Types de machine learning
Il existe plusieurs types de Machine Learning et il vous faut appliquer le type approprié en fonction de ce que vous essayez de prédire. Une répartition des types courants de Machine Learning est illustrée dans le diagramme suivant.
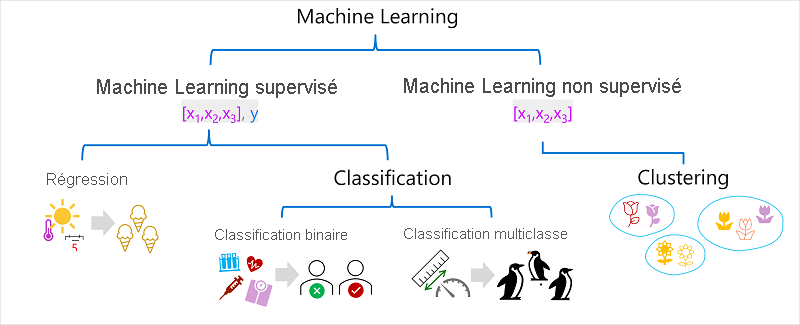
Machine learning supervisé
Le Machine Learning supervisé est un terme général pour des algorithmes de Machine Learning dans lesquels les données d’apprentissage comprennent à la fois des valeurs de fonctionnalité et des valeurs d’étiquette connues. Le Machine Learning supervisé sert à entraîner des modèles, en déterminant une relation entre les caractéristiques et les étiquettes dans les observations passées, afin que des étiquettes inconnues puissent être prédites pour des fonctionnalités des futurs cas.
régression ;
La régression est une forme de Machine Learning supervisé dans laquelle l’étiquette prédite par le modèle est une valeur numérique. Par exemple :
- Le nombre de glaces vendues une journée donnée, en fonction de la température, des précipitations et de la vitesse du vent.
- Le prix de vente d’une propriété en fonction de sa taille en mètres carrés, de son nombre de chambres et des métriques socio-économiques pour son emplacement.
- Le rendement énergétique (en miles par litre) d’une voiture en fonction de sa taille du moteur, de son poids, de sa largeur, de sa hauteur et de la longueur.
Classification
La classification est une forme de Machine Learning supervisé dans laquelle l’étiquette représente une catégorisation ou une classe. Il existe deux scénarios courants de classification.
Classification binaire
Dans la classification binaire, l’étiquette détermine si l’élément observé est (ou non) l’instance d’une classe spécifique. Autrement dit, les modèles de classification binaire prédisent l’un des deux résultats qui s’excluent mutuellement. Par exemple :
- Si un patient est à risque concernant le diabète, en fonction des métriques cliniques comme le poids, l’âge, le niveau de glucose dans le sang, etc.
- Si un client de la banque va faire défaut sur un prêt en fonction du revenu, des antécédents de crédit, de l’âge et d’autres facteurs.
- Si un client de liste de diffusion va répondre positivement à une offre marketing en fonction des attributs démographiques et des achats passés.
Dans tous ces exemples, le modèle établit une prédiction binaire vrai/faux ou positive/négative pour une seule classe possible.
Classification multiclasse
La classification multiclasse étend la classification binaire pour prédire une étiquette qui représente l’une des nombreuses classes possibles. Par exemple,
- L’espèce d’un manchot (Adelie, Gentoo, ou À jugulaire) en relative à des mesures physiques.
- Le genre d’un film (comédie, épouvante, romance, aventure ou science-fiction) basé sur sa distribution, son réalisateur et son budget.
Dans la plupart des scénarios qui impliquent un ensemble connu de classes, la classification multiclasse sert à prédire les étiquettes qui s’excluent mutuellement. Par exemple, un manchot ne peut pas être à la fois un Gentoo et un Adelie. Toutefois, il existe également des algorithmes que vous pouvez utiliser pour entraîner des modèles de classification multiétiquette et dans lesquels il peut y avoir plusieurs étiquettes valides pour une unique observation. Par exemple, un film pourrait être classé à la fois comme science-fiction et comédie.
Machine learning non supervisé
Le Machine Learning non supervisé implique l’apprentissage de modèles à l’aide de données qui se composent uniquement des valeurs de caractéristiques sans étiquette connue. Les algorithmes Machine Learning non supervisés déterminent les relations entre les caractéristiques des observations dans les données d’apprentissage.
Clustering
La plus courante forme de Machine Learning non supervisé est le clustering. Un algorithme de clustering identifie les similitudes entre les observations, en fonction de leurs caractéristiques, et les regroupe en clusters discrets. Par exemple :
- Regrouper des fleurs semblables en fonction de leur taille, du nombre de feuilles et de pétales.
- Identifiez les groupes de clients semblables en fonction des attributs démographiques et du comportement d’achat.
À certains égards, le clustering est semblable à la classification multiclasse. En ce sens qu’il classe les observations en groupes discrets. La différence est que lorsque vous utilisez la classification, vous connaissez déjà les classes auxquelles appartiennent les observations dans les données d’apprentissage. Ainsi, l’algorithme fonctionne en déterminant la relation entre les caractéristiques et l’étiquette de classification connue. Dans le clustering, il n’existe au préalable aucune étiquette de cluster connue et l’algorithme regroupe les observations de données en fonction de la similarité des fonctionnalités.
Dans certains cas, le clustering sert à déterminer l’ensemble des classes qui existent avant l’apprentissage d’un modèle de classification. Par exemple, vous pouvez utiliser un clustering pour scinder vos clients en groupes, puis analyser ces groupes pour identifier et créer différentes classes de clients (valeur élevée – faible volume, petit acheteur fréquent, etc.). Vous pouvez ensuite utiliser vos catégorisations pour étiqueter les observations dans vos résultats de clustering, puis utiliser les données étiquetées pour entraîner un modèle de classification qui prédit la catégorie à laquelle un nouveau client peut appartenir.