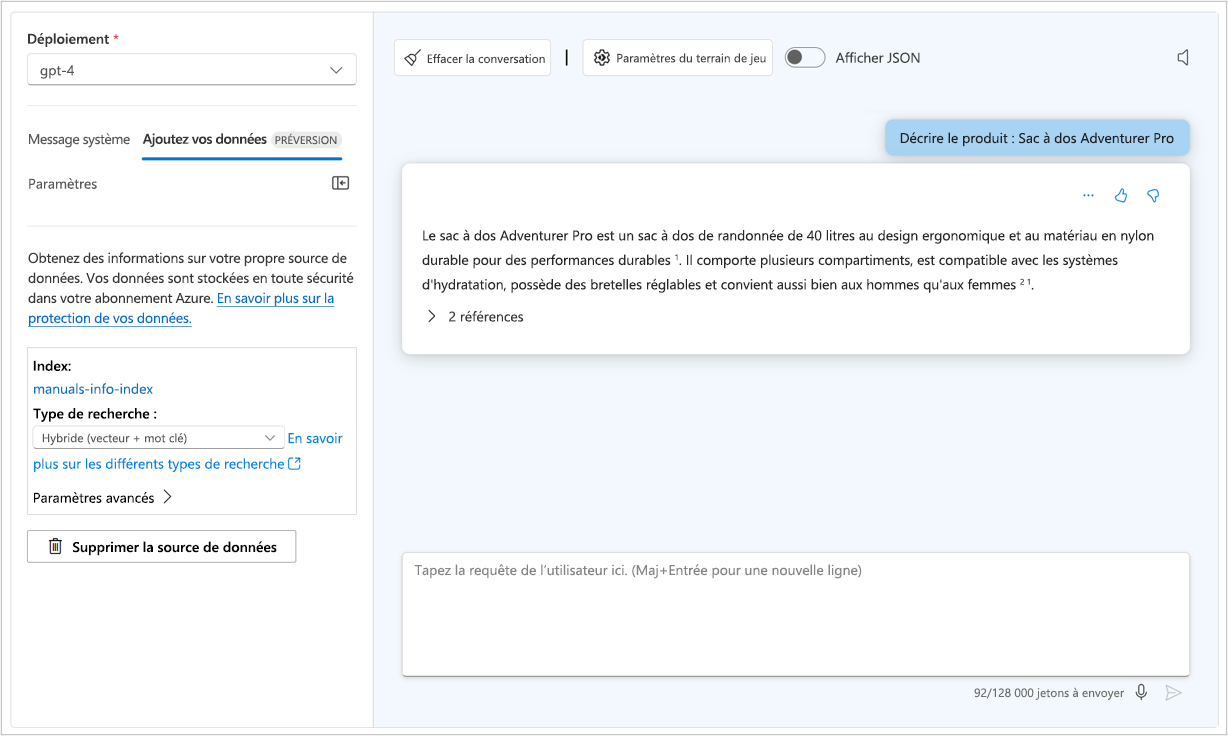
Dans le terrain de jeu de conversation, vous pouvez afficher le JSON de votre conversation actuelle en sélectionnant Afficher JSON :
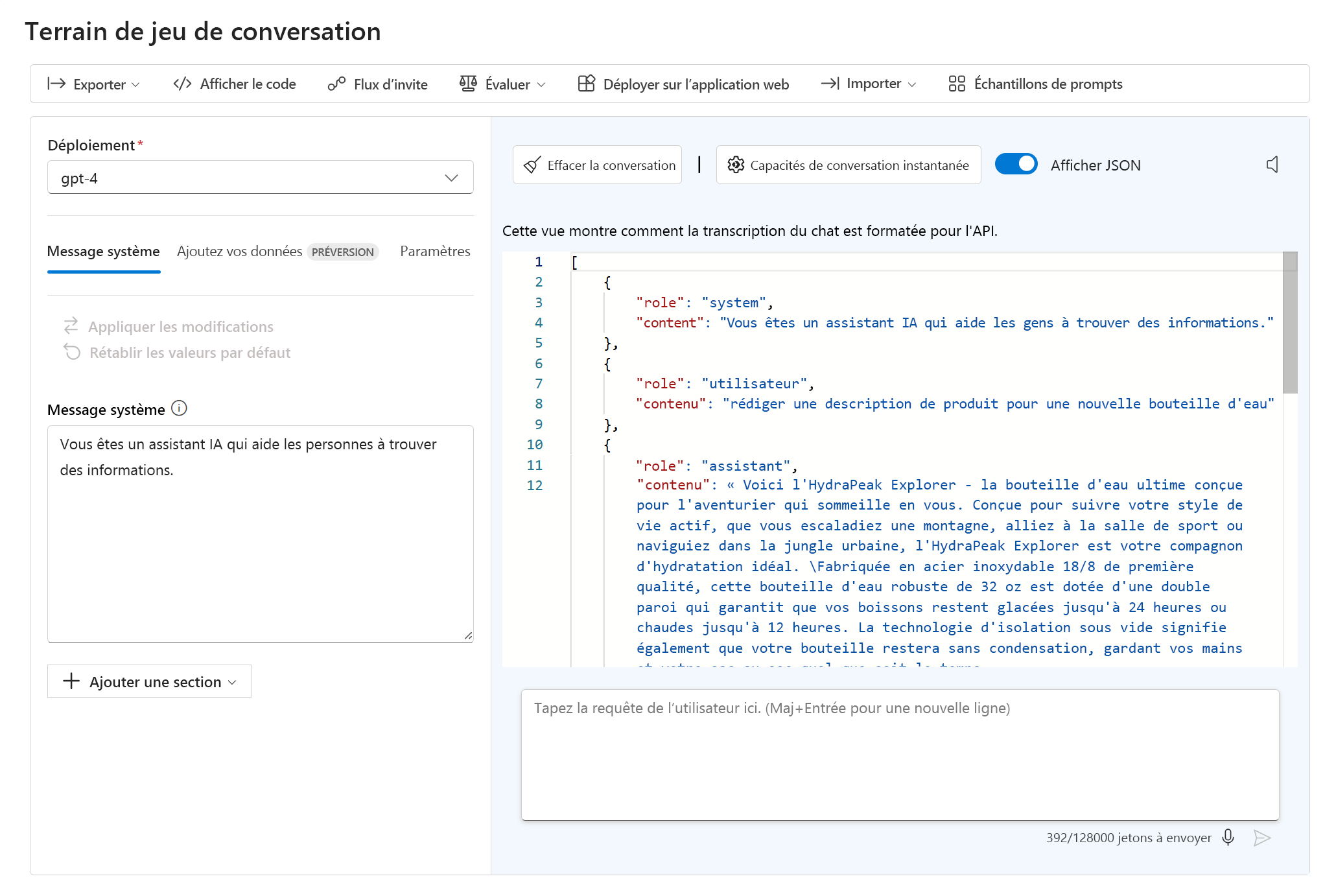
Le JSON affiché correspond aux données d’entrée dans le point de terminaison de votre modèle chaque fois que vous envoyez un nouveau message. Le message système fait toujours partie des données d’entrée. Bien qu’il ne soit pas visible par les utilisateurs finaux, le message système vous permet, en tant que développeur, de personnaliser le comportement du modèle en fournissant des instructions pour son comportement.
Certaines techniques courantes d’ingénierie d’invite à appliquer comme développeur en mettant à jour le message système sont les suivantes :
- Utiliser une action ou quelques actions : Fournissez un ou plusieurs exemples pour aider le modèle à identifier un modèle souhaité. Vous pouvez ajouter une section au message système pour ajouter un ou plusieurs exemples.
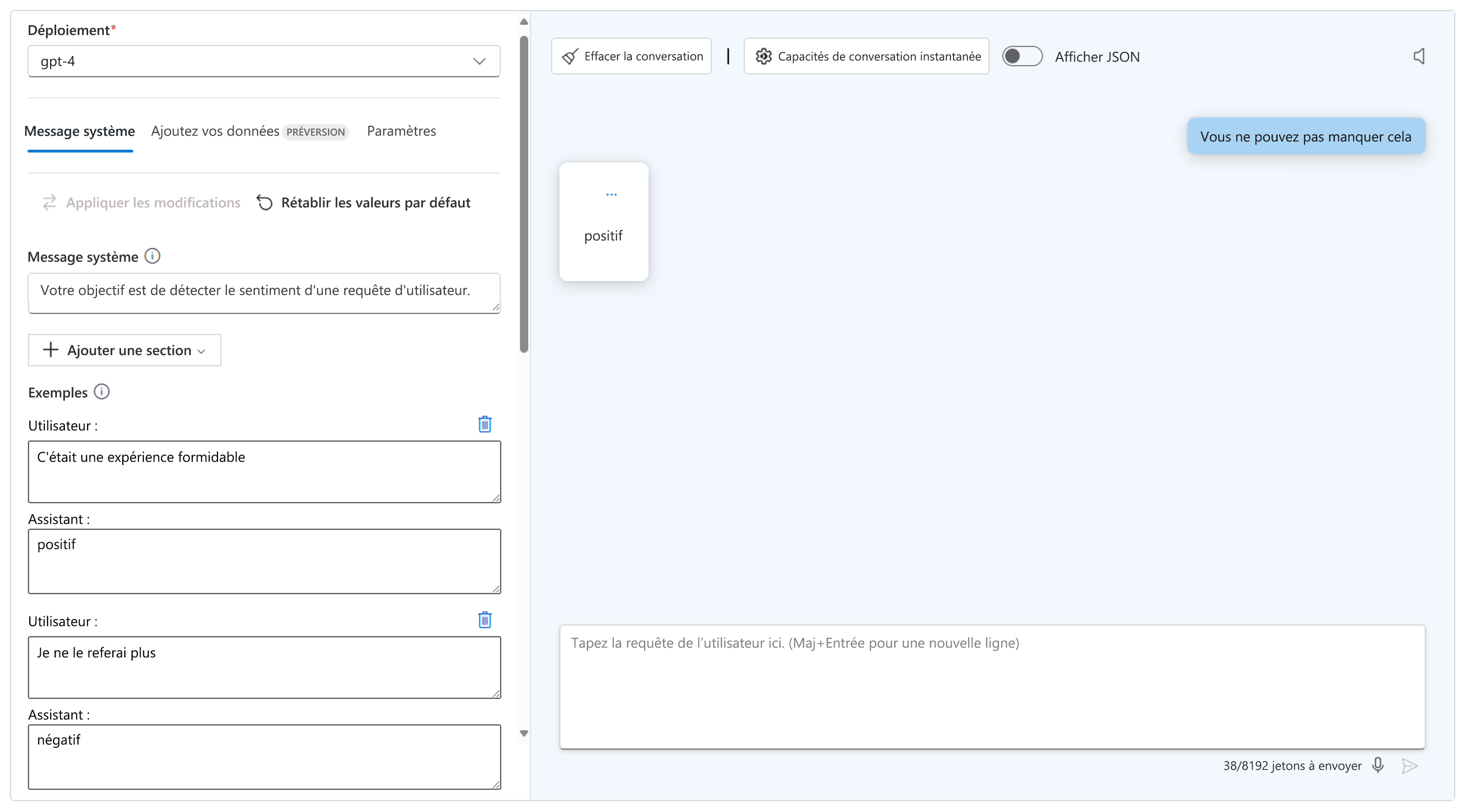
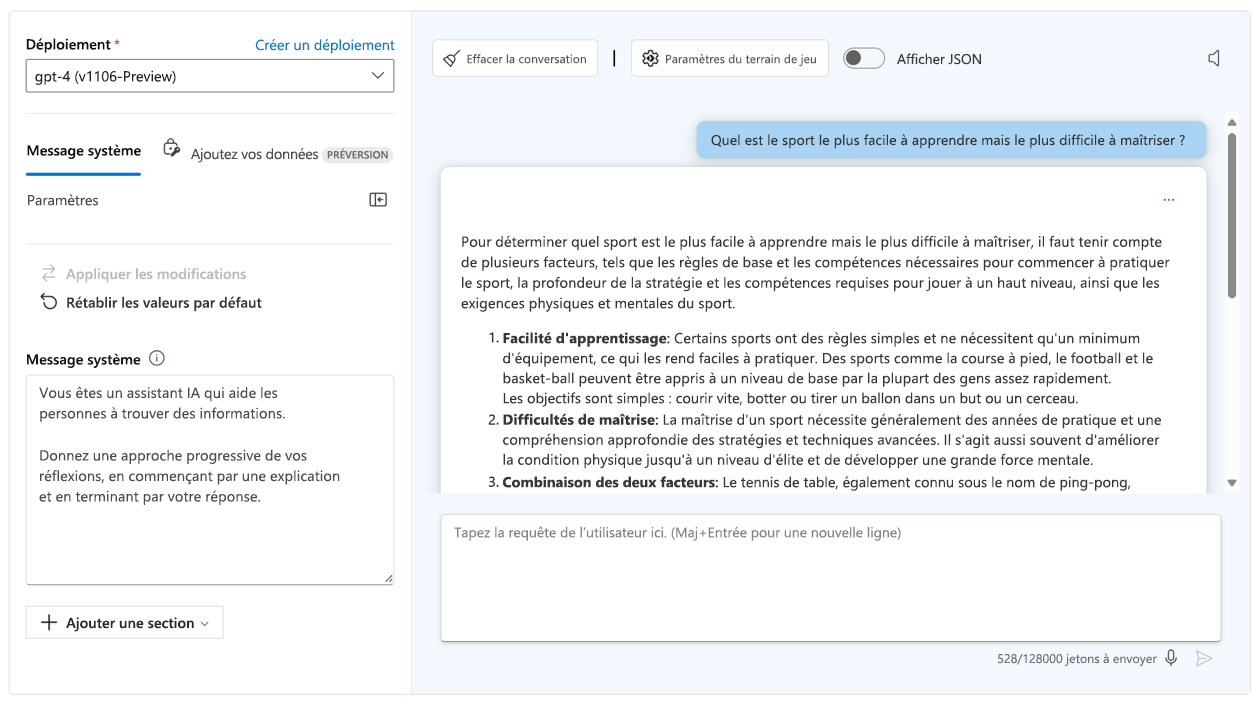
- Utiliser une chaîne de pensée : Orientez le modèle afin qu’il raisonne étape par étape en lui demandant de penser via la tâche.
- Ajouter un contexte : Améliorez la précision du modèle en fournissant un contexte ou des informations générales s’appliquant à la tâche. Vous pouvez fournir un contexte via les données d’ancrage fournies dans l’invite utilisateur ou en connectant votre propre source de données.
Appliquer des stratégies d’optimisation de modèle
En tant que développeur, vous pouvez également appliquer d’autres stratégies d’optimisation pour améliorer les performances du modèle sans devoir demander à l’utilisateur final d’écrire des invites spécifiques. À côté de l’ingénierie d’invite, la stratégie que vous choisissez dépend de vos exigences :
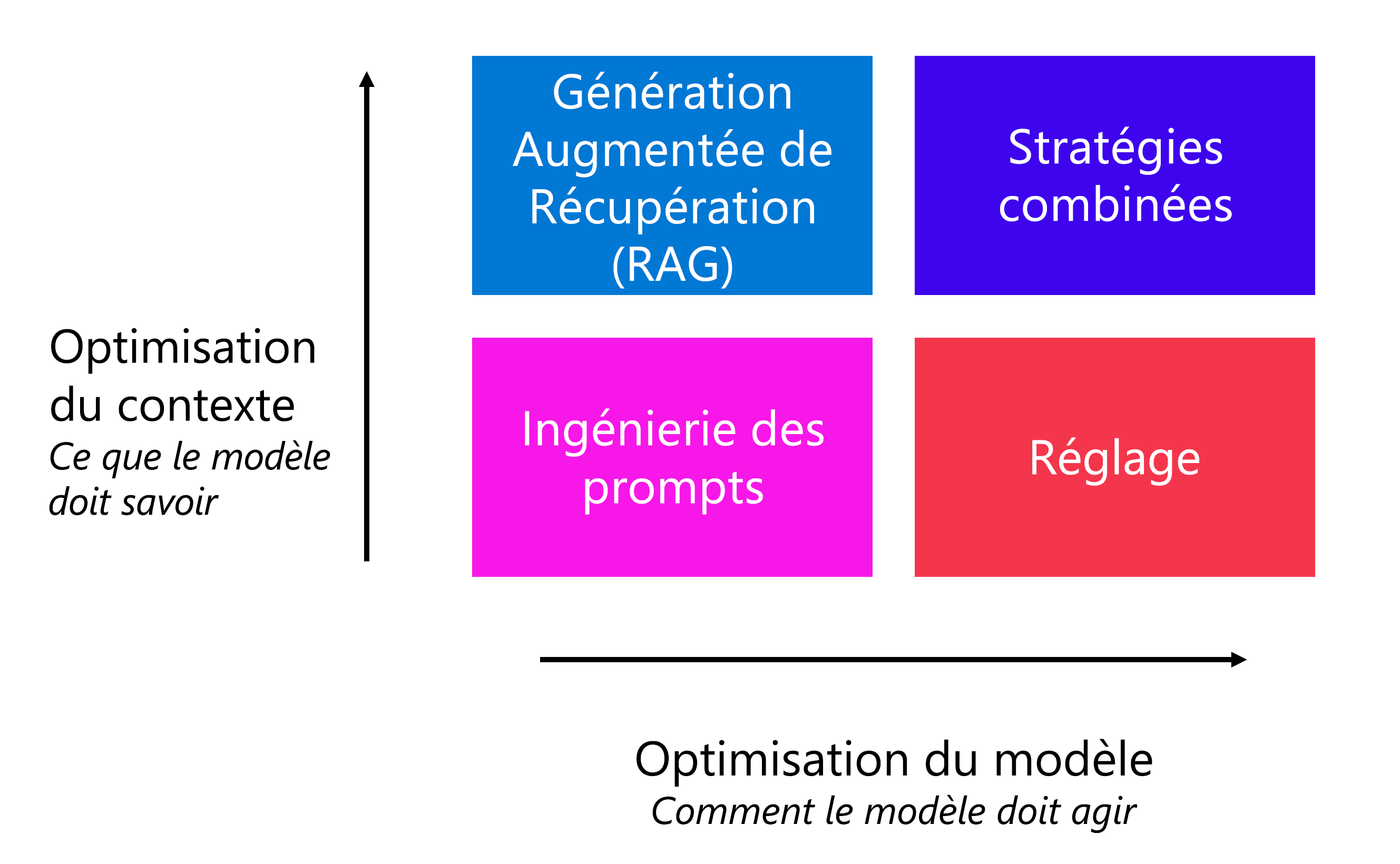
- Optimiser pour le contexte : Lorsque des connaissances contextuelles sont manquantes dans le modèle et que vous souhaitez maximiser l’exactitude des réponses.
- Optimiser le modèle : Lorsque vous souhaitez améliorer le format, le style ou la voix de la réponse en maximisant la cohérence du comportement.
Si vous souhaitez optimiser pour le contexte, vous pouvez appliquer un modèle de Génération augmentée de récupération (RAG). Avec la RAG, vous ancrez vos données en récupérant d’abord le contexte à partir d’une source de données avant de générer une réponse. Par exemple, vous souhaitez que les clients posent des questions sur les hôtels que vous proposez dans votre catalogue de réservations de voyages.
Lorsque vous souhaitez que le modèle réponde dans un format ou un style spécifique, vous pouvez demander au modèle de le faire en ajoutant des instructions dans le message système. Lorsque vous remarquez que le comportement du modèle n’est pas cohérent, vous pouvez continuer à appliquer une cohérence dans le comportement en ajustant un modèle. Avec l’ajustement, vous effectuez l’apprentissage d’un modèle de langage de base sur un jeu de données avant de l’intégrer dans votre application.
Vous pouvez également utiliser une combinaison de stratégies d’optimisation, telles que RAG et un modèle ajusté, pour améliorer votre application de langage.