Déterminer les besoins de mise à l’échelle du serveur Azure Database pour MySQL
En ce qui concerne le dimensionnement des ressources de calcul, déterminez si l’utilisation existante et prévue se situe dans les limites de la capacité. Vous pouvez obtenir les informations requises en supervisant les métriques de performances de base, telles que l’utilisation du processeur et de la RAM. Il est possible d’utiliser le journal des requêtes lentes pour identifier et optimiser les requêtes aux mauvaises performances et résoudre le problème de performances sans mettre à l’échelle la taille de calcul. Vous devez également superviser les performances des E/S pour vous assurer que les lectures et les écritures de base de données ne sont pas un goulot d’étranglement des performances. Une autre option permettant d’augmenter efficacement la capacité disponible sur la base de données principale consiste à approvisionner un réplica en lecture pour déplacer la charge des requêtes.
Superviser les métriques de performances de base de données
Le Portail Azure permet d’accéder à un certain nombre de métriques que vous pouvez utiliser pour superviser les performances de la base de données. Par exemple, vous pouvez visualiser le pourcentage de processeur utilisé par un serveur flexible.

À mesure que l’utilisation du processeur s’approche de 100 %, les performances de la base de données se dégradent gravement. Par conséquent, si l’utilisation du processeur sur votre serveur flexible est constamment supérieure à 50 %, envisagez d’augmenter la taille de calcul.
Vous pouvez afficher vos métriques de performances dans le classeur Vue d’ensemble de la supervision. Pour accéder au classeur Vue d’ensemble, procédez comme suit :
Dans le Portail Azure, dans le volet gauche, sous Supervision pour votre instance de serveur flexible Azure Database pour MySQL, sélectionnez Classeurs.
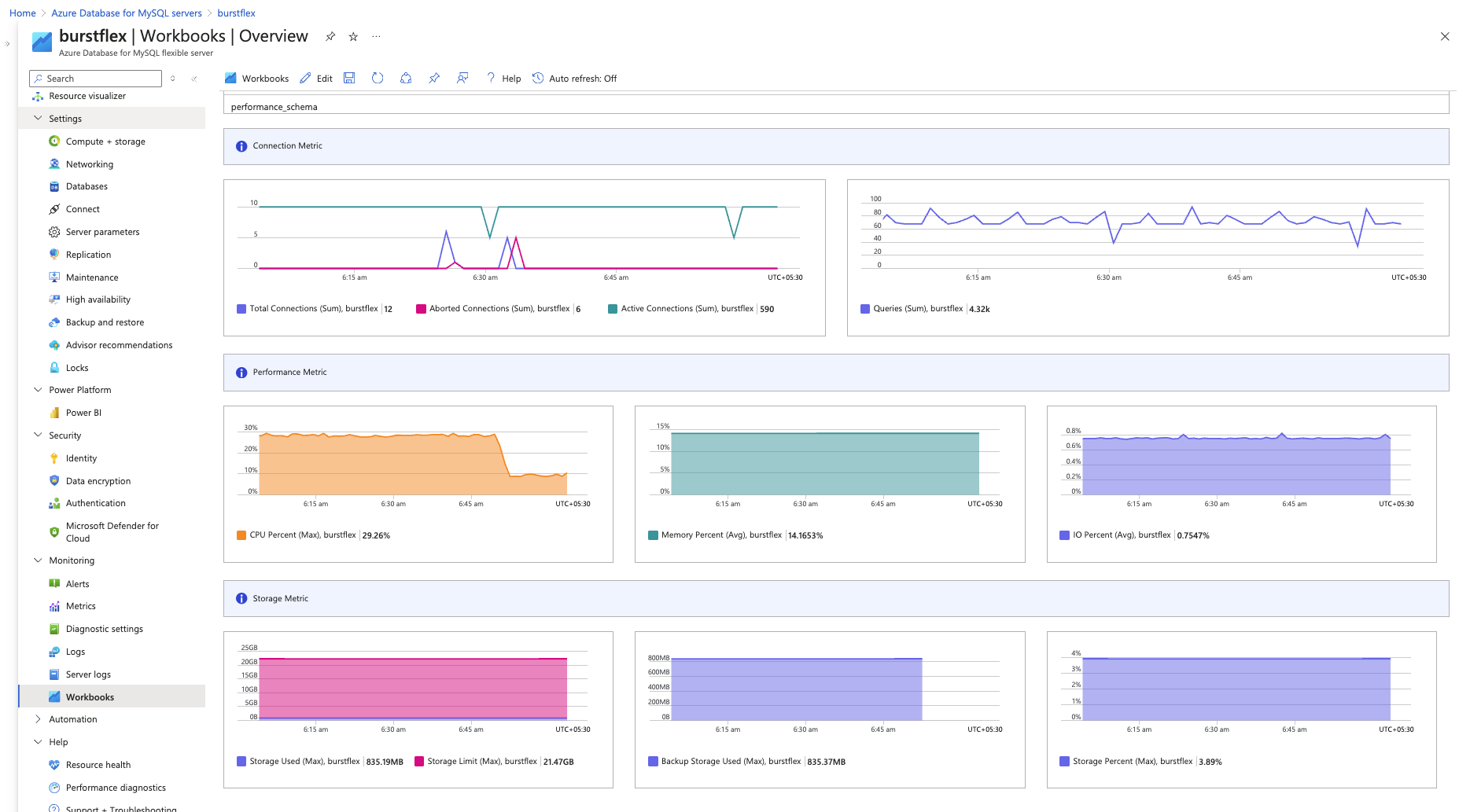
Sélectionnez le classeur Vue d’ensemble. Vous verrez des graphiques montrant les connexions, l’utilisation du processeur et de la mémoire, ainsi que d’autres métriques, comme dans la capture d’écran ci-dessous.


Outre l’analyse de ces métriques, vous pouvez afficher les diagnostics du serveur pour obtenir des informations sur les performances dans le panneau Journaux de votre serveur flexible.

En plus de ces métriques et journaux, vous pouvez également superviser le journal des requêtes lentes pour capturer des détails sur les requêtes longues. Ces informations peuvent révéler des requêtes lentes existantes pour l’optimisation, et vous pouvez configurer des alertes pour détecter immédiatement les régressions futures des performances des requêtes pour l’atténuation.
Pour activer la fonctionnalité Journal des requêtes lentes, sur la page associée à votre serveur flexible, sélectionnez Journaux du serveur, puis cochez les cases « Activer » et « Journaux des requêtes lentes ».

Une fois la journalisation des requêtes lentes activée, vous pouvez afficher les insights sur les performances des requêtes à l’aide de l’analytique des journaux d’activité ou de classeurs de visualisation. Pour accéder aux insights sur les performances des requêtes, suivez les mêmes étapes que celles ci-dessus, mais sélectionnez Analyse des performances des requêtes au lieu de Vue d’ensemble.
Vous verrez plusieurs visualisations, notamment les cinq requêtes les plus longues ou un résumé des requêtes lentes, comme illustré dans la capture d’écran suivante.

Ajuster les paramètres de performances du serveur
Vous pouvez configurer les paramètres du serveur MySQL pour optimiser les performances en fonction de votre supervision. Par exemple, vous pouvez augmenter la valeur de innodb_buffer_pool_size pour conserver davantage de données de table en mémoire et économiser sur les lectures de disque. Vous pouvez augmenter innodb_log_file_size pour réduire l’activité de vidage du point de contrôle du pool de mémoires tampons, au prix d’une récupération sur incident plus lente.
Si vous constatez que les connexions d’application sont mises en file d’attente et que la charge du serveur est acceptable, vous pouvez augmenter le nombre de connexions maximales pour permettre un parallélisme accru.
Pour modifier les paramètres du serveur, accédez au Portail Azure pour votre serveur flexible MySQL et accédez à la section Paramètres du serveur. Entrez le nom du paramètre dans la barre de recherche ou parcourez les Principaux ou Tous les paramètres de serveur pris en charge pris en charge.
Explorer et activer la fonctionnalité Mise à l'échelle automatique des IOPS
Azure Database pour MySQL a deux façons d’allouer la capacité d’E/S disque : les IOPS (opérations d’E/S par seconde) préapprovisionnées et « mises à l’échelle automatiquement ».
Les IOPS préapprovisionnées peuvent être préférables lorsque la charge de base de données est prévisible et ne présente pas de pics. Le serveur obtient un nombre de base d’IOPS approvisionnées et vous pouvez allouer des IOPS supplémentaires (jusqu’à la taille de calcul maximale) si nécessaire en accédant à Calcul + Stockage :

En cas de pic, les performances du serveur peuvent se dégrader temporairement si les opérations d’E/S dépassent la valeur allouée. Toutefois, la capacité et les coûts sont prévisibles.
La fonctionnalité Mise à l’échelle automatique des IOPS est conçue pour un trafic de base de données imprévisible, croissant ou présentant des pics. Avec cette fonctionnalité activée, les IOPS sont mises à l’échelle dynamiquement, de sorte que l’ajustement manuel n’est pas nécessaire pour optimiser les coûts ou les performances à mesure que varie le workflow. Par conséquent, l’utilisation de la fonctionnalité Mise à l'échelle automatique des IOPS gère les pics de charge de travail imprévus de manière transparente, et vous payez uniquement pour les opérations consommées, et non pour la capacité inutilisée.
Pour un serveur flexible MySQL existant, vous pouvez activer la fonctionnalité Mise à l’échelle automatique des IOPS dans le Portail Azure, en sélectionnant Calcul + stockage :

Remarque
Vous pouvez également activer la fonctionnalité de mise à l’échelle automatique des IOPS lors de la création du serveur.
Superviser les IOPS
Le monitoring des IOPS vous permet de déterminer la proximité de votre instance au nombre maximal d’IOPS, si vous utilisez des IOPS préapprovisionnées, ou à la taille de calcul maximale si vous utilisez la fonctionnalité de mise à l’échelle automatique des IOPS.
Pour superviser les performances des IOPS, accédez au panneau Métriques sous la section Supervision ou dans le panneau Vue d’ensemble, si vous souhaitez afficher les performances des IOPS avec d’autres métriques courantes.
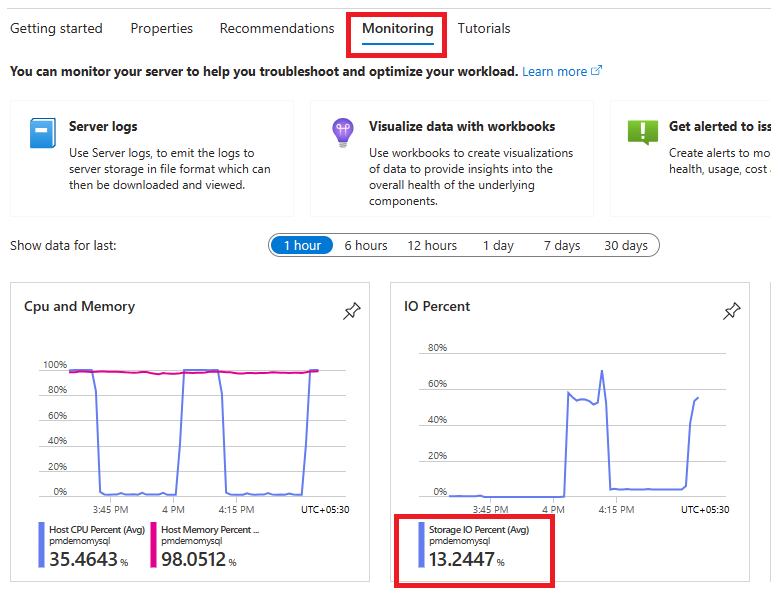
Chez WingTip Toys, étant donné que vous prévoyez une augmentation majeure du trafic à des moments imprévisibles au fur et à mesure du déploiement de la campagne marketing, vous souhaitez éviter le risque de ne pas pouvoir prendre en charge les commandes entrantes. Vous souhaitez également éviter de payer pour une capacité maximale si vous n’en avez pas réellement besoin. Vous optez pour la fonctionnalité de mise à l’échelle automatique des IOPS plutôt que pour les IOPS préapprovisionnées, ce qui nécessite d’ajouter plus d’IOPS manuellement en fonction des besoins. Cette approche équilibre le rapport coût-efficacité avec la scalabilité à la demande.
Approvisionner un réplica en lecture
Vous approvisionnez des réplicas en lecture pour décharger des requêtes en lecture seule vers une base de données distincte, ce qui réduit la charge sur la base de données d’application principale.
Pour approvisionner un réplica en lecture, dans le Portail Azure, sur la page associée à votre serveur flexible, sélectionnez Réplication, puis sélectionnez Ajouter un réplica.

Après avoir créé le réplica en lecture, vous pouvez configurer le nom du serveur réplica et ses paramètres de calcul et de stockage. Vous ne pouvez pas modifier certains paramètres, comme l’authentification, qui sont hérités du serveur principal.

Chez Wingtip Toys, l’équipe de science des données et les outils de création de rapports peuvent désormais interroger le serveur réplica en lecture, ce qui réduit la charge sur la base de données principale de l’application et supprime la nécessité de limiter les analyses ou de restreindre les requêtes aux heures creuses.