Qu’est-ce que la vision par ordinateur ?
La vision par ordinateur est un domaine de l’intelligence artificielle qui concerne le traitement visuel. Voyons certaines des possibilités que la vision par ordinateur apporte.
L’application Seeing AI illustre parfaitement la puissance de la vision par ordinateur. Conçue pour la communauté des personnes aveugles et malvoyantes, l’application Seeing AI exploite la puissance de l’IA pour ouvrir le monde visuel et décrire les personnes, le texte et les objets à proximité.
Regardez la vidéo suivante pour en savoir plus sur Seeing AI.
Pour en savoir plus, consultez la page web Seeing AI.
Modèles et fonctionnalités de la vision par ordinateur
La plupart des solutions de vision par ordinateur sont basées sur des modèles Machine Learning qui peuvent être appliqués à l’entrée visuelle des caméras, des vidéos ou des images. Le tableau suivant décrit les tâches qui sont couramment effectuées avec la vision par ordinateur.
| Tâche | Description |
|---|---|
| Classification des images |  La classification des images implique l’entraînement d’un modèle Machine Learning qui doit classifier les images en fonction de leur contenu. Par exemple, dans une solution de supervision du trafic, vous pouvez utiliser un modèle de classification d’images pour classifier les images en fonction du type de véhicule qu’elles contiennent, comme les taxis, les bus, les cyclistes, etc. |
| Détection des objets | 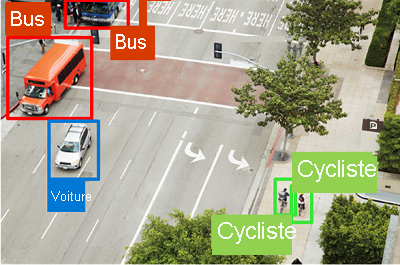 Les modèles Machine Learning de détection des objets sont entraînés pour classifier les objets d’une image et pour signaler leur emplacement à l’aide d’un cadre englobant. Par exemple, une solution de supervision du trafic peut utiliser la détection d’objet pour identifier l’emplacement de différentes classes de véhicules. |
| Segmentation sémantique |  La segmentation sémantique est une technique avancée de machine learning dans laquelle les pixels individuels de l’image sont classifiés en fonction de l’objet auquel ils appartiennent. Par exemple, une solution de supervision du trafic peut superposer des images de trafic avec des couches de « masques » pour mettre en évidence différents véhicules à l’aide de couleurs spécifiques. |
| Analyse d’image |  Vous pouvez créer des solutions qui combinent des modèles Machine Learning avec des techniques avancées d’analyse d’image afin d’extraire des informations à partir d’images, y compris des « étiquettes » qui permettent de cataloguer l’image, ou même des légendes descriptives qui résument la scène illustrée dans l’image. |
| Détection, analyse et reconnaissance des visages |  La détection des visages est une forme spécialisée de détection des objets qui localise les visages humains dans une image. Elle peut être combinée avec des techniques de classification et d’analyse de la géométrie faciale pour reconnaître des individus en fonction de leurs traits. |
| Reconnaissance optique de caractères |  La reconnaissance optique de caractères est une technique utilisée pour détecter et lire du texte dans des images. Vous pouvez utiliser la reconnaissance optique de caractères pour lire du texte sur des photos (par exemple, des panneaux de signalisation routière ou des vitrines de magasins), ou pour extraire des informations de documents numérisés tels que des lettres, des factures ou des formulaires. |
Services de vision par ordinateur dans Microsoft Azure
Vous pouvez utiliser Azure AI Vision de Microsoft pour développer des solutions de vision par ordinateur. Les caractéristiques du service peuvent être utilisées et testées dans Azure Vision Studio et dans d'autres langages de programmation. Parmi les caractéristiques d'Azure AI Vision figurent les suivantes :
- analyse d'images : capacités d'analyse d'images et de vidéos et d'extraction de descriptions, de balises, d'objets et de texte.
- visage : capacités de création de solutions de détection et de reconnaissance des visages.
- Reconnaissance optique des caractères (OCR) : capacités d'extraction de texte imprimé ou manuscrit à partir d'images, permettant d'accéder à une version numérique du texte numérisé.