Réduire les erreurs du modèle avec des fonctions de coût
Le processus d’apprentissage modifie un modèle de façon répétée jusqu’à ce qu’il puisse faire des estimations de grande qualité. Pour déterminer le degré d’efficacité d’un modèle, le processus d’apprentissage utilise les mathématiques sous la forme d’une fonction de coût. La fonction de coût est également appelée fonction d’objectif. Pour comprendre ce qu’est une fonction de coût, décomposons-la un peu.
Erreur, coût et perte
Dans l’apprentissage supervisé, l’erreur, le coût et la perte font référence au nombre d’erreurs que fait un modèle dans la prédiction d’une ou plusieurs étiquettes.
Ces trois termes sont utilisés assez librement dans le Machine Learning, ce qui peut entraîner une certaine confusion. Par souci de simplicité, nous les utilisons ici de façon interchangeable. Le coût est calculé au moyen des mathématiques : ce n’est pas un jugement qualitatif. Par exemple, si un modèle prédit une température quotidienne de 40 °F, mais que la valeur réelle est de 35 °F, nous pouvons dire qu’il a une erreur de 5 °F.
La réduction du coût est notre objectif.
Étant donné que le coût indique dans quelle mesure le modèle fonctionne incorrectement, notre objectif est d’avoir un coût nul. En d’autres termes, nous voulons entraîner le modèle à ne faire aucune erreur. Cette idée est cependant impossible : nous définissons donc à la place un objectif d’entraînement du modèle légèrement plus flou consistant à avoir le coût le plus petit possible.
En raison de cet objectif, la façon dont nous calculons le coût détermine ce que le modèle essaie d’apprendre. Dans l’exemple précédent, nous avons défini le coût comme l’erreur d’estimation de la température.
Qu’est-ce qu’une fonction de coût ?
Dans un apprentissage supervisé, une fonction de coût est un petit morceau de code qui calcule le coût à partir de la prédiction d’un modèle et de l’étiquette attendue, c’est-à-dire la réponse correcte. Par exemple, dans notre exercice précédent, nous avons calculé le coût en estimant les erreurs de prédiction, en les mettant au carré et en les additionnant.
Après le calcul du coût par la fonction de coût, nous savons si le modèle fonctionne correctement ou pas. S’il fonctionne bien, nous pouvons choisir d’arrêter l’entraînement. Si ce n’est pas le cas, nous pouvons passer les informations de coût à l’optimiseur, qui utilise ces informations pour choisir de nouveaux paramètres pour le modèle.
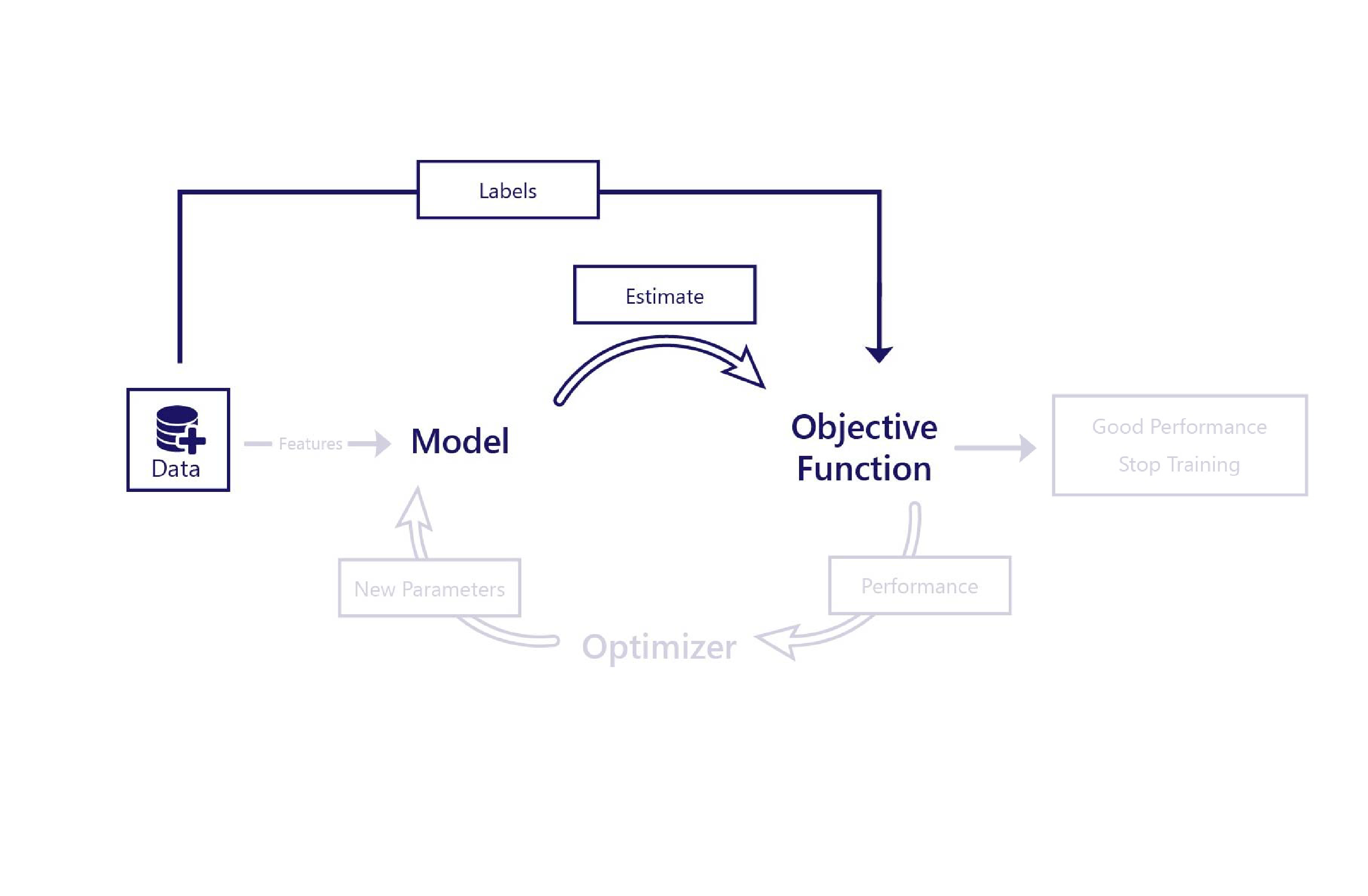
Au cours de l’apprentissage, différentes fonctions de coût peuvent modifier la durée de l’entraînement ou la qualité de son fonctionnement. Par exemple, si la fonction de coût indique toujours que les erreurs sont petites, l’optimiseur n’apporte que des modifications mineures au modèle. Un autre exemple est celui d’une fonction de coût qui retourne des valeurs importantes lorsque certaines erreurs sont commises. Dans ce cas, l’optimiseur apporte des modifications au modèle afin qu’il ne commette pas ces types d’erreurs.
Il n’existe pas de fonction de coût convenant à tous les cas. La meilleure dépend de ce que nous essayons d’atteindre. Nous devons souvent faire des expériences avec différentes fonctions de coût pour obtenir un résultat qui nous convient. Nous allons faire ces expériences dans l’exercice suivant.